 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Meaningful Perturbation Metric for Evaluating Explainability Methods
Apr 09, 2025Deep neural networks (DNNs) have demonstrated remarkable success, yet their wide adoption is often hindered by their opaque decision-making. To address this, attribution methods have been proposed to assign relevance values to each part of the input. However, different methods often produce entirely different relevance maps, necessitating the development of standardized metrics to evaluate them. Typically, such evaluation is performed through perturbation, wherein high- or low-relevance regions of the input image are manipulated to examine the change in prediction. In this work, we introduce a novel approach, which harnesses image generation models to perform targeted perturbation. Specifically, we focus on inpainting only the high-relevance pixels of an input image to modify the model's predictions while preserving image fidelity. This is in contrast to existing approaches, which often produce out-of-distribution modifications, leading to unreliable results. Through extensive experiments, we demonstrate the effectiveness of our approach in generating meaningful rankings across a wide range of models and attribution methods. Crucially, we establish that the ranking produced by our metric exhibits significantly higher correlation with human preferences compared to existing approaches, underscoring its potential for enhancing interpretability in DNNs.
VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Models
Feb 04, 2025



Despite tremendous recent progress, generative video models still struggle to capture real-world motion, dynamics, and physics. We show that this limitation arises from the conventional pixel reconstruction objective, which biases models toward appearance fidelity at the expense of motion coherence. To address this, we introduce VideoJAM, a novel framework that instills an effective motion prior to video generators, by encouraging the model to learn a joint appearance-motion representation. VideoJAM is composed of two complementary units. During training, we extend the objective to predict both the generated pixels and their corresponding motion from a single learned representation. During inference, we introduce Inner-Guidance, a mechanism that steers the generation toward coherent motion by leveraging the model's own evolving motion prediction as a dynamic guidance signal. Notably, our framework can be applied to any video model with minimal adaptations, requiring no modifications to the training data or scaling of the model. VideoJAM achieves state-of-the-art performance in motion coherence, surpassing highly competitive proprietary models while also enhancing the perceived visual quality of the generations. These findings emphasize that appearance and motion can be complementary and, when effectively integrated, enhance both the visual quality and the coherence of video generation. Project website: https://hila-chefer.github.io/videojam-paper.github.io/
Still-Moving: Customized Video Generation without Customized Video Data
Jul 11, 2024



Customizing text-to-image (T2I) models has seen tremendous progress recently, particularly in areas such as personalization, stylization, and conditional generation. However, expanding this progress to video generation is still in its infancy, primarily due to the lack of customized video data. In this work, we introduce Still-Moving, a novel generic framework for customizing a text-to-video (T2V) model, without requiring any customized video data. The framework applies to the prominent T2V design where the video model is built over a text-to-image (T2I) model (e.g., via inflation). We assume access to a customized version of the T2I model, trained only on still image data (e.g., using DreamBooth or StyleDrop). Naively plugging in the weights of the customized T2I model into the T2V model often leads to significant artifacts or insufficient adherence to the customization data. To overcome this issue, we train lightweight $\textit{Spatial Adapters}$ that adjust the features produced by the injected T2I layers. Importantly, our adapters are trained on $\textit{"frozen videos"}$ (i.e., repeated images), constructed from image samples generated by the customized T2I model. This training is facilitated by a novel $\textit{Motion Adapter}$ module, which allows us to train on such static videos while preserving the motion prior of the video model. At test time, we remove the Motion Adapter modules and leave in only the trained Spatial Adapters. This restores the motion prior of the T2V model while adhering to the spatial prior of the customized T2I model. We demonstrate the effectiveness of our approach on diverse tasks including personalized, stylized, and conditional generation. In all evaluated scenarios, our method seamlessly integrates the spatial prior of the customized T2I model with a motion prior supplied by the T2V model.
Lumiere: A Space-Time Diffusion Model for Video Generation
Feb 05, 2024



We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
The Hidden Language of Diffusion Models
Jun 06, 2023



Text-to-image diffusion models have demonstrated an unparalleled ability to generate high-quality, diverse images from a textual concept (e.g., "a doctor", "love"). However, the internal process of mapping text to a rich visual representation remains an enigma. In this work, we tackle the challenge of understanding concept representations in text-to-image models by decomposing an input text prompt into a small set of interpretable elements. This is achieved by learning a pseudo-token that is a sparse weighted combination of tokens from the model's vocabulary, with the objective of reconstructing the images generated for the given concept. Applied over the state-of-the-art Stable Diffusion model, this decomposition reveals non-trivial and surprising structures in the representations of concepts. For example, we find that some concepts such as "a president" or "a composer" are dominated by specific instances (e.g., "Obama", "Biden") and their interpolations. Other concepts, such as "happiness" combine associated terms that can be concrete ("family", "laughter") or abstract ("friendship", "emotion"). In addition to peering into the inner workings of Stable Diffusion, our method also enables applications such as single-image decomposition to tokens, bias detection and mitigation, and semantic image manipulation. Our code will be available at: https://hila-chefer.github.io/Conceptor/
Discriminative Class Tokens for Text-to-Image Diffusion Models
Mar 30, 2023Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. However, generated images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This comes with a downside, doing so limits their expressive power: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, and so the quality and diversity of generated images are severely affected, or (ii) the input is a hard-coded label, as opposed to free-form text, which limits the control over the generated images. In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier. The code is available at \url{https://github.com/idansc/discriminative_class_tokens}
Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
Jan 31, 2023Recent text-to-image generative models have demonstrated an unparalleled ability to generate diverse and creative imagery guided by a target text prompt. While revolutionary, current state-of-the-art diffusion models may still fail in generating images that fully convey the semantics in the given text prompt. We analyze the publicly available Stable Diffusion model and assess the existence of catastrophic neglect, where the model fails to generate one or more of the subjects from the input prompt. Moreover, we find that in some cases the model also fails to correctly bind attributes (e.g., colors) to their corresponding subjects. To help mitigate these failure cases, we introduce the concept of Generative Semantic Nursing (GSN), where we seek to intervene in the generative process on the fly during inference time to improve the faithfulness of the generated images. Using an attention-based formulation of GSN, dubbed Attend-and-Excite, we guide the model to refine the cross-attention units to attend to all subject tokens in the text prompt and strengthen - or excite - their activations, encouraging the model to generate all subjects described in the text prompt. We compare our approach to alternative approaches and demonstrate that it conveys the desired concepts more faithfully across a range of text prompts.
Optimizing Relevance Maps of Vision Transformers Improves Robustness
Jun 02, 2022
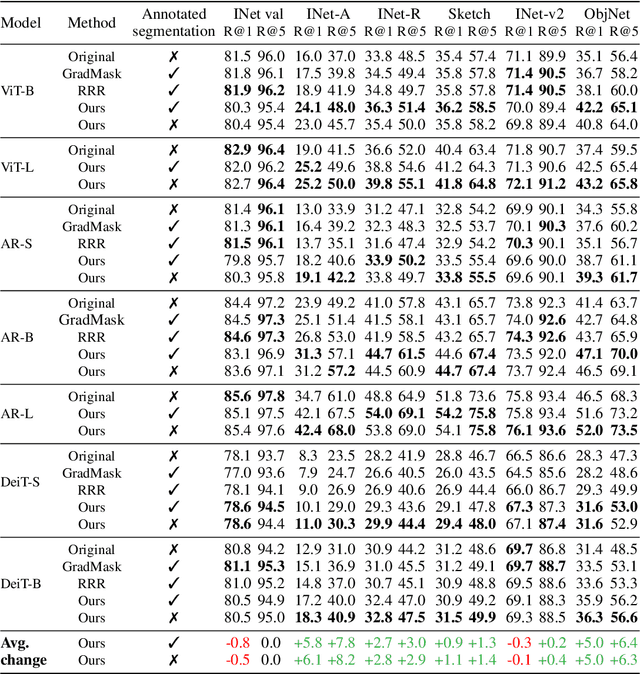
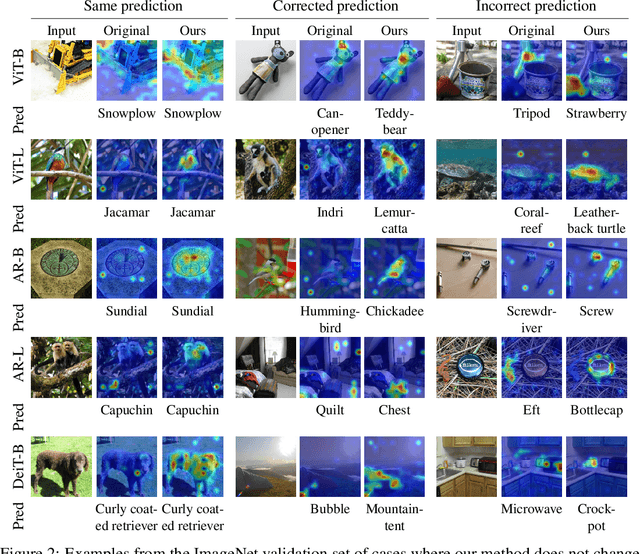
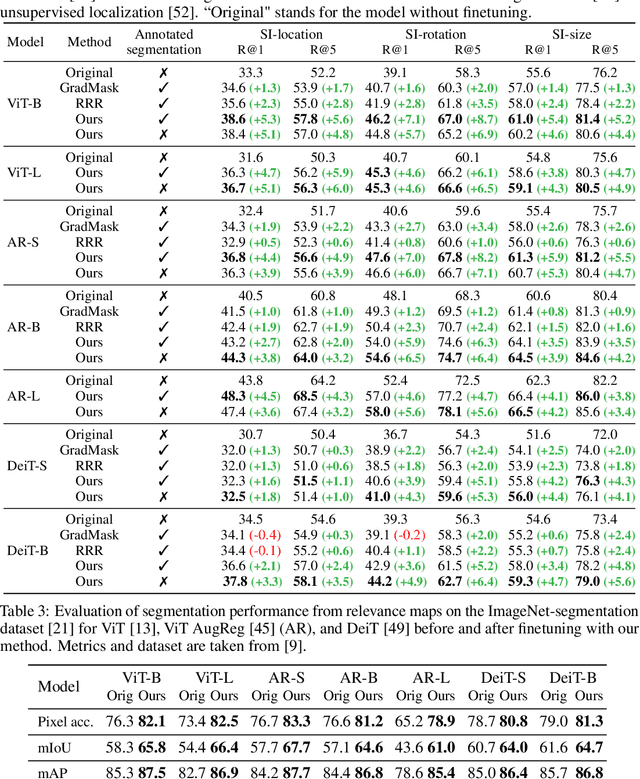
It has been observed that visual classification models often rely mostly on the image background, neglecting the foreground, which hurts their robustness to distribution changes. To alleviate this shortcoming, we propose to monitor the model's relevancy signal and manipulate it such that the model is focused on the foreground object. This is done as a finetuning step, involving relatively few samples consisting of pairs of images and their associated foreground masks. Specifically, we encourage the model's relevancy map (i) to assign lower relevance to background regions, (ii) to consider as much information as possible from the foreground, and (iii) we encourage the decisions to have high confidence. When applied to Vision Transformer (ViT) models, a marked improvement in robustness to domain shifts is observed. Moreover, the foreground masks can be obtained automatically, from a self-supervised variant of the ViT model itself; therefore no additional supervision is required.
No Token Left Behind: Explainability-Aided Image Classification and Generation
Apr 11, 2022
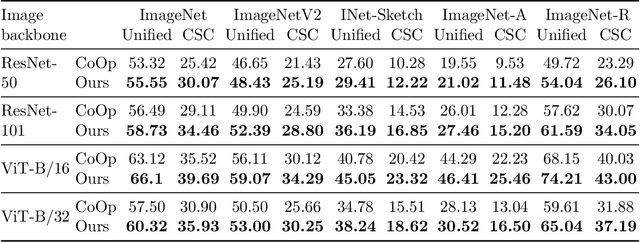


The application of zero-shot learning in computer vision has been revolutionized by the use of image-text matching models. The most notable example, CLIP, has been widely used for both zero-shot classification and guiding generative models with a text prompt. However, the zero-shot use of CLIP is unstable with respect to the phrasing of the input text, making it necessary to carefully engineer the prompts used. We find that this instability stems from a selective similarity score, which is based only on a subset of the semantically meaningful input tokens. To mitigate it, we present a novel explainability-based approach, which adds a loss term to ensure that CLIP focuses on all relevant semantic parts of the input, in addition to employing the CLIP similarity loss used in previous works. When applied to one-shot classification through prompt engineering, our method yields an improvement in the recognition rate, without additional training or fine-tuning. Additionally, we show that CLIP guidance of generative models using our method significantly improves the generated images. Finally, we demonstrate a novel use of CLIP guidance for text-based image generation with spatial conditioning on object location, by requiring the image explainability heatmap for each object to be confined to a pre-determined bounding box.
Image-Based CLIP-Guided Essence Transfer
Oct 26, 2021


The conceptual blending of two signals is a semantic task that may underline both creativity and intelligence. We propose to perform such blending in a way that incorporates two latent spaces: that of the generator network and that of the semantic network. For the first network, we employ the powerful StyleGAN generator, and for the second, the powerful image-language matching network of CLIP. The new method creates a blending operator that is optimized to be simultaneously additive in both latent spaces. Our results demonstrate that this leads to blending that is much more natural than what can be obtained in each space separately.