 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempoControl: Temporal Attention Guidance for Text-to-Video Models
Oct 02, 2025Recent advances in generative video models have enabled the creation of high-quality videos based on natural language prompts. However, these models frequently lack fine-grained temporal control, meaning they do not allow users to specify when particular visual elements should appear within a generated sequence. In this work, we introduce TempoControl, a method that allows for temporal alignment of visual concepts during inference, without requiring retraining or additional supervision. TempoControl utilizes cross-attention maps, a key component of text-to-video diffusion models, to guide the timing of concepts through a novel optimization approach. Our method steers attention using three complementary principles: aligning its temporal shape with a control signal (via correlation), amplifying it where visibility is needed (via energy), and maintaining spatial focus (via entropy). TempoControl allows precise control over timing while ensuring high video quality and diversity. We demonstrate its effectiveness across various video generation applications, including temporal reordering for single and multiple objects, as well as action and audio-aligned generation.
Single Image Iterative Subject-driven Generation and Editing
Mar 20, 2025



Personalizing image generation and editing is particularly challenging when we only have a few images of the subject, or even a single image. A common approach to personalization is concept learning, which can integrate the subject into existing models relatively quickly, but produces images whose quality tends to deteriorate quickly when the number of subject images is small. Quality can be improved by pre-training an encoder, but training restricts generation to the training distribution, and is time consuming. It is still an open hard challenge to personalize image generation and editing from a single image without training. Here, we present SISO, a novel, training-free approach based on optimizing a similarity score with an input subject image. More specifically, SISO iteratively generates images and optimizes the model based on loss of similarity with the given subject image until a satisfactory level of similarity is achieved, allowing plug-and-play optimization to any image generator. We evaluated SISO in two tasks, image editing and image generation, using a diverse data set of personal subjects, and demonstrate significant improvements over existing methods in image quality, subject fidelity, and background preservation.
Iterative Object Count Optimization for Text-to-image Diffusion Models
Aug 21, 2024



We address a persistent challenge in text-to-image models: accurately generating a specified number of objects. Current models, which learn from image-text pairs, inherently struggle with counting, as training data cannot depict every possible number of objects for any given object. To solve this, we propose optimizing the generated image based on a counting loss derived from a counting model that aggregates an object\'s potential. Employing an out-of-the-box counting model is challenging for two reasons: first, the model requires a scaling hyperparameter for the potential aggregation that varies depending on the viewpoint of the objects, and second, classifier guidance techniques require modified models that operate on noisy intermediate diffusion steps. To address these challenges, we propose an iterated online training mode that improves the accuracy of inferred images while altering the text conditioning embedding and dynamically adjusting hyperparameters. Our method offers three key advantages: (i) it can consider non-derivable counting techniques based on detection models, (ii) it is a zero-shot plug-and-play solution facilitating rapid changes to the counting techniques and image generation methods, and (iii) the optimized counting token can be reused to generate accurate images without additional optimization. We evaluate the generation of various objects and show significant improvements in accuracy. The project page is available at https://ozzafar.github.io/count_token.
Improving Visual Commonsense in Language Models via Multiple Image Generation
Jun 19, 2024



Commonsense reasoning is fundamentally based on multimodal knowledge. However, existing large language models (LLMs) are primarily trained using textual data only, limiting their ability to incorporate essential visual information. In contrast, Visual Language Models, which excel at visually-oriented tasks, often fail at non-visual tasks such as basic commonsense reasoning. This divergence highlights a critical challenge - the integration of robust visual understanding with foundational text-based language reasoning. To this end, we introduce a method aimed at enhancing LLMs' visual commonsense. Specifically, our method generates multiple images based on the input text prompt and integrates these into the model's decision-making process by mixing their prediction probabilities. To facilitate multimodal grounded language modeling, we employ a late-fusion layer that combines the projected visual features with the output of a pre-trained LLM conditioned on text only. This late-fusion layer enables predictions based on comprehensive image-text knowledge as well as text only when this is required. We evaluate our approach using several visual commonsense reasoning tasks together with traditional NLP tasks, including common sense reasoning and reading comprehension. Our experimental results demonstrate significant superiority over existing baselines. When applied to recent state-of-the-art LLMs (e.g., Llama3), we observe improvements not only in visual common sense but also in traditional NLP benchmarks. Code and models are available under https://github.com/guyyariv/vLMIG.
Diverse and Aligned Audio-to-Video Generation via Text-to-Video Model Adaptation
Sep 28, 2023



We consider the task of generating diverse and realistic videos guided by natural audio samples from a wide variety of semantic classes. For this task, the videos are required to be aligned both globally and temporally with the input audio: globally, the input audio is semantically associated with the entire output video, and temporally, each segment of the input audio is associated with a corresponding segment of that video. We utilize an existing text-conditioned video generation model and a pre-trained audio encoder model. The proposed method is based on a lightweight adaptor network, which learns to map the audio-based representation to the input representation expected by the text-to-video generation model. As such, it also enables video generation conditioned on text, audio, and, for the first time as far as we can ascertain, on both text and audio. We validate our method extensively on three datasets demonstrating significant semantic diversity of audio-video samples and further propose a novel evaluation metric (AV-Align) to assess the alignment of generated videos with input audio samples. AV-Align is based on the detection and comparison of energy peaks in both modalities. In comparison to recent state-of-the-art approaches, our method generates videos that are better aligned with the input sound, both with respect to content and temporal axis. We also show that videos produced by our method present higher visual quality and are more diverse.
AudioToken: Adaptation of Text-Conditioned Diffusion Models for Audio-to-Image Generation
May 22, 2023In recent years, image generation has shown a great leap in performance, where diffusion models play a central role. Although generating high-quality images, such models are mainly conditioned on textual descriptions. This begs the question: "how can we adopt such models to be conditioned on other modalities?". In this paper, we propose a novel method utilizing latent diffusion models trained for text-to-image-generation to generate images conditioned on audio recordings. Using a pre-trained audio encoding model, the proposed method encodes audio into a new token, which can be considered as an adaptation layer between the audio and text representations. Such a modeling paradigm requires a small number of trainable parameters, making the proposed approach appealing for lightweight optimization. Results suggest the proposed method is superior to the evaluated baseline methods, considering objective and subjective metrics. Code and samples are available at: https://pages.cs.huji.ac.il/adiyoss-lab/AudioToken.
Discriminative Class Tokens for Text-to-Image Diffusion Models
Mar 30, 2023Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. However, generated images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This comes with a downside, doing so limits their expressive power: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, and so the quality and diversity of generated images are severely affected, or (ii) the input is a hard-coded label, as opposed to free-form text, which limits the control over the generated images. In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier. The code is available at \url{https://github.com/idansc/discriminative_class_tokens}
Zero-Shot Video Captioning with Evolving Pseudo-Tokens
Jul 27, 2022
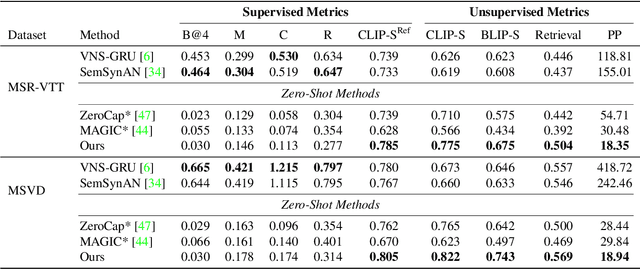
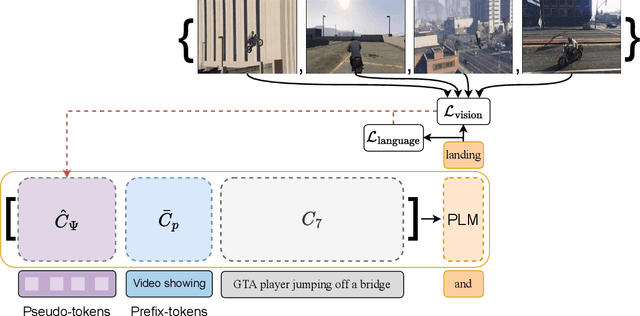
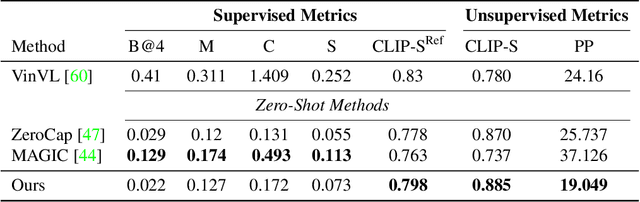
We introduce a zero-shot video captioning method that employs two frozen networks: the GPT-2 language model and the CLIP image-text matching model. The matching score is used to steer the language model toward generating a sentence that has a high average matching score to a subset of the video frames. Unlike zero-shot image captioning methods, our work considers the entire sentence at once. This is achieved by optimizing, during the generation process, part of the prompt from scratch, by modifying the representation of all other tokens in the prompt, and by repeating the process iteratively, gradually improving the specificity and comprehensiveness of the generated sentence. Our experiments show that the generated captions are coherent and display a broad range of real-world knowledge. Our code is available at: https://github.com/YoadTew/zero-shot-video-to-text
Optimizing Relevance Maps of Vision Transformers Improves Robustness
Jun 02, 2022
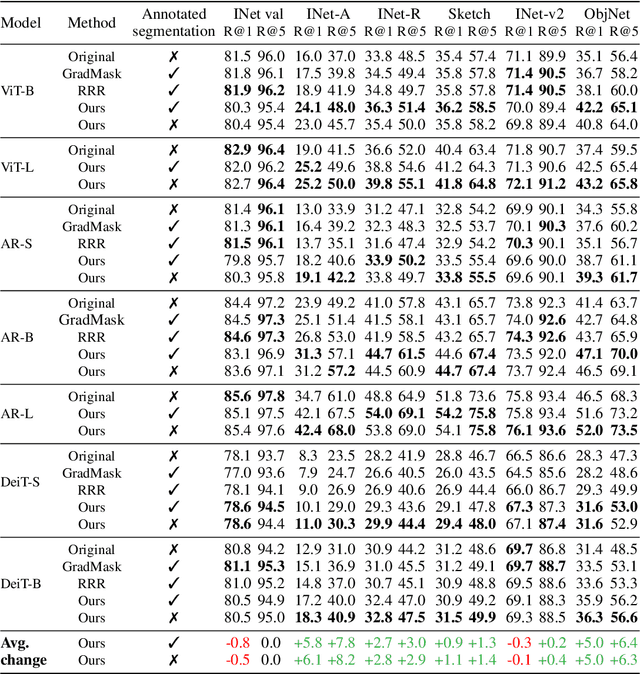
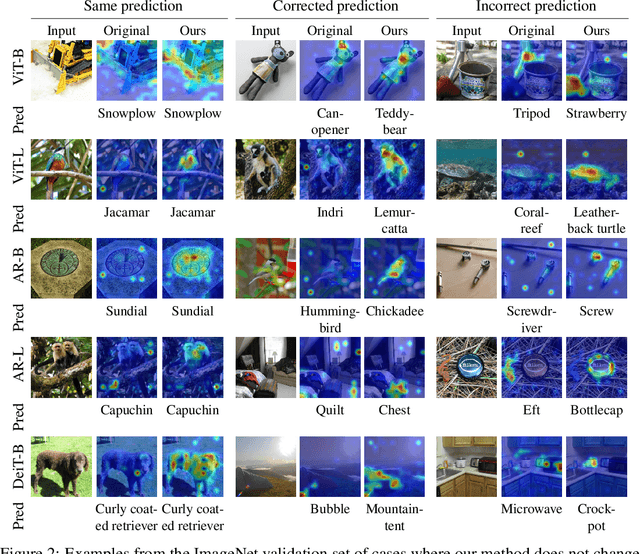
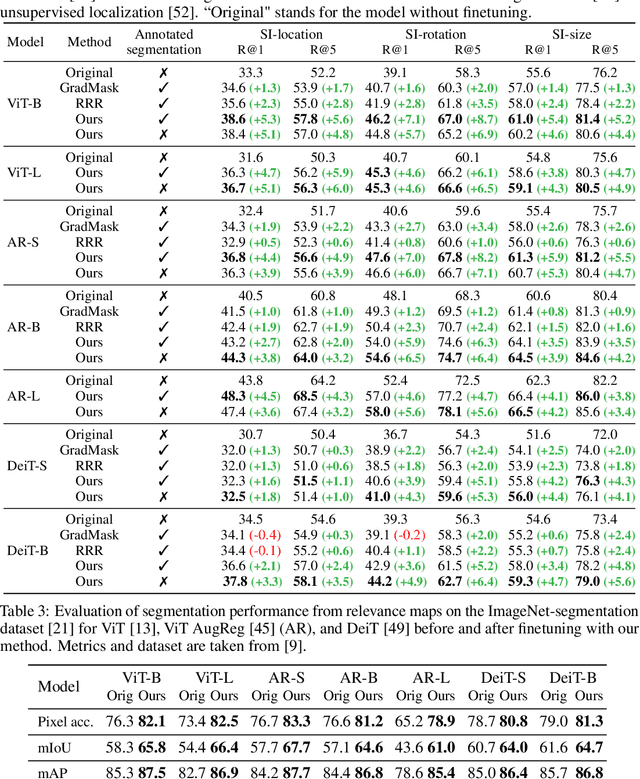
It has been observed that visual classification models often rely mostly on the image background, neglecting the foreground, which hurts their robustness to distribution changes. To alleviate this shortcoming, we propose to monitor the model's relevancy signal and manipulate it such that the model is focused on the foreground object. This is done as a finetuning step, involving relatively few samples consisting of pairs of images and their associated foreground masks. Specifically, we encourage the model's relevancy map (i) to assign lower relevance to background regions, (ii) to consider as much information as possible from the foreground, and (iii) we encourage the decisions to have high confidence. When applied to Vision Transformer (ViT) models, a marked improvement in robustness to domain shifts is observed. Moreover, the foreground masks can be obtained automatically, from a self-supervised variant of the ViT model itself; therefore no additional supervision is required.
Latent Space Explanation by Intervention
Dec 09, 2021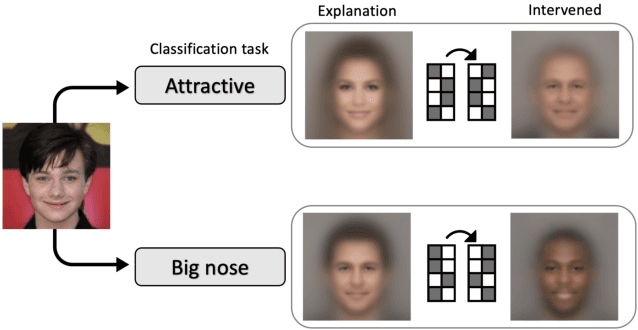
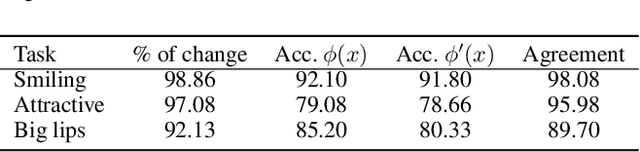
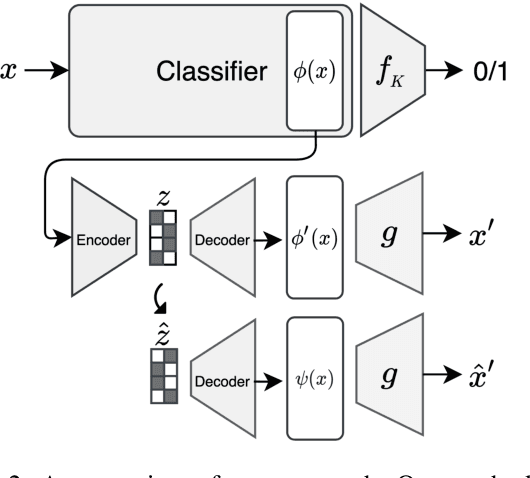

The success of deep neural nets heavily relies on their ability to encode complex relations between their input and their output. While this property serves to fit the training data well, it also obscures the mechanism that drives prediction. This study aims to reveal hidden concepts by employing an intervention mechanism that shifts the predicted class based on discrete variational autoencoders. An explanatory model then visualizes the encoded information from any hidden layer and its corresponding intervened representation. By the assessment of differences between the original representation and the intervened representation, one can determine the concepts that can alter the class, hence providing interpretability. We demonstrate the effectiveness of our approach on CelebA, where we show various visualizations for bias in the data and suggest different interventions to reveal and change bias.