 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Potential of BERTopic for Multilingual Fake News Analysis -- Use Case: Covid-19
Jul 11, 2024



Topic modeling is frequently being used for analysing large text corpora such as news articles or social media data. BERTopic, consisting of sentence embedding, dimension reduction, clustering, and topic extraction, is the newest and currently the SOTA topic modeling method. However, current topic modeling methods have room for improvement because, as unsupervised methods, they require careful tuning and selection of hyperparameters, e.g., for dimension reduction and clustering. This paper aims to analyse the technical application of BERTopic in practice. For this purpose, it compares and selects different methods and hyperparameters for each stage of BERTopic through density based clustering validation and six different topic coherence measures. Moreover, it also aims to analyse the results of topic modeling on real world data as a use case. For this purpose, the German fake news dataset (GermanFakeNCovid) on Covid-19 was created by us and in order to experiment with topic modeling in a multilingual (English and German) setting combined with the FakeCovid dataset. With the final results, we were able to determine thematic similarities between the United States and Germany. Whereas, distinguishing the topics of fake news from India proved to be more challenging.
Fraunhofer SIT at CheckThat! 2023: Tackling Classification Uncertainty Using Model Souping on the Example of Check-Worthiness Classification
Jul 03, 2023



This paper describes the second-placed approach developed by the Fraunhofer SIT team in the CLEF-2023 CheckThat! lab Task 1B for English. Given a text snippet from a political debate, the aim of this task is to determine whether it should be assessed for check-worthiness. Detecting check-worthy statements aims to facilitate manual fact-checking efforts by prioritizing the claims that fact-checkers should consider first. It can also be considered as primary step of a fact-checking system. Our best-performing method took advantage of an ensemble classification scheme centered on Model Souping. When applied to the English data set, our submitted model achieved an overall F1 score of 0.878 and was ranked as the second-best model in the competition.
* 9 pages
Fraunhofer SIT at CheckThat! 2023: Mixing Single-Modal Classifiers to Estimate the Check-Worthiness of Multi-Modal Tweets
Jul 02, 2023



The option of sharing images, videos and audio files on social media opens up new possibilities for distinguishing between false information and fake news on the Internet. Due to the vast amount of data shared every second on social media, not all data can be verified by a computer or a human expert. Here, a check-worthiness analysis can be used as a first step in the fact-checking pipeline and as a filtering mechanism to improve efficiency. This paper proposes a novel way of detecting the check-worthiness in multi-modal tweets. It takes advantage of two classifiers, each trained on a single modality. For image data, extracting the embedded text with an OCR analysis has shown to perform best. By combining the two classifiers, the proposed solution was able to place first in the CheckThat! 2023 Task 1A with an F1 score of 0.7297 achieved on the private test set.
* 8 pages
Fake News Spreader Detection on Twitter using Character N-Grams. Notebook for PAN at CLEF 2020
Sep 29, 2020
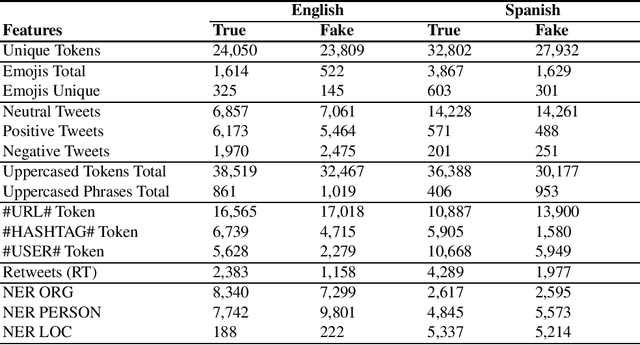


The authors of fake news often use facts from verified news sources and mix them with misinformation to create confusion and provoke unrest among the readers. The spread of fake news can thereby have serious implications on our society. They can sway political elections, push down the stock price or crush reputations of corporations or public figures. Several websites have taken on the mission of checking rumors and allegations, but are often not fast enough to check the content of all the news being disseminated. Especially social media websites have offered an easy platform for the fast propagation of information. Towards limiting fake news from being propagated among social media users, the task of this year's PAN 2020 challenge lays the focus on the fake news spreaders. The aim of the task is to determine whether it is possible to discriminate authors that have shared fake news in the past from those that have never done it. In this notebook, we describe our profiling system for the fake news detection task on Twitter. For this, we conduct different feature extraction techniques and learning experiments from a multilingual perspective, namely English and Spanish. Our final submitted systems use character n-grams as features in combination with a linear SVM for English and Logistic Regression for the Spanish language. Our submitted models achieve an overall accuracy of 73% and 79% on the English and Spanish official test set, respectively. Our experiments show that it is difficult to differentiate solidly fake news spreaders on Twitter from users who share credible information leaving room for further investigations. Our model ranked 3rd out of 72 competitors.
Similarity Detection Pipeline for Crawling a Topic Related Fake News Corpus
Sep 28, 2020
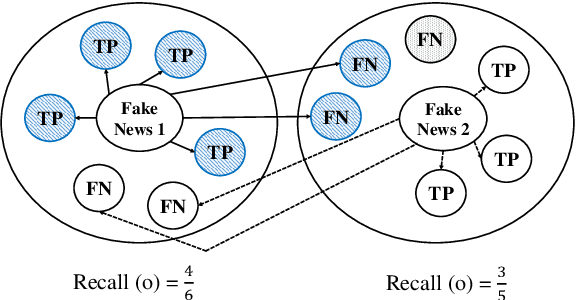
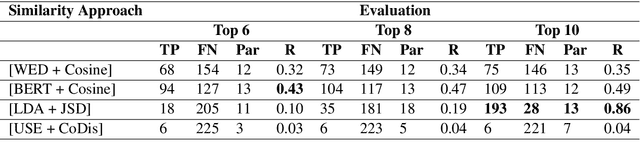
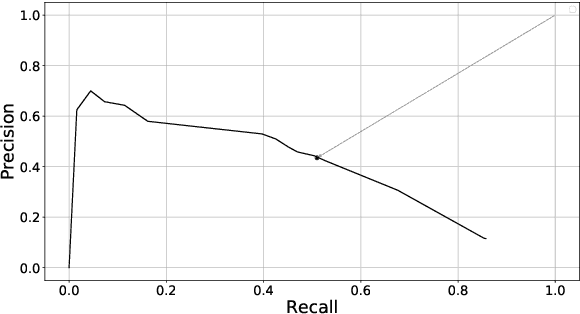
Fake news detection is a challenging task aiming to reduce human time and effort to check the truthfulness of news. Automated approaches to combat fake news, however, are limited by the lack of labeled benchmark datasets, especially in languages other than English. Moreover, many publicly available corpora have specific limitations that make them difficult to use. To address this problem, our contribution is threefold. First, we propose a new, publicly available German topic related corpus for fake news detection. To the best of our knowledge, this is the first corpus of its kind. In this regard, we developed a pipeline for crawling similar news articles. As our third contribution, we conduct different learning experiments to detect fake news. The best performance was achieved using sentence level embeddings from SBERT in combination with a Bi-LSTM (k=0.88).