 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Apr 18, 2023
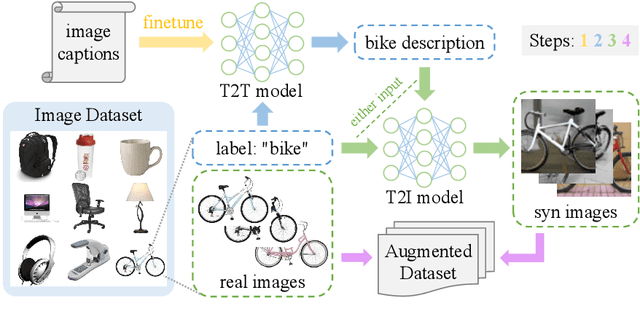
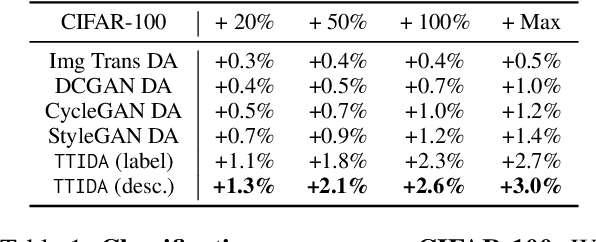
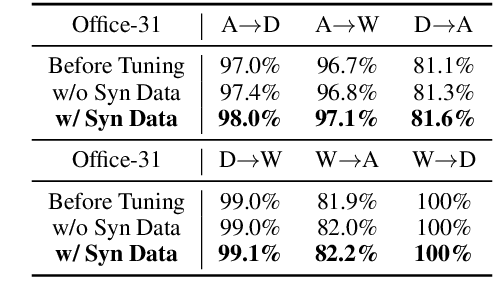
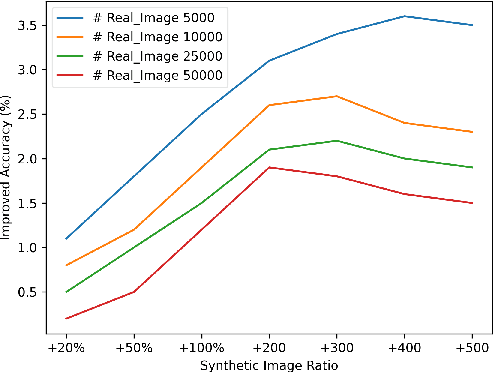
Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.
Promptify: Text-to-Image Generation through Interactive Prompt Exploration with Large Language Models
Apr 18, 2023
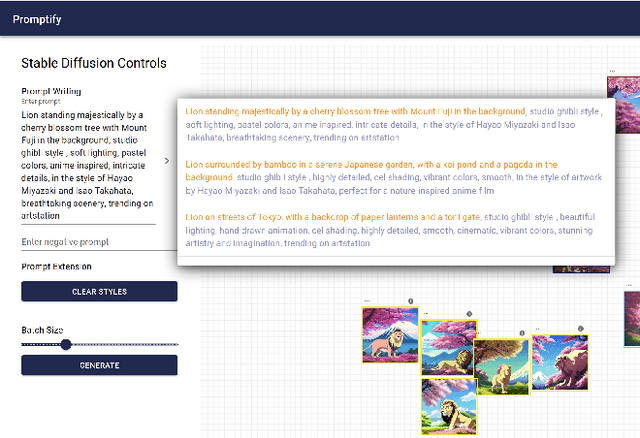

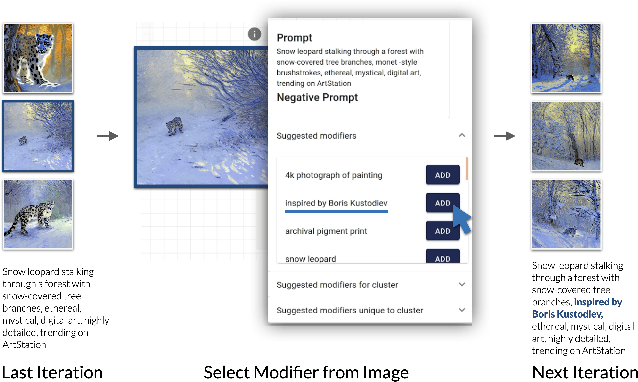
Text-to-image generative models have demonstrated remarkable capabilities in generating high-quality images based on textual prompts. However, crafting prompts that accurately capture the user's creative intent remains challenging. It often involves laborious trial-and-error procedures to ensure that the model interprets the prompts in alignment with the user's intention. To address the challenges, we present Promptify, an interactive system that supports prompt exploration and refinement for text-to-image generative models. Promptify utilizes a suggestion engine powered by large language models to help users quickly explore and craft diverse prompts. Our interface allows users to organize the generated images flexibly, and based on their preferences, Promptify suggests potential changes to the original prompt. This feedback loop enables users to iteratively refine their prompts and enhance desired features while avoiding unwanted ones. Our user study shows that Promptify effectively facilitates the text-to-image workflow and outperforms an existing baseline tool widely used for text-to-image generation.
SLIC: Self-Conditioned Adaptive Transform with Large-Scale Receptive Fields for Learned Image Compression
Apr 19, 2023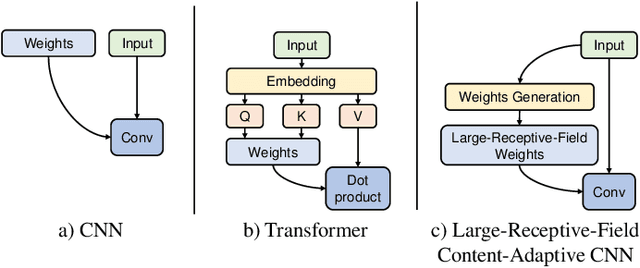
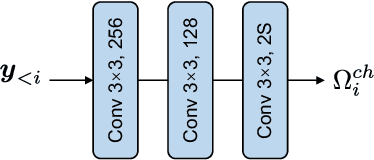
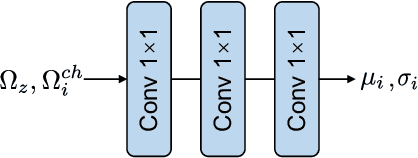
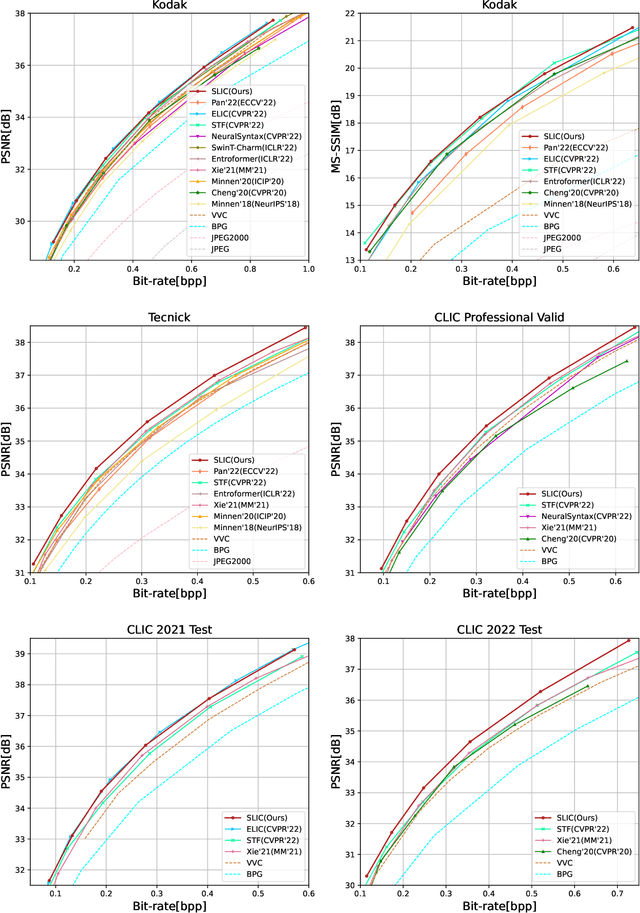
Learned image compression has achieved remarkable performance. Transform, plays an important role in boosting the RD performance. Analysis transform converts the input image to a compact latent representation. The more compact the latent representation is, the fewer bits we need to compress it. When designing better transform, some previous works adopt Swin-Transformer. The success of the Swin-Transformer in image compression can be attributed to the dynamic weights and large receptive field.However,the LayerNorm adopted in transformers is not suitable for image compression.We find CNN-based modules can also be dynamic and have large receptive-fields. The CNN-based modules can also work with GDN/IGDN. To make the CNN-based modules dynamic, we generate the weights of kernels conditioned on the input feature. We scale up the size of each kernel for larger receptive fields. To reduce complexity, we make the CNN-module channel-wise connected. We call this module Dynamic Depth-wise convolution. We replace the self-attention module with the proposed Dynamic Depth-wise convolution, replace the embedding layer with a depth-wise residual bottleneck for non-linearity and replace the FFN layer with an inverted residual bottleneck for more interactions in the spatial domain. The interactions among channels of dynamic depth-wise convolution are limited. We design the other block, which replaces the dynamic depth-wise convolution with channel attention. We equip the proposed modules in the analysis and synthesis transform and receive a more compact latent representation and propose the learned image compression model SLIC, meaning Self-Conditioned Adaptive Transform with Large-Scale Receptive Fields for Learned Image Compression Learned Image Compression. Thanks to the proposed transform modules, our proposed SLIC achieves 6.35% BD-rate reduction over VVC when measured in PSNR on Kodak dataset.
Machine learning for option pricing: an empirical investigation of network architectures
Jul 14, 2023We consider the supervised learning problem of learning the price of an option or the implied volatility given appropriate input data (model parameters) and corresponding output data (option prices or implied volatilities). The majority of articles in this literature considers a (plain) feed forward neural network architecture in order to connect the neurons used for learning the function mapping inputs to outputs. In this article, motivated by methods in image classification and recent advances in machine learning methods for PDEs, we investigate empirically whether and how the choice of network architecture affects the accuracy and training time of a machine learning algorithm. We find that for option pricing problems, where we focus on the Black--Scholes and the Heston model, the generalized highway network architecture outperforms all other variants, when considering the mean squared error and the training time as criteria. Moreover, for the computation of the implied volatility, after a necessary transformation, a variant of the DGM architecture outperforms all other variants, when considering again the mean squared error and the training time as criteria.
L-DAWA: Layer-wise Divergence Aware Weight Aggregation in Federated Self-Supervised Visual Representation Learning
Jul 14, 2023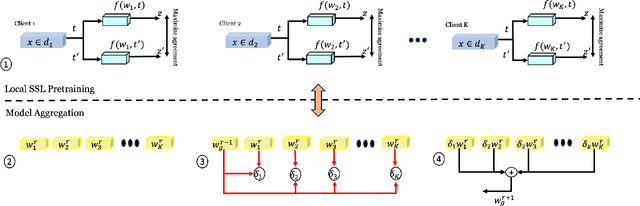
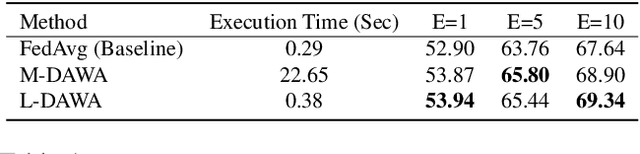
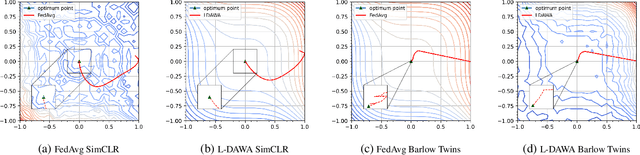
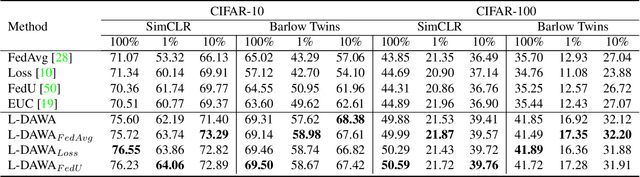
The ubiquity of camera-enabled devices has led to large amounts of unlabeled image data being produced at the edge. The integration of self-supervised learning (SSL) and federated learning (FL) into one coherent system can potentially offer data privacy guarantees while also advancing the quality and robustness of the learned visual representations without needing to move data around. However, client bias and divergence during FL aggregation caused by data heterogeneity limits the performance of learned visual representations on downstream tasks. In this paper, we propose a new aggregation strategy termed Layer-wise Divergence Aware Weight Aggregation (L-DAWA) to mitigate the influence of client bias and divergence during FL aggregation. The proposed method aggregates weights at the layer-level according to the measure of angular divergence between the clients' model and the global model. Extensive experiments with cross-silo and cross-device settings on CIFAR-10/100 and Tiny ImageNet datasets demonstrate that our methods are effective and obtain new SOTA performance on both contrastive and non-contrastive SSL approaches.
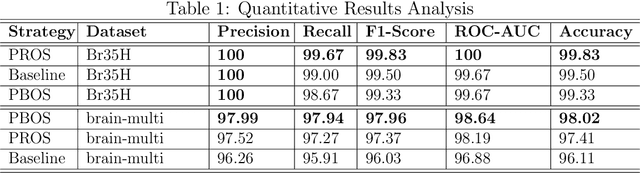
See Through the Fog: Curriculum Learning with Progressive Occlusion in Medical Imaging
Jun 30, 2023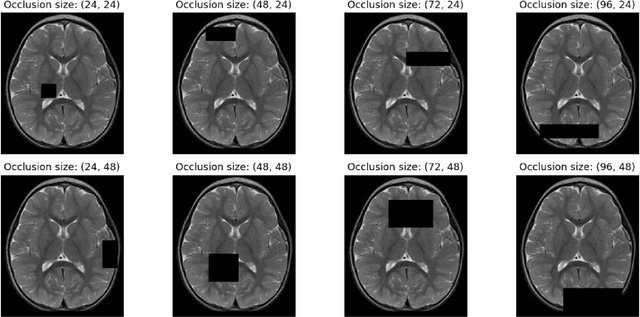
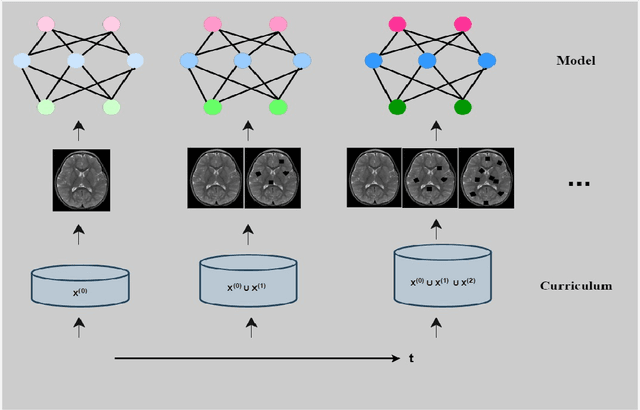
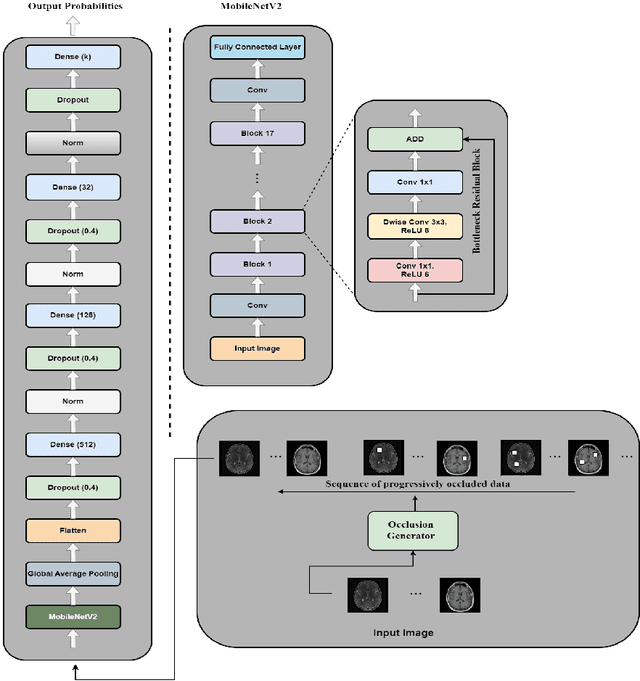
In recent years, deep learning models have revolutionized medical image interpretation, offering substantial improvements in diagnostic accuracy. However, these models often struggle with challenging images where critical features are partially or fully occluded, which is a common scenario in clinical practice. In this paper, we propose a novel curriculum learning-based approach to train deep learning models to handle occluded medical images effectively. Our method progressively introduces occlusion, starting from clear, unobstructed images and gradually moving to images with increasing occlusion levels. This ordered learning process, akin to human learning, allows the model to first grasp simple, discernable patterns and subsequently build upon this knowledge to understand more complicated, occluded scenarios. Furthermore, we present three novel occlusion synthesis methods, namely Wasserstein Curriculum Learning (WCL), Information Adaptive Learning (IAL), and Geodesic Curriculum Learning (GCL). Our extensive experiments on diverse medical image datasets demonstrate substantial improvements in model robustness and diagnostic accuracy over conventional training methodologies.
RetinexFlow for CT metal artifact reduction
Jun 18, 2023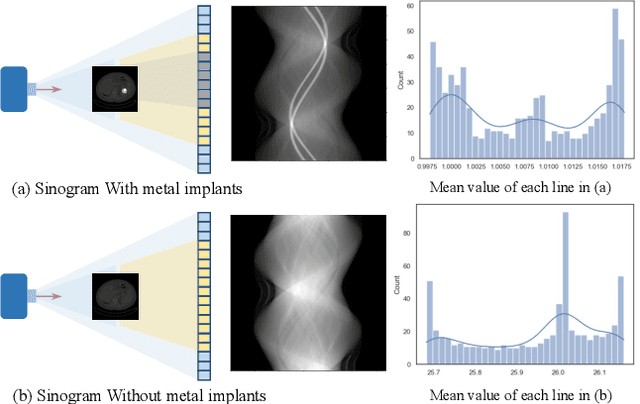
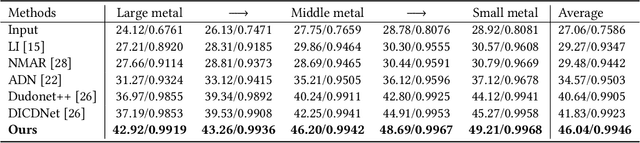
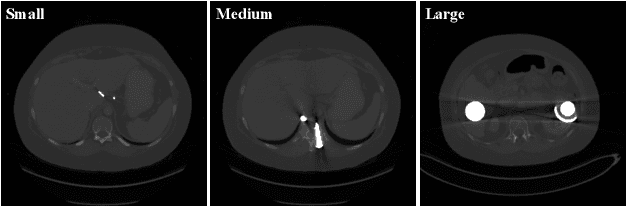
Metal artifacts is a major challenge in computed tomography (CT) imaging, significantly degrading image quality and making accurate diagnosis difficult. However, previous methods either require prior knowledge of the location of metal implants, or have modeling deviations with the mechanism of artifact formation, which limits the ability to obtain high-quality CT images. In this work, we formulate metal artifacts reduction problem as a combination of decomposition and completion tasks. And we propose RetinexFlow, which is a novel end-to-end image domain model based on Retinex theory and conditional normalizing flow, to solve it. Specifically, we first design a feature decomposition encoder for decomposing the metal implant component and inherent component, and extracting the inherent feature. Then, it uses a feature-to-image flow module to complete the metal artifact-free CT image step by step through a series of invertible transformations. These designs are incorporated in our model with a coarse-to-fine strategy, enabling it to achieve superior performance. The experimental results on on simulation and clinical datasets show our method achieves better quantitative and qualitative results, exhibiting better visual performance in artifact removal and image fidelity
Efficient and Explicit Modelling of Image Hierarchies for Image Restoration
Mar 01, 2023
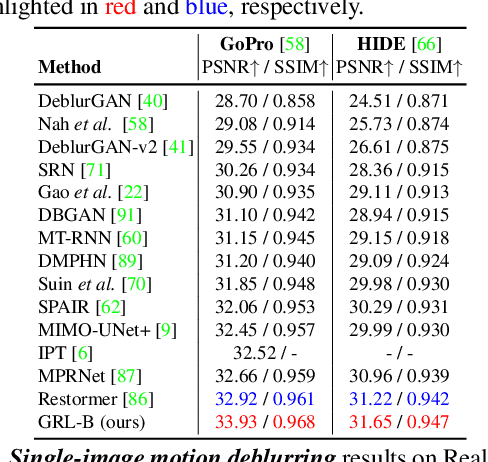

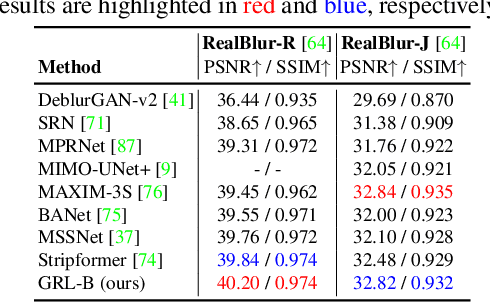
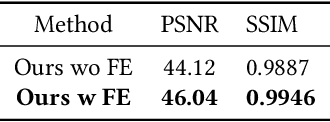
The aim of this paper is to propose a mechanism to efficiently and explicitly model image hierarchies in the global, regional, and local range for image restoration. To achieve that, we start by analyzing two important properties of natural images including cross-scale similarity and anisotropic image features. Inspired by that, we propose the anchored stripe self-attention which achieves a good balance between the space and time complexity of self-attention and the modelling capacity beyond the regional range. Then we propose a new network architecture dubbed GRL to explicitly model image hierarchies in the Global, Regional, and Local range via anchored stripe self-attention, window self-attention, and channel attention enhanced convolution. Finally, the proposed network is applied to 7 image restoration types, covering both real and synthetic settings. The proposed method sets the new state-of-the-art for several of those. Code will be available at https://github.com/ofsoundof/GRL-Image-Restoration.git.
Robust Semantic Segmentation: Strong Adversarial Attacks and Fast Training of Robust Models
Jun 22, 2023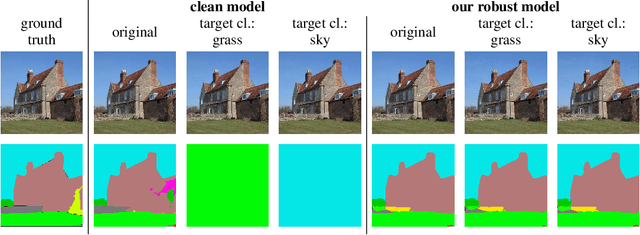
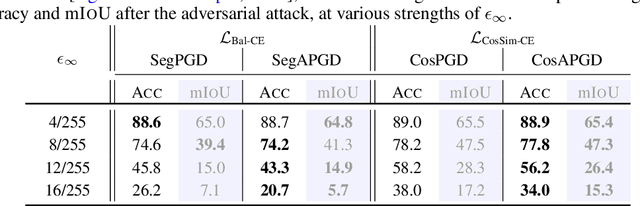
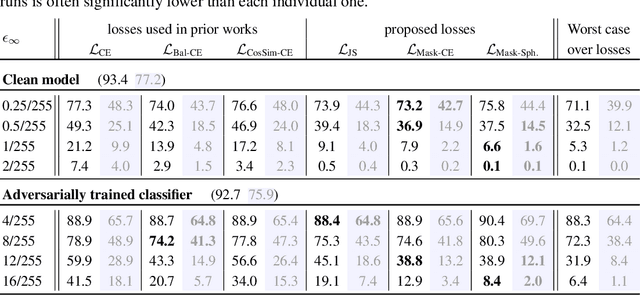
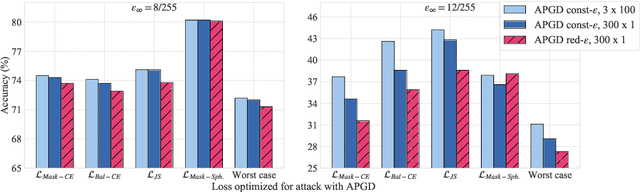
While a large amount of work has focused on designing adversarial attacks against image classifiers, only a few methods exist to attack semantic segmentation models. We show that attacking segmentation models presents task-specific challenges, for which we propose novel solutions. Our final evaluation protocol outperforms existing methods, and shows that those can overestimate the robustness of the models. Additionally, so far adversarial training, the most successful way for obtaining robust image classifiers, could not be successfully applied to semantic segmentation. We argue that this is because the task to be learned is more challenging, and requires significantly higher computational effort than for image classification. As a remedy, we show that by taking advantage of recent advances in robust ImageNet classifiers, one can train adversarially robust segmentation models at limited computational cost by fine-tuning robust backbones.
RaViTT: Random Vision Transformer Tokens
Jun 19, 2023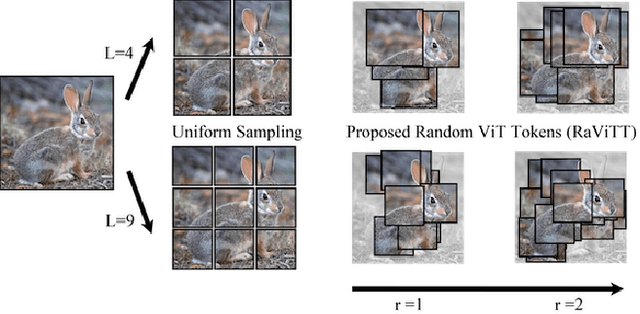
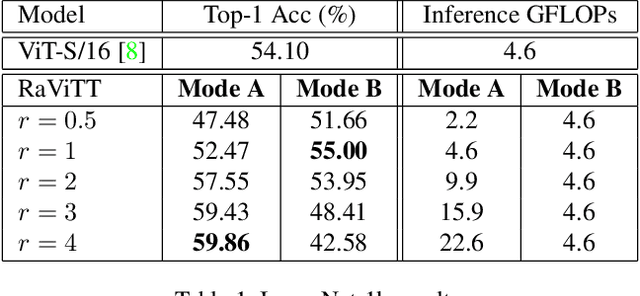
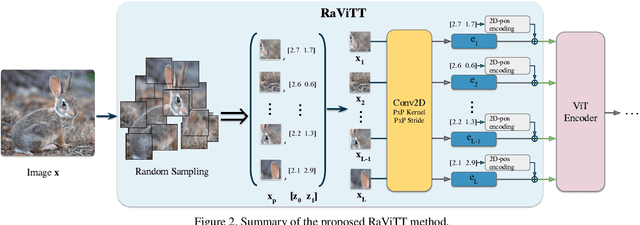
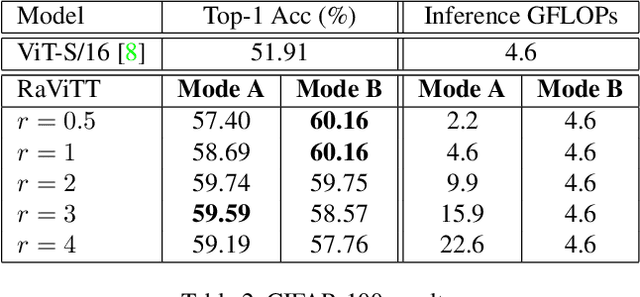
Vision Transformers (ViTs) have successfully been applied to image classification problems where large annotated datasets are available. On the other hand, when fewer annotations are available, such as in biomedical applications, image augmentation techniques like introducing image variations or combinations have been proposed. However, regarding ViT patch sampling, less has been explored outside grid-based strategies. In this work, we propose Random Vision Transformer Tokens (RaViTT), a random patch sampling strategy that can be incorporated into existing ViTs. We experimentally evaluated RaViTT for image classification, comparing it with a baseline ViT and state-of-the-art (SOTA) augmentation techniques in 4 datasets, including ImageNet-1k and CIFAR-100. Results show that RaViTT increases the accuracy of the baseline in all datasets and outperforms the SOTA augmentation techniques in 3 out of 4 datasets by a significant margin +1.23% to +4.32%. Interestingly, RaViTT accuracy improvements can be achieved even with fewer tokens, thus reducing the computational load of any ViT model for a given accuracy value.