 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Histogram-guided Video Colorization Structure with Spatial-Temporal Connection
Aug 09, 2023
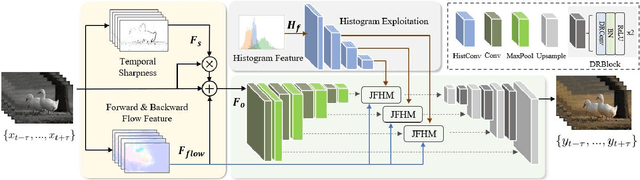
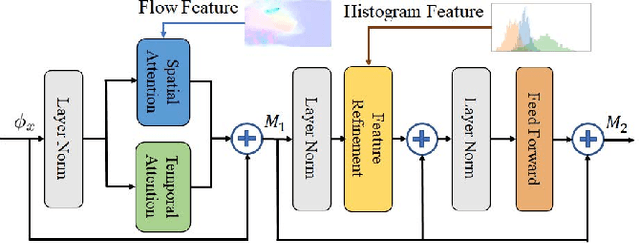

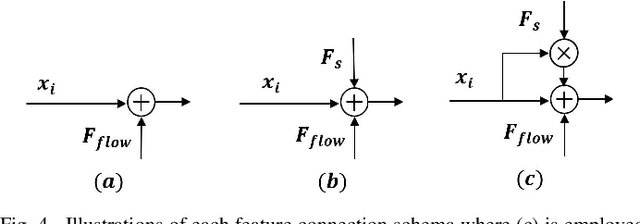
Video colorization, aiming at obtaining colorful and plausible results from grayish frames, has aroused a lot of interest recently. Nevertheless, how to maintain temporal consistency while keeping the quality of colorized results remains challenging. To tackle the above problems, we present a Histogram-guided Video Colorization with Spatial-Temporal connection structure (named ST-HVC). To fully exploit the chroma and motion information, the joint flow and histogram module is tailored to integrate the histogram and flow features. To manage the blurred and artifact, we design a combination scheme attending to temporal detail and flow feature combination. We further recombine the histogram, flow and sharpness features via a U-shape network. Extensive comparisons are conducted with several state-of-the-art image and video-based methods, demonstrating that the developed method achieves excellent performance both quantitatively and qualitatively in two video datasets.
Multi-Scale Memory Comparison for Zero-/Few-Shot Anomaly Detection
Aug 09, 2023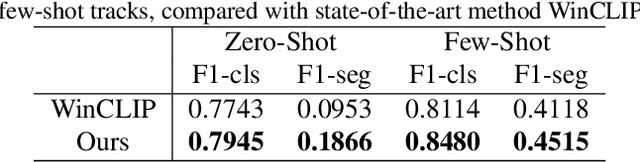
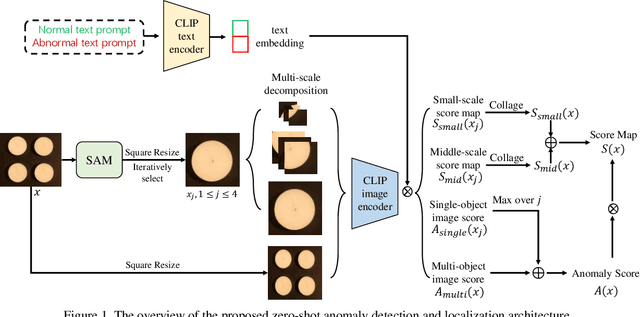
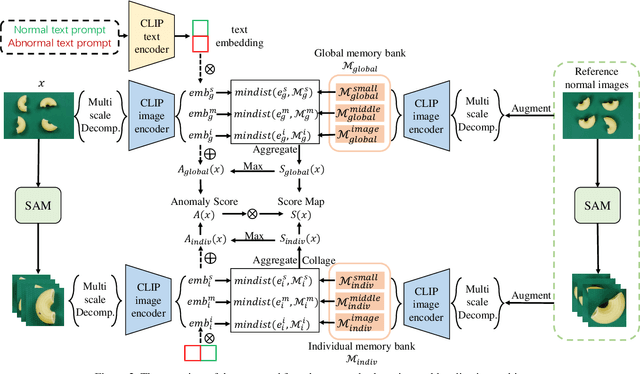

Anomaly detection has gained considerable attention due to its broad range of applications, particularly in industrial defect detection. To address the challenges of data collection, researchers have introduced zero-/few-shot anomaly detection techniques that require minimal normal images for each category. However, complex industrial scenarios often involve multiple objects, presenting a significant challenge. In light of this, we propose a straightforward yet powerful multi-scale memory comparison framework for zero-/few-shot anomaly detection. Our approach employs a global memory bank to capture features across the entire image, while an individual memory bank focuses on simplified scenes containing a single object. The efficacy of our method is validated by its remarkable achievement of 4th place in the zero-shot track and 2nd place in the few-shot track of the Visual Anomaly and Novelty Detection (VAND) competition.
Multi-level Cross-modal Feature Alignment via Contrastive Learning towards Zero-shot Classification of Remote Sensing Image Scenes
May 31, 2023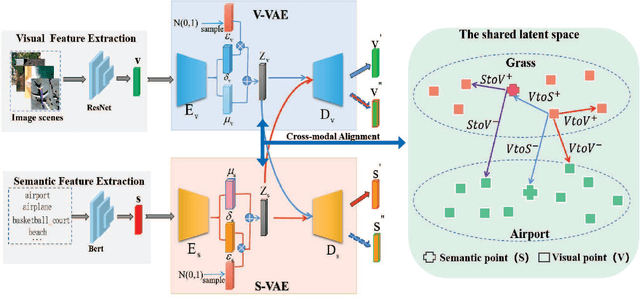

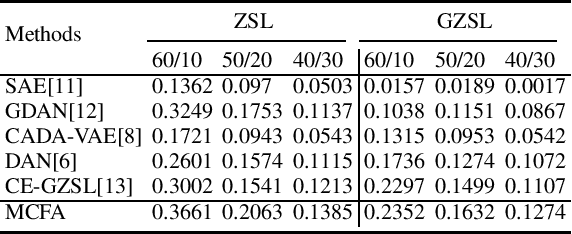

Zero-shot classification of image scenes which can recognize the image scenes that are not seen in the training stage holds great promise of lowering the dependence on large numbers of labeled samples. To address the zero-shot image scene classification, the cross-modal feature alignment methods have been proposed in recent years. These methods mainly focus on matching the visual features of each image scene with their corresponding semantic descriptors in the latent space. Less attention has been paid to the contrastive relationships between different image scenes and different semantic descriptors. In light of the challenge of large intra-class difference and inter-class similarity among image scenes and the potential noisy samples, these methods are susceptible to the influence of the instances which are far from these of the same classes and close to these of other classes. In this work, we propose a multi-level cross-modal feature alignment method via contrastive learning for zero-shot classification of remote sensing image scenes. While promoting the single-instance level positive alignment between each image scene with their corresponding semantic descriptors, the proposed method takes the cross-instance contrastive relationships into consideration,and learns to keep the visual and semantic features of different classes in the latent space apart from each other. Extensive experiments have been done to evaluate the performance of the proposed method. The results show that our proposed method outperforms state of the art methods for zero-shot remote sensing image scene classification. All the code and data are available at github https://github.com/masuqiang/MCFA-Pytorch
HFLIC: Human Friendly Perceptual Learned Image Compression with Reinforced Transform
May 18, 2023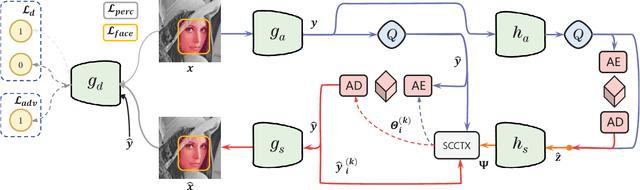
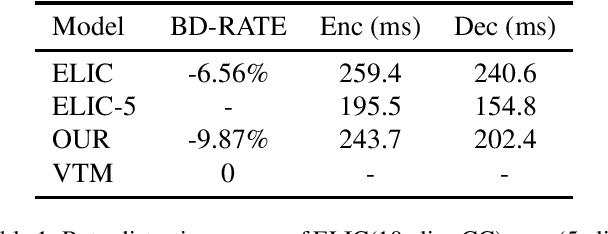
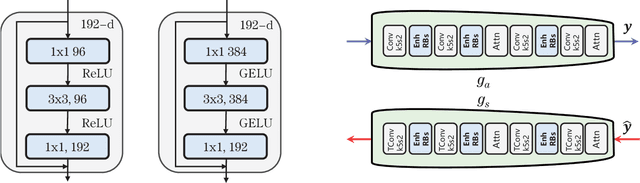
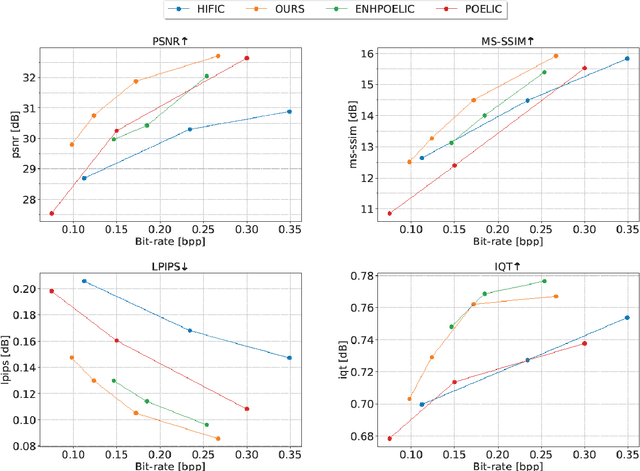
In recent years, there has been rapid development in learned image compression techniques that prioritize ratedistortion-perceptual compression, preserving fine details even at lower bit-rates. However, current learning-based image compression methods often sacrifice human-friendly compression and require long decoding times. In this paper, we propose enhancements to the backbone network and loss function of existing image compression model, focusing on improving human perception and efficiency. Our proposed approach achieves competitive subjective results compared to state-of-the-art end-to-end learned image compression methods and classic methods, while requiring less decoding time and offering human-friendly compression. Through empirical evaluation, we demonstrate the effectiveness of our proposed method in achieving outstanding performance, with more than 25% bit-rate saving at the same subjective quality.
SciRE-Solver: Efficient Sampling of Diffusion Probabilistic Models by Score-integrand Solver with Recursive Derivative Estimation
Aug 16, 2023
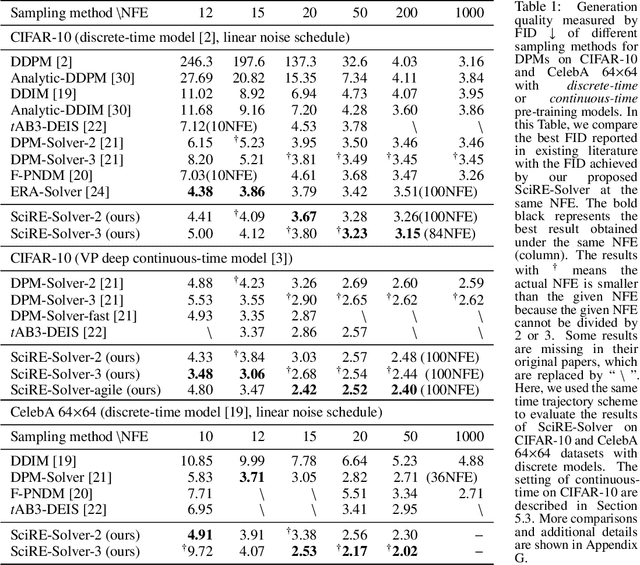
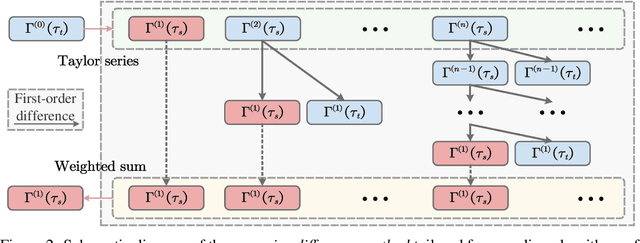
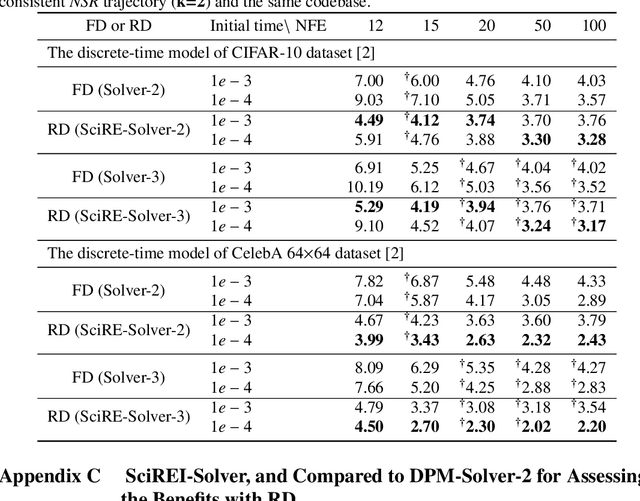
Diffusion probabilistic models (DPMs) are a powerful class of generative models known for their ability to generate high-fidelity image samples. A major challenge in the implementation of DPMs is the slow sampling process. In this work, we bring a high-efficiency sampler for DPMs. Specifically, we propose a score-based exact solution paradigm for the diffusion ODEs corresponding to the sampling process of DPMs, which introduces a new perspective on developing numerical algorithms for solving diffusion ODEs. To achieve an efficient sampler, we propose a recursive derivative estimation (RDE) method to reduce the estimation error. With our proposed solution paradigm and RDE method, we propose the score-integrand solver with the convergence order guarantee as efficient solver (SciRE-Solver) for solving diffusion ODEs. The SciRE-Solver attains state-of-the-art (SOTA) sampling performance with a limited number of score function evaluations (NFE) on both discrete-time and continuous-time DPMs in comparison to existing training-free sampling algorithms. Such as, we achieve $3.48$ FID with $12$ NFE and $2.42$ FID with $20$ NFE for continuous-time DPMs on CIFAR10, respectively. Different from other samplers, SciRE-Solver has the promising potential to surpass the FIDs achieved in the original papers of some pre-trained models with a small NFEs. For example, we reach SOTA value of $2.40$ FID with $100$ NFE for continuous-time DPM and of $3.15$ FID with $84$ NFE for discrete-time DPM on CIFAR-10, as well as of $2.17$ ($2.02$) FID with $18$ ($50$) NFE for discrete-time DPM on CelebA 64$\times$64.
Visually-Grounded Descriptions Improve Zero-Shot Image Classification
Jun 05, 2023
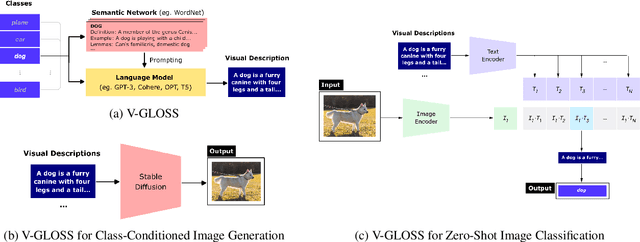

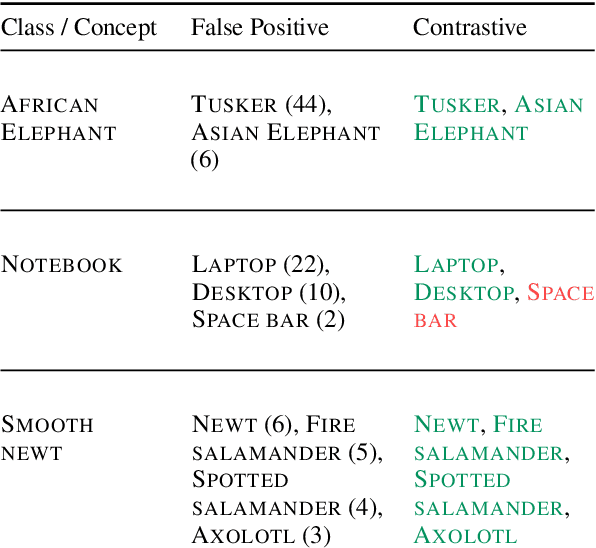
Language-vision models like CLIP have made significant progress in zero-shot vision tasks, such as zero-shot image classification (ZSIC). However, generating specific and expressive class descriptions remains a major challenge. Existing approaches suffer from granularity and label ambiguity issues. To tackle these challenges, we propose V-GLOSS: Visual Glosses, a novel method leveraging modern language models and semantic knowledge bases to produce visually-grounded class descriptions. We demonstrate V-GLOSS's effectiveness by achieving state-of-the-art results on benchmark ZSIC datasets including ImageNet and STL-10. In addition, we introduce a silver dataset with class descriptions generated by V-GLOSS, and show its usefulness for vision tasks. We make available our code and dataset.
Fairness in Image Search: A Study of Occupational Stereotyping in Image Retrieval and its Debiasing
May 06, 2023


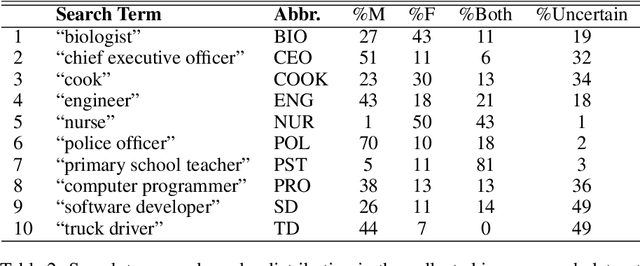
Multi-modal search engines have experienced significant growth and widespread use in recent years, making them the second most common internet use. While search engine systems offer a range of services, the image search field has recently become a focal point in the information retrieval community, as the adage goes, "a picture is worth a thousand words". Although popular search engines like Google excel at image search accuracy and agility, there is an ongoing debate over whether their search results can be biased in terms of gender, language, demographics, socio-cultural aspects, and stereotypes. This potential for bias can have a significant impact on individuals' perceptions and influence their perspectives. In this paper, we present our study on bias and fairness in web search, with a focus on keyword-based image search. We first discuss several kinds of biases that exist in search systems and why it is important to mitigate them. We narrow down our study to assessing and mitigating occupational stereotypes in image search, which is a prevalent fairness issue in image retrieval. For the assessment of stereotypes, we take gender as an indicator. We explore various open-source and proprietary APIs for gender identification from images. With these, we examine the extent of gender bias in top-tanked image search results obtained for several occupational keywords. To mitigate the bias, we then propose a fairness-aware re-ranking algorithm that optimizes (a) relevance of the search result with the keyword and (b) fairness w.r.t genders identified. We experiment on 100 top-ranked images obtained for 10 occupational keywords and consider random re-ranking and re-ranking based on relevance as baselines. Our experimental results show that the fairness-aware re-ranking algorithm produces rankings with better fairness scores and competitive relevance scores than the baselines.
Pretrained deep models outperform GBDTs in Learning-To-Rank under label scarcity
Jul 31, 2023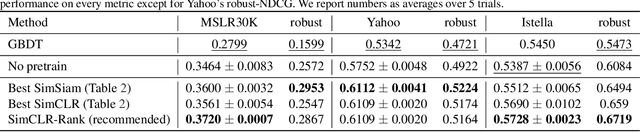
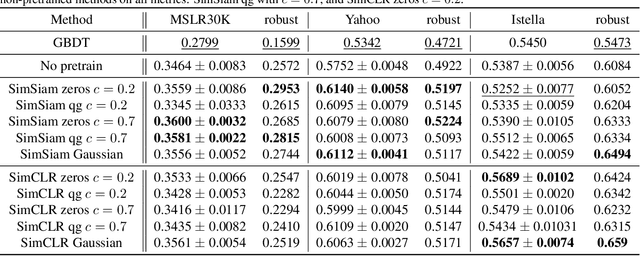

While deep learning (DL) models are state-of-the-art in text and image domains, they have not yet consistently outperformed Gradient Boosted Decision Trees (GBDTs) on tabular Learning-To-Rank (LTR) problems. Most of the recent performance gains attained by DL models in text and image tasks have used unsupervised pretraining, which exploits orders of magnitude more unlabeled data than labeled data. To the best of our knowledge, unsupervised pretraining has not been applied to the LTR problem, which often produces vast amounts of unlabeled data. In this work, we study whether unsupervised pretraining can improve LTR performance over GBDTs and other non-pretrained models. Using simple design choices--including SimCLR-Rank, our ranking-specific modification of SimCLR (an unsupervised pretraining method for images)--we produce pretrained deep learning models that soundly outperform GBDTs (and other non-pretrained models) in the case where labeled data is vastly outnumbered by unlabeled data. We also show that pretrained models also often achieve significantly better robustness than non-pretrained models (GBDTs or DL models) in ranking outlier data.
Test-Time Selection for Robust Skin Lesion Analysis
Aug 10, 2023Skin lesion analysis models are biased by artifacts placed during image acquisition, which influence model predictions despite carrying no clinical information. Solutions that address this problem by regularizing models to prevent learning those spurious features achieve only partial success, and existing test-time debiasing techniques are inappropriate for skin lesion analysis due to either making unrealistic assumptions on the distribution of test data or requiring laborious annotation from medical practitioners. We propose TTS (Test-Time Selection), a human-in-the-loop method that leverages positive (e.g., lesion area) and negative (e.g., artifacts) keypoints in test samples. TTS effectively steers models away from exploiting spurious artifact-related correlations without retraining, and with less annotation requirements. Our solution is robust to a varying availability of annotations, and different levels of bias. We showcase on the ISIC2019 dataset (for which we release a subset of annotated images) how our model could be deployed in the real-world for mitigating bias.
Learning Dense UV Completion for Human Mesh Recovery
Aug 10, 2023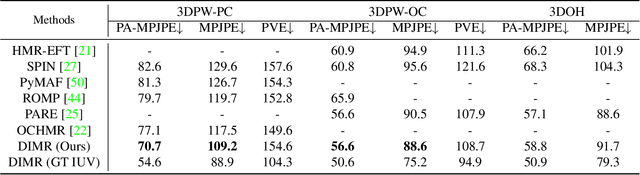
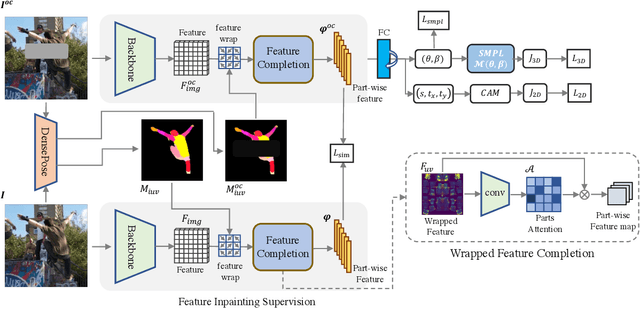
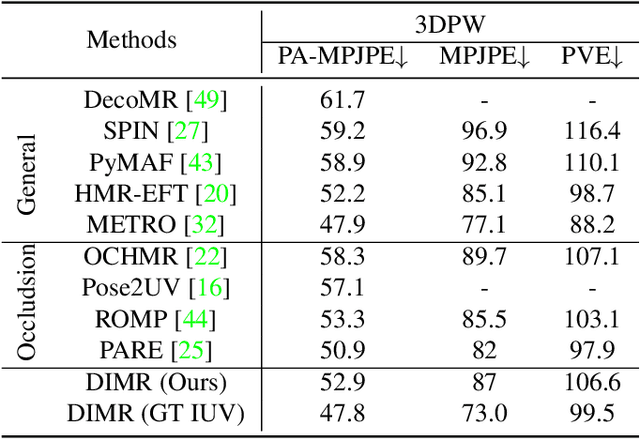

Human mesh reconstruction from a single image is challenging in the presence of occlusion, which can be caused by self, objects, or other humans. Existing methods either fail to separate human features accurately or lack proper supervision for feature completion. In this paper, we propose Dense Inpainting Human Mesh Recovery (DIMR), a two-stage method that leverages dense correspondence maps to handle occlusion. Our method utilizes a dense correspondence map to separate visible human features and completes human features on a structured UV map dense human with an attention-based feature completion module. We also design a feature inpainting training procedure that guides the network to learn from unoccluded features. We evaluate our method on several datasets and demonstrate its superior performance under heavily occluded scenarios compared to other methods. Extensive experiments show that our method obviously outperforms prior SOTA methods on heavily occluded images and achieves comparable results on the standard benchmarks (3DPW).