 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrypto x AI, AI x Crypto: A Survey
Jun 11, 2026The intersection of crypto x AI is spawning papers, products, online posts, and companies. All the surrounding buzz, though, obscures what exactly has been done, what the opportunities and challenges are, and what open questions deserve attention. This survey paper asks what AI can do for blockchain-based technologies (broadly construed as "crypto") (crypto x AI), and vice versa (AI x crypto). We systematize existing work, summarize key takeaways, highlight open research questions, and offer a perspective on pervasive industry misconceptions, concluding that AI and crypto are still in the very early stages of meaningful integration.
Do Language Models Need Sleep? Offline Recurrence for Improved Online Inference
May 27, 2026Transformer-based large language models are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consolidation mechanism in which a model periodically converts recent context into persistent fast weights before clearing its key-value cache. During sleep, the model performs $N$ offline recurrent passes over the accumulated context and updates the fast weights in its state-space model (SSM) blocks through a learned local rule. During inference, this shifts extra computation to sleep while preserving the latency of wake-time prediction. We test our method on controlled synthetic tasks, including cellular automata and multi-hop graph retrieval, as well as a realistic math reasoning task, on which a regular transformer as well as SSM-attention hybrid models fail. We then show that increasing sleep duration $N$ for our models improves performance, with the largest gains on examples that require deeper reasoning.
Smooth Partial Lotteries for Stable Randomized Selection
May 21, 2026Competitive selection processes, from scientific funding to admissions and hiring, use evaluations to score candidates, and eventually choose a subset of them based on those scores. Recently, many organizations have adopted partial lotteries, which randomize selection based on evaluation scores. However, existing lottery designs are inherently unstable, as a small change to a single candidate's score can cause large shifts in their selection probabilities. This instability undermines a key goal of lotteries: reducing the influence of fine-grained score distinctions near the decision boundary. We propose smoothness as a design principle for partial lotteries, formalizing it as a Lipschitz condition on the mapping from review scores over candidates to selection probabilities. We introduce the Clipped Linear Lottery, a simple mechanism in which selection probabilities scale linearly with estimated quality between an upper threshold, above which we always accept, and a lower threshold, below which we always reject. We prove that the Clipped Linear Lottery's worst-case regret matches a lower bound for any smooth selection rule up to a factor of $(1 - k/n)$, where $k/n$ is the acceptance rate. We compare smooth selection to other stability notions like Individual Fairness and Differential Privacy, showing that the Clipped Linear Lottery achieves a better smoothness-regret tradeoff than alternatives. Experiments on real peer review data from ICLR 2025, NeurIPS 2024, and the Swiss National Science Foundation demonstrate that existing lottery designs are highly unstable in practice even under perturbations to a single score. Our experiments also confirm the tightness of our theoretical analysis and show that our proposed Clipped Linear Lottery achieves a better smoothness-utility tradeoff than alternatives in practice.
SynAE: A Framework for Measuring the Quality of Synthetic Data for Tool-Calling Agent Evaluations
May 21, 2026Today, tool-calling agents are commonly evaluated or tested on static datasets of execution traces, including input commands, agent responses, and associated tool calls. However, internal production datasets are often insufficient or unusable for testing; for example, they may contain sensitive or proprietary data, or they may be too sparse to support comprehensive testing (especially pre-deployment). In these settings, practitioners are increasingly replacing or augmenting real datasets with synthetic ones for evaluation purposes. A key challenge is quantifying the relation between these synthetic datasets and the real data. We introduce SynAE, an evaluation framework for assessing how well synthetic benchmarks for multi-turn, tool-calling agents replicate and augment the characteristics of real data trajectories. SynAE assesses the validity, fidelity, and diversity of synthetic data across four metric categories: (i) task instructions and intermediate responses, (ii) tool calls, (iii) final outputs, and (iv) downstream evaluation. We evaluate SynAE using recent agent benchmarks and test common synthetic data failure modes via realistic and controlled generation schemes. SynAE detects fine-grained variations in data validity, fidelity and diversity, and shows that no single metric is sufficient to fully characterize synthetic data quality, motivating a multi-axis evaluation of synthetic data for agent testing. A demo of SynAE is available at https://synae-2026-synae-demo.static.hf.space/index.html, with code at https://github.com/wsqwsq/SynAE.
Value-Based Pre-Training with Downstream Feedback
Jan 29, 2026Can a small amount of verified goal information steer the expensive self-supervised pretraining of foundation models? Standard pretraining optimizes a fixed proxy objective (e.g., next-token prediction), which can misallocate compute away from downstream capabilities of interest. We introduce V-Pretraining: a value-based, modality-agnostic method for controlled continued pretraining in which a lightweight task designer reshapes the pretraining task to maximize the value of each gradient step. For example, consider self-supervised learning (SSL) with sample augmentation. The V-Pretraining task designer selects pretraining tasks (e.g., augmentations) for which the pretraining loss gradient is aligned with a gradient computed over a downstream task (e.g., image segmentation). This helps steer pretraining towards relevant downstream capabilities. Notably, the pretrained model is never updated on downstream task labels; they are used only to shape the pretraining task. Under matched learner update budgets, V-Pretraining of 0.5B--7B language models improves reasoning (GSM8K test Pass@1) by up to 18% relative over standard next-token prediction using only 12% of GSM8K training examples as feedback. In vision SSL, we improve the state-of-the-art results on ADE20K by up to 1.07 mIoU and reduce NYUv2 RMSE while improving ImageNet linear accuracy, and we provide pilot evidence of improved token efficiency in continued pretraining.
BaNEL: Exploration Posteriors for Generative Modeling Using Only Negative Rewards
Oct 10, 2025Today's generative models thrive with large amounts of supervised data and informative reward functions characterizing the quality of the generation. They work under the assumptions that the supervised data provides knowledge to pre-train the model, and the reward function provides dense information about how to further improve the generation quality and correctness. However, in the hardest instances of important problems, two problems arise: (1) the base generative model attains a near-zero reward signal, and (2) calls to the reward oracle are expensive. This setting poses a fundamentally different learning challenge than standard reward-based post-training. To address this, we propose BaNEL (Bayesian Negative Evidence Learning), an algorithm that post-trains the model using failed attempts only, while minimizing the number of reward evaluations (NREs). Our method is based on the idea that the problem of learning regularities underlying failures can be cast as another, in-loop generative modeling problem. We then leverage this model to assess whether new data resembles previously seen failures and steer the generation away from them. We show that BaNEL can improve model performance without observing a single successful sample on several sparse-reward tasks, outperforming existing novelty-bonus approaches by up to several orders of magnitude in success rate, while using fewer reward evaluations.
Private Evolution Converges
Jun 10, 2025Private Evolution (PE) is a promising training-free method for differentially private (DP) synthetic data generation. While it achieves strong performance in some domains (e.g., images and text), its behavior in others (e.g., tabular data) is less consistent. To date, the only theoretical analysis of the convergence of PE depends on unrealistic assumptions about both the algorithm's behavior and the structure of the sensitive dataset. In this work, we develop a new theoretical framework to explain PE's practical behavior and identify sufficient conditions for its convergence. For $d$-dimensional sensitive datasets with $n$ data points from a bounded domain, we prove that PE produces an $(\epsilon, \delta)$-DP synthetic dataset with expected 1-Wasserstein distance of order $\tilde{O}(d(n\epsilon)^{-1/d})$ from the original, establishing worst-case convergence of the algorithm as $n \to \infty$. Our analysis extends to general Banach spaces as well. We also connect PE to the Private Signed Measure Mechanism, a method for DP synthetic data generation that has thus far not seen much practical adoption. We demonstrate the practical relevance of our theoretical findings in simulations.
Private Federated Learning using Preference-Optimized Synthetic Data
Apr 23, 2025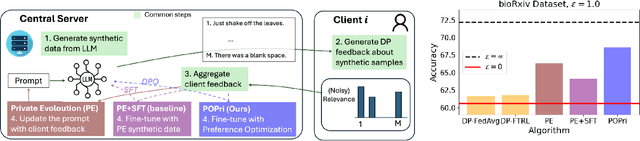
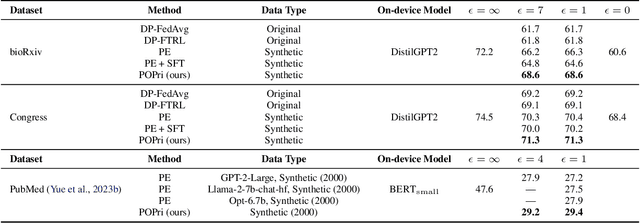
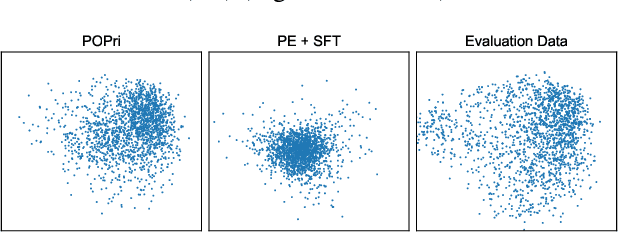

In practical settings, differentially private Federated learning (DP-FL) is the dominant method for training models from private, on-device client data. Recent work has suggested that DP-FL may be enhanced or outperformed by methods that use DP synthetic data (Wu et al., 2024; Hou et al., 2024). The primary algorithms for generating DP synthetic data for FL applications require careful prompt engineering based on public information and/or iterative private client feedback. Our key insight is that the private client feedback collected by prior DP synthetic data methods (Hou et al., 2024; Xie et al., 2024) can be viewed as a preference ranking. Our algorithm, Preference Optimization for Private Client Data (POPri) harnesses client feedback using preference optimization algorithms such as Direct Preference Optimization (DPO) to fine-tune LLMs to generate high-quality DP synthetic data. To evaluate POPri, we release LargeFedBench, a new federated text benchmark for uncontaminated LLM evaluations on federated client data. POPri substantially improves the utility of DP synthetic data relative to prior work on LargeFedBench datasets and an existing benchmark from Xie et al. (2024). POPri closes the gap between next-token prediction accuracy in the fully-private and non-private settings by up to 68%, compared to 52% for prior synthetic data methods, and 10% for state-of-the-art DP federated learning methods. The code and data are available at https://github.com/meiyuw/POPri.
A Water Efficiency Dataset for African Data Centers
Dec 04, 2024AI computing and data centers consume a large amount of freshwater, both directly for cooling and indirectly for electricity generation. While most attention has been paid to developed countries such as the U.S., this paper presents the first-of-its-kind dataset that combines nation-level weather and electricity generation data to estimate water usage efficiency for data centers in 41 African countries across five different climate regions. We also use our dataset to evaluate and estimate the water consumption of inference on two large language models (i.e., Llama-3-70B and GPT-4) in 11 selected African countries. Our findings show that writing a 10-page report using Llama-3-70B could consume about \textbf{0.7 liters} of water, while the water consumption by GPT-4 for the same task may go up to about 60 liters. For writing a medium-length email of 120-200 words, Llama-3-70B and GPT-4 could consume about \textbf{0.13 liters} and 3 liters of water, respectively. Interestingly, given the same AI model, 8 out of the 11 selected African countries consume less water than the global average, mainly because of lower water intensities for electricity generation. However, water consumption can be substantially higher in some African countries with a steppe climate than the U.S. and global averages, prompting more attention when deploying AI computing in these countries. Our dataset is publicly available on \href{https://huggingface.co/datasets/masterlion/WaterEfficientDatasetForAfricanCountries/tree/main}{Hugging Face}.
Truncated Consistency Models
Oct 18, 2024



Consistency models have recently been introduced to accelerate sampling from diffusion models by directly predicting the solution (i.e., data) of the probability flow ODE (PF ODE) from initial noise. However, the training of consistency models requires learning to map all intermediate points along PF ODE trajectories to their corresponding endpoints. This task is much more challenging than the ultimate objective of one-step generation, which only concerns the PF ODE's noise-to-data mapping. We empirically find that this training paradigm limits the one-step generation performance of consistency models. To address this issue, we generalize consistency training to the truncated time range, which allows the model to ignore denoising tasks at earlier time steps and focus its capacity on generation. We propose a new parameterization of the consistency function and a two-stage training procedure that prevents the truncated-time training from collapsing to a trivial solution. Experiments on CIFAR-10 and ImageNet $64\times64$ datasets show that our method achieves better one-step and two-step FIDs than the state-of-the-art consistency models such as iCT-deep, using more than 2$\times$ smaller networks. Project page: https://truncated-cm.github.io/