 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual Branch Deep Learning Network for Detection and Stage Grading of Diabetic Retinopathy
Aug 19, 2023
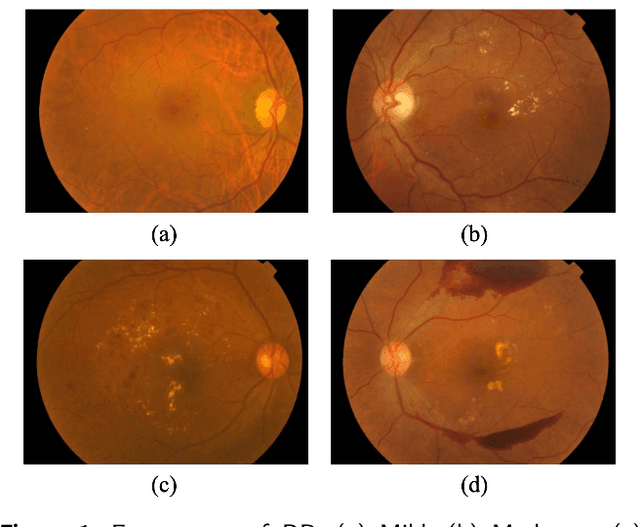
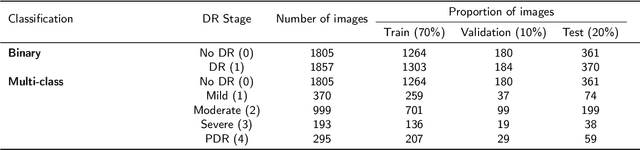
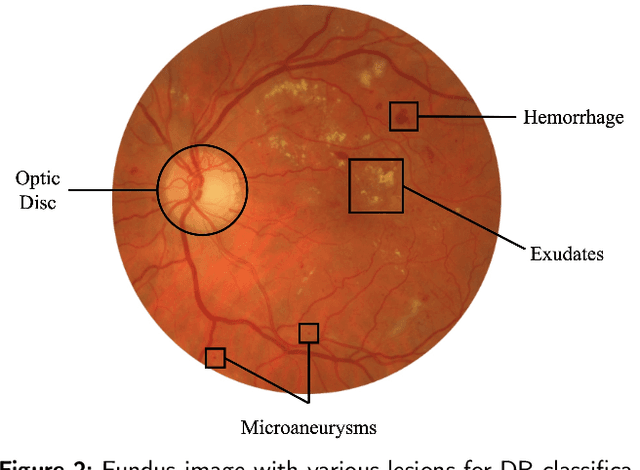
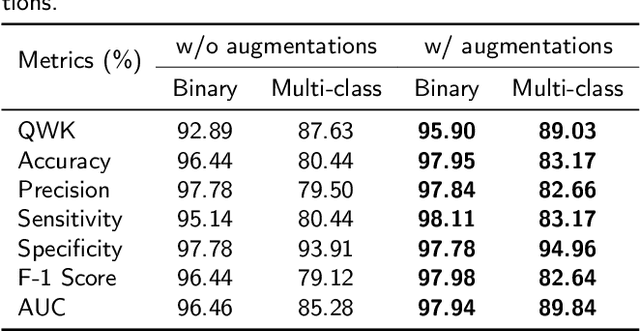
Diabetic retinopathy is a severe complication of diabetes that can lead to permanent blindness if not treated promptly. Early and accurate diagnosis of the disease is essential for successful treatment. This paper introduces a deep learning method for the detection and stage grading of diabetic retinopathy, using a single fundus retinal image. Our model utilizes transfer learning, employing two state-of-the-art pre-trained models as feature extractors and fine-tuning them on a new dataset. The proposed model is trained on a large multi-center dataset, including the APTOS 2019 dataset, obtained from publicly available sources. It achieves remarkable performance in diabetic retinopathy detection and stage classification on the APTOS 2019, outperforming the established literature. For binary classification, the proposed approach achieves an accuracy of 98.50%, a sensitivity of 99.46%, and a specificity of 97.51%. In stage grading, it achieves a quadratic weighted kappa of 93.00%, an accuracy of 89.60%, a sensitivity of 89.60%, and a specificity of 97.72%. The proposed approach serves as a reliable screening and stage grading tool for diabetic retinopathy, offering significant potential to enhance clinical decision-making and patient care.
ControlRetriever: Harnessing the Power of Instructions for Controllable Retrieval
Aug 19, 2023
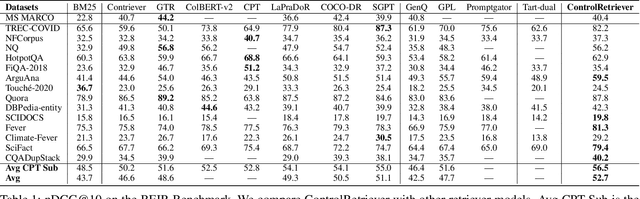
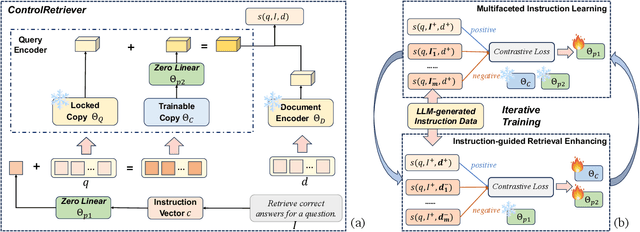
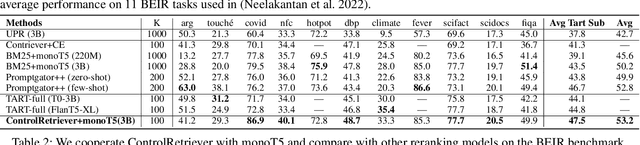
Recent studies have shown that dense retrieval models, lacking dedicated training data, struggle to perform well across diverse retrieval tasks, as different retrieval tasks often entail distinct search intents. To address this challenge, in this work we introduce ControlRetriever, a generic and efficient approach with a parameter isolated architecture, capable of controlling dense retrieval models to directly perform varied retrieval tasks, harnessing the power of instructions that explicitly describe retrieval intents in natural language. Leveraging the foundation of ControlNet, which has proven powerful in text-to-image generation, ControlRetriever imbues different retrieval models with the new capacity of controllable retrieval, all while being guided by task-specific instructions. Furthermore, we propose a novel LLM guided Instruction Synthesizing and Iterative Training strategy, which iteratively tunes ControlRetriever based on extensive automatically-generated retrieval data with diverse instructions by capitalizing the advancement of large language models. Extensive experiments show that in the BEIR benchmark, with only natural language descriptions of specific retrieval intent for each task, ControlRetriever, as a unified multi-task retrieval system without task-specific tuning, significantly outperforms baseline methods designed with task-specific retrievers and also achieves state-of-the-art zero-shot performance.
A Deep Learning Approach for Virtual Contrast Enhancement in Contrast Enhanced Spectral Mammography
Aug 03, 2023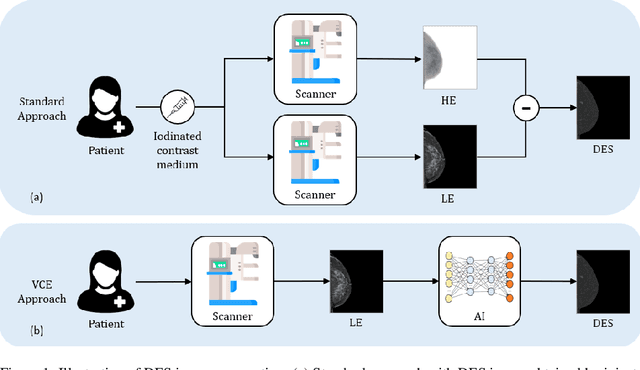
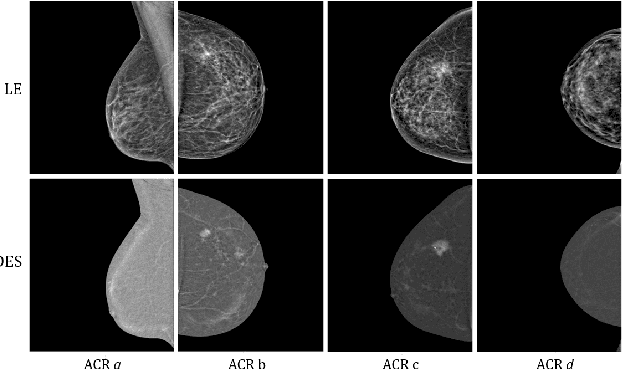
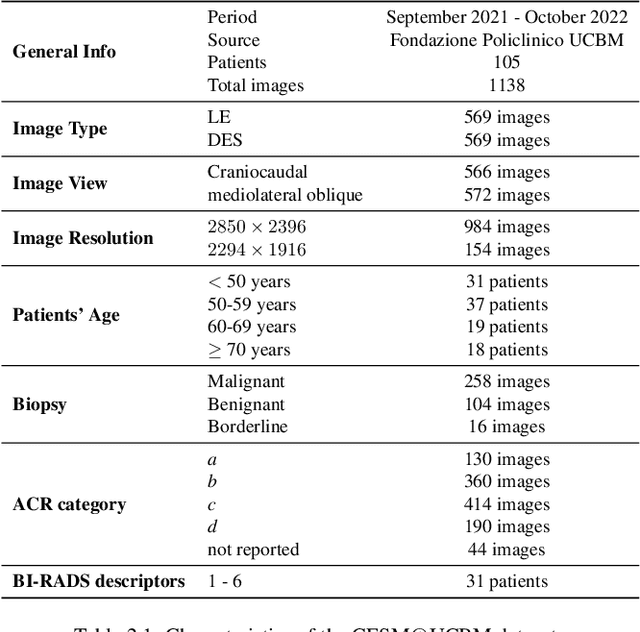
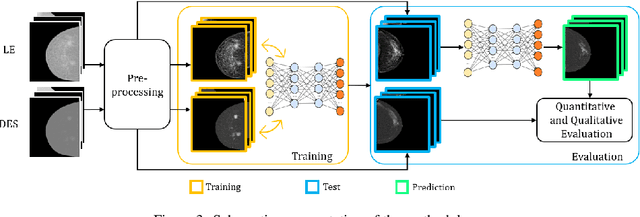
Contrast Enhanced Spectral Mammography (CESM) is a dual-energy mammographic imaging technique that first needs intravenously administration of an iodinated contrast medium; then, it collects both a low-energy image, comparable to standard mammography, and a high-energy image. The two scans are then combined to get a recombined image showing contrast enhancement. Despite CESM diagnostic advantages for breast cancer diagnosis, the use of contrast medium can cause side effects, and CESM also beams patients with a higher radiation dose compared to standard mammography. To address these limitations this work proposes to use deep generative models for virtual contrast enhancement on CESM, aiming to make the CESM contrast-free as well as to reduce the radiation dose. Our deep networks, consisting of an autoencoder and two Generative Adversarial Networks, the Pix2Pix, and the CycleGAN, generate synthetic recombined images solely from low-energy images. We perform an extensive quantitative and qualitative analysis of the model's performance, also exploiting radiologists' assessments, on a novel CESM dataset that includes 1138 images that, as a further contribution of this work, we make publicly available. The results show that CycleGAN is the most promising deep network to generate synthetic recombined images, highlighting the potential of artificial intelligence techniques for virtual contrast enhancement in this field.
CartiMorph: a framework for automated knee articular cartilage morphometrics
Aug 03, 2023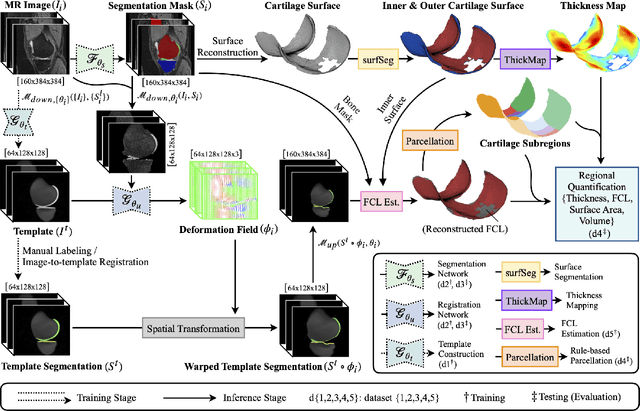
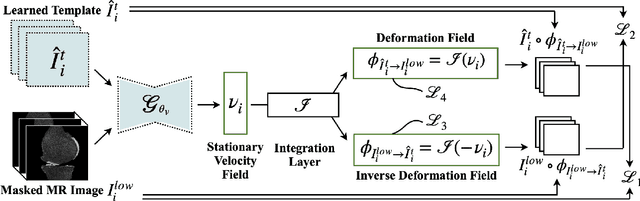
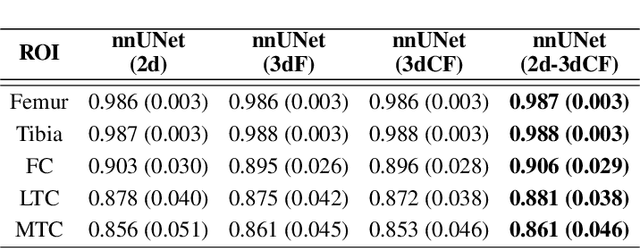
We introduce CartiMorph, a framework for automated knee articular cartilage morphometrics. It takes an image as input and generates quantitative metrics for cartilage subregions, including the percentage of full-thickness cartilage loss (FCL), mean thickness, surface area, and volume. CartiMorph leverages the power of deep learning models for hierarchical image feature representation. Deep learning models were trained and validated for tissue segmentation, template construction, and template-to-image registration. We established methods for surface-normal-based cartilage thickness mapping, FCL estimation, and rule-based cartilage parcellation. Our cartilage thickness map showed less error in thin and peripheral regions. We evaluated the effectiveness of the adopted segmentation model by comparing the quantitative metrics obtained from model segmentation and those from manual segmentation. The root-mean-squared deviation of the FCL measurements was less than 8%, and strong correlations were observed for the mean thickness (Pearson's correlation coefficient $\rho \in [0.82,0.97]$), surface area ($\rho \in [0.82,0.98]$) and volume ($\rho \in [0.89,0.98]$) measurements. We compared our FCL measurements with those from a previous study and found that our measurements deviated less from the ground truths. We observed superior performance of the proposed rule-based cartilage parcellation method compared with the atlas-based approach. CartiMorph has the potential to promote imaging biomarkers discovery for knee osteoarthritis.
Mirror Diffusion Models
Aug 11, 2023Diffusion models have successfully been applied to generative tasks in various continuous domains. However, applying diffusion to discrete categorical data remains a non-trivial task. Moreover, generation in continuous domains often requires clipping in practice, which motivates the need for a theoretical framework for adapting diffusion to constrained domains. Inspired by the mirror Langevin algorithm for the constrained sampling problem, in this theoretical report we propose Mirror Diffusion Models (MDMs). We demonstrate MDMs in the context of simplex diffusion and propose natural extensions to popular domains such as image and text generation.
Follow Anything: Open-set detection, tracking, and following in real-time
Aug 10, 2023



Tracking and following objects of interest is critical to several robotics use cases, ranging from industrial automation to logistics and warehousing, to healthcare and security. In this paper, we present a robotic system to detect, track, and follow any object in real-time. Our approach, dubbed ``follow anything'' (FAn), is an open-vocabulary and multimodal model -- it is not restricted to concepts seen at training time and can be applied to novel classes at inference time using text, images, or click queries. Leveraging rich visual descriptors from large-scale pre-trained models (foundation models), FAn can detect and segment objects by matching multimodal queries (text, images, clicks) against an input image sequence. These detected and segmented objects are tracked across image frames, all while accounting for occlusion and object re-emergence. We demonstrate FAn on a real-world robotic system (a micro aerial vehicle) and report its ability to seamlessly follow the objects of interest in a real-time control loop. FAn can be deployed on a laptop with a lightweight (6-8 GB) graphics card, achieving a throughput of 6-20 frames per second. To enable rapid adoption, deployment, and extensibility, we open-source all our code on our project webpage at https://github.com/alaamaalouf/FollowAnything . We also encourage the reader the watch our 5-minutes explainer video in this https://www.youtube.com/watch?v=6Mgt3EPytrw .
AD-CLIP: Adapting Domains in Prompt Space Using CLIP
Aug 10, 2023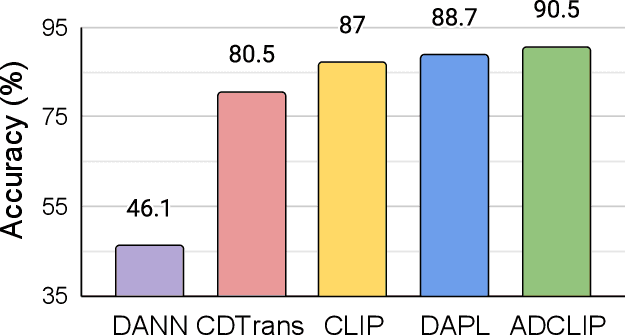
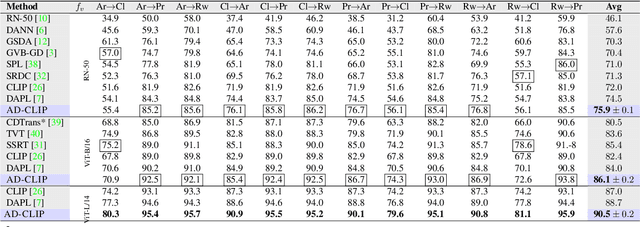

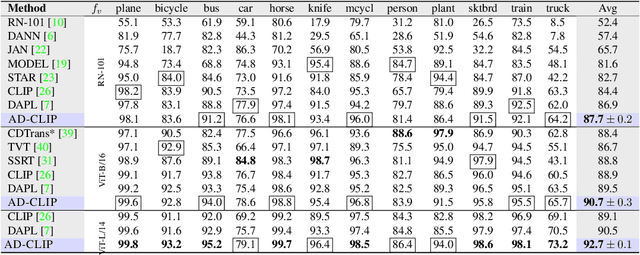
Although deep learning models have shown impressive performance on supervised learning tasks, they often struggle to generalize well when the training (source) and test (target) domains differ. Unsupervised domain adaptation (DA) has emerged as a popular solution to this problem. However, current DA techniques rely on visual backbones, which may lack semantic richness. Despite the potential of large-scale vision-language foundation models like CLIP, their effectiveness for DA has yet to be fully explored. To address this gap, we introduce AD-CLIP, a domain-agnostic prompt learning strategy for CLIP that aims to solve the DA problem in the prompt space. We leverage the frozen vision backbone of CLIP to extract both image style (domain) and content information, which we apply to learn prompt tokens. Our prompts are designed to be domain-invariant and class-generalizable, by conditioning prompt learning on image style and content features simultaneously. We use standard supervised contrastive learning in the source domain, while proposing an entropy minimization strategy to align domains in the embedding space given the target domain data. We also consider a scenario where only target domain samples are available during testing, without any source domain data, and propose a cross-domain style mapping network to hallucinate domain-agnostic tokens. Our extensive experiments on three benchmark DA datasets demonstrate the effectiveness of AD-CLIP compared to existing literature.
HSR-Diff:Hyperspectral Image Super-Resolution via Conditional Diffusion Models
Jun 21, 2023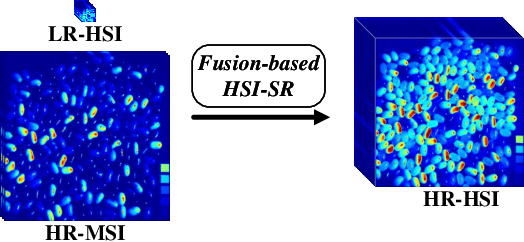
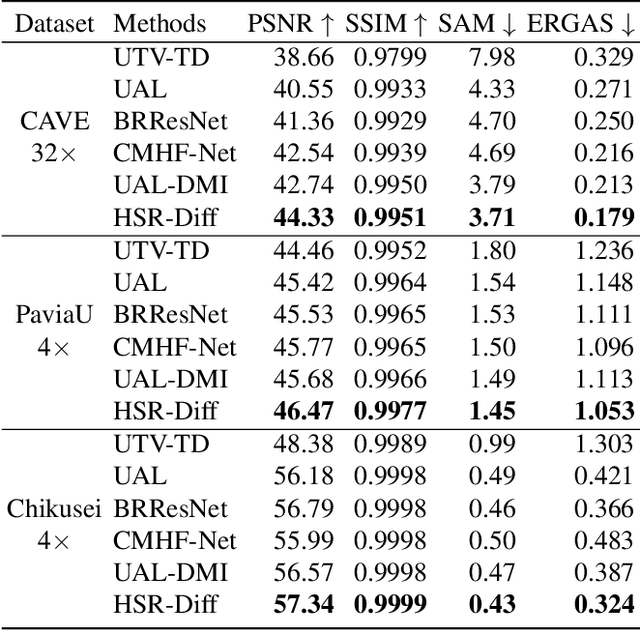
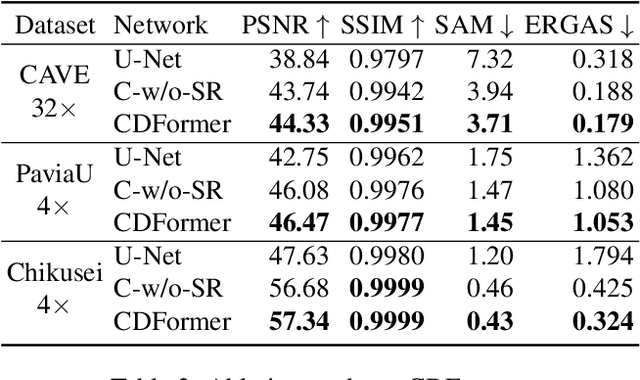
Despite the proven significance of hyperspectral images (HSIs) in performing various computer vision tasks, its potential is adversely affected by the low-resolution (LR) property in the spatial domain, resulting from multiple physical factors. Inspired by recent advancements in deep generative models, we propose an HSI Super-resolution (SR) approach with Conditional Diffusion Models (HSR-Diff) that merges a high-resolution (HR) multispectral image (MSI) with the corresponding LR-HSI. HSR-Diff generates an HR-HSI via repeated refinement, in which the HR-HSI is initialized with pure Gaussian noise and iteratively refined. At each iteration, the noise is removed with a Conditional Denoising Transformer (CDF ormer) that is trained on denoising at different noise levels, conditioned on the hierarchical feature maps of HR-MSI and LR-HSI. In addition, a progressive learning strategy is employed to exploit the global information of full-resolution images. Systematic experiments have been conducted on four public datasets, demonstrating that HSR-Diff outperforms state-of-the-art methods.
Distributionally Robust Classification on a Data Budget
Aug 07, 2023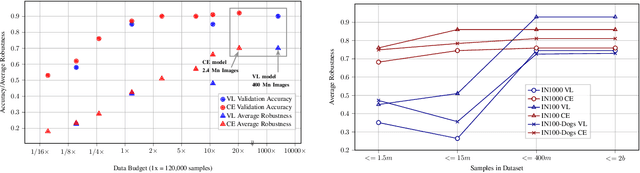


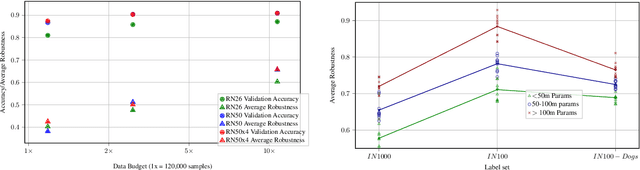
Real world uses of deep learning require predictable model behavior under distribution shifts. Models such as CLIP show emergent natural distributional robustness comparable to humans, but may require hundreds of millions of training samples. Can we train robust learners in a domain where data is limited? To rigorously address this question, we introduce JANuS (Joint Annotations and Names Set), a collection of four new training datasets with images, labels, and corresponding captions, and perform a series of carefully controlled investigations of factors contributing to robustness in image classification, then compare those results to findings derived from a large-scale meta-analysis. Using this approach, we show that standard ResNet-50 trained with the cross-entropy loss on 2.4 million image samples can attain comparable robustness to a CLIP ResNet-50 trained on 400 million samples. To our knowledge, this is the first result showing (near) state-of-the-art distributional robustness on limited data budgets. Our dataset is available at \url{https://huggingface.co/datasets/penfever/JANuS_dataset}, and the code used to reproduce our experiments can be found at \url{https://github.com/penfever/vlhub/}.
FPGA Resource-aware Structured Pruning for Real-Time Neural Networks
Aug 09, 2023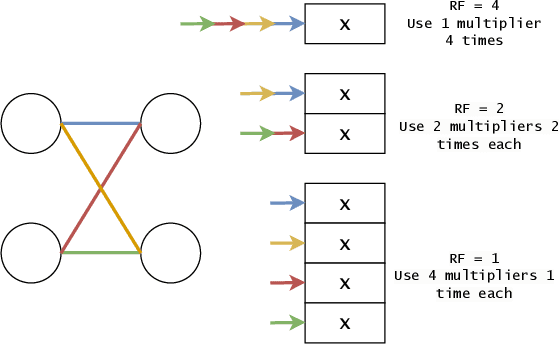
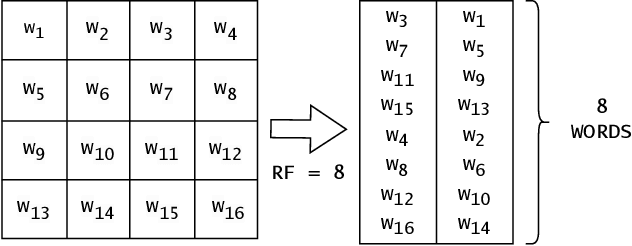
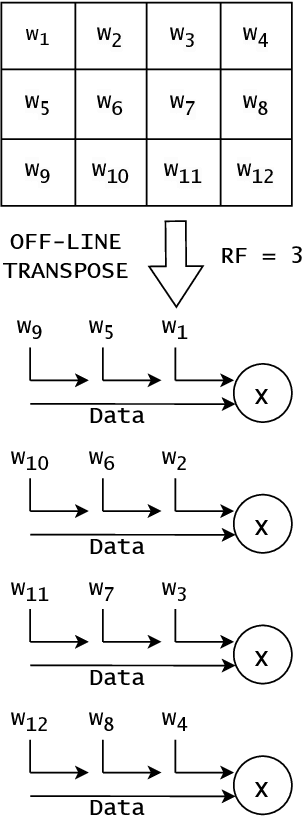
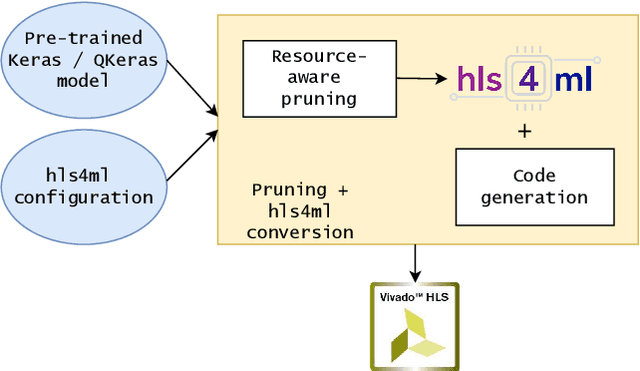
Neural networks achieve state-of-the-art performance in image classification, speech recognition, scientific analysis and many more application areas. With the ever-increasing need for faster computation and lower power consumption, driven by real-time systems and Internet-of-Things (IoT) devices, FPGAs have emerged as suitable devices for deep learning inference. Due to the high computational complexity and memory footprint of neural networks, various compression techniques, such as pruning, quantization and knowledge distillation, have been proposed in literature. Pruning sparsifies a neural network, reducing the number of multiplications and memory. However, pruning often fails to capture properties of the underlying hardware, causing unstructured sparsity and load-balance inefficiency, thus bottlenecking resource improvements. We propose a hardware-centric formulation of pruning, by formulating it as a knapsack problem with resource-aware tensor structures. The primary emphasis is on real-time inference, with latencies in the order of 1$\mu$s, accelerated with hls4ml, an open-source framework for deep learning inference on FPGAs. Evaluated on a range of tasks, including real-time particle classification at CERN's Large Hadron Collider and fast image classification, the proposed method achieves a reduction ranging between 55% and 92% in the utilization of digital signal processing blocks (DSP) and up to 81% in block memory (BRAM) utilization.