 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAMScore: A Semantic Structural Similarity Metric for Image Translation Evaluation
May 24, 2023
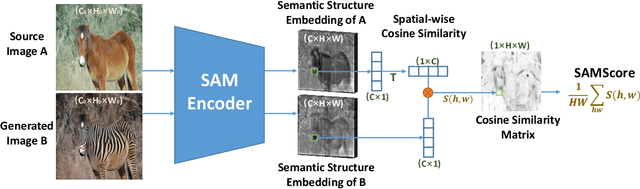
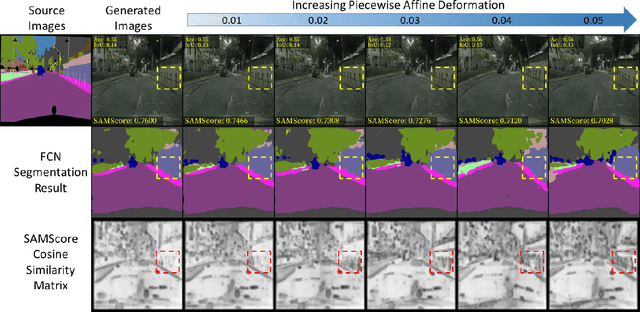

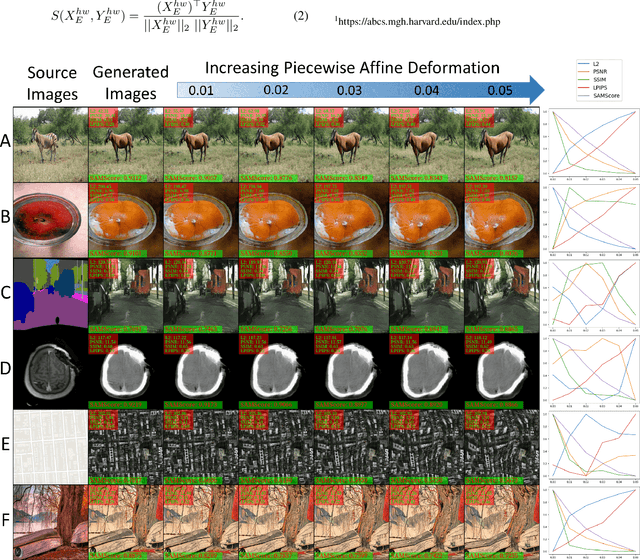
Image translation has wide applications, such as style transfer and modality conversion, usually aiming to generate images having both high degrees of realism and faithfulness. These problems remain difficult, especially when it is important to preserve semantic structures. Traditional image-level similarity metrics are of limited use, since the semantics of an image are high-level, and not strongly governed by pixel-wise faithfulness to an original image. Towards filling this gap, we introduce SAMScore, a generic semantic structural similarity metric for evaluating the faithfulness of image translation models. SAMScore is based on the recent high-performance Segment Anything Model (SAM), which can perform semantic similarity comparisons with standout accuracy. We applied SAMScore on 19 image translation tasks, and found that it is able to outperform all other competitive metrics on all of the tasks. We envision that SAMScore will prove to be a valuable tool that will help to drive the vibrant field of image translation, by allowing for more precise evaluations of new and evolving translation models. The code is available at https://github.com/Kent0n-Li/SAMScore.
A Comprehensive Empirical Evaluation on Online Continual Learning
Aug 20, 2023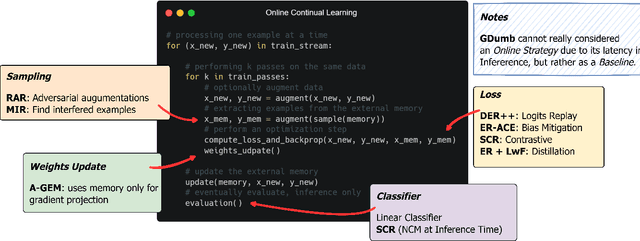
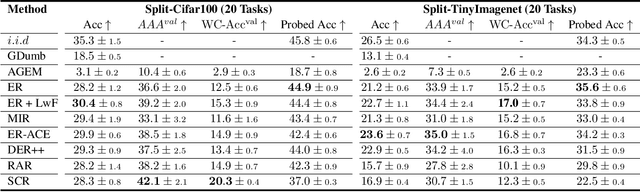
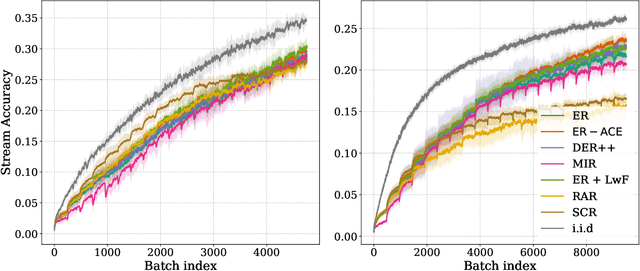
Online continual learning aims to get closer to a live learning experience by learning directly on a stream of data with temporally shifting distribution and by storing a minimum amount of data from that stream. In this empirical evaluation, we evaluate various methods from the literature that tackle online continual learning. More specifically, we focus on the class-incremental setting in the context of image classification, where the learner must learn new classes incrementally from a stream of data. We compare these methods on the Split-CIFAR100 and Split-TinyImagenet benchmarks, and measure their average accuracy, forgetting, stability, and quality of the representations, to evaluate various aspects of the algorithm at the end but also during the whole training period. We find that most methods suffer from stability and underfitting issues. However, the learned representations are comparable to i.i.d. training under the same computational budget. No clear winner emerges from the results and basic experience replay, when properly tuned and implemented, is a very strong baseline. We release our modular and extensible codebase at https://github.com/AlbinSou/ocl_survey based on the avalanche framework to reproduce our results and encourage future research.
EDDense-Net: Fully Dense Encoder Decoder Network for Joint Segmentation of Optic Cup and Disc
Aug 20, 2023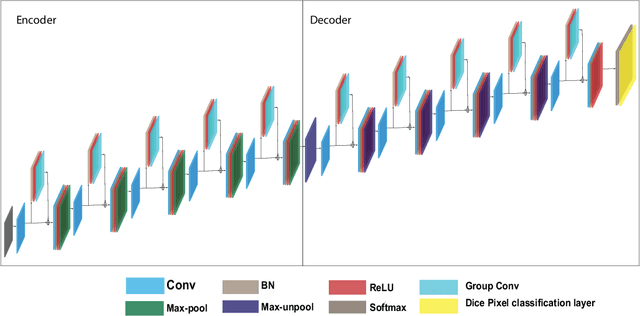
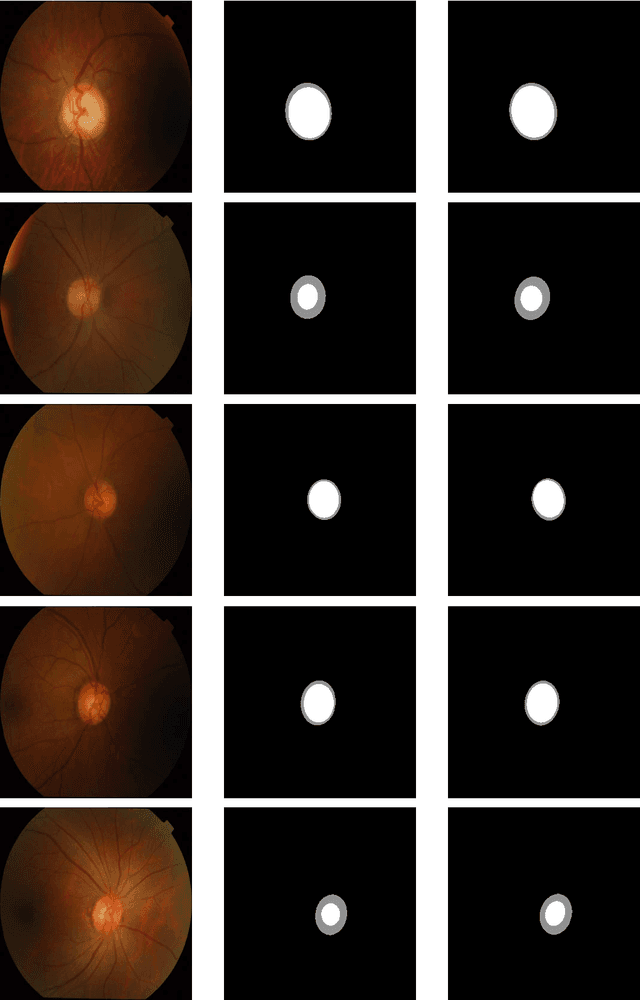
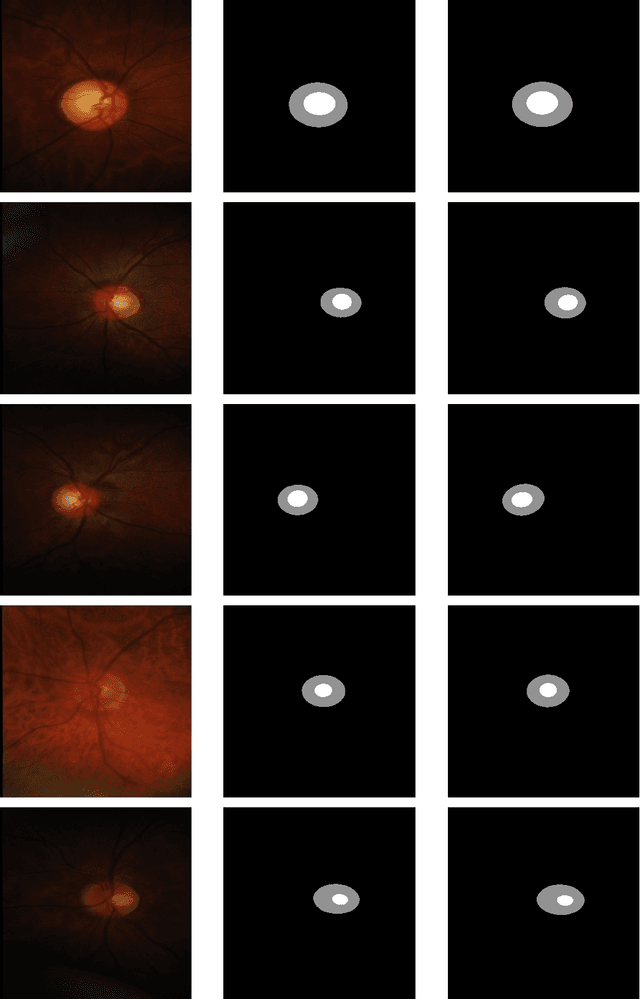
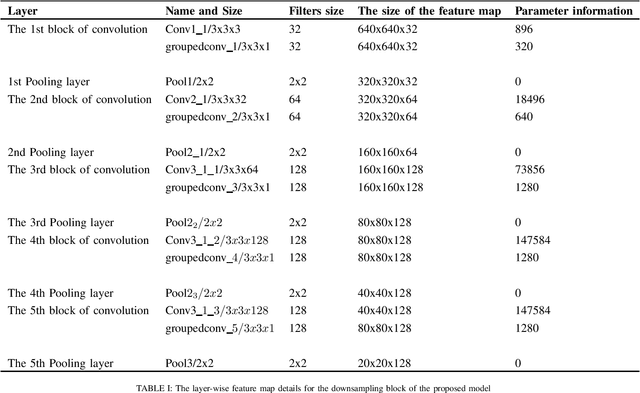
Glaucoma is an eye disease that causes damage to the optic nerve, which can lead to visual loss and permanent blindness. Early glaucoma detection is therefore critical in order to avoid permanent blindness. The estimation of the cup-to-disc ratio (CDR) during an examination of the optical disc (OD) is used for the diagnosis of glaucoma. In this paper, we present the EDDense-Net segmentation network for the joint segmentation of OC and OD. The encoder and decoder in this network are made up of dense blocks with a grouped convolutional layer in each block, allowing the network to acquire and convey spatial information from the image while simultaneously reducing the network's complexity. To reduce spatial information loss, the optimal number of filters in all convolution layers were utilised. In semantic segmentation, dice pixel classification is employed in the decoder to alleviate the problem of class imbalance. The proposed network was evaluated on two publicly available datasets where it outperformed existing state-of-the-art methods in terms of accuracy and efficiency. For the diagnosis and analysis of glaucoma, this method can be used as a second opinion system to assist medical ophthalmologists.
GraSS: Contrastive Learning with Gradient Guided Sampling Strategy for Remote Sensing Image Semantic Segmentation
Jun 28, 2023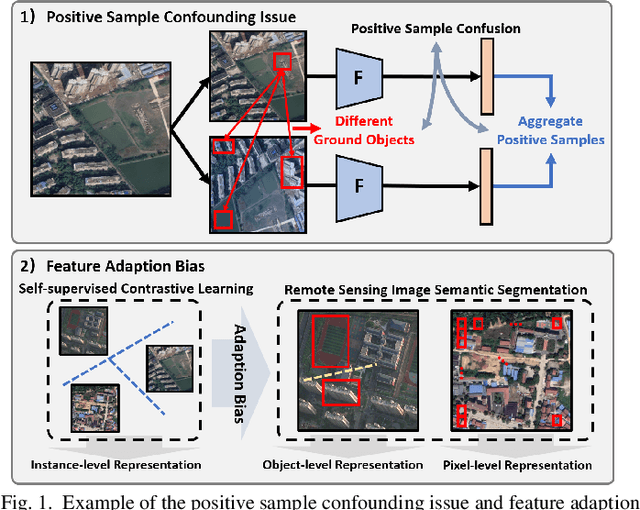
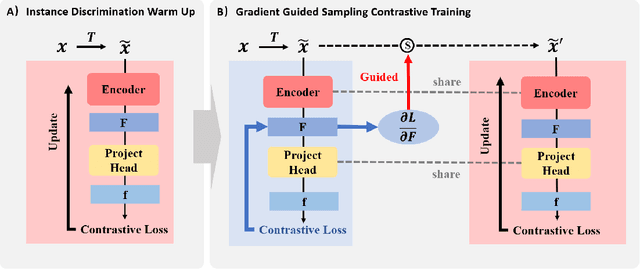
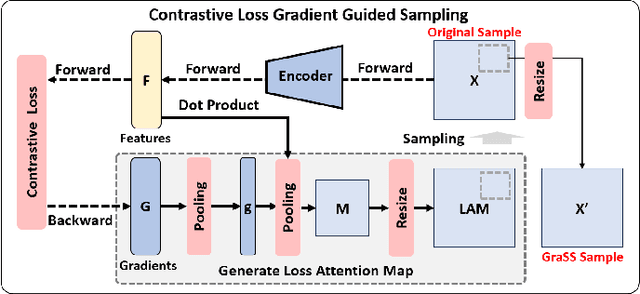
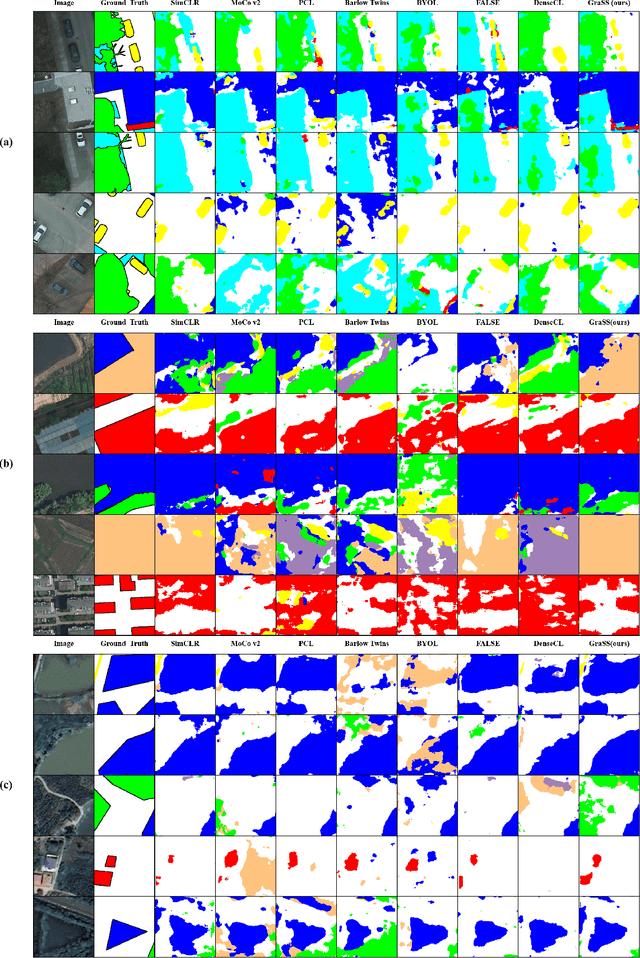
Self-supervised contrastive learning (SSCL) has achieved significant milestones in remote sensing image (RSI) understanding. Its essence lies in designing an unsupervised instance discrimination pretext task to extract image features from a large number of unlabeled images that are beneficial for downstream tasks. However, existing instance discrimination based SSCL suffer from two limitations when applied to the RSI semantic segmentation task: 1) Positive sample confounding issue; 2) Feature adaptation bias. It introduces a feature adaptation bias when applied to semantic segmentation tasks that require pixel-level or object-level features. In this study, We observed that the discrimination information can be mapped to specific regions in RSI through the gradient of unsupervised contrastive loss, these specific regions tend to contain singular ground objects. Based on this, we propose contrastive learning with Gradient guided Sampling Strategy (GraSS) for RSI semantic segmentation. GraSS consists of two stages: Instance Discrimination warm-up (ID warm-up) and Gradient guided Sampling contrastive training (GS training). The ID warm-up aims to provide initial discrimination information to the contrastive loss gradients. The GS training stage aims to utilize the discrimination information contained in the contrastive loss gradients and adaptively select regions in RSI patches that contain more singular ground objects, in order to construct new positive and negative samples. Experimental results on three open datasets demonstrate that GraSS effectively enhances the performance of SSCL in high-resolution RSI semantic segmentation. Compared to seven baseline methods from five different types of SSCL, GraSS achieves an average improvement of 1.57\% and a maximum improvement of 3.58\% in terms of mean intersection over the union. The source code is available at https://github.com/GeoX-Lab/GraSS
Fusing Sparsity with Deep Learning for Rotating Scatter Mask Gamma Imaging
Jul 29, 2023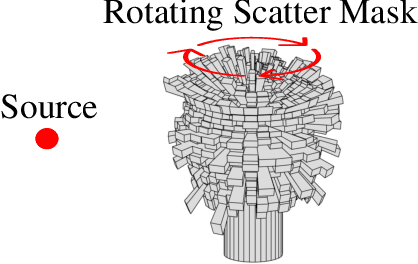
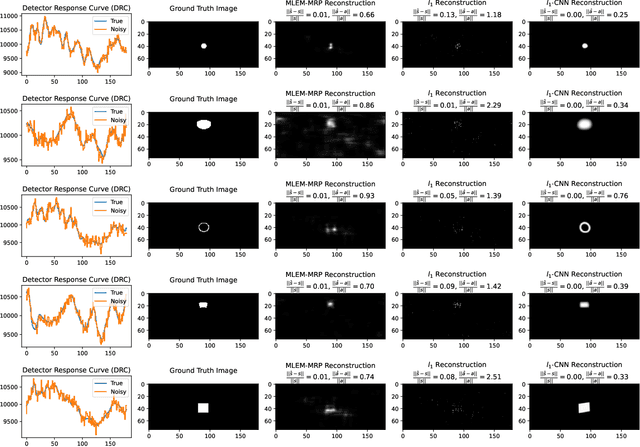
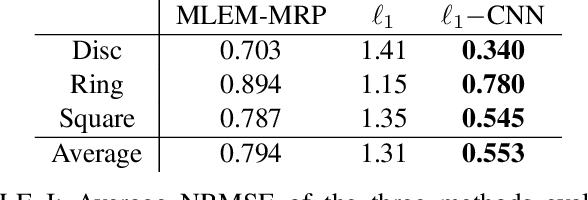
Many nuclear safety applications need fast, portable, and accurate imagers to better locate radiation sources. The Rotating Scatter Mask (RSM) system is an emerging device with the potential to meet these needs. The main challenge is the under-determined nature of the data acquisition process: the dimension of the measured signal is far less than the dimension of the image to be reconstructed. To address this challenge, this work aims to fuse model-based sparsity-promoting regularization and a data-driven deep neural network denoising image prior to perform image reconstruction. An efficient algorithm is developed and produces superior reconstructions relative to current approaches.
A Review on Classification of White Blood Cells Using Machine Learning Models
Aug 11, 2023

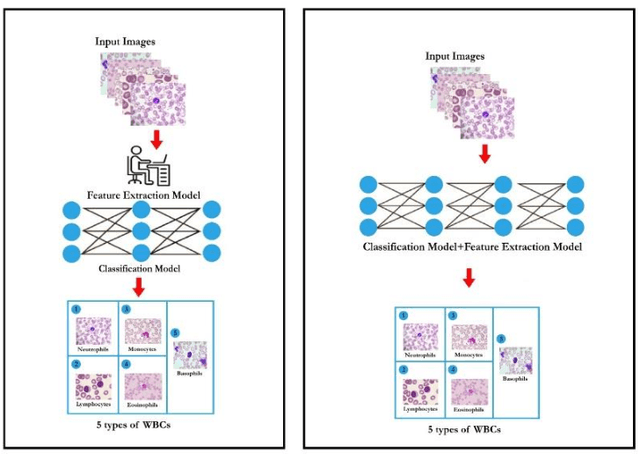
The machine learning (ML) and deep learning (DL) models contribute to exceptional medical image analysis improvement. The models enhance the prediction and improve the accuracy by prediction and classification. It helps the hematologist to diagnose the blood cancer and brain tumor based on calculations and facts. This review focuses on an in-depth analysis of modern techniques applied in the domain of medical image analysis of white blood cell classification. For this review, the methodologies are discussed that have used blood smear images, magnetic resonance imaging (MRI), X-rays, and similar medical imaging domains. The main impact of this review is to present a detailed analysis of machine learning techniques applied for the classification of white blood cells (WBCs). This analysis provides valuable insight, such as the most widely used techniques and best-performing white blood cell classification methods. It was found that in recent decades researchers have been using ML and DL for white blood cell classification, but there are still some challenges. 1) Availability of the dataset is the main challenge, and it could be resolved using data augmentation techniques. 2) Medical training of researchers is recommended to help them understand the structure of white blood cells and select appropriate classification models. 3) Advanced DL networks such as Generative Adversarial Networks, R-CNN, Fast R-CNN, and faster R-CNN can also be used in future techniques.
Enhancing Nucleus Segmentation with HARU-Net: A Hybrid Attention Based Residual U-Blocks Network
Aug 10, 2023
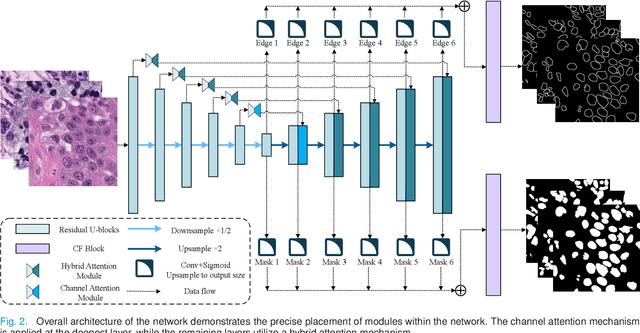
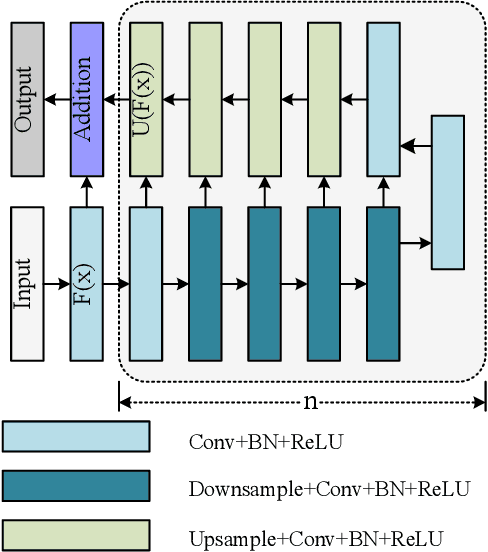
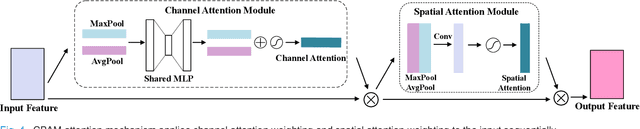
Nucleus image segmentation is a crucial step in the analysis, pathological diagnosis, and classification, which heavily relies on the quality of nucleus segmentation. However, the complexity of issues such as variations in nucleus size, blurred nucleus contours, uneven staining, cell clustering, and overlapping cells poses significant challenges. Current methods for nucleus segmentation primarily rely on nuclear morphology or contour-based approaches. Nuclear morphology-based methods exhibit limited generalization ability and struggle to effectively predict irregular-shaped nuclei, while contour-based extraction methods face challenges in accurately segmenting overlapping nuclei. To address the aforementioned issues, we propose a dual-branch network using hybrid attention based residual U-blocks for nucleus instance segmentation. The network simultaneously predicts target information and target contours. Additionally, we introduce a post-processing method that combines the target information and target contours to distinguish overlapping nuclei and generate an instance segmentation image. Within the network, we propose a context fusion block (CF-block) that effectively extracts and merges contextual information from the network. Extensive quantitative evaluations are conducted to assess the performance of our method. Experimental results demonstrate the superior performance of the proposed method compared to state-of-the-art approaches on the BNS, MoNuSeg, CoNSeg, and CPM-17 datasets.
Look at the Neighbor: Distortion-aware Unsupervised Domain Adaptation for Panoramic Semantic Segmentation
Aug 10, 2023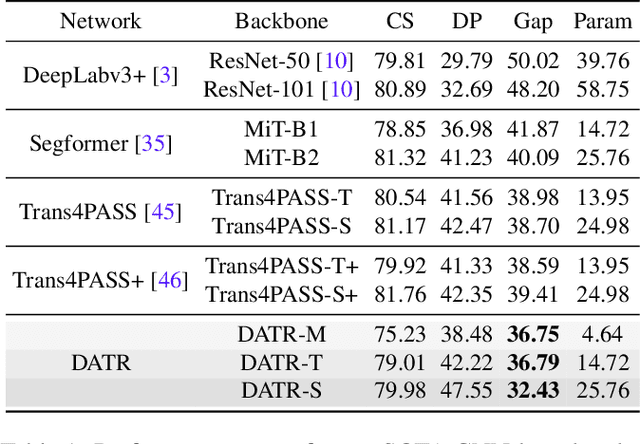
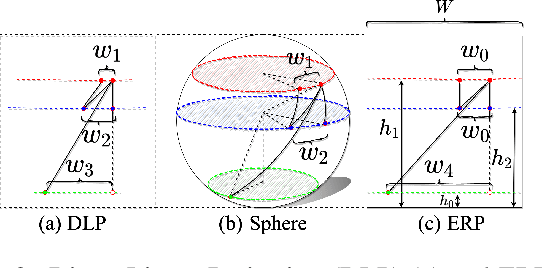
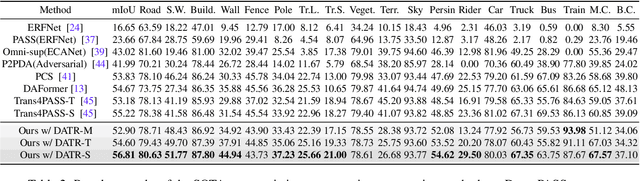
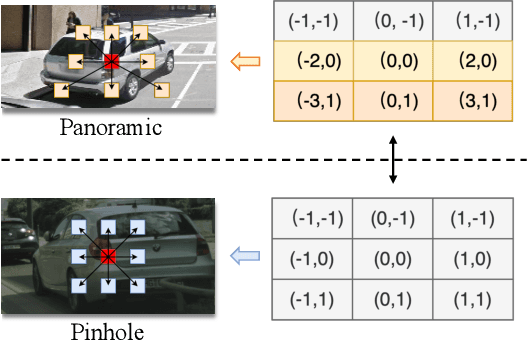
Endeavors have been recently made to transfer knowledge from the labeled pinhole image domain to the unlabeled panoramic image domain via Unsupervised Domain Adaptation (UDA). The aim is to tackle the domain gaps caused by the style disparities and distortion problem from the non-uniformly distributed pixels of equirectangular projection (ERP). Previous works typically focus on transferring knowledge based on geometric priors with specially designed multi-branch network architectures. As a result, considerable computational costs are induced, and meanwhile, their generalization abilities are profoundly hindered by the variation of distortion among pixels. In this paper, we find that the pixels' neighborhood regions of the ERP indeed introduce less distortion. Intuitively, we propose a novel UDA framework that can effectively address the distortion problems for panoramic semantic segmentation. In comparison, our method is simpler, easier to implement, and more computationally efficient. Specifically, we propose distortion-aware attention (DA) capturing the neighboring pixel distribution without using any geometric constraints. Moreover, we propose a class-wise feature aggregation (CFA) module to iteratively update the feature representations with a memory bank. As such, the feature similarity between two domains can be consistently optimized. Extensive experiments show that our method achieves new state-of-the-art performance while remarkably reducing 80% parameters.
Benchmarking Algorithmic Bias in Face Recognition: An Experimental Approach Using Synthetic Faces and Human Evaluation
Aug 10, 2023

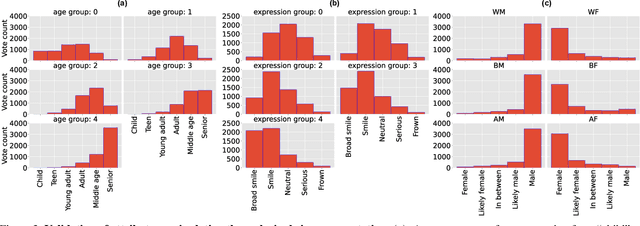
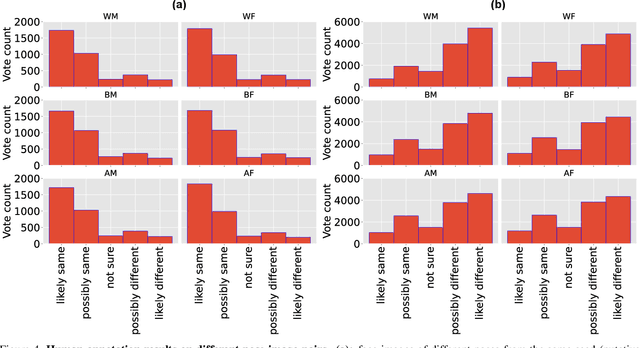
We propose an experimental method for measuring bias in face recognition systems. Existing methods to measure bias depend on benchmark datasets that are collected in the wild and annotated for protected (e.g., race, gender) and non-protected (e.g., pose, lighting) attributes. Such observational datasets only permit correlational conclusions, e.g., "Algorithm A's accuracy is different on female and male faces in dataset X.". By contrast, experimental methods manipulate attributes individually and thus permit causal conclusions, e.g., "Algorithm A's accuracy is affected by gender and skin color." Our method is based on generating synthetic faces using a neural face generator, where each attribute of interest is modified independently while leaving all other attributes constant. Human observers crucially provide the ground truth on perceptual identity similarity between synthetic image pairs. We validate our method quantitatively by evaluating race and gender biases of three research-grade face recognition models. Our synthetic pipeline reveals that for these algorithms, accuracy is lower for Black and East Asian population subgroups. Our method can also quantify how perceptual changes in attributes affect face identity distances reported by these models. Our large synthetic dataset, consisting of 48,000 synthetic face image pairs (10,200 unique synthetic faces) and 555,000 human annotations (individual attributes and pairwise identity comparisons) is available to researchers in this important area.
Informative Scene Graph Generation via Debiasing
Aug 10, 2023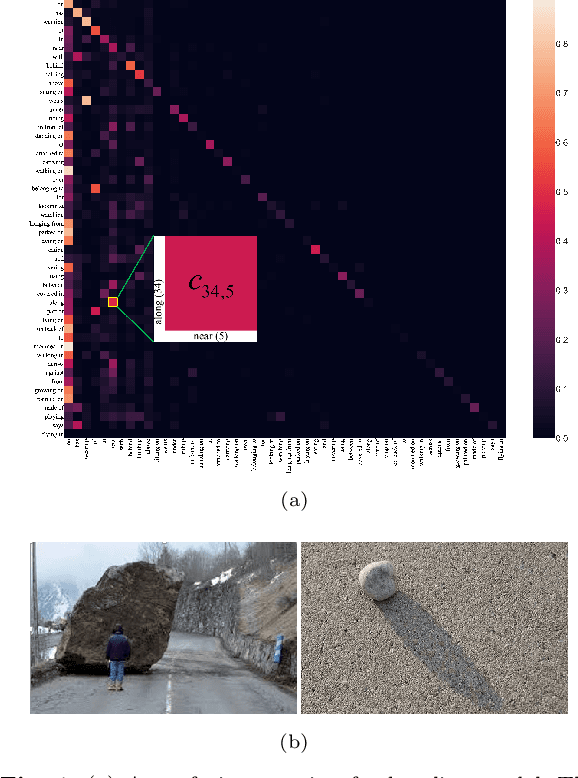
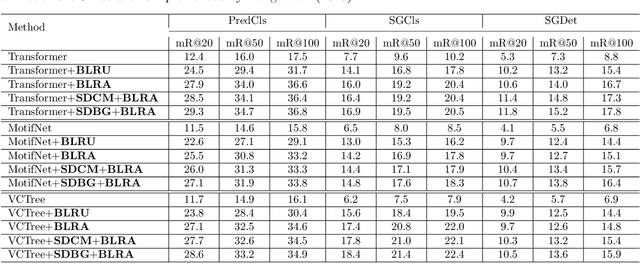

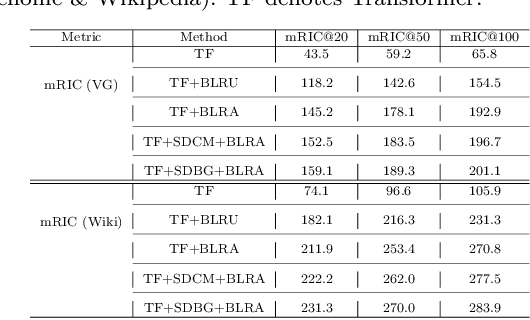
Scene graph generation aims to detect visual relationship triplets, (subject, predicate, object). Due to biases in data, current models tend to predict common predicates, e.g. "on" and "at", instead of informative ones, e.g. "standing on" and "looking at". This tendency results in the loss of precise information and overall performance. If a model only uses "stone on road" rather than "stone blocking road" to describe an image, it may be a grave misunderstanding. We argue that this phenomenon is caused by two imbalances: semantic space level imbalance and training sample level imbalance. For this problem, we propose DB-SGG, an effective framework based on debiasing but not the conventional distribution fitting. It integrates two components: Semantic Debiasing (SD) and Balanced Predicate Learning (BPL), for these imbalances. SD utilizes a confusion matrix and a bipartite graph to construct predicate relationships. BPL adopts a random undersampling strategy and an ambiguity removing strategy to focus on informative predicates. Benefiting from the model-agnostic process, our method can be easily applied to SGG models and outperforms Transformer by 136.3%, 119.5%, and 122.6% on mR@20 at three SGG sub-tasks on the SGG-VG dataset. Our method is further verified on another complex SGG dataset (SGG-GQA) and two downstream tasks (sentence-to-graph retrieval and image captioning).