 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Continuous Reasoning via Asymmetric Mutual Variational Learning
Jul 01, 2026Multimodal Large Language Models (MLLMs) are often constrained by a language-space bottleneck, forcing complex visual reasoning into discrete tokens which can lose perceptual nuance. A promising alternative is continuous latent reasoning, where the goal is to discover implicit reasoning pathways that bridge the multimodal query and the final answer. However, this introduces a severe train-inference mismatch: a training-time posterior, conditioned on the ground-truth answer, can exploit answer-dependent shortcuts. Standard variational training then forces the inference-time prior to mimic a posterior that has access to information unavailable at test time, leading to poor performance. To address this, we propose Asymmetric Mutual Variational Learning (AMVL), a framework that resolves this mismatch via a bidirectional calibration objective. A forward KL divergence trains the target-agnostic prior to match the posterior, while a novel reverse KL divergence simultaneously regularizes the posterior, preventing it from collapsing into inference-incompatible regions and mitigating this ``answer leakage''. We provide theoretical analysis formalizing this leakage as prior contamination and prove that our dual-KL objective reduces it. We instantiate AMVL in a latent-integrated MLLM and show that it consistently outperforms strong discrete and latent-reasoning baselines, improving the average score on the complex BLINK benchmark by +10.83 and achieving gains of up to +32.00 on individual reasoning tasks, with analyses confirming improved latent-space stability.
Janus-LoRA: A Balanced Low-Rank Adaptation for Continual Learning
May 27, 2026Low-Rank Adaptation (LoRA) has emerged as a promising paradigm for Continual Learning. It independently updates its low-rank factors ($A$ and $B$), creating a composite update to the full weight matrix through their interaction. To prevent catastrophic forgetting, this update should remain orthogonal to the task-specific subspace that contains previously learned knowledge. However, we identify that this composite update systematically violates this orthogonality, reintroducing interference and undermining stability. Furthermore, naively enforcing this orthogonality compromises plasticity, disrupting the delicate stability-plasticity trade-off. To resolve these issues, we propose \textbf{Janus-LoRA}, a framework that restores this balance through two novel components. Specifically, we first introduce Gradient Rectification, a closed-form solution that mathematically decouples LoRA's factor updates, enforcing orthogonality against the historical knowledge subspace identified by an efficient Online Estimation. Next, to enhance plasticity, we introduce a Decoupled Margin Loss that promotes feature-level separation by pushing new feature representations away from old ones, thus creating distinct, low-interference regions for new learning. Comprehensive experiments on challenging benchmarks demonstrate that by harmonizing parameter-level orthogonality with feature-level separation, Janus-LoRA achieves a superior balance and establishes new state-of-the-art performance.
OpAgent: Operator Agent for Web Navigation
Feb 14, 2026To fulfill user instructions, autonomous web agents must contend with the inherent complexity and volatile nature of real-world websites. Conventional paradigms predominantly rely on Supervised Fine-Tuning (SFT) or Offline Reinforcement Learning (RL) using static datasets. However, these methods suffer from severe distributional shifts, as offline trajectories fail to capture the stochastic state transitions and real-time feedback of unconstrained wide web environments. In this paper, we propose a robust Online Reinforcement Learning WebAgent, designed to optimize its policy through direct, iterative interactions with unconstrained wide websites. Our approach comprises three core innovations: 1) Hierarchical Multi-Task Fine-tuning: We curate a comprehensive mixture of datasets categorized by functional primitives -- Planning, Acting, and Grounding -- establishing a Vision-Language Model (VLM) with strong instruction-following capabilities for Web GUI tasks. 2) Online Agentic RL in the Wild: We develop an online interaction environment and fine-tune the VLM using a specialized RL pipeline. We introduce a Hybrid Reward Mechanism that combines a ground-truth-agnostic WebJudge for holistic outcome assessment with a Rule-based Decision Tree (RDT) for progress reward. This system effectively mitigates the credit assignment challenge in long-horizon navigation. Notably, our RL-enhanced model achieves a 38.1\% success rate (pass@5) on WebArena, outperforming all existing monolithic baselines. 3) Operator Agent: We introduce a modular agentic framework, namely \textbf{OpAgent}, orchestrating a Planner, Grounder, Reflector, and Summarizer. This synergy enables robust error recovery and self-correction, elevating the agent's performance to a new State-of-the-Art (SOTA) success rate of \textbf{71.6\%}.
From One-to-One to Many-to-Many: Dynamic Cross-Layer Injection for Deep Vision-Language Fusion
Jan 15, 2026Vision-Language Models (VLMs) create a severe visual feature bottleneck by using a crude, asymmetric connection that links only the output of the vision encoder to the input of the large language model (LLM). This static architecture fundamentally limits the ability of LLMs to achieve comprehensive alignment with hierarchical visual knowledge, compromising their capacity to accurately integrate local details with global semantics into coherent reasoning. To resolve this, we introduce Cross-Layer Injection (CLI), a novel and lightweight framework that forges a dynamic many-to-many bridge between the two modalities. CLI consists of two synergistic, parameter-efficient components: an Adaptive Multi-Projection (AMP) module that harmonizes features from diverse vision layers, and an Adaptive Gating Fusion (AGF) mechanism that empowers the LLM to selectively inject the most relevant visual information based on its real-time decoding context. We validate the effectiveness and versatility of CLI by integrating it into LLaVA-OneVision and LLaVA-1.5. Extensive experiments on 18 diverse benchmarks demonstrate significant performance improvements, establishing CLI as a scalable paradigm that unlocks deeper multimodal understanding by granting LLMs on-demand access to the full visual hierarchy.
Automatic Left Ventricular Cavity Segmentation via Deep Spatial Sequential Network in 4D Computed Tomography Studies
Dec 17, 2024



Automated segmentation of left ventricular cavity (LVC) in temporal cardiac image sequences (multiple time points) is a fundamental requirement for quantitative analysis of its structural and functional changes. Deep learning based methods for the segmentation of LVC are the state of the art; however, these methods are generally formulated to work on single time points, and fails to exploit the complementary information from the temporal image sequences that can aid in segmentation accuracy and consistency among the images across the time points. Furthermore, these segmentation methods perform poorly in segmenting the end-systole (ES) phase images, where the left ventricle deforms to the smallest irregular shape, and the boundary between the blood chamber and myocardium becomes inconspicuous. To overcome these limitations, we propose a new method to automatically segment temporal cardiac images where we introduce a spatial sequential (SS) network to learn the deformation and motion characteristics of the LVC in an unsupervised manner; these characteristics were then integrated with sequential context information derived from bi-directional learning (BL) where both chronological and reverse-chronological directions of the image sequence were used. Our experimental results on a cardiac computed tomography (CT) dataset demonstrated that our spatial-sequential network with bi-directional learning (SS-BL) method outperformed existing methods for LVC segmentation. Our method was also applied to MRI cardiac dataset and the results demonstrated the generalizability of our method.
Informative Scene Graph Generation via Debiasing
Aug 10, 2023Scene graph generation aims to detect visual relationship triplets, (subject, predicate, object). Due to biases in data, current models tend to predict common predicates, e.g. "on" and "at", instead of informative ones, e.g. "standing on" and "looking at". This tendency results in the loss of precise information and overall performance. If a model only uses "stone on road" rather than "stone blocking road" to describe an image, it may be a grave misunderstanding. We argue that this phenomenon is caused by two imbalances: semantic space level imbalance and training sample level imbalance. For this problem, we propose DB-SGG, an effective framework based on debiasing but not the conventional distribution fitting. It integrates two components: Semantic Debiasing (SD) and Balanced Predicate Learning (BPL), for these imbalances. SD utilizes a confusion matrix and a bipartite graph to construct predicate relationships. BPL adopts a random undersampling strategy and an ambiguity removing strategy to focus on informative predicates. Benefiting from the model-agnostic process, our method can be easily applied to SGG models and outperforms Transformer by 136.3%, 119.5%, and 122.6% on mR@20 at three SGG sub-tasks on the SGG-VG dataset. Our method is further verified on another complex SGG dataset (SGG-GQA) and two downstream tasks (sentence-to-graph retrieval and image captioning).
Local-Global Information Interaction Debiasing for Dynamic Scene Graph Generation
Aug 10, 2023



The task of dynamic scene graph generation (DynSGG) aims to generate scene graphs for given videos, which involves modeling the spatial-temporal information in the video. However, due to the long-tailed distribution of samples in the dataset, previous DynSGG models fail to predict the tail predicates. We argue that this phenomenon is due to previous methods that only pay attention to the local spatial-temporal information and neglect the consistency of multiple frames. To solve this problem, we propose a novel DynSGG model based on multi-task learning, DynSGG-MTL, which introduces the local interaction information and global human-action interaction information. The interaction between objects and frame features makes the model more fully understand the visual context of the single image. Long-temporal human actions supervise the model to generate multiple scene graphs that conform to the global constraints and avoid the model being unable to learn the tail predicates. Extensive experiments on Action Genome dataset demonstrate the efficacy of our proposed framework, which not only improves the dynamic scene graph generation but also alleviates the long-tail problem.
Learning To Generate Scene Graph from Head to Tail
Jun 23, 2022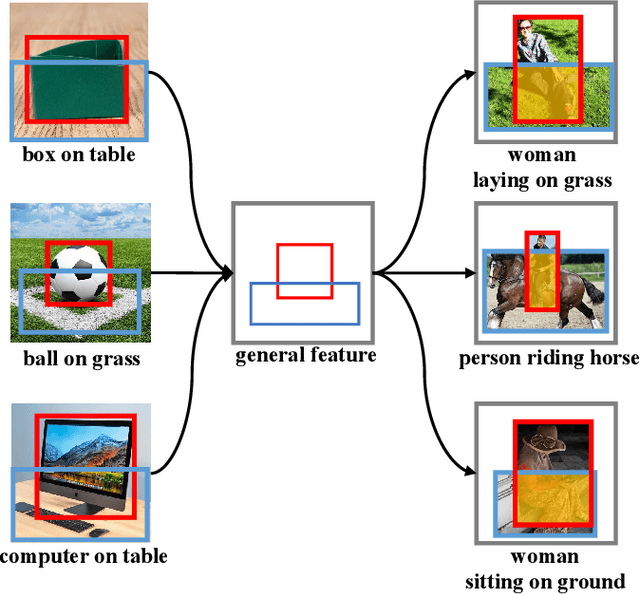
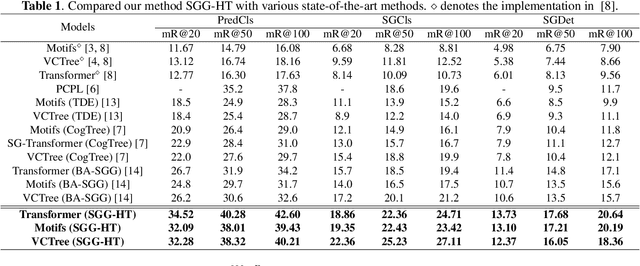
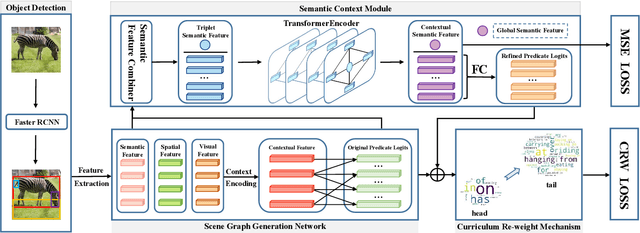
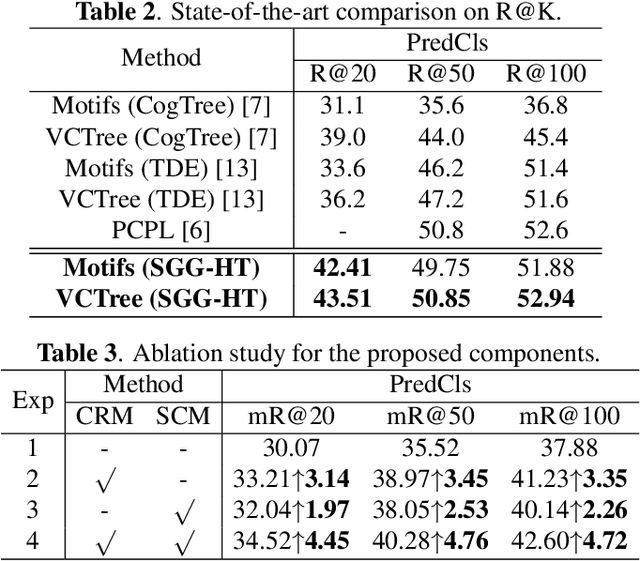
Scene Graph Generation (SGG) represents objects and their interactions with a graph structure. Recently, many works are devoted to solving the imbalanced problem in SGG. However, underestimating the head predicates in the whole training process, they wreck the features of head predicates that provide general features for tail ones. Besides, assigning excessive attention to the tail predicates leads to semantic deviation. Based on this, we propose a novel SGG framework, learning to generate scene graphs from Head to Tail (SGG-HT), containing Curriculum Re-weight Mechanism (CRM) and Semantic Context Module (SCM). CRM learns head/easy samples firstly for robust features of head predicates and then gradually focuses on tail/hard ones. SCM is proposed to relieve semantic deviation by ensuring the semantic consistency between the generated scene graph and the ground truth in global and local representations. Experiments show that SGG-HT significantly alleviates the biased problem and chieves state-of-the-art performances on Visual Genome.
Fine-Grained Predicates Learning for Scene Graph Generation
Apr 08, 2022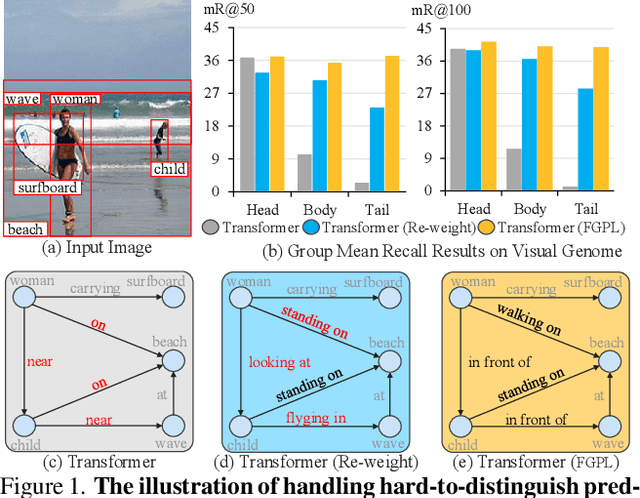
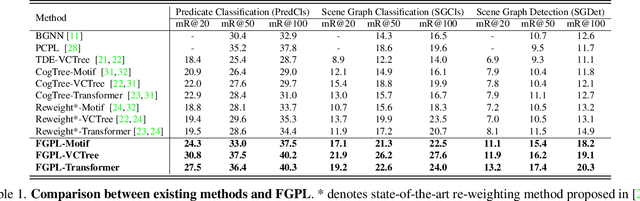
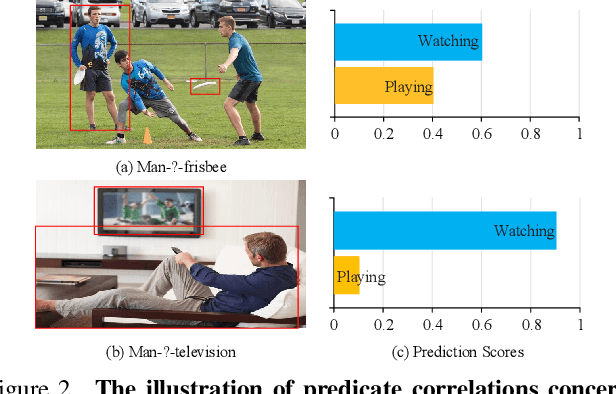
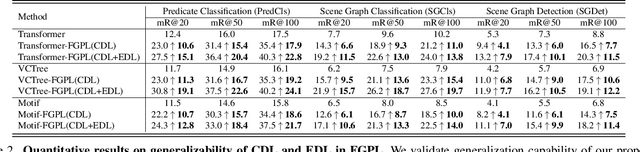
The performance of current Scene Graph Generation models is severely hampered by some hard-to-distinguish predicates, e.g., "woman-on/standing on/walking on-beach" or "woman-near/looking at/in front of-child". While general SGG models are prone to predict head predicates and existing re-balancing strategies prefer tail categories, none of them can appropriately handle these hard-to-distinguish predicates. To tackle this issue, inspired by fine-grained image classification, which focuses on differentiating among hard-to-distinguish object classes, we propose a method named Fine-Grained Predicates Learning (FGPL) which aims at differentiating among hard-to-distinguish predicates for Scene Graph Generation task. Specifically, we first introduce a Predicate Lattice that helps SGG models to figure out fine-grained predicate pairs. Then, utilizing the Predicate Lattice, we propose a Category Discriminating Loss and an Entity Discriminating Loss, which both contribute to distinguishing fine-grained predicates while maintaining learned discriminatory power over recognizable ones. The proposed model-agnostic strategy significantly boosts the performances of three benchmark models (Transformer, VCTree, and Motif) by 22.8\%, 24.1\% and 21.7\% of Mean Recall (mR@100) on the Predicate Classification sub-task, respectively. Our model also outperforms state-of-the-art methods by a large margin (i.e., 6.1\%, 4.6\%, and 3.2\% of Mean Recall (mR@100)) on the Visual Genome dataset.
One-shot Scene Graph Generation
Feb 26, 2022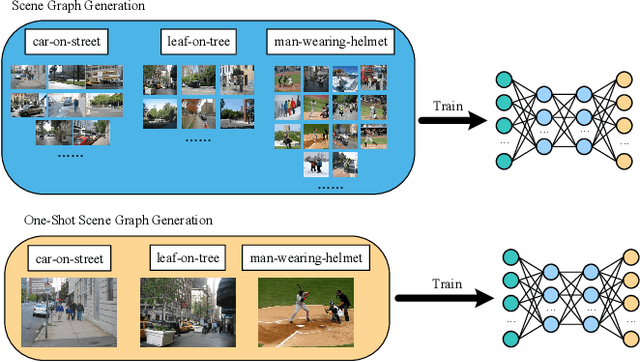
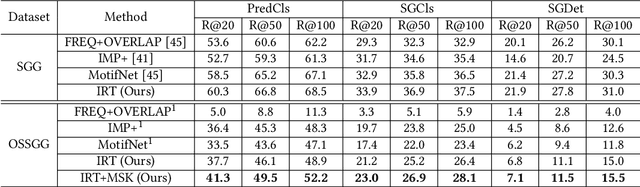
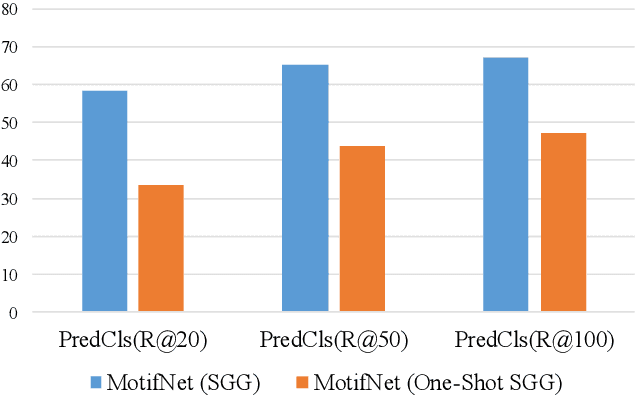
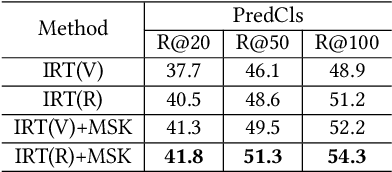
As a structured representation of the image content, the visual scene graph (visual relationship) acts as a bridge between computer vision and natural language processing. Existing models on the scene graph generation task notoriously require tens or hundreds of labeled samples. By contrast, human beings can learn visual relationships from a few or even one example. Inspired by this, we design a task named One-Shot Scene Graph Generation, where each relationship triplet (e.g., "dog-has-head") comes from only one labeled example. The key insight is that rather than learning from scratch, one can utilize rich prior knowledge. In this paper, we propose Multiple Structured Knowledge (Relational Knowledge and Commonsense Knowledge) for the one-shot scene graph generation task. Specifically, the Relational Knowledge represents the prior knowledge of relationships between entities extracted from the visual content, e.g., the visual relationships "standing in", "sitting in", and "lying in" may exist between "dog" and "yard", while the Commonsense Knowledge encodes "sense-making" knowledge like "dog can guard yard". By organizing these two kinds of knowledge in a graph structure, Graph Convolution Networks (GCNs) are used to extract knowledge-embedded semantic features of the entities. Besides, instead of extracting isolated visual features from each entity generated by Faster R-CNN, we utilize an Instance Relation Transformer encoder to fully explore their context information. Based on a constructed one-shot dataset, the experimental results show that our method significantly outperforms existing state-of-the-art methods by a large margin. Ablation studies also verify the effectiveness of the Instance Relation Transformer encoder and the Multiple Structured Knowledge.