 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prompt Learning for Oriented Power Transmission Tower Detection in High-Resolution SAR Images
Apr 01, 2024
Detecting transmission towers from synthetic aperture radar (SAR) images remains a challenging task due to the comparatively small size and side-looking geometry, with background clutter interference frequently hindering tower identification. A large number of interfering signals superimposes the return signal from the tower. We found that localizing or prompting positions of power transmission towers is beneficial to address this obstacle. Based on this revelation, this paper introduces prompt learning into the oriented object detector (P2Det) for multimodal information learning. P2Det contains the sparse prompt coding and cross-attention between the multimodal data. Specifically, the sparse prompt encoder (SPE) is proposed to represent point locations, converting prompts into sparse embeddings. The image embeddings are generated through the Transformer layers. Then a two-way fusion module (TWFM) is proposed to calculate the cross-attention of the two different embeddings. The interaction of image-level and prompt-level features is utilized to address the clutter interference. A shape-adaptive refinement module (SARM) is proposed to reduce the effect of aspect ratio. Extensive experiments demonstrated the effectiveness of the proposed model on high-resolution SAR images. P2Det provides a novel insight for multimodal object detection due to its competitive performance.
Teeth-SEG: An Efficient Instance Segmentation Framework for Orthodontic Treatment based on Anthropic Prior Knowledge
Apr 01, 2024Teeth localization, segmentation, and labeling in 2D images have great potential in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, general instance segmentation frameworks are incompetent due to 1) the subtle differences between some teeth' shapes (e.g., maxillary first premolar and second premolar), 2) the teeth's position and shape variation across subjects, and 3) the presence of abnormalities in the dentition (e.g., caries and edentulism). To address these problems, we propose a ViT-based framework named TeethSEG, which consists of stacked Multi-Scale Aggregation (MSA) blocks and an Anthropic Prior Knowledge (APK) layer. Specifically, to compose the two modules, we design 1) a unique permutation-based upscaler to ensure high efficiency while establishing clear segmentation boundaries with 2) multi-head self/cross-gating layers to emphasize particular semantics meanwhile maintaining the divergence between token embeddings. Besides, we collect 3) the first open-sourced intraoral image dataset IO150K, which comprises over 150k intraoral photos, and all photos are annotated by orthodontists using a human-machine hybrid algorithm. Experiments on IO150K demonstrate that our TeethSEG outperforms the state-of-the-art segmentation models on dental image segmentation.
Roadside Monocular 3D Detection via 2D Detection Prompting
Apr 04, 2024The problem of roadside monocular 3D detection requires detecting objects of interested classes in a 2D RGB frame and predicting their 3D information such as locations in bird's-eye-view (BEV). It has broad applications in traffic control, vehicle-vehicle communication, and vehicle-infrastructure cooperative perception. To approach this problem, we present a novel and simple method by prompting the 3D detector using 2D detections. Our method builds on a key insight that, compared with 3D detectors, a 2D detector is much easier to train and performs significantly better w.r.t detections on the 2D image plane. That said, one can exploit 2D detections of a well-trained 2D detector as prompts to a 3D detector, being trained in a way of inflating such 2D detections to 3D towards 3D detection. To construct better prompts using the 2D detector, we explore three techniques: (a) concatenating both 2D and 3D detectors' features, (b) attentively fusing 2D and 3D detectors' features, and (c) encoding predicted 2D boxes x, y, width, height, label and attentively fusing such with the 3D detector's features. Surprisingly, the third performs the best. Moreover, we present a yaw tuning tactic and a class-grouping strategy that merges classes based on their functionality; these techniques improve 3D detection performance further. Comprehensive ablation studies and extensive experiments demonstrate that our method resoundingly outperforms prior works, achieving the state-of-the-art on two large-scale roadside 3D detection benchmarks.
FairRAG: Fair Human Generation via Fair Retrieval Augmentation
Mar 29, 2024
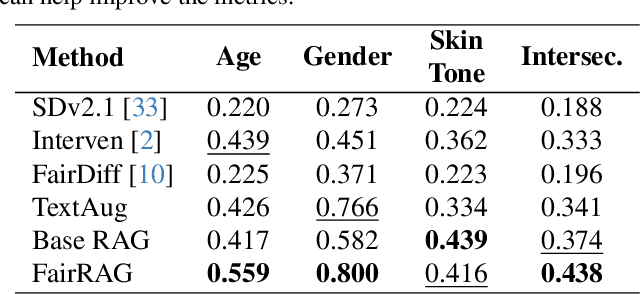
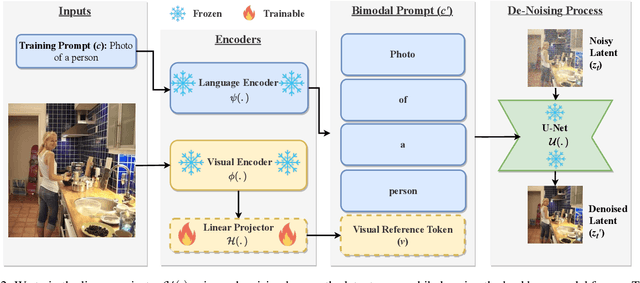
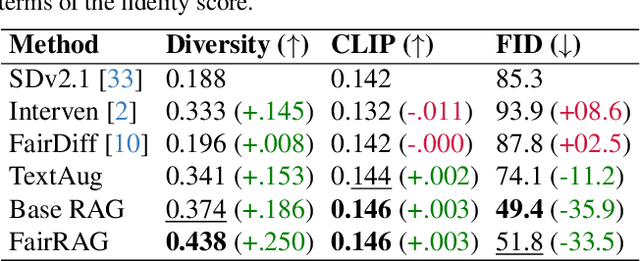
Existing text-to-image generative models reflect or even amplify societal biases ingrained in their training data. This is especially concerning for human image generation where models are biased against certain demographic groups. Existing attempts to rectify this issue are hindered by the inherent limitations of the pre-trained models and fail to substantially improve demographic diversity. In this work, we introduce Fair Retrieval Augmented Generation (FairRAG), a novel framework that conditions pre-trained generative models on reference images retrieved from an external image database to improve fairness in human generation. FairRAG enables conditioning through a lightweight linear module that projects reference images into the textual space. To enhance fairness, FairRAG applies simple-yet-effective debiasing strategies, providing images from diverse demographic groups during the generative process. Extensive experiments demonstrate that FairRAG outperforms existing methods in terms of demographic diversity, image-text alignment, and image fidelity while incurring minimal computational overhead during inference.
Attention-based Shape-Deformation Networks for Artifact-Free Geometry Reconstruction of Lumbar Spine from MR Images
Mar 30, 2024Lumbar disc degeneration, a progressive structural wear and tear of lumbar intervertebral disc, is regarded as an essential role on low back pain, a significant global health concern. Automated lumbar spine geometry reconstruction from MR images will enable fast measurement of medical parameters to evaluate the lumbar status, in order to determine a suitable treatment. Existing image segmentation-based techniques often generate erroneous segments or unstructured point clouds, unsuitable for medical parameter measurement. In this work, we present TransDeformer: a novel attention-based deep learning approach that reconstructs the contours of the lumbar spine with high spatial accuracy and mesh correspondence across patients, and we also present a variant of TransDeformer for error estimation. Specially, we devise new attention modules with a new attention formula, which integrates image features and tokenized contour features to predict the displacements of the points on a shape template without the need for image segmentation. The deformed template reveals the lumbar spine geometry in the input image. We develop a multi-stage training strategy to enhance model robustness with respect to template initialization. Experiment results show that our TransDeformer generates artifact-free geometry outputs, and its variant predicts the error of a reconstructed geometry. Our code is available at https://github.com/linchenq/TransDeformer-Mesh.
One-Step Image Translation with Text-to-Image Models
Mar 18, 2024
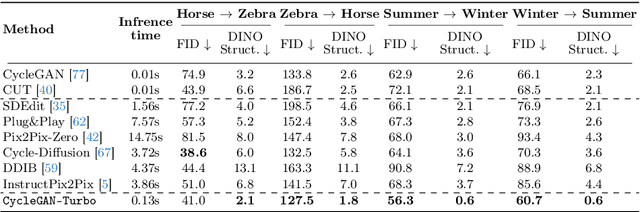
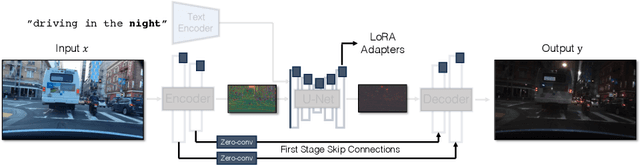
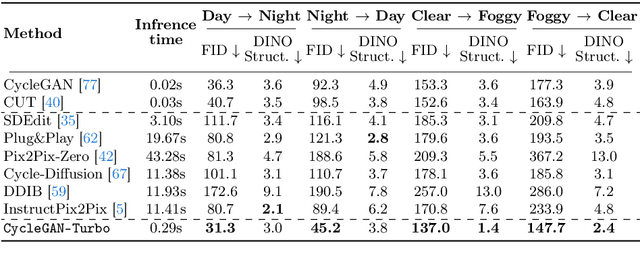
In this work, we address two limitations of existing conditional diffusion models: their slow inference speed due to the iterative denoising process and their reliance on paired data for model fine-tuning. To tackle these issues, we introduce a general method for adapting a single-step diffusion model to new tasks and domains through adversarial learning objectives. Specifically, we consolidate various modules of the vanilla latent diffusion model into a single end-to-end generator network with small trainable weights, enhancing its ability to preserve the input image structure while reducing overfitting. We demonstrate that, for unpaired settings, our model CycleGAN-Turbo outperforms existing GAN-based and diffusion-based methods for various scene translation tasks, such as day-to-night conversion and adding/removing weather effects like fog, snow, and rain. We extend our method to paired settings, where our model pix2pix-Turbo is on par with recent works like Control-Net for Sketch2Photo and Edge2Image, but with a single-step inference. This work suggests that single-step diffusion models can serve as strong backbones for a range of GAN learning objectives. Our code and models are available at https://github.com/GaParmar/img2img-turbo.
Ultra-High-Resolution Image Synthesis with Pyramid Diffusion Model
Mar 19, 2024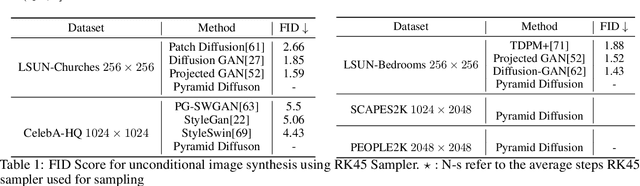
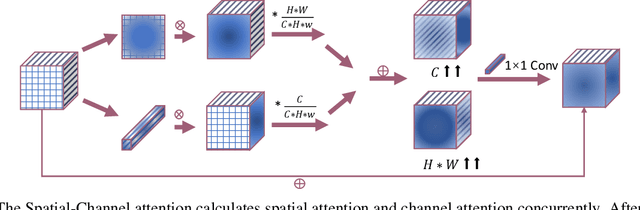
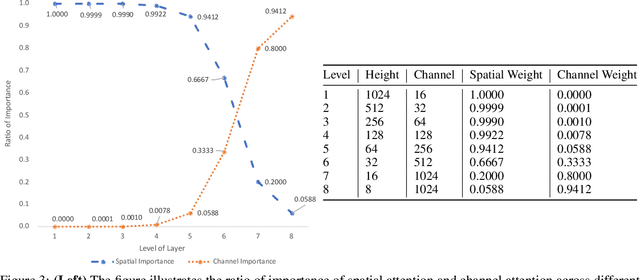
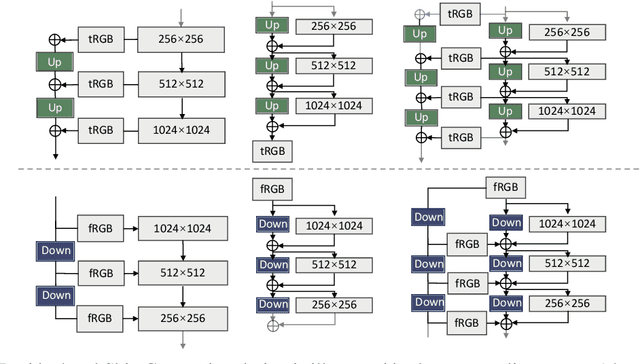
We introduce the Pyramid Diffusion Model (PDM), a novel architecture designed for ultra-high-resolution image synthesis. PDM utilizes a pyramid latent representation, providing a broader design space that enables more flexible, structured, and efficient perceptual compression which enable AutoEncoder and Network of Diffusion to equip branches and deeper layers. To enhance PDM's capabilities for generative tasks, we propose the integration of Spatial-Channel Attention and Res-Skip Connection, along with the utilization of Spectral Norm and Decreasing Dropout Strategy for the Diffusion Network and AutoEncoder. In summary, PDM achieves the synthesis of images with a 2K resolution for the first time, demonstrated on two new datasets comprising images of sizes 2048x2048 pixels and 2048x1024 pixels respectively. We believe that this work offers an alternative approach to designing scalable image generative models, while also providing incremental reinforcement for existing frameworks.
Multi-task Magnetic Resonance Imaging Reconstruction using Meta-learning
Mar 29, 2024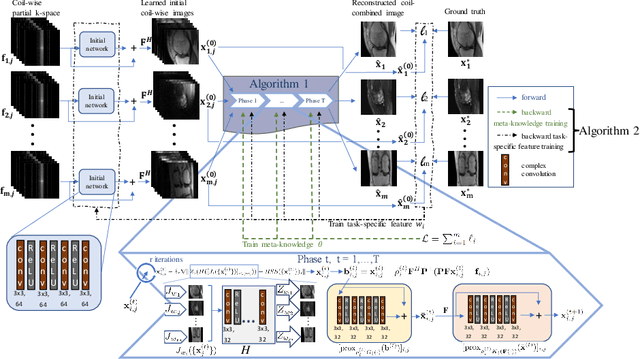

Using single-task deep learning methods to reconstruct Magnetic Resonance Imaging (MRI) data acquired with different imaging sequences is inherently challenging. The trained deep learning model typically lacks generalizability, and the dissimilarity among image datasets with different types of contrast leads to suboptimal learning performance. This paper proposes a meta-learning approach to efficiently learn image features from multiple MR image datasets. Our algorithm can perform multi-task learning to simultaneously reconstruct MR images acquired using different imaging sequences with different image contrasts. The experiment results demonstrate the ability of our new meta-learning reconstruction method to successfully reconstruct highly-undersampled k-space data from multiple MRI datasets simultaneously, outperforming other compelling reconstruction methods previously developed for single-task learning.
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
Mar 21, 2024In this study, we introduce a methodology for human image animation by leveraging a 3D human parametric model within a latent diffusion framework to enhance shape alignment and motion guidance in curernt human generative techniques. The methodology utilizes the SMPL(Skinned Multi-Person Linear) model as the 3D human parametric model to establish a unified representation of body shape and pose. This facilitates the accurate capture of intricate human geometry and motion characteristics from source videos. Specifically, we incorporate rendered depth images, normal maps, and semantic maps obtained from SMPL sequences, alongside skeleton-based motion guidance, to enrich the conditions to the latent diffusion model with comprehensive 3D shape and detailed pose attributes. A multi-layer motion fusion module, integrating self-attention mechanisms, is employed to fuse the shape and motion latent representations in the spatial domain. By representing the 3D human parametric model as the motion guidance, we can perform parametric shape alignment of the human body between the reference image and the source video motion. Experimental evaluations conducted on benchmark datasets demonstrate the methodology's superior ability to generate high-quality human animations that accurately capture both pose and shape variations. Furthermore, our approach also exhibits superior generalization capabilities on the proposed wild dataset. Project page: https://fudan-generative-vision.github.io/champ.
TimeRewind: Rewinding Time with Image-and-Events Video Diffusion
Mar 20, 2024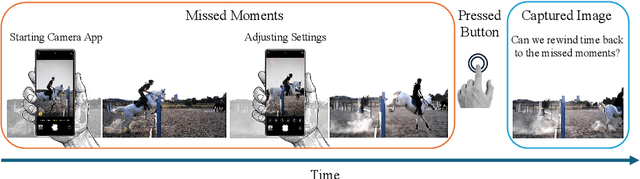

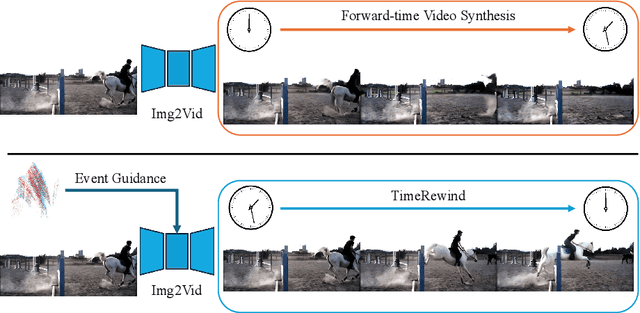
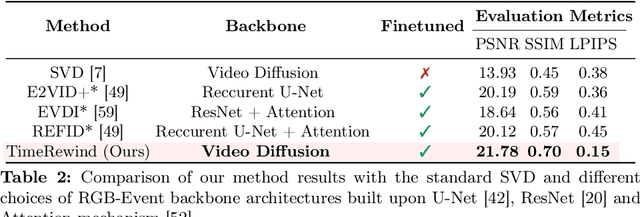
This paper addresses the novel challenge of ``rewinding'' time from a single captured image to recover the fleeting moments missed just before the shutter button is pressed. This problem poses a significant challenge in computer vision and computational photography, as it requires predicting plausible pre-capture motion from a single static frame, an inherently ill-posed task due to the high degree of freedom in potential pixel movements. We overcome this challenge by leveraging the emerging technology of neuromorphic event cameras, which capture motion information with high temporal resolution, and integrating this data with advanced image-to-video diffusion models. Our proposed framework introduces an event motion adaptor conditioned on event camera data, guiding the diffusion model to generate videos that are visually coherent and physically grounded in the captured events. Through extensive experimentation, we demonstrate the capability of our approach to synthesize high-quality videos that effectively ``rewind'' time, showcasing the potential of combining event camera technology with generative models. Our work opens new avenues for research at the intersection of computer vision, computational photography, and generative modeling, offering a forward-thinking solution to capturing missed moments and enhancing future consumer cameras and smartphones. Please see the project page at https://timerewind.github.io/ for video results and code release.