 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Group Inference for Diverse and High-Quality Generation
Aug 21, 2025Generative models typically sample outputs independently, and recent inference-time guidance and scaling algorithms focus on improving the quality of individual samples. However, in real-world applications, users are often presented with a set of multiple images (e.g., 4-8) for each prompt, where independent sampling tends to lead to redundant results, limiting user choices and hindering idea exploration. In this work, we introduce a scalable group inference method that improves both the diversity and quality of a group of samples. We formulate group inference as a quadratic integer assignment problem: candidate outputs are modeled as graph nodes, and a subset is selected to optimize sample quality (unary term) while maximizing group diversity (binary term). To substantially improve runtime efficiency, we progressively prune the candidate set using intermediate predictions, allowing our method to scale up to large candidate sets. Extensive experiments show that our method significantly improves group diversity and quality compared to independent sampling baselines and recent inference algorithms. Our framework generalizes across a wide range of tasks, including text-to-image, image-to-image, image prompting, and video generation, enabling generative models to treat multiple outputs as cohesive groups rather than independent samples.
Object-level Visual Prompts for Compositional Image Generation
Jan 02, 2025



We introduce a method for composing object-level visual prompts within a text-to-image diffusion model. Our approach addresses the task of generating semantically coherent compositions across diverse scenes and styles, similar to the versatility and expressiveness offered by text prompts. A key challenge in this task is to preserve the identity of the objects depicted in the input visual prompts, while also generating diverse compositions across different images. To address this challenge, we introduce a new KV-mixed cross-attention mechanism, in which keys and values are learned from distinct visual representations. The keys are derived from an encoder with a small bottleneck for layout control, whereas the values come from a larger bottleneck encoder that captures fine-grained appearance details. By mixing keys and values from these complementary sources, our model preserves the identity of the visual prompts while supporting flexible variations in object arrangement, pose, and composition. During inference, we further propose object-level compositional guidance to improve the method's identity preservation and layout correctness. Results show that our technique produces diverse scene compositions that preserve the unique characteristics of each visual prompt, expanding the creative potential of text-to-image generation.
On the Content Bias in Fréchet Video Distance
Apr 18, 2024



Fr\'echet Video Distance (FVD), a prominent metric for evaluating video generation models, is known to conflict with human perception occasionally. In this paper, we aim to explore the extent of FVD's bias toward per-frame quality over temporal realism and identify its sources. We first quantify the FVD's sensitivity to the temporal axis by decoupling the frame and motion quality and find that the FVD increases only slightly with large temporal corruption. We then analyze the generated videos and show that via careful sampling from a large set of generated videos that do not contain motions, one can drastically decrease FVD without improving the temporal quality. Both studies suggest FVD's bias towards the quality of individual frames. We further observe that the bias can be attributed to the features extracted from a supervised video classifier trained on the content-biased dataset. We show that FVD with features extracted from the recent large-scale self-supervised video models is less biased toward image quality. Finally, we revisit a few real-world examples to validate our hypothesis.
One-Step Image Translation with Text-to-Image Models
Mar 18, 2024



In this work, we address two limitations of existing conditional diffusion models: their slow inference speed due to the iterative denoising process and their reliance on paired data for model fine-tuning. To tackle these issues, we introduce a general method for adapting a single-step diffusion model to new tasks and domains through adversarial learning objectives. Specifically, we consolidate various modules of the vanilla latent diffusion model into a single end-to-end generator network with small trainable weights, enhancing its ability to preserve the input image structure while reducing overfitting. We demonstrate that, for unpaired settings, our model CycleGAN-Turbo outperforms existing GAN-based and diffusion-based methods for various scene translation tasks, such as day-to-night conversion and adding/removing weather effects like fog, snow, and rain. We extend our method to paired settings, where our model pix2pix-Turbo is on par with recent works like Control-Net for Sketch2Photo and Edge2Image, but with a single-step inference. This work suggests that single-step diffusion models can serve as strong backbones for a range of GAN learning objectives. Our code and models are available at https://github.com/GaParmar/img2img-turbo.
CoFRIDA: Self-Supervised Fine-Tuning for Human-Robot Co-Painting
Feb 21, 2024



Prior robot painting and drawing work, such as FRIDA, has focused on decreasing the sim-to-real gap and expanding input modalities for users, but the interaction with these systems generally exists only in the input stages. To support interactive, human-robot collaborative painting, we introduce the Collaborative FRIDA (CoFRIDA) robot painting framework, which can co-paint by modifying and engaging with content already painted by a human collaborator. To improve text-image alignment, FRIDA's major weakness, our system uses pre-trained text-to-image models; however, pre-trained models in the context of real-world co-painting do not perform well because they (1) do not understand the constraints and abilities of the robot and (2) cannot perform co-painting without making unrealistic edits to the canvas and overwriting content. We propose a self-supervised fine-tuning procedure that can tackle both issues, allowing the use of pre-trained state-of-the-art text-image alignment models with robots to enable co-painting in the physical world. Our open-source approach, CoFRIDA, creates paintings and drawings that match the input text prompt more clearly than FRIDA, both from a blank canvas and one with human created work. More generally, our fine-tuning procedure successfully encodes the robot's constraints and abilities into a foundation model, showcasing promising results as an effective method for reducing sim-to-real gaps.
Zero-shot Image-to-Image Translation
Feb 06, 2023



Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.
Spatially-Adaptive Multilayer Selection for GAN Inversion and Editing
Jun 16, 2022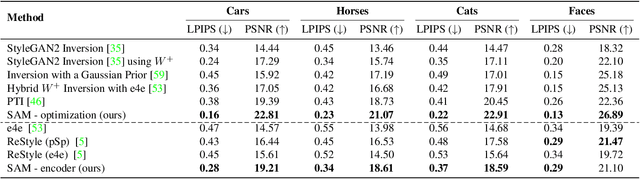
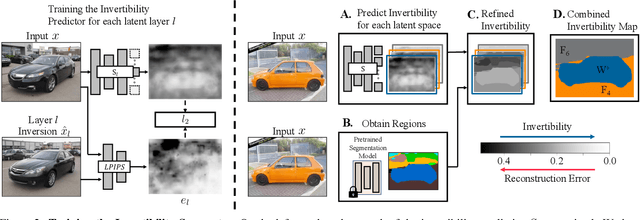
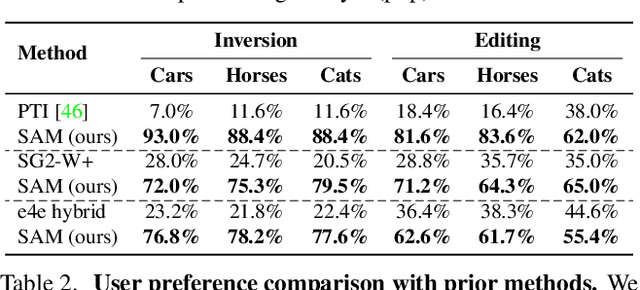

Existing GAN inversion and editing methods work well for aligned objects with a clean background, such as portraits and animal faces, but often struggle for more difficult categories with complex scene layouts and object occlusions, such as cars, animals, and outdoor images. We propose a new method to invert and edit such complex images in the latent space of GANs, such as StyleGAN2. Our key idea is to explore inversion with a collection of layers, spatially adapting the inversion process to the difficulty of the image. We learn to predict the "invertibility" of different image segments and project each segment into a latent layer. Easier regions can be inverted into an earlier layer in the generator's latent space, while more challenging regions can be inverted into a later feature space. Experiments show that our method obtains better inversion results compared to the recent approaches on complex categories, while maintaining downstream editability. Please refer to our project page at https://www.cs.cmu.edu/~SAMInversion.
On Buggy Resizing Libraries and Surprising Subtleties in FID Calculation
Apr 22, 2021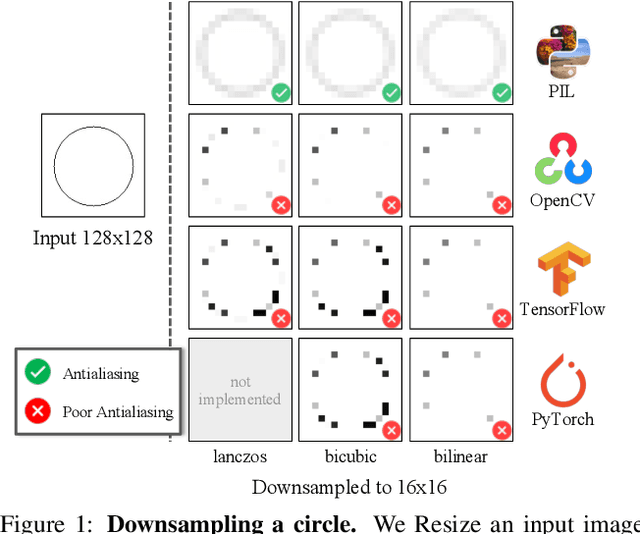
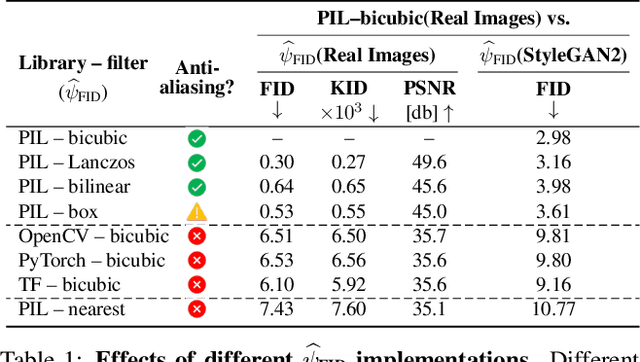
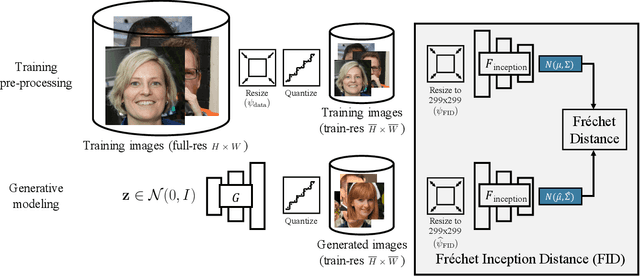
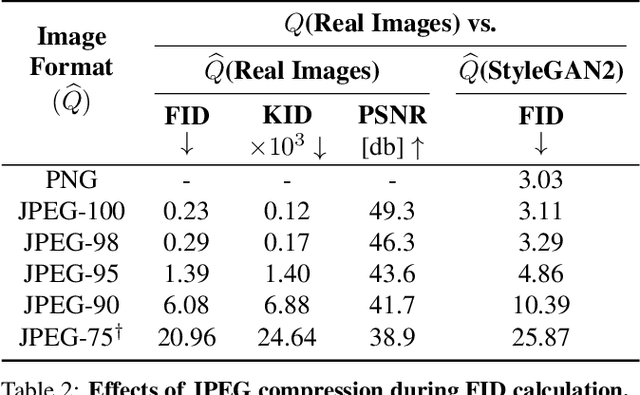
We investigate the sensitivity of the Fr\'echet Inception Distance (FID) score to inconsistent and often incorrect implementations across different image processing libraries. FID score is widely used to evaluate generative models, but each FID implementation uses a different low-level image processing process. Image resizing functions in commonly-used deep learning libraries often introduce aliasing artifacts. We observe that numerous subtle choices need to be made for FID calculation and a lack of consistencies in these choices can lead to vastly different FID scores. In particular, we show that the following choices are significant: (1) selecting what image resizing library to use, (2) choosing what interpolation kernel to use, (3) what encoding to use when representing images. We additionally outline numerous common pitfalls that should be avoided and provide recommendations for computing the FID score accurately. We provide an easy-to-use optimized implementation of our proposed recommendations in the accompanying code.
Dual Contradistinctive Generative Autoencoder
Nov 19, 2020
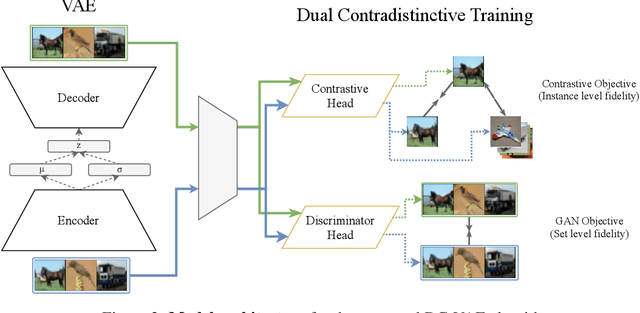
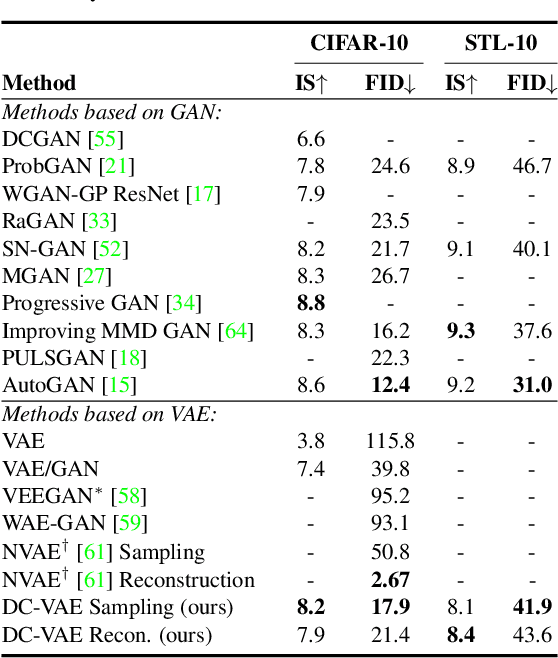

We present a new generative autoencoder model with dual contradistinctive losses to improve generative autoencoder that performs simultaneous inference (reconstruction) and synthesis (sampling). Our model, named dual contradistinctive generative autoencoder (DC-VAE), integrates an instance-level discriminative loss (maintaining the instance-level fidelity for the reconstruction/synthesis) with a set-level adversarial loss (encouraging the set-level fidelity for there construction/synthesis), both being contradistinctive. Extensive experimental results by DC-VAE across different resolutions including 32x32, 64x64, 128x128, and 512x512 are reported. The two contradistinctive losses in VAE work harmoniously in DC-VAE leading to a significant qualitative and quantitative performance enhancement over the baseline VAEs without architectural changes. State-of-the-art or competitive results among generative autoencoders for image reconstruction, image synthesis, image interpolation, and representation learning are observed. DC-VAE is a general-purpose VAE model, applicable to a wide variety of downstream tasks in computer vision and machine learning.
Guided Variational Autoencoder for Disentanglement Learning
Apr 02, 2020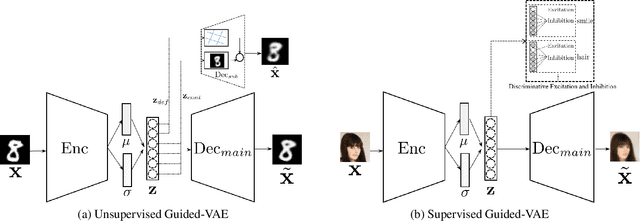
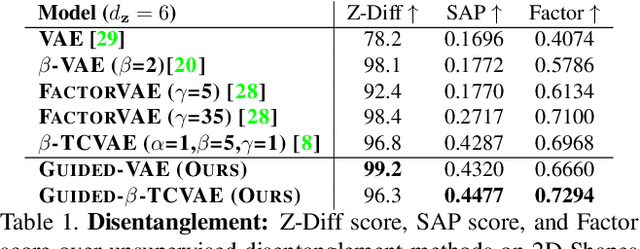

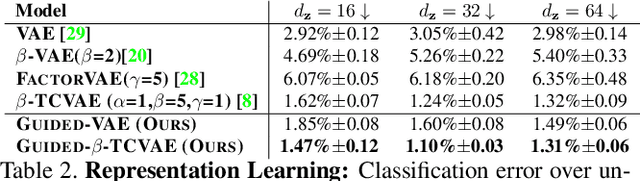
We propose an algorithm, guided variational autoencoder (Guided-VAE), that is able to learn a controllable generative model by performing latent representation disentanglement learning. The learning objective is achieved by providing signals to the latent encoding/embedding in VAE without changing its main backbone architecture, hence retaining the desirable properties of the VAE. We design an unsupervised strategy and a supervised strategy in Guided-VAE and observe enhanced modeling and controlling capability over the vanilla VAE. In the unsupervised strategy, we guide the VAE learning by introducing a lightweight decoder that learns latent geometric transformation and principal components; in the supervised strategy, we use an adversarial excitation and inhibition mechanism to encourage the disentanglement of the latent variables. Guided-VAE enjoys its transparency and simplicity for the general representation learning task, as well as disentanglement learning. On a number of experiments for representation learning, improved synthesis/sampling, better disentanglement for classification, and reduced classification errors in meta-learning have been observed.