 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVminerLLM2: Improving Structured Extraction of Patient Voice via Preference Optimization
Jun 15, 2026Motivation: Patient-generated text contains critical information on patients' lived experiences, social context, and care engagement, but remains largely unstructured, limiting its use in patient-centered outcomes research. Prior work introduced the PV-Miner benchmark and PVMinerLLM models for structured extraction. However, supervised fine-tuning (SFT) alone struggles with rare, fine-grained, and unevenly distributed errors, particularly in token-critical structured outputs. Results: We present PVminerLLM2, an improved set of LLMs for structured patient voice extraction that applies preference optimization to address token-critical errors beyond the reach of supervised fine-tuning. Our method introduces (i) a preference objective with token-level gated stabilization term that prevents degradation of absolute token likelihood under preference optimization, and (ii) confusion-aware preference pair construction to better capture low-separation distinctions. We further incorporate token-importance weighting and inverse-frequency reweighing to address token imbalance and class skew. Across multiple model sizes, PVMinerLLM2 consistently outperforms strong baselines, achieving gains of up to 4.43% (Code), 3.50% (Sub-code), and 1.55% (Span), and outperforms baseline LLM trained with existing preference optimization methods. Availability and Implementation: The supplementary material, code, evaluation scripts, and trained models for PVminerLLM2 are publicly available at: https://github.com/Data-Mining-Lab-Yale/PVminerLLM2
EPPC-OASIS: Ontology-Aware Adaptation and Structured Inference Refinement for Electronic Patient-Provider Communication Mining in Secure Messages
May 22, 2026Secure patient-provider messages contain clinically important communication behaviors that are difficult to characterize manually at scale. The Electronic Patient-Provider Communication (EPPC) framework provides an ontology for coding these behaviors, but automated extraction remains challenging because predictions must preserve fine-grained code/sub-code structure while grounding annotations in message text. We developed EPPC-OASIS, an ontology-aware adaptation approach for structured EPPC extraction, and combined it with deployable inference-refinement procedures designed to improve the coherence of final annotations. EPPC-OASIS augments supervised fine-tuning with a Wasserstein alignment objective that encourages alignment between model representation neighborhoods and EPPC ontology-derived neighborhoods, while inference refinement uses verification, self-consistency, hybrid correction, and selection or ensembling to address residual prediction errors. We evaluated the framework on a de-identified corpus of secure patient-provider messages against prompting, supervised fine-tuning, preference-based, and robustness-oriented baselines across multiple open-weight language models. Across model families, the best deployable pipeline achieved 77.13% Code+Sub-code F1 and 63.83% Triplet F1, corresponding to modest but consistent absolute gains of +1.39 and +2.12 F1 points over the strongest supervised fine-tuning baseline. These results suggest that ontology-aware adaptation with structured inference refinement can support scalable retrospective EPPC mining, although external validation is needed before operational use.
Herculean: An Agentic Benchmark for Financial Intelligence
May 14, 2026As AI agents improve, the central question is no longer whether they can solve isolated well-defined financial tasks, but whether they can reliably carry out financial professional work. Existing financial benchmarks offer only a partial view of this ability, as they primarily evaluate static competencies such as question answering, retrieval, summarization, and classification. We introduce Herculean, the first skilled benchmark for agentic financial intelligence spanning four representative workflows, including Trading, Hedging, Market Insights, and Auditing. Each workflow is instantiated as a standardized MCP-based skill environment with its own tools, interaction dynamics, constraints, and success criteria, enabling consistent end-to-end assessment of heterogeneous agent systems. Across frontier agents, we find agents perform relatively well on Trading and Market Insights, but struggle substantially on Hedging and Auditing, where long-horizon coordination, state consistency, and structured verification are critical. Overall, our results point to a key gap in current agents in turning financial reasoning into dependable workflow execution in high-stakes financial workflows.
STaR-DRO: Stateful Tsallis Reweighting for Group-Robust Structured Prediction
Apr 09, 2026Structured prediction requires models to generate ontology-constrained labels, grounded evidence, and valid structure under ambiguity, label skew, and heterogeneous group difficulty. We present a two-part framework for controllable inference and robust fine-tuning. First, we introduce a task-agnostic prompting strategy that combines XML-based instruction structure, disambiguation rules, verification-style reasoning, schema constraints, and self-validation to address format drift, label ambiguity, evidence hallucination, and metadata-conditioned confusion in in-context structured generation. Second, we introduce STaR-DRO, a stateful robust optimization method for group heterogeneity. It combines Tsallis mirror descent with momentum-smoothed, centered group-loss signals and bounded excess-only multipliers so that only persistently hard groups above a neutral baseline are upweighted, concentrating learning where it is most needed while avoiding volatile, dense exponentiated-gradient reweighting and unnecessary loss from downweighting easier groups. We evaluate the combined framework on EPPC Miner, a benchmark for extracting hierarchical labels and evidence spans from patient-provider secure messages. Prompt engineering improves zero-shot by +15.44 average F1 across Code, Sub-code, and Span over four Llama models. Building on supervised fine-tuning, STaR-DRO further improves the hardest semantic decisions: on Llama-3.3-70B-Instruct, Code F1 rises from 79.24 to 81.47 and Sub-code F1 from 67.78 to 69.30, while preserving Span performance and reducing group-wise validation cross-entropy by up to 29.6% on the most difficult clinical categories. Because these rare and difficult groups correspond to clinically consequential communication behaviors, these gains are not merely statistical improvements: they directly strengthen communication mining reliability for patient-centered care analysis.
PVminer: A Domain-Specific Tool to Detect the Patient Voice in Patient Generated Data
Feb 24, 2026Patient-generated text such as secure messages, surveys, and interviews contains rich expressions of the patient voice (PV), reflecting communicative behaviors and social determinants of health (SDoH). Traditional qualitative coding frameworks are labor intensive and do not scale to large volumes of patient-authored messages across health systems. Existing machine learning (ML) and natural language processing (NLP) approaches provide partial solutions but often treat patient-centered communication (PCC) and SDoH as separate tasks or rely on models not well suited to patient-facing language. We introduce PVminer, a domain-adapted NLP framework for structuring patient voice in secure patient-provider communication. PVminer formulates PV detection as a multi-label, multi-class prediction task integrating patient-specific BERT encoders (PV-BERT-base and PV-BERT-large), unsupervised topic modeling for thematic augmentation (PV-Topic-BERT), and fine-tuned classifiers for Code, Subcode, and Combo-level labels. Topic representations are incorporated during fine-tuning and inference to enrich semantic inputs. PVminer achieves strong performance across hierarchical tasks and outperforms biomedical and clinical pre-trained baselines, achieving F1 scores of 82.25% (Code), 80.14% (Subcode), and up to 77.87% (Combo). An ablation study further shows that author identity and topic-based augmentation each contribute meaningful gains. Pre-trained models, source code, and documentation will be publicly released, with annotated datasets available upon request for research use.
Fast-DDPM: Fast Denoising Diffusion Probabilistic Models for Medical Image-to-Image Generation
May 24, 2024



Denoising diffusion probabilistic models (DDPMs) have achieved unprecedented success in computer vision. However, they remain underutilized in medical imaging, a field crucial for disease diagnosis and treatment planning. This is primarily due to the high computational cost associated with (1) the use of large number of time steps (e.g., 1,000) in diffusion processes and (2) the increased dimensionality of medical images, which are often 3D or 4D. Training a diffusion model on medical images typically takes days to weeks, while sampling each image volume takes minutes to hours. To address this challenge, we introduce Fast-DDPM, a simple yet effective approach capable of improving training speed, sampling speed, and generation quality simultaneously. Unlike DDPM, which trains the image denoiser across 1,000 time steps, Fast-DDPM trains and samples using only 10 time steps. The key to our method lies in aligning the training and sampling procedures to optimize time-step utilization. Specifically, we introduced two efficient noise schedulers with 10 time steps: one with uniform time step sampling and another with non-uniform sampling. We evaluated Fast-DDPM across three medical image-to-image generation tasks: multi-image super-resolution, image denoising, and image-to-image translation. Fast-DDPM outperformed DDPM and current state-of-the-art methods based on convolutional networks and generative adversarial networks in all tasks. Additionally, Fast-DDPM reduced the training time to 0.2x and the sampling time to 0.01x compared to DDPM. Our code is publicly available at: https://github.com/mirthAI/Fast-DDPM.
Fast Denoising Diffusion Probabilistic Models for Medical Image-to-Image Generation
May 23, 2024Denoising diffusion probabilistic models (DDPMs) have achieved unprecedented success in computer vision. However, they remain underutilized in medical imaging, a field crucial for disease diagnosis and treatment planning. This is primarily due to the high computational cost associated with (1) the use of large number of time steps (e.g., 1,000) in diffusion processes and (2) the increased dimensionality of medical images, which are often 3D or 4D. Training a diffusion model on medical images typically takes days to weeks, while sampling each image volume takes minutes to hours. To address this challenge, we introduce Fast-DDPM, a simple yet effective approach capable of improving training speed, sampling speed, and generation quality simultaneously. Unlike DDPM, which trains the image denoiser across 1,000 time steps, Fast-DDPM trains and samples using only 10 time steps. The key to our method lies in aligning the training and sampling procedures. We introduced two efficient noise schedulers with 10 time steps: one with uniform time step sampling and another with non-uniform sampling. We evaluated Fast-DDPM across three medical image-to-image generation tasks: multi-image super-resolution, image denoising, and image-to-image translation. Fast-DDPM outperformed DDPM and current state-of-the-art methods based on convolutional networks and generative adversarial networks in all tasks. Additionally, Fast-DDPM reduced training time by a factor of 5 and sampling time by a factor of 100 compared to DDPM. Our code is publicly available at: https://github.com/mirthAI/Fast-DDPM.
Attention-based Shape-Deformation Networks for Artifact-Free Geometry Reconstruction of Lumbar Spine from MR Images
Mar 30, 2024



Lumbar disc degeneration, a progressive structural wear and tear of lumbar intervertebral disc, is regarded as an essential role on low back pain, a significant global health concern. Automated lumbar spine geometry reconstruction from MR images will enable fast measurement of medical parameters to evaluate the lumbar status, in order to determine a suitable treatment. Existing image segmentation-based techniques often generate erroneous segments or unstructured point clouds, unsuitable for medical parameter measurement. In this work, we present TransDeformer: a novel attention-based deep learning approach that reconstructs the contours of the lumbar spine with high spatial accuracy and mesh correspondence across patients, and we also present a variant of TransDeformer for error estimation. Specially, we devise new attention modules with a new attention formula, which integrates image features and tokenized contour features to predict the displacements of the points on a shape template without the need for image segmentation. The deformed template reveals the lumbar spine geometry in the input image. We develop a multi-stage training strategy to enhance model robustness with respect to template initialization. Experiment results show that our TransDeformer generates artifact-free geometry outputs, and its variant predicts the error of a reconstructed geometry. Our code is available at https://github.com/linchenq/TransDeformer-Mesh.
SymTC: A Symbiotic Transformer-CNN Net for Instance Segmentation of Lumbar Spine MRI
Jan 25, 2024



Intervertebral disc disease, a prevalent ailment, frequently leads to intermittent or persistent low back pain, and diagnosing and assessing of this disease rely on accurate measurement of vertebral bone and intervertebral disc geometries from lumbar MR images. Deep neural network (DNN) models may assist clinicians with more efficient image segmentation of individual instances (disks and vertebrae) of the lumbar spine in an automated way, which is termed as instance image segmentation. In this work, we proposed SymTC, an innovative lumbar spine MR image segmentation model that combines the strengths of Transformer and Convolutional Neural Network (CNN). Specifically, we designed a parallel dual-path architecture to merge CNN layers and Transformer layers, and we integrated a novel position embedding into the self-attention module of Transformer, enhancing the utilization of positional information for more accurate segmentation. To further improves model performance, we introduced a new data augmentation technique to create synthetic yet realistic MR image dataset, named SSMSpine, which is made publicly available. We evaluated our SymTC and the other 15 existing image segmentation models on our private in-house dataset and the public SSMSpine dataset, using two metrics, Dice Similarity Coefficient and 95% Hausdorff Distance. The results show that our SymTC has the best performance for segmenting vertebral bones and intervertebral discs in lumbar spine MR images. The SymTC code and SSMSpine dataset are available at https://github.com/jiasongchen/SymTC.
Adaptive Adversarial Training to Improve Adversarial Robustness of DNNs for Medical Image Segmentation and Detection
Jun 02, 2022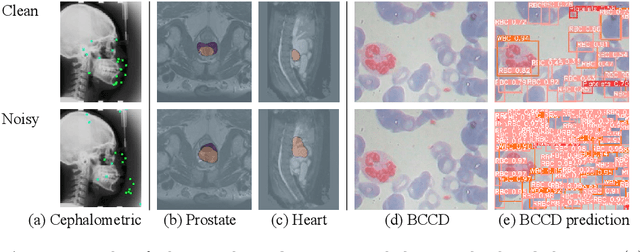
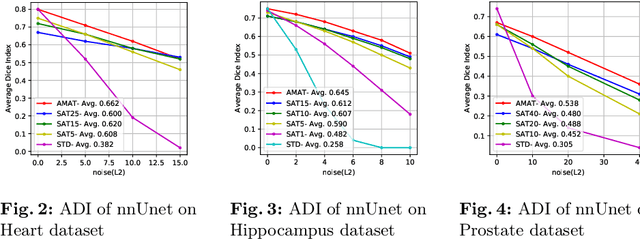
Recent methods based on Deep Neural Networks (DNNs) have reached high accuracy for medical image analysis, including the three basic tasks: segmentation, landmark detection, and object detection. It is known that DNNs are vulnerable to adversarial attacks, and the adversarial robustness of DNNs could be improved by adding adversarial noises to training data (i.e., adversarial training). In this study, we show that the standard adversarial training (SAT) method has a severe issue that limits its practical use: it generates a fixed level of noise for DNN training, and it is difficult for the user to choose an appropriate noise level, because a high noise level may lead to a large reduction in model performance, and a low noise level may have little effect. To resolve this issue, we have designed a novel adaptive-margin adversarial training (AMAT) method that generates adaptive adversarial noises for DNN training, which are dynamically tailored for each individual training sample. We have applied our AMAT method to state-of-the-art DNNs for the three basic tasks, using five publicly available datasets. The experimental results demonstrate that our AMAT method outperforms the SAT method in adversarial robustness on noisy data and prediction accuracy on clean data. Please contact the author for the source code.