 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HoloPOCUS: Portable Mixed-Reality 3D Ultrasound Tracking, Reconstruction and Overlay
Aug 26, 2023
Ultrasound (US) imaging provides a safe and accessible solution to procedural guidance and diagnostic imaging. The effective usage of conventional 2D US for interventional guidance requires extensive experience to project the image plane onto the patient, and the interpretation of images in diagnostics suffers from high intra- and inter-user variability. 3D US reconstruction allows for more consistent diagnosis and interpretation, but existing solutions are limited in terms of equipment and applicability in real-time navigation. To address these issues, we propose HoloPOCUS - a mixed reality US system (MR-US) that overlays rich US information onto the user's vision in a point-of-care setting. HoloPOCUS extends existing MR-US methods beyond placing a US plane in the user's vision to include a 3D reconstruction and projection that can aid in procedural guidance using conventional probes. We validated a tracking pipeline that demonstrates higher accuracy compared to existing MR-US works. Furthermore, user studies conducted via a phantom task showed significant improvements in navigation duration when using our proposed methods.
Devignet: High-Resolution Vignetting Removal via a Dual Aggregated Fusion Transformer With Adaptive Channel Expansion
Aug 26, 2023
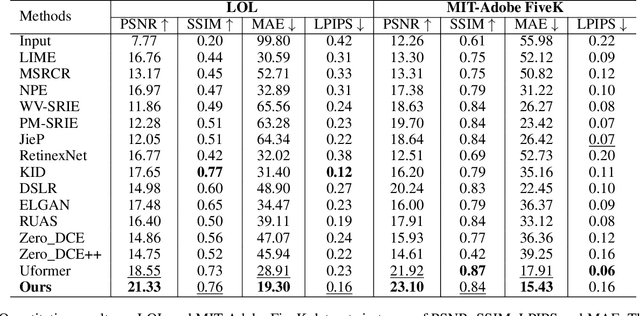

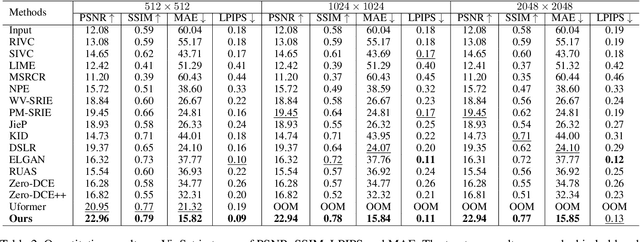
Vignetting commonly occurs as a degradation in images resulting from factors such as lens design, improper lens hood usage, and limitations in camera sensors. This degradation affects image details, color accuracy, and presents challenges in computational photography. Existing vignetting removal algorithms predominantly rely on ideal physics assumptions and hand-crafted parameters, resulting in ineffective removal of irregular vignetting and suboptimal results. Moreover, the substantial lack of real-world vignetting datasets hinders the objective and comprehensive evaluation of vignetting removal. To address these challenges, we present Vigset, a pioneering dataset for vignette removal. Vigset includes 983 pairs of both vignetting and vignetting-free high-resolution ($5340\times3697$) real-world images under various conditions. In addition, We introduce DeVigNet, a novel frequency-aware Transformer architecture designed for vignetting removal. Through the Laplacian Pyramid decomposition, we propose the Dual Aggregated Fusion Transformer to handle global features and remove vignetting in the low-frequency domain. Additionally, we introduce the Adaptive Channel Expansion Module to enhance details in the high-frequency domain. The experiments demonstrate that the proposed model outperforms existing state-of-the-art methods.
Semi-Supervised Learning in the Few-Shot Zero-Shot Scenario
Aug 27, 2023Semi-Supervised Learning (SSL) leverages both labeled and unlabeled data to improve model performance. Traditional SSL methods assume that labeled and unlabeled data share the same label space. However, in real-world applications, especially when the labeled training set is small, there may be classes that are missing from the labeled set. Existing frameworks aim to either reject all unseen classes (open-set SSL) or to discover unseen classes by partitioning an unlabeled set during training (open-world SSL). In our work, we construct a classifier for points from both seen and unseen classes. Our approach is based on extending an existing SSL method, such as FlexMatch, by incorporating an additional entropy loss. This enhancement allows our method to improve the performance of any existing SSL method in the classification of both seen and unseen classes. We demonstrate large improvement gains over state-of-the-art SSL, open-set SSL, and open-world SSL methods, on two benchmark image classification data sets, CIFAR-100 and STL-10. The gains are most pronounced when the labeled data is severely limited (1-25 labeled examples per class).
Label Denoising through Cross-Model Agreement
Aug 27, 2023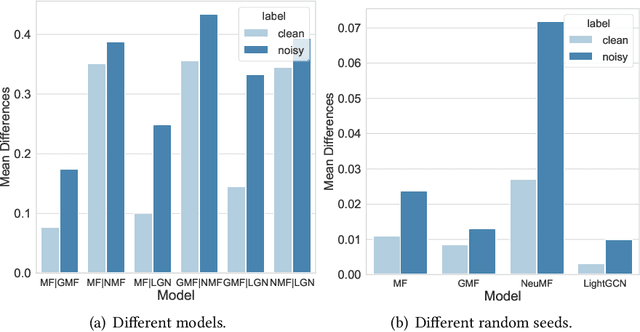
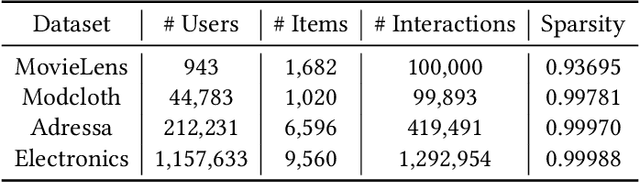
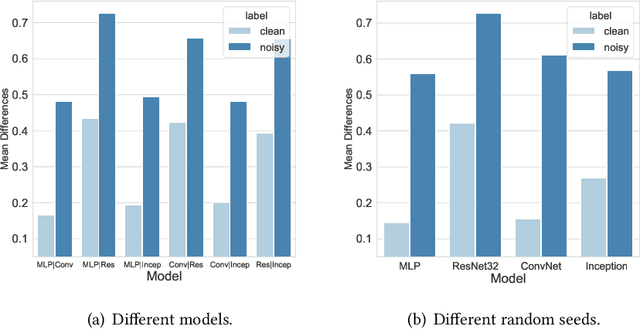
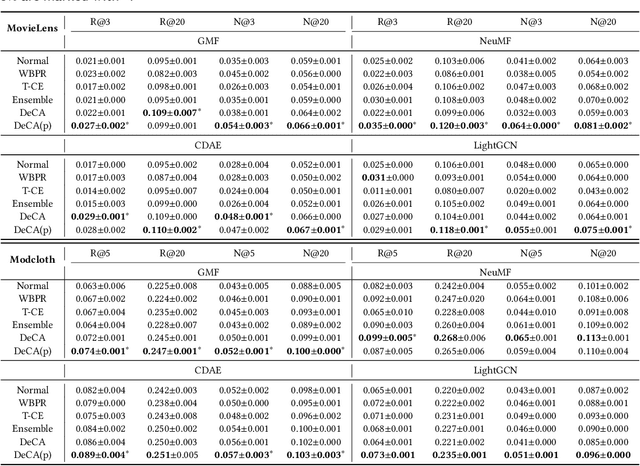
Learning from corrupted labels is very common in real-world machine-learning applications. Memorizing such noisy labels could affect the learning of the model, leading to sub-optimal performances. In this work, we propose a novel framework to learn robust machine-learning models from noisy labels. Through an empirical study, we find that different models make relatively similar predictions on clean examples, while the predictions on noisy examples vary much more across different models. Motivated by this observation, we propose \em denoising with cross-model agreement \em (DeCA) which aims to minimize the KL-divergence between the true label distributions parameterized by two machine learning models while maximizing the likelihood of data observation. We employ the proposed DeCA on both the binary label scenario and the multiple label scenario. For the binary label scenario, we select implicit feedback recommendation as the downstream task and conduct experiments with four state-of-the-art recommendation models on four datasets. For the multiple-label scenario, the downstream application is image classification on two benchmark datasets. Experimental results demonstrate that the proposed methods significantly improve the model performance compared with normal training and other denoising methods on both binary and multiple-label scenarios.
DISBELIEVE: Distance Between Client Models is Very Essential for Effective Local Model Poisoning Attacks
Aug 14, 2023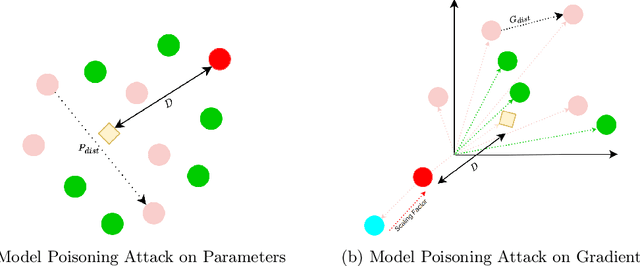
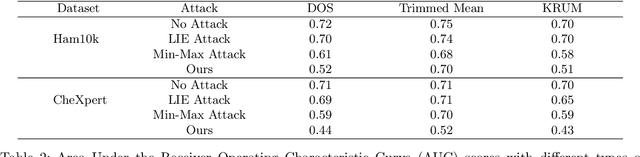
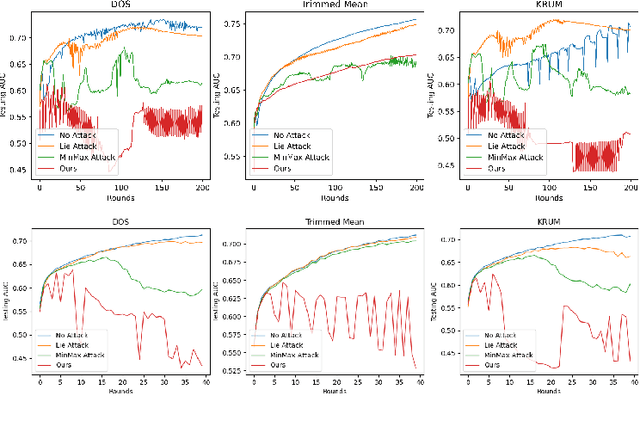
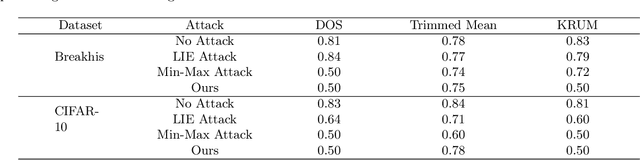
Federated learning is a promising direction to tackle the privacy issues related to sharing patients' sensitive data. Often, federated systems in the medical image analysis domain assume that the participating local clients are \textit{honest}. Several studies report mechanisms through which a set of malicious clients can be introduced that can poison the federated setup, hampering the performance of the global model. To overcome this, robust aggregation methods have been proposed that defend against those attacks. We observe that most of the state-of-the-art robust aggregation methods are heavily dependent on the distance between the parameters or gradients of malicious clients and benign clients, which makes them prone to local model poisoning attacks when the parameters or gradients of malicious and benign clients are close. Leveraging this, we introduce DISBELIEVE, a local model poisoning attack that creates malicious parameters or gradients such that their distance to benign clients' parameters or gradients is low respectively but at the same time their adverse effect on the global model's performance is high. Experiments on three publicly available medical image datasets demonstrate the efficacy of the proposed DISBELIEVE attack as it significantly lowers the performance of the state-of-the-art \textit{robust aggregation} methods for medical image analysis. Furthermore, compared to state-of-the-art local model poisoning attacks, DISBELIEVE attack is also effective on natural images where we observe a severe drop in classification performance of the global model for multi-class classification on benchmark dataset CIFAR-10.
1M parameters are enough? A lightweight CNN-based model for medical image segmentation
Jul 03, 2023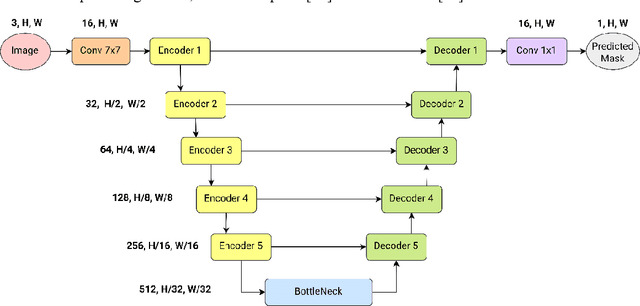
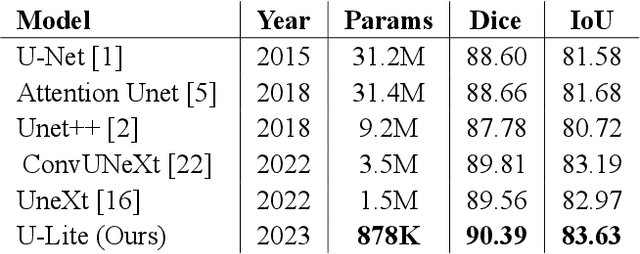
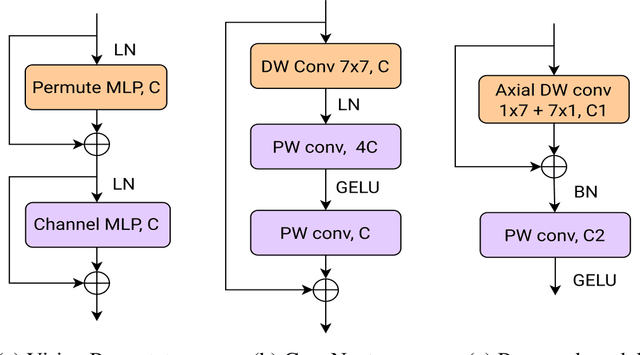
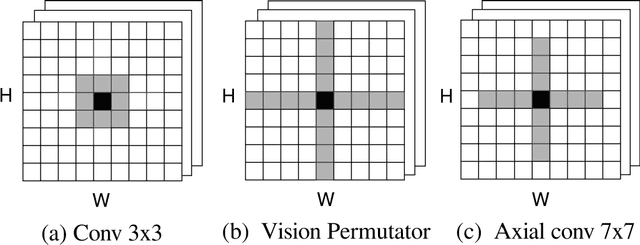
Convolutional neural networks (CNNs) and Transformer-based models are being widely applied in medical image segmentation thanks to their ability to extract high-level features and capture important aspects of the image. However, there is often a trade-off between the need for high accuracy and the desire for low computational cost. A model with higher parameters can theoretically achieve better performance but also result in more computational complexity and higher memory usage, and thus is not practical to implement. In this paper, we look for a lightweight U-Net-based model which can remain the same or even achieve better performance, namely U-Lite. We design U-Lite based on the principle of Depthwise Separable Convolution so that the model can both leverage the strength of CNNs and reduce a remarkable number of computing parameters. Specifically, we propose Axial Depthwise Convolutions with kernels 7x7 in both the encoder and decoder to enlarge the model receptive field. To further improve the performance, we use several Axial Dilated Depthwise Convolutions with filters 3x3 for the bottleneck as one of our branches. Overall, U-Lite contains only 878K parameters, 35 times less than the traditional U-Net, and much more times less than other modern Transformer-based models. The proposed model cuts down a large amount of computational complexity while attaining an impressive performance on medical segmentation tasks compared to other state-of-the-art architectures. The code will be available at: https://github.com/duong-db/U-Lite.
SAR Ship Target Recognition via Selective Feature Discrimination and Multifeature Center Classifier
Aug 20, 2023
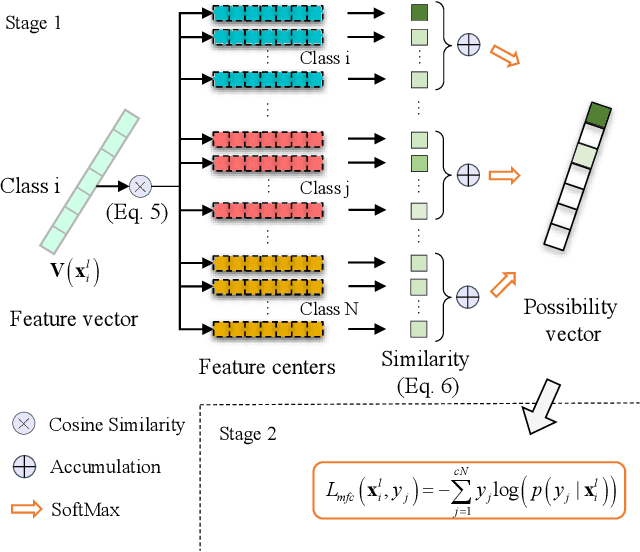
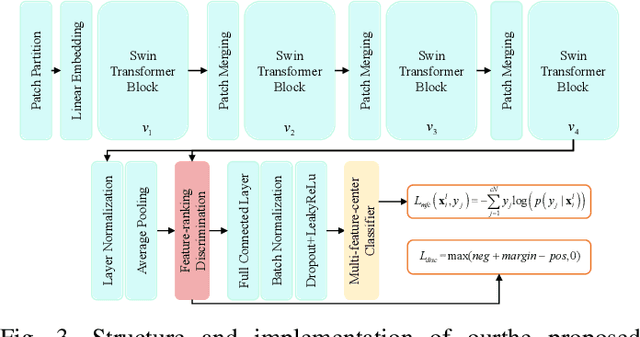

Maritime surveillance is not only necessary for every country, such as in maritime safeguarding and fishing controls, but also plays an essential role in international fields, such as in rescue support and illegal immigration control. Most of the existing automatic target recognition (ATR) methods directly send the extracted whole features of SAR ships into one classifier. The classifiers of most methods only assign one feature center to each class. However, the characteristics of SAR ship images, large inner-class variance, and small interclass difference lead to the whole features containing useless partial features and a single feature center for each class in the classifier failing with large inner-class variance. We proposes a SAR ship target recognition method via selective feature discrimination and multifeature center classifier. The selective feature discrimination automatically finds the similar partial features from the most similar interclass image pairs and the dissimilar partial features from the most dissimilar inner-class image pairs. It then provides a loss to enhance these partial features with more interclass separability. Motivated by divide and conquer, the multifeature center classifier assigns multiple learnable feature centers for each ship class. In this way, the multifeature centers divide the large inner-class variance into several smaller variances and conquered by combining all feature centers of one ship class. Finally, the probability distribution over all feature centers is considered comprehensively to achieve an accurate recognition of SAR ship images. The ablation experiments and experimental results on OpenSARShip and FUSAR-Ship datasets show that our method has achieved superior recognition performance under decreasing training SAR ship samples.
Large Transformers are Better EEG Learners
Aug 20, 2023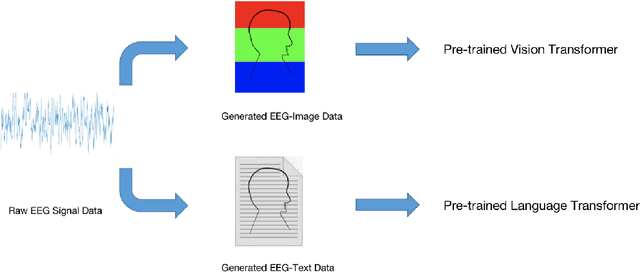
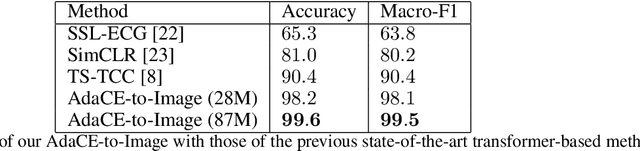
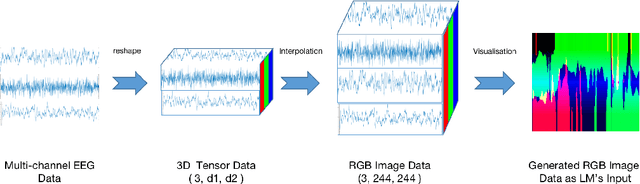
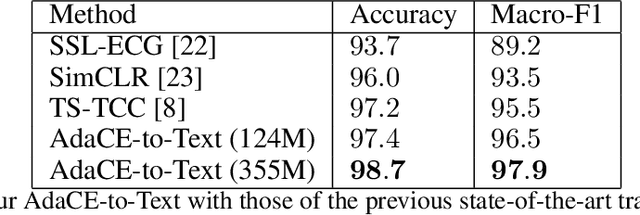
Pre-trained large transformer models have achieved remarkable performance in the fields of natural language processing and computer vision. Since the magnitude of available labeled electroencephalogram (EEG) data is much lower than that of text and image data, it is difficult for transformer models pre-trained from EEG to be developed as large as GPT-4 100T to fully unleash the potential of this architecture. In this paper, we show that transformers pre-trained from images as well as text can be directly fine-tuned for EEG-based prediction tasks. We design AdaCE, plug-and-play Adapters for Converting EEG data into image as well as text forms, to fine-tune pre-trained vision and language transformers. The proposed AdaCE module is highly effective for fine-tuning pre-trained transformers while achieving state-of-the-art performance on diverse EEG-based prediction tasks. For example, AdaCE on the pre-trained Swin-Transformer achieves 99.6%, an absolute improvement of 9.2%, on the EEG-decoding task of human activity recognition (UCI HAR). Furthermore, we empirically show that applying the proposed AdaCE to fine-tune larger pre-trained models can achieve better performance on EEG-based predicting tasks, indicating the potential of our adapters for even larger transformers. The plug-and-play AdaCE module can be applied to fine-tuning most of the popular pre-trained transformers on many other time-series data with multiple channels, not limited to EEG data and the models we use. Our code will be available at https://github.com/wangbxj1234/AdaCE.
Unsupervised Low Light Image Enhancement Using SNR-Aware Swin Transformer
Jun 03, 2023
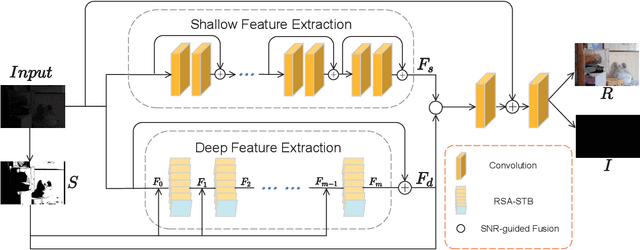
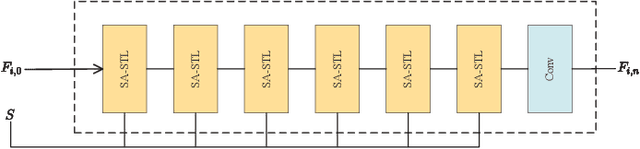
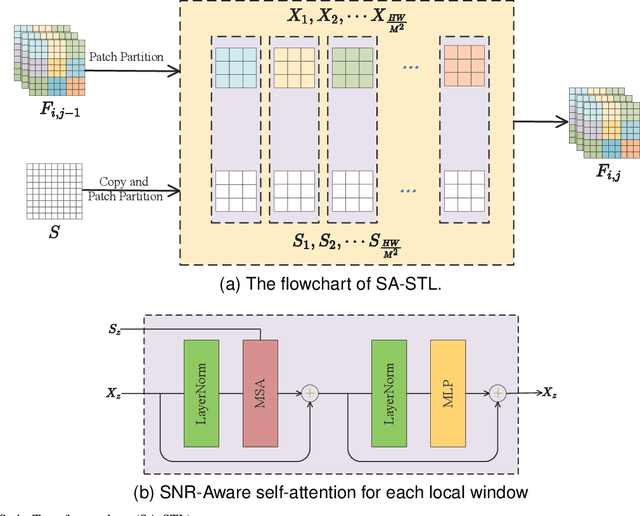
Image captured under low-light conditions presents unpleasing artifacts, which debilitate the performance of feature extraction for many upstream visual tasks. Low-light image enhancement aims at improving brightness and contrast, and further reducing noise that corrupts the visual quality. Recently, many image restoration methods based on Swin Transformer have been proposed and achieve impressive performance. However, On one hand, trivially employing Swin Transformer for low-light image enhancement would expose some artifacts, including over-exposure, brightness imbalance and noise corruption, etc. On the other hand, it is impractical to capture image pairs of low-light images and corresponding ground-truth, i.e. well-exposed image in same visual scene. In this paper, we propose a dual-branch network based on Swin Transformer, guided by a signal-to-noise ratio prior map which provides the spatial-varying information for low-light image enhancement. Moreover, we leverage unsupervised learning to construct the optimization objective based on Retinex model, to guide the training of proposed network. Experimental results demonstrate that the proposed model is competitive with the baseline models.
ModelScope Text-to-Video Technical Report
Aug 12, 2023

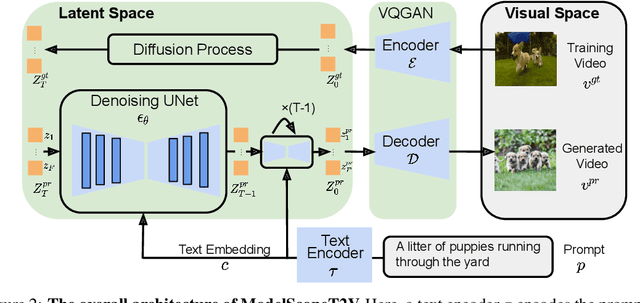
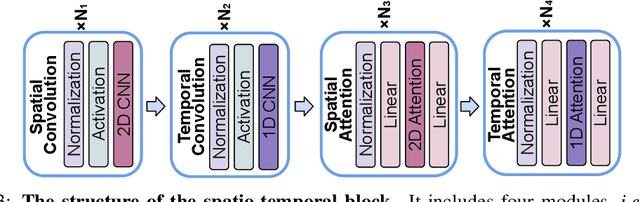
This paper introduces ModelScopeT2V, a text-to-video synthesis model that evolves from a text-to-image synthesis model (i.e., Stable Diffusion). ModelScopeT2V incorporates spatio-temporal blocks to ensure consistent frame generation and smooth movement transitions. The model could adapt to varying frame numbers during training and inference, rendering it suitable for both image-text and video-text datasets. ModelScopeT2V brings together three components (i.e., VQGAN, a text encoder, and a denoising UNet), totally comprising 1.7 billion parameters, in which 0.5 billion parameters are dedicated to temporal capabilities. The model demonstrates superior performance over state-of-the-art methods across three evaluation metrics. The code and an online demo are available at \url{https://modelscope.cn/models/damo/text-to-video-synthesis/summary}.