 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Pic Swift: Enhancing Long-Text to Image Retrieval for Large-Scale Libraries
Feb 28, 2024



Text-to-image retrieval plays a crucial role across various applications, including digital libraries, e-commerce platforms, and multimedia databases, by enabling the search for images using text queries. Despite the advancements in Multimodal Large Language Models (MLLMs), which offer leading-edge performance, their applicability in large-scale, varied, and ambiguous retrieval scenarios is constrained by significant computational demands and the generation of injective embeddings. This paper introduces the Text2Pic Swift framework, tailored for efficient and robust retrieval of images corresponding to extensive textual descriptions in sizable datasets. The framework employs a two-tier approach: the initial Entity-based Ranking (ER) stage addresses the ambiguity inherent in lengthy text queries through a multiple-queries-to-multiple-targets strategy, effectively narrowing down potential candidates for subsequent analysis. Following this, the Summary-based Re-ranking (SR) stage further refines these selections based on concise query summaries. Additionally, we present a novel Decoupling-BEiT-3 encoder, specifically designed to tackle the challenges of ambiguous queries and to facilitate both stages of the retrieval process, thereby significantly improving computational efficiency via vector-based similarity assessments. Our evaluation, conducted on the AToMiC dataset, demonstrates that Text2Pic Swift outperforms current MLLMs by achieving up to an 11.06% increase in Recall@1000, alongside reductions in training and retrieval durations by 68.75% and 99.79%, respectively.
Label Denoising through Cross-Model Agreement
Sep 01, 2023



Learning from corrupted labels is very common in real-world machine-learning applications. Memorizing such noisy labels could affect the learning of the model, leading to sub-optimal performances. In this work, we propose a novel framework to learn robust machine-learning models from noisy labels. Through an empirical study, we find that different models make relatively similar predictions on clean examples, while the predictions on noisy examples vary much more across different models. Motivated by this observation, we propose \em denoising with cross-model agreement \em (DeCA) which aims to minimize the KL-divergence between the true label distributions parameterized by two machine learning models while maximizing the likelihood of data observation. We employ the proposed DeCA on both the binary label scenario and the multiple label scenario. For the binary label scenario, we select implicit feedback recommendation as the downstream task and conduct experiments with four state-of-the-art recommendation models on four datasets. For the multiple-label scenario, the downstream application is image classification on two benchmark datasets. Experimental results demonstrate that the proposed methods significantly improve the model performance compared with normal training and other denoising methods on both binary and multiple-label scenarios.
Improving Implicit Feedback-Based Recommendation through Multi-Behavior Alignment
May 09, 2023



Recommender systems that learn from implicit feedback often use large volumes of a single type of implicit user feedback, such as clicks, to enhance the prediction of sparse target behavior such as purchases. Using multiple types of implicit user feedback for such target behavior prediction purposes is still an open question. Existing studies that attempted to learn from multiple types of user behavior often fail to: (i) learn universal and accurate user preferences from different behavioral data distributions, and (ii) overcome the noise and bias in observed implicit user feedback. To address the above problems, we propose multi-behavior alignment (MBA), a novel recommendation framework that learns from implicit feedback by using multiple types of behavioral data. We conjecture that multiple types of behavior from the same user (e.g., clicks and purchases) should reflect similar preferences of that user. To this end, we regard the underlying universal user preferences as a latent variable. The variable is inferred by maximizing the likelihood of multiple observed behavioral data distributions and, at the same time, minimizing the Kullback-Leibler divergence (KL-divergence) between user models learned from auxiliary behavior (such as clicks or views) and the target behavior separately. MBA infers universal user preferences from multi-behavior data and performs data denoising to enable effective knowledge transfer. We conduct experiments on three datasets, including a dataset collected from an operational e-commerce platform. Empirical results demonstrate the effectiveness of our proposed method in utilizing multiple types of behavioral data to enhance the prediction of the target behavior.
Probabilistic and Variational Recommendation Denoising
May 20, 2021
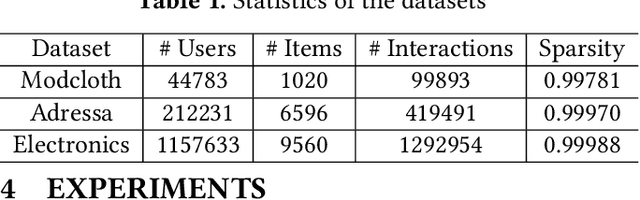
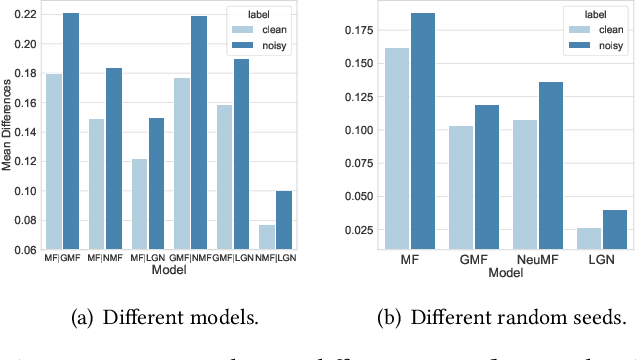
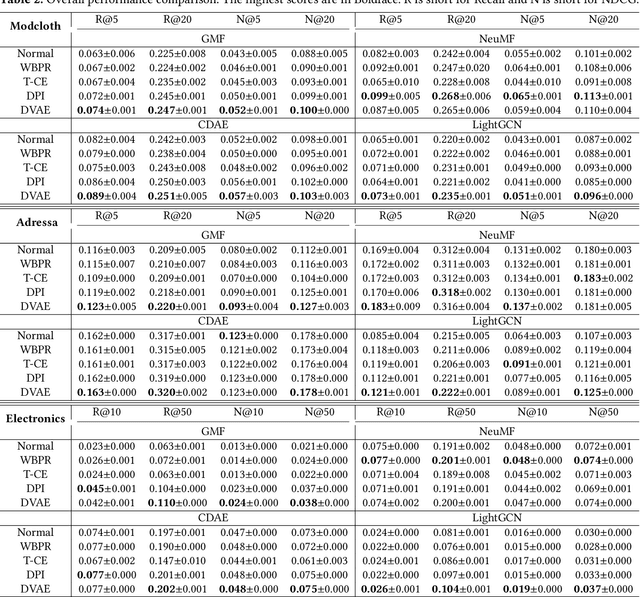
Learning from implicit feedback is one of the most common cases in the application of recommender systems. Generally speaking, interacted examples are considered as positive while negative examples are sampled from uninteracted ones. However, noisy examples are prevalent in real-world implicit feedback. A noisy positive example could be interacted but it actually leads to negative user preference. A noisy negative example which is uninteracted because of unawareness of the user could also denote potential positive user preference. Conventional training methods overlook these noisy examples, leading to sub-optimal recommendation. In this work, we propose probabilistic and variational recommendation denoising for implicit feedback. Through an empirical study, we find that different models make relatively similar predictions on clean examples which denote the real user preference, while the predictions on noisy examples vary much more across different models. Motivated by this observation, we propose denoising with probabilistic inference (DPI) which aims to minimize the KL-divergence between the real user preference distributions parameterized by two recommendation models while maximize the likelihood of data observation. We then show that DPI recovers the evidence lower bound of an variational auto-encoder when the real user preference is considered as the latent variables. This leads to our second learning framework denoising with variational autoencoder (DVAE). We employ the proposed DPI and DVAE on four state-of-the-art recommendation models and conduct experiments on three datasets. Experimental results demonstrate that DPI and DVAE significantly improve recommendation performance compared with normal training and other denoising methods. Codes will be open-sourced.
Relational Collaborative Filtering:Modeling Multiple Item Relations for Recommendation
May 11, 2019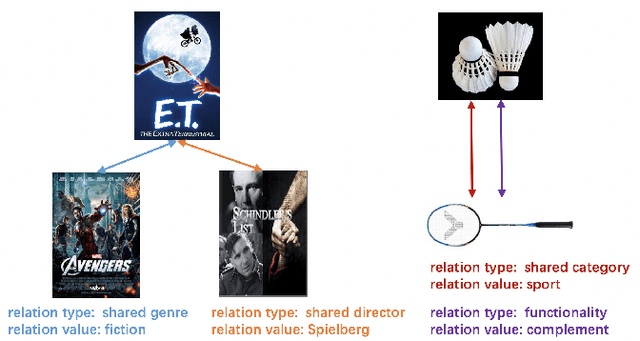

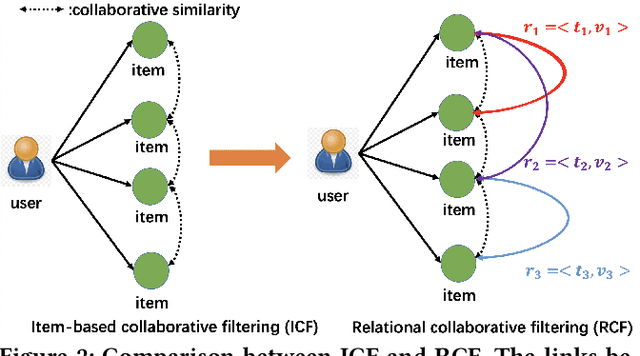
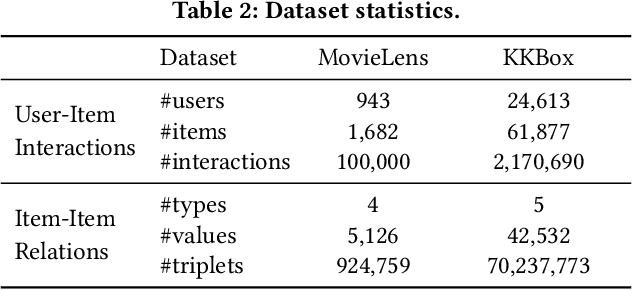
Existing item-based collaborative filtering (ICF) methods leverage only the relation of collaborative similarity. Nevertheless, there exist multiple relations between items in real-world scenarios. Distinct from the collaborative similarity that implies co-interact patterns from the user perspective, these relations reveal fine-grained knowledge on items from different perspectives of meta-data, functionality, etc. However, how to incorporate multiple item relations is less explored in recommendation research. In this work, we propose Relational Collaborative Filtering (RCF), a general framework to exploit multiple relations between items in recommender system. We find that both the relation type and the relation value are crucial in inferring user preference. To this end, we develop a two-level hierarchical attention mechanism to model user preference. The first-level attention discriminates which types of relations are more important, and the second-level attention considers the specific relation values to estimate the contribution of a historical item in recommending the target item. To make the item embeddings be reflective of the relational structure between items, we further formulate a task to preserve the item relations, and jointly train it with the recommendation task of preference modeling. Empirical results on two real datasets demonstrate the strong performance of RCF. Furthermore, we also conduct qualitative analyses to show the benefits of explanations brought by the modeling of multiple item relations.