 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Tensor-to-Image: Image-to-Image Translation with Vision Transformers
Oct 06, 2021
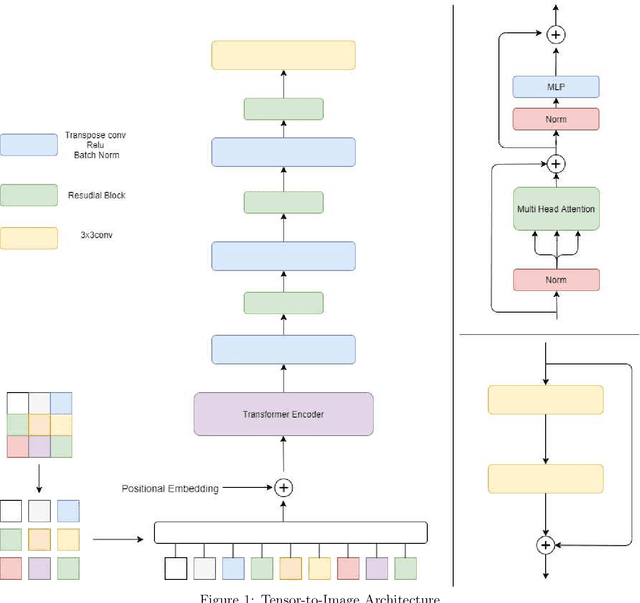


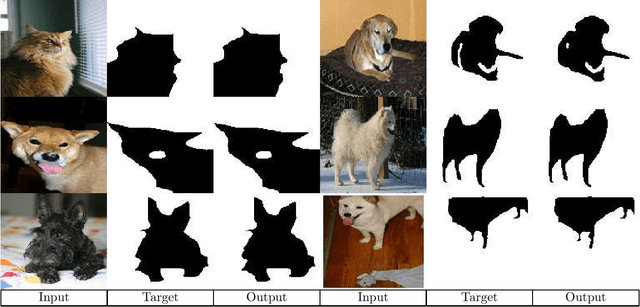
Transformers gain huge attention since they are first introduced and have a wide range of applications. Transformers start to take over all areas of deep learning and the Vision transformers paper also proved that they can be used for computer vision tasks. In this paper, we utilized a vision transformer-based custom-designed model, tensor-to-image, for the image to image translation. With the help of self-attention, our model was able to generalize and apply to different problems without a single modification.
Few-shot Image Generation via Style Adaptation and Content Preservation
Nov 30, 2023Training a generative model with limited data (e.g., 10) is a very challenging task. Many works propose to fine-tune a pre-trained GAN model. However, this can easily result in overfitting. In other words, they manage to adapt the style but fail to preserve the content, where \textit{style} denotes the specific properties that defines a domain while \textit{content} denotes the domain-irrelevant information that represents diversity. Recent works try to maintain a pre-defined correspondence to preserve the content, however, the diversity is still not enough and it may affect style adaptation. In this work, we propose a paired image reconstruction approach for content preservation. We propose to introduce an image translation module to GAN transferring, where the module teaches the generator to separate style and content, and the generator provides training data to the translation module in return. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
Unsupervised Image-to-Image Translation with Generative Prior
Apr 07, 2022

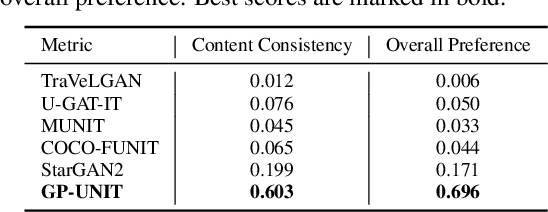

Unsupervised image-to-image translation aims to learn the translation between two visual domains without paired data. Despite the recent progress in image translation models, it remains challenging to build mappings between complex domains with drastic visual discrepancies. In this work, we present a novel framework, Generative Prior-guided UNsupervised Image-to-image Translation (GP-UNIT), to improve the overall quality and applicability of the translation algorithm. Our key insight is to leverage the generative prior from pre-trained class-conditional GANs (e.g., BigGAN) to learn rich content correspondences across various domains. We propose a novel coarse-to-fine scheme: we first distill the generative prior to capture a robust coarse-level content representation that can link objects at an abstract semantic level, based on which fine-level content features are adaptively learned for more accurate multi-level content correspondences. Extensive experiments demonstrate the superiority of our versatile framework over state-of-the-art methods in robust, high-quality and diversified translations, even for challenging and distant domains.
Hypercomplex Image-to-Image Translation
May 04, 2022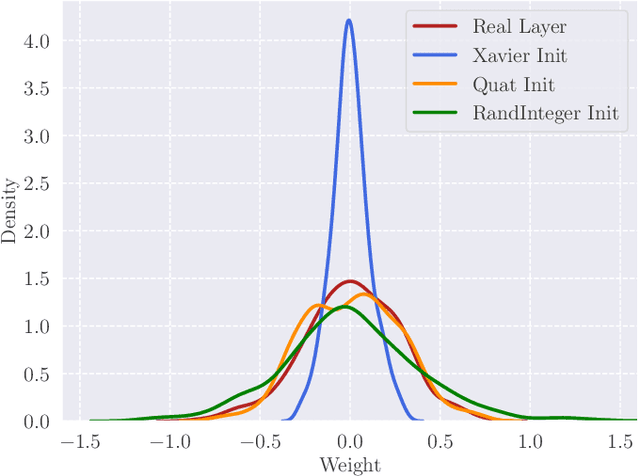
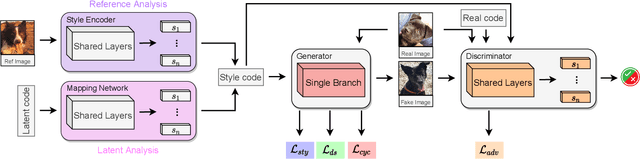


Image-to-image translation (I2I) aims at transferring the content representation from an input domain to an output one, bouncing along different target domains. Recent I2I generative models, which gain outstanding results in this task, comprise a set of diverse deep networks each with tens of million parameters. Moreover, images are usually three-dimensional being composed of RGB channels and common neural models do not take dimensions correlation into account, losing beneficial information. In this paper, we propose to leverage hypercomplex algebra properties to define lightweight I2I generative models capable of preserving pre-existing relations among image dimensions, thus exploiting additional input information. On manifold I2I benchmarks, we show how the proposed Quaternion StarGANv2 and parameterized hypercomplex StarGANv2 (PHStarGANv2) reduce parameters and storage memory amount while ensuring high domain translation performance and good image quality as measured by FID and LPIPS scores. Full code is available at: https://github.com/ispamm/HI2I.
Rethinking CycleGAN: Improving Quality of GANs for Unpaired Image-to-Image Translation
Mar 28, 2023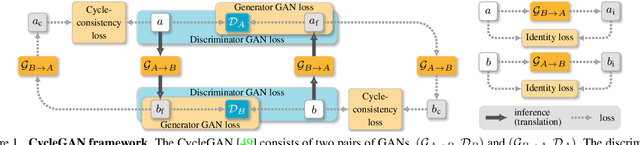
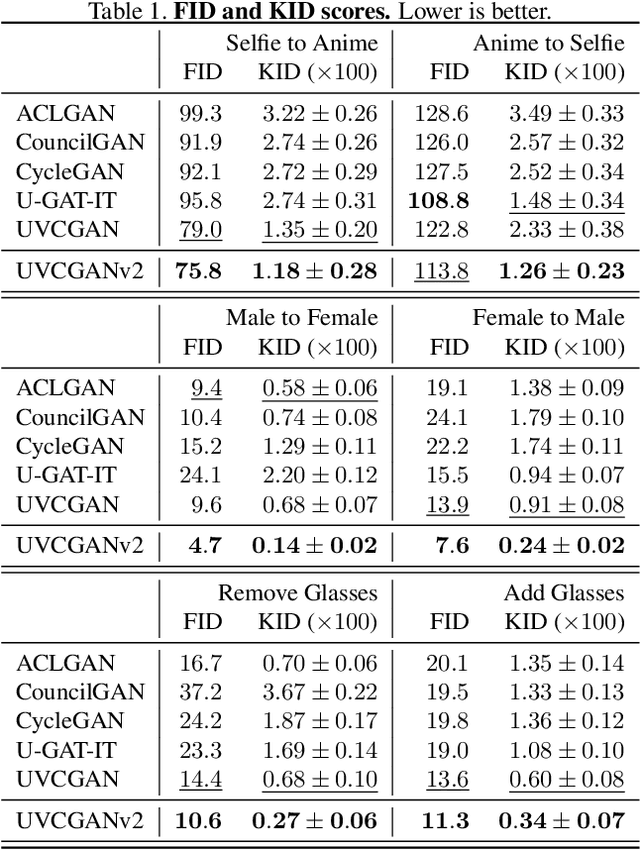

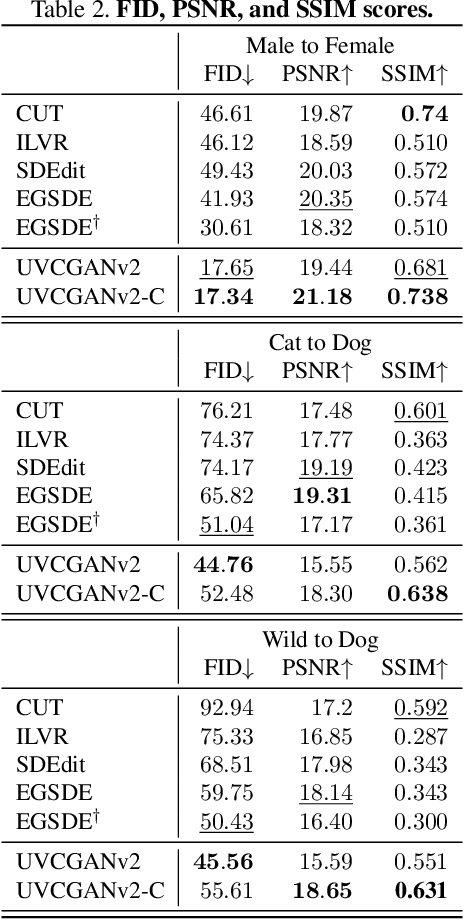
An unpaired image-to-image (I2I) translation technique seeks to find a mapping between two domains of data in a fully unsupervised manner. While the initial solutions to the I2I problem were provided by the generative adversarial neural networks (GANs), currently, diffusion models (DM) hold the state-of-the-art status on the I2I translation benchmarks in terms of FID. Yet, they suffer from some limitations, such as not using data from the source domain during the training, or maintaining consistency of the source and translated images only via simple pixel-wise errors. This work revisits the classic CycleGAN model and equips it with recent advancements in model architectures and model training procedures. The revised model is shown to significantly outperform other advanced GAN- and DM-based competitors on a variety of benchmarks. In the case of Male2Female translation of CelebA, the model achieves over 40% improvement in FID score compared to the state-of-the-art results. This work also demonstrates the ineffectiveness of the pixel-wise I2I translation faithfulness metrics and suggests their revision. The code and trained models are available at https://github.com/LS4GAN/uvcgan2
Exploring Semantic Consistency in Unpaired Image Translation to Generate Data for Surgical Applications
Sep 11, 2023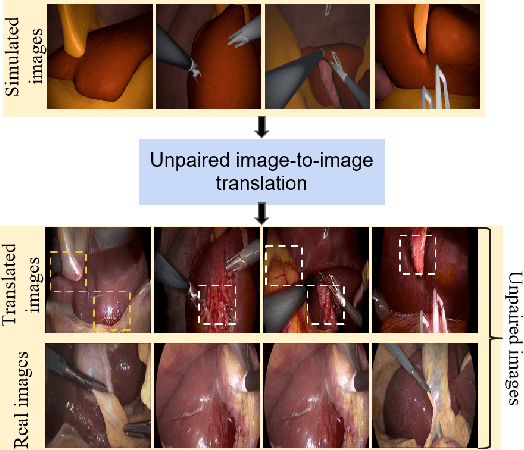
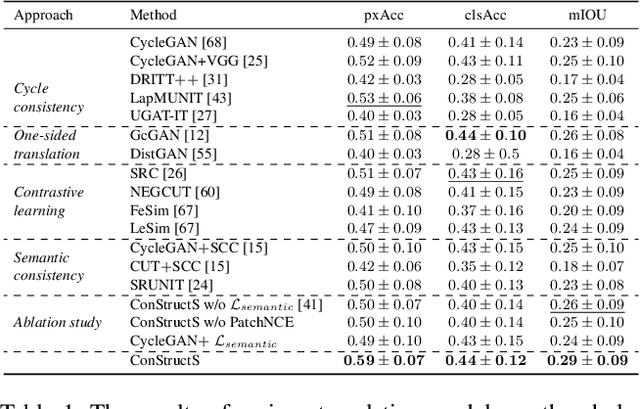
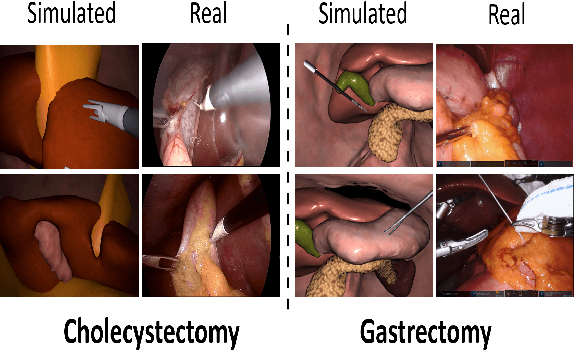
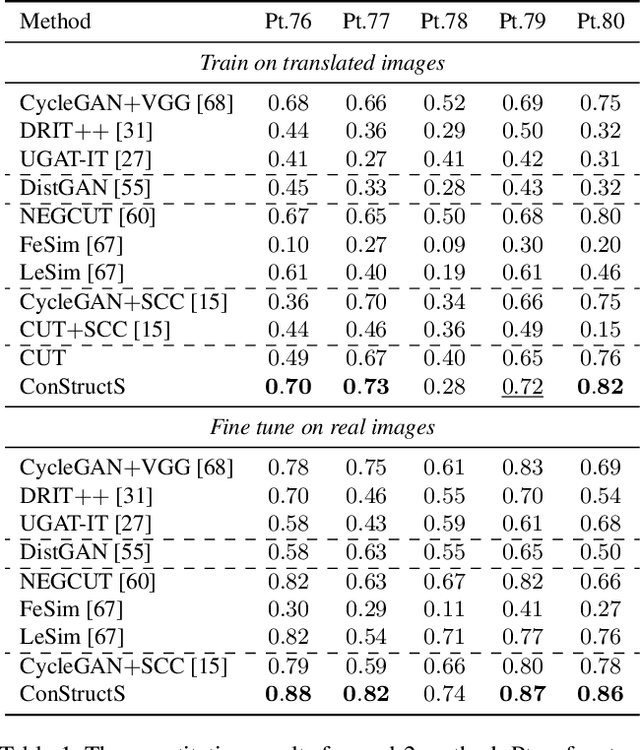
In surgical computer vision applications, obtaining labeled training data is challenging due to data-privacy concerns and the need for expert annotation. Unpaired image-to-image translation techniques have been explored to automatically generate large annotated datasets by translating synthetic images to the realistic domain. However, preserving the structure and semantic consistency between the input and translated images presents significant challenges, mainly when there is a distributional mismatch in the semantic characteristics of the domains. This study empirically investigates unpaired image translation methods for generating suitable data in surgical applications, explicitly focusing on semantic consistency. We extensively evaluate various state-of-the-art image translation models on two challenging surgical datasets and downstream semantic segmentation tasks. We find that a simple combination of structural-similarity loss and contrastive learning yields the most promising results. Quantitatively, we show that the data generated with this approach yields higher semantic consistency and can be used more effectively as training data.
Self-supervised Domain-agnostic Domain Adaptation for Satellite Images
Sep 25, 2023
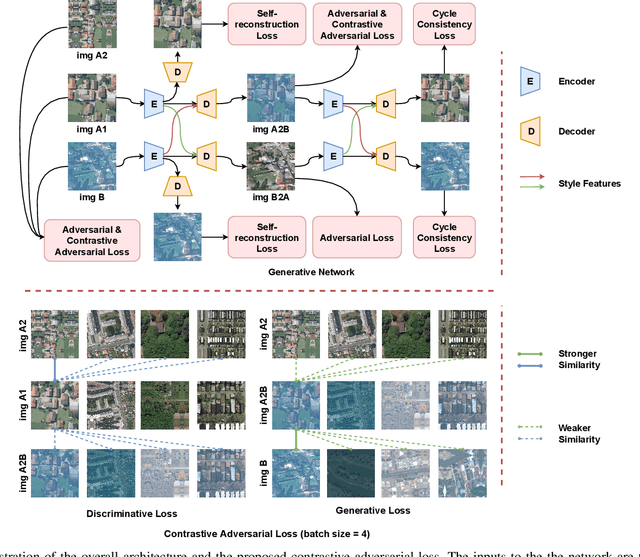

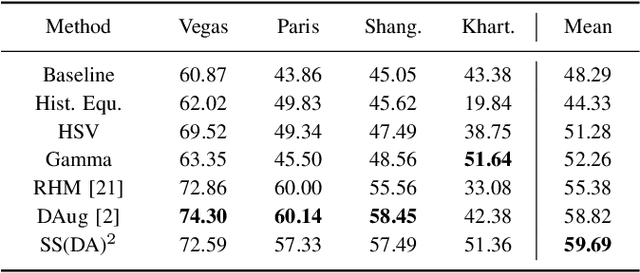
Domain shift caused by, e.g., different geographical regions or acquisition conditions is a common issue in machine learning for global scale satellite image processing. A promising method to address this problem is domain adaptation, where the training and the testing datasets are split into two or multiple domains according to their distributions, and an adaptation method is applied to improve the generalizability of the model on the testing dataset. However, defining the domain to which each satellite image belongs is not trivial, especially under large-scale multi-temporal and multi-sensory scenarios, where a single image mosaic could be generated from multiple data sources. In this paper, we propose an self-supervised domain-agnostic domain adaptation (SS(DA)2) method to perform domain adaptation without such a domain definition. To achieve this, we first design a contrastive generative adversarial loss to train a generative network to perform image-to-image translation between any two satellite image patches. Then, we improve the generalizability of the downstream models by augmenting the training data with different testing spectral characteristics. The experimental results on public benchmarks verify the effectiveness of SS(DA)2.
Application of image-to-image translation in improving pedestrian detection
Sep 08, 2022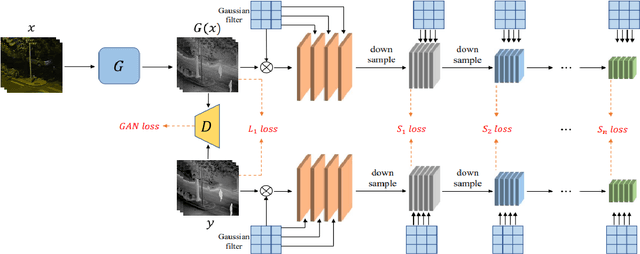
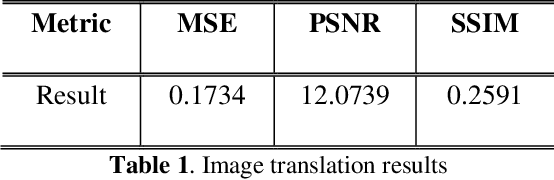

The lack of effective target regions makes it difficult to perform several visual functions in low intensity light, including pedestrian recognition, and image-to-image translation. In this situation, with the accumulation of high-quality information by the combined use of infrared and visible images it is possible to detect pedestrians even in low light. In this study we are going to use advanced deep learning models like pix2pixGAN and YOLOv7 on LLVIP dataset, containing visible-infrared image pairs for low light vision. This dataset contains 33672 images and most of the images were captured in dark scenes, tightly synchronized with time and location.
SemST: Semantically Consistent Multi-Scale Image Translation via Structure-Texture Alignment
Oct 08, 2023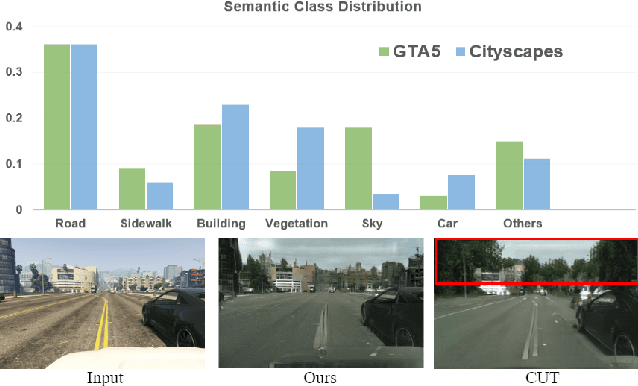
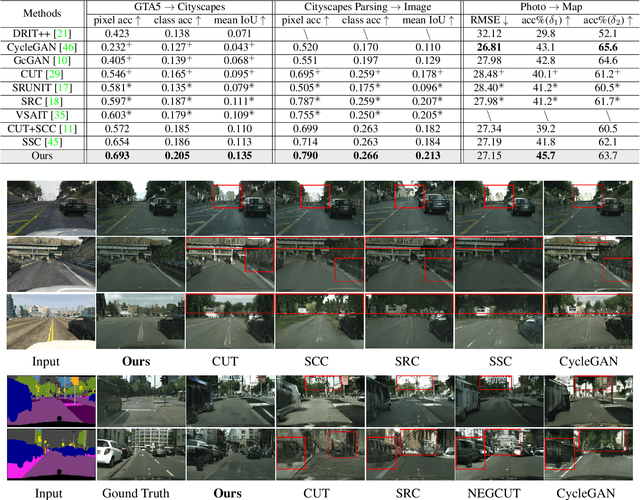
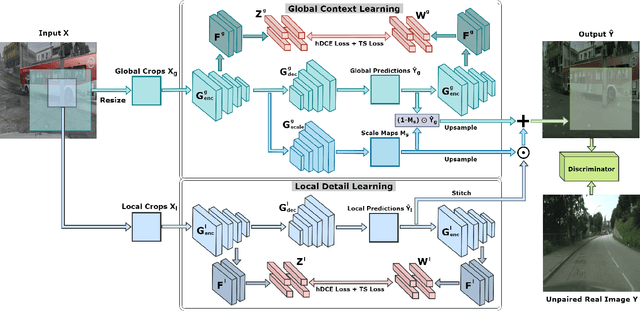
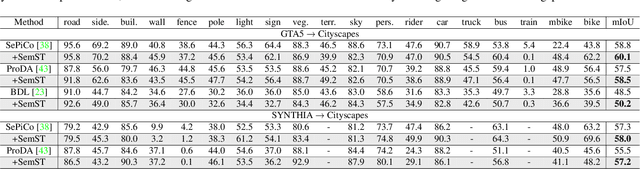
Unsupervised image-to-image (I2I) translation learns cross-domain image mapping that transfers input from the source domain to output in the target domain while preserving its semantics. One challenge is that different semantic statistics in source and target domains result in content discrepancy known as semantic distortion. To address this problem, a novel I2I method that maintains semantic consistency in translation is proposed and named SemST in this work. SemST reduces semantic distortion by employing contrastive learning and aligning the structural and textural properties of input and output by maximizing their mutual information. Furthermore, a multi-scale approach is introduced to enhance translation performance, thereby enabling the applicability of SemST to domain adaptation in high-resolution images. Experiments show that SemST effectively mitigates semantic distortion and achieves state-of-the-art performance. Also, the application of SemST to domain adaptation (DA) is explored. It is demonstrated by preliminary experiments that SemST can be utilized as a beneficial pre-training for the semantic segmentation task.