 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIVOTS: Aligning unseen Structures using Preoperative to Intraoperative Volume-To-Surface Registration for Liver Navigation
Jul 27, 2025



Non-rigid registration is essential for Augmented Reality guided laparoscopic liver surgery by fusing preoperative information, such as tumor location and vascular structures, into the limited intraoperative view, thereby enhancing surgical navigation. A prerequisite is the accurate prediction of intraoperative liver deformation which remains highly challenging due to factors such as large deformation caused by pneumoperitoneum, respiration and tool interaction as well as noisy intraoperative data, and limited field of view due to occlusion and constrained camera movement. To address these challenges, we introduce PIVOTS, a Preoperative to Intraoperative VOlume-To-Surface registration neural network that directly takes point clouds as input for deformation prediction. The geometric feature extraction encoder allows multi-resolution feature extraction, and the decoder, comprising novel deformation aware cross attention modules, enables pre- and intraoperative information interaction and accurate multi-level displacement prediction. We train the neural network on synthetic data simulated from a biomechanical simulation pipeline and validate its performance on both synthetic and real datasets. Results demonstrate superior registration performance of our method compared to baseline methods, exhibiting strong robustness against high amounts of noise, large deformation, and various levels of intraoperative visibility. We publish the training and test sets as evaluation benchmarks and call for a fair comparison of liver registration methods with volume-to-surface data. Code and datasets are available here https://github.com/pengliu-nct/PIVOTS.
Challenging Vision-Language Models with Surgical Data: A New Dataset and Broad Benchmarking Study
Jun 06, 2025While traditional computer vision models have historically struggled to generalize to endoscopic domains, the emergence of foundation models has shown promising cross-domain performance. In this work, we present the first large-scale study assessing the capabilities of Vision Language Models (VLMs) for endoscopic tasks with a specific focus on laparoscopic surgery. Using a diverse set of state-of-the-art models, multiple surgical datasets, and extensive human reference annotations, we address three key research questions: (1) Can current VLMs solve basic perception tasks on surgical images? (2) Can they handle advanced frame-based endoscopic scene understanding tasks? and (3) How do specialized medical VLMs compare to generalist models in this context? Our results reveal that VLMs can effectively perform basic surgical perception tasks, such as object counting and localization, with performance levels comparable to general domain tasks. However, their performance deteriorates significantly when the tasks require medical knowledge. Notably, we find that specialized medical VLMs currently underperform compared to generalist models across both basic and advanced surgical tasks, suggesting that they are not yet optimized for the complexity of surgical environments. These findings highlight the need for further advancements to enable VLMs to handle the unique challenges posed by surgery. Overall, our work provides important insights for the development of next-generation endoscopic AI systems and identifies key areas for improvement in medical visual language models.
Mission Balance: Generating Under-represented Class Samples using Video Diffusion Models
May 14, 2025Computer-assisted interventions can improve intra-operative guidance, particularly through deep learning methods that harness the spatiotemporal information in surgical videos. However, the severe data imbalance often found in surgical video datasets hinders the development of high-performing models. In this work, we aim to overcome the data imbalance by synthesizing surgical videos. We propose a unique two-stage, text-conditioned diffusion-based method to generate high-fidelity surgical videos for under-represented classes. Our approach conditions the generation process on text prompts and decouples spatial and temporal modeling by utilizing a 2D latent diffusion model to capture spatial content and then integrating temporal attention layers to ensure temporal consistency. Furthermore, we introduce a rejection sampling strategy to select the most suitable synthetic samples, effectively augmenting existing datasets to address class imbalance. We evaluate our method on two downstream tasks-surgical action recognition and intra-operative event prediction-demonstrating that incorporating synthetic videos from our approach substantially enhances model performance. We open-source our implementation at https://gitlab.com/nct_tso_public/surgvgen.
Synthesizing Multi-Class Surgical Datasets with Anatomy-Aware Diffusion Models
Oct 10, 2024In computer-assisted surgery, automatically recognizing anatomical organs is crucial for understanding the surgical scene and providing intraoperative assistance. While machine learning models can identify such structures, their deployment is hindered by the need for labeled, diverse surgical datasets with anatomical annotations. Labeling multiple classes (i.e., organs) in a surgical scene is time-intensive, requiring medical experts. Although synthetically generated images can enhance segmentation performance, maintaining both organ structure and texture during generation is challenging. We introduce a multi-stage approach using diffusion models to generate multi-class surgical datasets with annotations. Our framework improves anatomy awareness by training organ specific models with an inpainting objective guided by binary segmentation masks. The organs are generated with an inference pipeline using pre-trained ControlNet to maintain the organ structure. The synthetic multi-class datasets are constructed through an image composition step, ensuring structural and textural consistency. This versatile approach allows the generation of multi-class datasets from real binary datasets and simulated surgical masks. We thoroughly evaluate the generated datasets on image quality and downstream segmentation, achieving a $15\%$ improvement in segmentation scores when combined with real images. Our codebase https://gitlab.com/nct_tso_public/muli-class-image-synthesis
Exploring Semantic Consistency in Unpaired Image Translation to Generate Data for Surgical Applications
Sep 11, 2023In surgical computer vision applications, obtaining labeled training data is challenging due to data-privacy concerns and the need for expert annotation. Unpaired image-to-image translation techniques have been explored to automatically generate large annotated datasets by translating synthetic images to the realistic domain. However, preserving the structure and semantic consistency between the input and translated images presents significant challenges, mainly when there is a distributional mismatch in the semantic characteristics of the domains. This study empirically investigates unpaired image translation methods for generating suitable data in surgical applications, explicitly focusing on semantic consistency. We extensively evaluate various state-of-the-art image translation models on two challenging surgical datasets and downstream semantic segmentation tasks. We find that a simple combination of structural-similarity loss and contrastive learning yields the most promising results. Quantitatively, we show that the data generated with this approach yields higher semantic consistency and can be used more effectively as training data.
Long-Term Temporally Consistent Unpaired Video Translation from Simulated Surgical 3D Data
Mar 31, 2021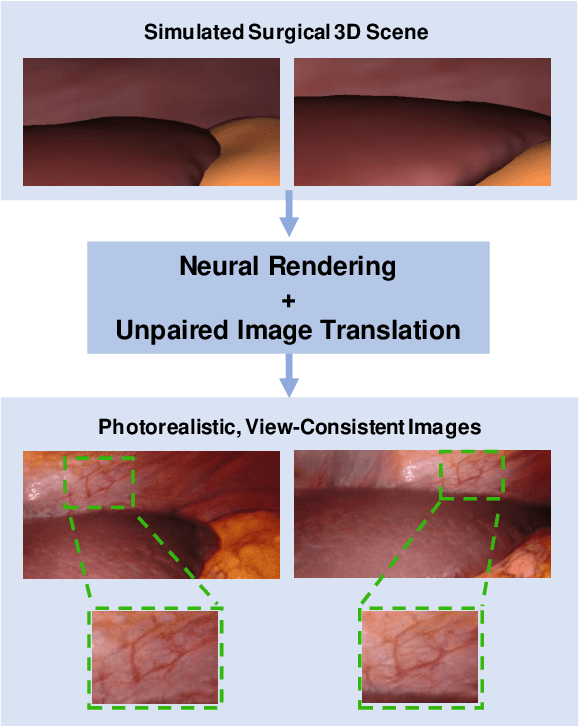
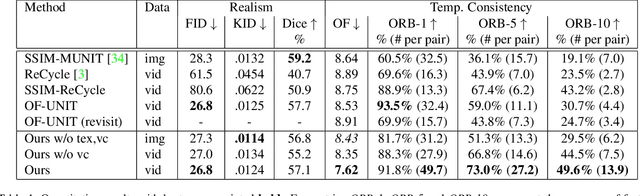
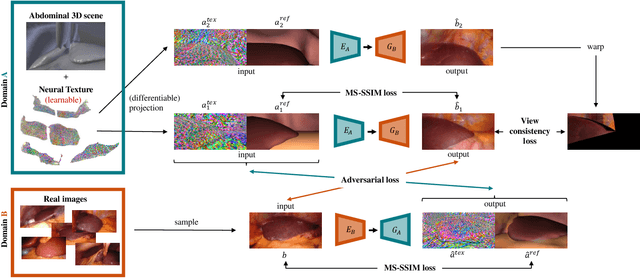
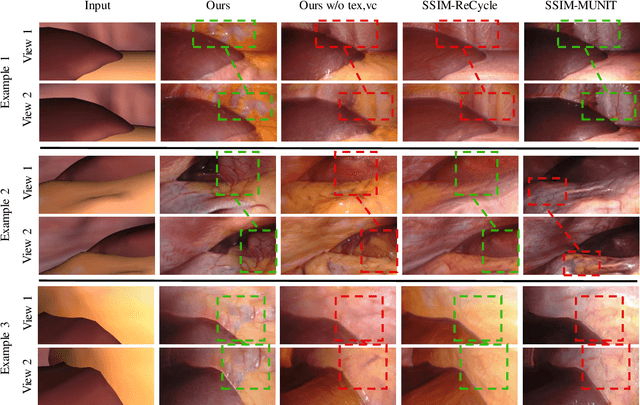
Research in unpaired video translation has mainly focused on short-term temporal consistency by conditioning on neighboring frames. However for transfer from simulated to photorealistic sequences, available information on the underlying geometry offers potential for achieving global consistency across views. We propose a novel approach which combines unpaired image translation with neural rendering to transfer simulated to photorealistic surgical abdominal scenes. By introducing global learnable textures and a lighting-invariant view-consistency loss, our method produces consistent translations of arbitrary views and thus enables long-term consistent video synthesis. We design and test our model to generate video sequences from minimally-invasive surgical abdominal scenes. Because labeled data is often limited in this domain, photorealistic data where ground truth information from the simulated domain is preserved is especially relevant. By extending existing image-based methods to view-consistent videos, we aim to impact the applicability of simulated training and evaluation environments for surgical applications. Code and data will be made publicly available soon.