 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Agent Path Finding
Papers and Code
Multi-Agent Path Finding via Offline RL and LLM Collaboration
Sep 26, 2025Multi-Agent Path Finding (MAPF) poses a significant and challenging problem critical for applications in robotics and logistics, particularly due to its combinatorial complexity and the partial observability inherent in realistic environments. Decentralized reinforcement learning methods commonly encounter two substantial difficulties: first, they often yield self-centered behaviors among agents, resulting in frequent collisions, and second, their reliance on complex communication modules leads to prolonged training times, sometimes spanning weeks. To address these challenges, we propose an efficient decentralized planning framework based on the Decision Transformer (DT), uniquely leveraging offline reinforcement learning to substantially reduce training durations from weeks to mere hours. Crucially, our approach effectively handles long-horizon credit assignment and significantly improves performance in scenarios with sparse and delayed rewards. Furthermore, to overcome adaptability limitations inherent in standard RL methods under dynamic environmental changes, we integrate a large language model (GPT-4o) to dynamically guide agent policies. Extensive experiments in both static and dynamically changing environments demonstrate that our DT-based approach, augmented briefly by GPT-4o, significantly enhances adaptability and performance.
Design for One, Deploy for Many: Navigating Tree Mazes with Multiple Agents
Oct 30, 2025



Maze-like environments, such as cave and pipe networks, pose unique challenges for multiple robots to coordinate, including communication constraints and congestion. To address these challenges, we propose a distributed multi-agent maze traversal algorithm for environments that can be represented by acyclic graphs. It uses a leader-switching mechanism where one agent, assuming a head role, employs any single-agent maze solver while the other agents each choose an agent to follow. The head role gets transferred to neighboring agents where necessary, ensuring it follows the same path as a single agent would. The multi-agent maze traversal algorithm is evaluated in simulations with groups of up to 300 agents, various maze sizes, and multiple single-agent maze solvers. It is compared against strategies that are na\"ive, or assume either global communication or full knowledge of the environment. The algorithm outperforms the na\"ive strategy in terms of makespan and sum-of-fuel. It is superior to the global-communication strategy in terms of makespan but is inferior to it in terms of sum-of-fuel. The findings suggest it is asymptotically equivalent to the full-knowledge strategy with respect to either metric. Moreover, real-world experiments with up to 20 Pi-puck robots confirm the feasibility of the approach.
Asynchronous Risk-Aware Multi-Agent Packet Routing for Ultra-Dense LEO Satellite Networks
Oct 31, 2025The rise of ultra-dense LEO constellations creates a complex and asynchronous network environment, driven by their massive scale, dynamic topologies, and significant delays. This unique complexity demands an adaptive packet routing algorithm that is asynchronous, risk-aware, and capable of balancing diverse and often conflicting QoS objectives in a decentralized manner. However, existing methods fail to address this need, as they typically rely on impractical synchronous decision-making and/or risk-oblivious approaches. To tackle this gap, we introduce PRIMAL, an event-driven multi-agent routing framework designed specifically to allow each satellite to act independently on its own event-driven timeline, while managing the risk of worst-case performance degradation via a principled primal-dual approach. This is achieved by enabling agents to learn the full cost distribution of the targeted QoS objectives and constrain tail-end risks. Extensive simulations on a LEO constellation with 1584 satellites validate its superiority in effectively optimizing latency and balancing load. Compared to a recent risk-oblivious baseline, it reduces queuing delay by over 70%, and achieves a nearly 12 ms end-to-end delay reduction in loaded scenarios. This is accomplished by resolving the core conflict between naive shortest-path finding and congestion avoidance, highlighting such autonomous risk-awareness as a key to robust routing.
Network-Constrained Policy Optimization for Adaptive Multi-agent Vehicle Routing
Oct 30, 2025Traffic congestion in urban road networks leads to longer trip times and higher emissions, especially during peak periods. While the Shortest Path First (SPF) algorithm is optimal for a single vehicle in a static network, it performs poorly in dynamic, multi-vehicle settings, often worsening congestion by routing all vehicles along identical paths. We address dynamic vehicle routing through a multi-agent reinforcement learning (MARL) framework for coordinated, network-aware fleet navigation. We first propose Adaptive Navigation (AN), a decentralized MARL model where each intersection agent provides routing guidance based on (i) local traffic and (ii) neighborhood state modeled using Graph Attention Networks (GAT). To improve scalability in large networks, we further propose Hierarchical Hub-based Adaptive Navigation (HHAN), an extension of AN that assigns agents only to key intersections (hubs). Vehicles are routed hub-to-hub under agent control, while SPF handles micro-routing within each hub region. For hub coordination, HHAN adopts centralized training with decentralized execution (CTDE) under the Attentive Q-Mixing (A-QMIX) framework, which aggregates asynchronous vehicle decisions via attention. Hub agents use flow-aware state features that combine local congestion and predictive dynamics for proactive routing. Experiments on synthetic grids and real urban maps (Toronto, Manhattan) show that AN reduces average travel time versus SPF and learning baselines, maintaining 100% routing success. HHAN scales to networks with hundreds of intersections, achieving up to 15.9% improvement under heavy traffic. These findings highlight the potential of network-constrained MARL for scalable, coordinated, and congestion-aware routing in intelligent transportation systems.
Diffusion-Guided Multi-Arm Motion Planning
Sep 09, 2025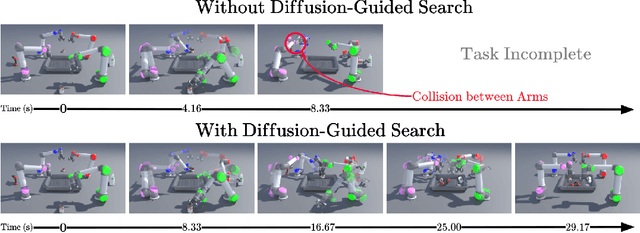
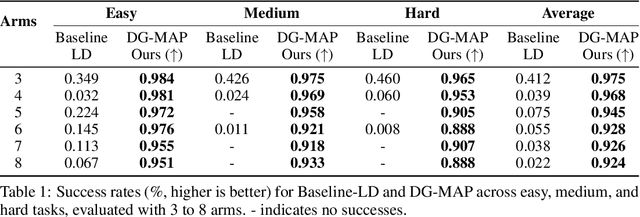
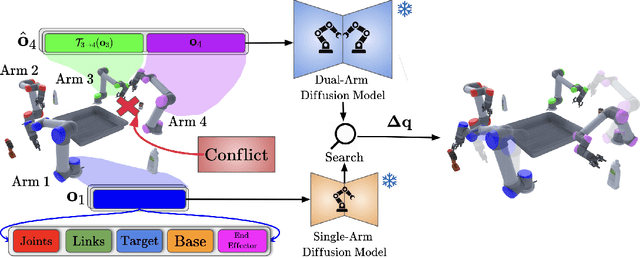
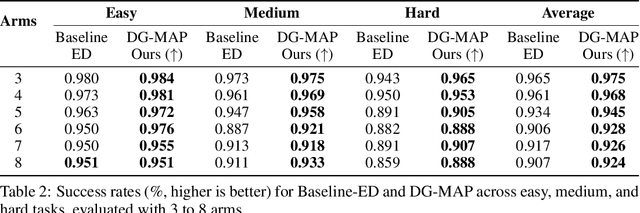
Multi-arm motion planning is fundamental for enabling arms to complete complex long-horizon tasks in shared spaces efficiently but current methods struggle with scalability due to exponential state-space growth and reliance on large training datasets for learned models. Inspired by Multi-Agent Path Finding (MAPF), which decomposes planning into single-agent problems coupled with collision resolution, we propose a novel diffusion-guided multi-arm planner (DG-MAP) that enhances scalability of learning-based models while reducing their reliance on massive multi-arm datasets. Recognizing that collisions are primarily pairwise, we train two conditional diffusion models, one to generate feasible single-arm trajectories, and a second, to model the dual-arm dynamics required for effective pairwise collision resolution. By integrating these specialized generative models within a MAPF-inspired structured decomposition, our planner efficiently scales to larger number of arms. Evaluations against alternative learning-based methods across various team sizes demonstrate our method's effectiveness and practical applicability. Project website can be found at https://diff-mapf-mers.csail.mit.edu
Neural Algorithmic Reasoners informed Large Language Model for Multi-Agent Path Finding
Aug 25, 2025The development and application of large language models (LLM) have demonstrated that foundational models can be utilized to solve a wide array of tasks. However, their performance in multi-agent path finding (MAPF) tasks has been less than satisfactory, with only a few studies exploring this area. MAPF is a complex problem requiring both planning and multi-agent coordination. To improve the performance of LLM in MAPF tasks, we propose a novel framework, LLM-NAR, which leverages neural algorithmic reasoners (NAR) to inform LLM for MAPF. LLM-NAR consists of three key components: an LLM for MAPF, a pre-trained graph neural network-based NAR, and a cross-attention mechanism. This is the first work to propose using a neural algorithmic reasoner to integrate GNNs with the map information for MAPF, thereby guiding LLM to achieve superior performance. LLM-NAR can be easily adapted to various LLM models. Both simulation and real-world experiments demonstrate that our method significantly outperforms existing LLM-based approaches in solving MAPF problems.
Discrete-Guided Diffusion for Scalable and Safe Multi-Robot Motion Planning
Aug 27, 2025



Multi-Robot Motion Planning (MRMP) involves generating collision-free trajectories for multiple robots operating in a shared continuous workspace. While discrete multi-agent path finding (MAPF) methods are broadly adopted due to their scalability, their coarse discretization severely limits trajectory quality. In contrast, continuous optimization-based planners offer higher-quality paths but suffer from the curse of dimensionality, resulting in poor scalability with respect to the number of robots. This paper tackles the limitations of these two approaches by introducing a novel framework that integrates discrete MAPF solvers with constrained generative diffusion models. The resulting framework, called Discrete-Guided Diffusion (DGD), has three key characteristics: (1) it decomposes the original nonconvex MRMP problem into tractable subproblems with convex configuration spaces, (2) it combines discrete MAPF solutions with constrained optimization techniques to guide diffusion models capture complex spatiotemporal dependencies among robots, and (3) it incorporates a lightweight constraint repair mechanism to ensure trajectory feasibility. The proposed method sets a new state-of-the-art performance in large-scale, complex environments, scaling to 100 robots while achieving planning efficiency and high success rates.
Multi-Agent Path Finding Among Dynamic Uncontrollable Agents with Statistical Safety Guarantees
Jul 29, 2025



Existing multi-agent path finding (MAPF) solvers do not account for uncertain behavior of uncontrollable agents. We present a novel variant of Enhanced Conflict-Based Search (ECBS), for both one-shot and lifelong MAPF in dynamic environments with uncontrollable agents. Our method consists of (1) training a learned predictor for the movement of uncontrollable agents, (2) quantifying the prediction error using conformal prediction (CP), a tool for statistical uncertainty quantification, and (3) integrating these uncertainty intervals into our modified ECBS solver. Our method can account for uncertain agent behavior, comes with statistical guarantees on collision-free paths for one-shot missions, and scales to lifelong missions with a receding horizon sequence of one-shot instances. We run our algorithm, CP-Solver, across warehouse and game maps, with competitive throughput and reduced collisions.
ReSeek: A Self-Correcting Framework for Search Agents with Instructive Rewards
Oct 01, 2025



Search agents powered by Large Language Models (LLMs) have demonstrated significant potential in tackling knowledge-intensive tasks. Reinforcement learning (RL) has emerged as a powerful paradigm for training these agents to perform complex, multi-step reasoning. However, prior RL-based methods often rely on sparse or rule-based rewards, which can lead agents to commit to suboptimal or erroneous reasoning paths without the ability to recover. To address these limitations, we propose ReSeek, a novel self-correcting framework for training search agents. Our framework introduces a self-correction mechanism that empowers the agent to dynamically identify and recover from erroneous search paths during an episode. By invoking a special JUDGE action, the agent can judge the information and re-plan its search strategy. To guide this process, we design a dense, instructive process reward function, which decomposes into a correctness reward for retrieving factual information and a utility reward for finding information genuinely useful for the query. Furthermore, to mitigate the risk of data contamination in existing datasets, we introduce FictionalHot, a new and challenging benchmark with recently curated questions requiring complex reasoning. Being intuitively reasonable and practically simple, extensive experiments show that agents trained with ReSeek significantly outperform SOTA baselines in task success rate and path faithfulness.
New Mechanisms in Flex Distribution for Bounded Suboptimal Multi-Agent Path Finding
Jul 22, 2025



Multi-Agent Path Finding (MAPF) is the problem of finding a set of collision-free paths, one for each agent in a shared environment. Its objective is to minimize the sum of path costs (SOC), where the path cost of each agent is defined as the travel time from its start location to its target location. Explicit Estimation Conflict-Based Search (EECBS) is the leading algorithm for bounded-suboptimal MAPF, with the SOC of the solution being at most a user-specified factor $w$ away from optimal. EECBS maintains sets of paths and a lower bound $LB$ on the optimal SOC. Then, it iteratively selects a set of paths whose SOC is at most $w \cdot LB$ and introduces constraints to resolve collisions. For each path in a set, EECBS maintains a lower bound on its optimal path that satisfies constraints. By finding an individually bounded-suboptimal path with cost at most a threshold of $w$ times its lower bound, EECBS guarantees to find a bounded-suboptimal solution. To speed up EECBS, previous work uses flex distribution to increase the threshold. Though EECBS with flex distribution guarantees to find a bounded-suboptimal solution, increasing the thresholds may push the SOC beyond $w \cdot LB$, forcing EECBS to switch among different sets of paths instead of resolving collisions on a particular set of paths, and thus reducing efficiency. To address this issue, we propose Conflict-Based Flex Distribution that distributes flex in proportion to the number of collisions. We also estimate the delays needed to satisfy constraints and propose Delay-Based Flex Distribution. On top of that, we propose Mixed-Strategy Flex Distribution, combining both in a hierarchical framework. We prove that EECBS with our new flex distribution mechanisms is complete and bounded-suboptimal. Our experiments show that our approaches outperform the original (greedy) flex distribution.