 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Path Finding Among Dynamic Uncontrollable Agents with Statistical Safety Guarantees
Jul 29, 2025



Existing multi-agent path finding (MAPF) solvers do not account for uncertain behavior of uncontrollable agents. We present a novel variant of Enhanced Conflict-Based Search (ECBS), for both one-shot and lifelong MAPF in dynamic environments with uncontrollable agents. Our method consists of (1) training a learned predictor for the movement of uncontrollable agents, (2) quantifying the prediction error using conformal prediction (CP), a tool for statistical uncertainty quantification, and (3) integrating these uncertainty intervals into our modified ECBS solver. Our method can account for uncertain agent behavior, comes with statistical guarantees on collision-free paths for one-shot missions, and scales to lifelong missions with a receding horizon sequence of one-shot instances. We run our algorithm, CP-Solver, across warehouse and game maps, with competitive throughput and reduced collisions.
New Mechanisms in Flex Distribution for Bounded Suboptimal Multi-Agent Path Finding
Jul 22, 2025



Multi-Agent Path Finding (MAPF) is the problem of finding a set of collision-free paths, one for each agent in a shared environment. Its objective is to minimize the sum of path costs (SOC), where the path cost of each agent is defined as the travel time from its start location to its target location. Explicit Estimation Conflict-Based Search (EECBS) is the leading algorithm for bounded-suboptimal MAPF, with the SOC of the solution being at most a user-specified factor $w$ away from optimal. EECBS maintains sets of paths and a lower bound $LB$ on the optimal SOC. Then, it iteratively selects a set of paths whose SOC is at most $w \cdot LB$ and introduces constraints to resolve collisions. For each path in a set, EECBS maintains a lower bound on its optimal path that satisfies constraints. By finding an individually bounded-suboptimal path with cost at most a threshold of $w$ times its lower bound, EECBS guarantees to find a bounded-suboptimal solution. To speed up EECBS, previous work uses flex distribution to increase the threshold. Though EECBS with flex distribution guarantees to find a bounded-suboptimal solution, increasing the thresholds may push the SOC beyond $w \cdot LB$, forcing EECBS to switch among different sets of paths instead of resolving collisions on a particular set of paths, and thus reducing efficiency. To address this issue, we propose Conflict-Based Flex Distribution that distributes flex in proportion to the number of collisions. We also estimate the delays needed to satisfy constraints and propose Delay-Based Flex Distribution. On top of that, we propose Mixed-Strategy Flex Distribution, combining both in a hierarchical framework. We prove that EECBS with our new flex distribution mechanisms is complete and bounded-suboptimal. Our experiments show that our approaches outperform the original (greedy) flex distribution.
Anytime Multi-Agent Path Finding with an Adaptive Delay-Based Heuristic
Aug 06, 2024



Anytime multi-agent path finding (MAPF) is a promising approach to scalable path optimization in multi-agent systems. MAPF-LNS, based on Large Neighborhood Search (LNS), is the current state-of-the-art approach where a fast initial solution is iteratively optimized by destroying and repairing selected paths of the solution. Current MAPF-LNS variants commonly use an adaptive selection mechanism to choose among multiple destroy heuristics. However, to determine promising destroy heuristics, MAPF-LNS requires a considerable amount of exploration time. As common destroy heuristics are non-adaptive, any performance bottleneck caused by these heuristics cannot be overcome via adaptive heuristic selection alone, thus limiting the overall effectiveness of MAPF-LNS in terms of solution cost. In this paper, we propose Adaptive Delay-based Destroy-and-Repair Enhanced with Success-based Self-Learning (ADDRESS) as a single-destroy-heuristic variant of MAPF-LNS. ADDRESS applies restricted Thompson Sampling to the top-K set of the most delayed agents to select a seed agent for adaptive LNS neighborhood generation. We evaluate ADDRESS in multiple maps from the MAPF benchmark set and demonstrate cost improvements by at least 50% in large-scale scenarios with up to a thousand agents, compared with the original MAPF-LNS and other state-of-the-art methods.
Architectural Influence on Variational Quantum Circuits in Multi-Agent Reinforcement Learning: Evolutionary Strategies for Optimization
Jul 30, 2024



In recent years, Multi-Agent Reinforcement Learning (MARL) has found application in numerous areas of science and industry, such as autonomous driving, telecommunications, and global health. Nevertheless, MARL suffers from, for instance, an exponential growth of dimensions. Inherent properties of quantum mechanics help to overcome these limitations, e.g., by significantly reducing the number of trainable parameters. Previous studies have developed an approach that uses gradient-free quantum Reinforcement Learning and evolutionary optimization for variational quantum circuits (VQCs) to reduce the trainable parameters and avoid barren plateaus as well as vanishing gradients. This leads to a significantly better performance of VQCs compared to classical neural networks with a similar number of trainable parameters and a reduction in the number of parameters by more than 97 \% compared to similarly good neural networks. We extend an approach of K\"olle et al. by proposing a Gate-Based, a Layer-Based, and a Prototype-Based concept to mutate and recombine VQCs. Our results show the best performance for mutation-only strategies and the Gate-Based approach. In particular, we observe a significantly better score, higher total and own collected coins, as well as a superior own coin rate for the best agent when evaluated in the Coin Game environment.
Aquarium: A Comprehensive Framework for Exploring Predator-Prey Dynamics through Multi-Agent Reinforcement Learning Algorithms
Jan 13, 2024



Recent advances in Multi-Agent Reinforcement Learning have prompted the modeling of intricate interactions between agents in simulated environments. In particular, the predator-prey dynamics have captured substantial interest and various simulations been tailored to unique requirements. To prevent further time-intensive developments, we introduce Aquarium, a comprehensive Multi-Agent Reinforcement Learning environment for predator-prey interaction, enabling the study of emergent behavior. Aquarium is open source and offers a seamless integration of the PettingZoo framework, allowing a quick start with proven algorithm implementations. It features physics-based agent movement on a two-dimensional, edge-wrapping plane. The agent-environment interaction (observations, actions, rewards) and the environment settings (agent speed, prey reproduction, predator starvation, and others) are fully customizable. Besides a resource-efficient visualization, Aquarium supports to record video files, providing a visual comprehension of agent behavior. To demonstrate the environment's capabilities, we conduct preliminary studies which use PPO to train multiple prey agents to evade a predator. In accordance to the literature, we find Individual Learning to result in worse performance than Parameter Sharing, which significantly improves coordination and sample-efficiency.
ClusterComm: Discrete Communication in Decentralized MARL using Internal Representation Clustering
Jan 07, 2024



In the realm of Multi-Agent Reinforcement Learning (MARL), prevailing approaches exhibit shortcomings in aligning with human learning, robustness, and scalability. Addressing this, we introduce ClusterComm, a fully decentralized MARL framework where agents communicate discretely without a central control unit. ClusterComm utilizes Mini-Batch-K-Means clustering on the last hidden layer's activations of an agent's policy network, translating them into discrete messages. This approach outperforms no communication and competes favorably with unbounded, continuous communication and hence poses a simple yet effective strategy for enhancing collaborative task-solving in MARL.
Adaptive Anytime Multi-Agent Path Finding Using Bandit-Based Large Neighborhood Search
Jan 01, 2024



Anytime multi-agent path finding (MAPF) is a promising approach to scalable path optimization in large-scale multi-agent systems. State-of-the-art anytime MAPF is based on Large Neighborhood Search (LNS), where a fast initial solution is iteratively optimized by destroying and repairing a fixed number of parts, i.e., the neighborhood, of the solution, using randomized destroy heuristics and prioritized planning. Despite their recent success in various MAPF instances, current LNS-based approaches lack exploration and flexibility due to greedy optimization with a fixed neighborhood size which can lead to low quality solutions in general. So far, these limitations have been addressed with extensive prior effort in tuning or offline machine learning beyond actual planning. In this paper, we focus on online learning in LNS and propose Bandit-based Adaptive LArge Neighborhood search Combined with Exploration (BALANCE). BALANCE uses a bi-level multi-armed bandit scheme to adapt the selection of destroy heuristics and neighborhood sizes on the fly during search. We evaluate BALANCE on multiple maps from the MAPF benchmark set and empirically demonstrate cost improvements of at least 50% compared to state-of-the-art anytime MAPF in large-scale scenarios. We find that Thompson Sampling performs particularly well compared to alternative multi-armed bandit algorithms.
Challenges for Reinforcement Learning in Quantum Computing
Dec 18, 2023


Quantum computing (QC) in the current NISQ-era is still limited. To gain early insights and advantages, hybrid applications are widely considered mitigating those shortcomings. Hybrid quantum machine learning (QML) comprises both the application of QC to improve machine learning (ML), and the application of ML to improve QC architectures. This work considers the latter, focusing on leveraging reinforcement learning (RL) to improve current QC approaches. We therefore introduce various generic challenges arising from quantum architecture search and quantum circuit optimization that RL algorithms need to solve to provide benefits for more complex applications and combinations of those. Building upon these challenges we propose a concrete framework, formalized as a Markov decision process, to enable to learn policies that are capable of controlling a universal set of quantum gates. Furthermore, we provide benchmark results to assess shortcomings and strengths of current state-of-the-art algorithms.
Multi-Agent Quantum Reinforcement Learning using Evolutionary Optimization
Nov 09, 2023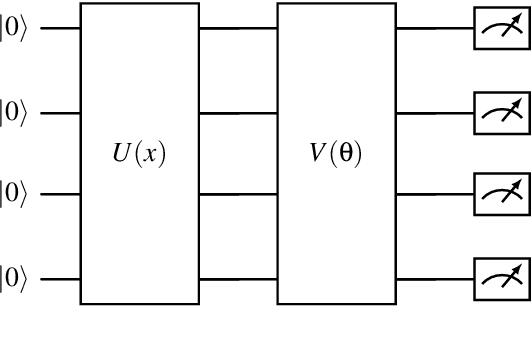



Multi-Agent Reinforcement Learning is becoming increasingly more important in times of autonomous driving and other smart industrial applications. Simultaneously a promising new approach to Reinforcement Learning arises using the inherent properties of quantum mechanics, reducing the trainable parameters of a model significantly. However, gradient-based Multi-Agent Quantum Reinforcement Learning methods often have to struggle with barren plateaus, holding them back from matching the performance of classical approaches. We build upon a existing approach for gradient free Quantum Reinforcement Learning and propose tree approaches with Variational Quantum Circuits for Multi-Agent Reinforcement Learning using evolutionary optimization. We evaluate our approach in the Coin Game environment and compare them to classical approaches. We showed that our Variational Quantum Circuit approaches perform significantly better compared to a neural network with a similar amount of trainable parameters. Compared to the larger neural network, our approaches archive similar results using $97.88\%$ less parameters.
CROP: Towards Distributional-Shift Robust Reinforcement Learning using Compact Reshaped Observation Processing
Apr 26, 2023



The safe application of reinforcement learning (RL) requires generalization from limited training data to unseen scenarios. Yet, fulfilling tasks under changing circumstances is a key challenge in RL. Current state-of-the-art approaches for generalization apply data augmentation techniques to increase the diversity of training data. Even though this prevents overfitting to the training environment(s), it hinders policy optimization. Crafting a suitable observation, only containing crucial information, has been shown to be a challenging task itself. To improve data efficiency and generalization capabilities, we propose Compact Reshaped Observation Processing (CROP) to reduce the state information used for policy optimization. By providing only relevant information, overfitting to a specific training layout is precluded and generalization to unseen environments is improved. We formulate three CROPs that can be applied to fully observable observation- and action-spaces and provide methodical foundation. We empirically show the improvements of CROP in a distributionally shifted safety gridworld. We furthermore provide benchmark comparisons to full observability and data-augmentation in two different-sized procedurally generated mazes.