 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Neighborhood Search for Multi-Agent Task Assignment and Path Finding with Precedence Constraints
Mar 30, 2026Many multi-robot applications require tasks to be completed efficiently and in the correct order, so that downstream operations can proceed at the right time. Multi-agent path finding with precedence constraints (MAPF-PC) is a well-studied framework for computing collision-free plans that satisfy ordering relations when task sequences are fixed in advance. In many applications, however, solution quality depends not only on how agents move, but also on which agent performs which task. This motivates the lifted problem of task assignment and path finding with precedence constraints (TAPF-PC), which extends MAPF-PC by jointly optimizing assignment, precedence satisfaction, and routing cost. To address the resulting coupled TAPF-PC search space, we develop a large neighborhood search approach that starts from a feasible MAPF-PC seed and iteratively improves it through reassignment-based neighborhood repair, restoring feasibility within each selected neighborhood. Experiments across multiple benchmark families and scaling regimes show that the best-performing configuration improves 89.1% of instances over fixed-assignment seed solutions, demonstrating that large neighborhood search effectively captures the gains from flexible reassignment under precedence constraints.
Risk-Bounded Multi-Agent Visual Navigation via Dynamic Budget Allocation
Sep 09, 2025Safe navigation is essential for autonomous systems operating in hazardous environments, especially when multiple agents must coordinate using just visual inputs over extended time horizons. Traditional planning methods excel at solving long-horizon tasks but rely on predefined distance metrics, while safe Reinforcement Learning (RL) can learn complex behaviors using high-dimensional inputs yet struggles with multi-agent, goal-conditioned scenarios. Recent work combined these paradigms by leveraging goal-conditioned RL (GCRL) to build an intermediate graph from replay buffer states, pruning unsafe edges, and using Conflict-Based Search (CBS) for multi-agent path planning. Although effective, this graph-pruning approach can be overly conservative, limiting mission efficiency by precluding missions that must traverse high-risk regions. To address this limitation, we propose RB-CBS, a novel extension to CBS that dynamically allocates and adjusts user-specified risk bound ($\Delta$) across agents to flexibly trade off safety and speed. Our improved planner ensures that each agent receives a local risk budget ($\delta$) enabling more efficient navigation while still respecting overall safety constraints. Experimental results demonstrate that this iterative risk-allocation framework yields superior performance in complex environments, allowing multiple agents to find collision-free paths within the user-specified $\Delta$.
Diffusion-Guided Multi-Arm Motion Planning
Sep 09, 2025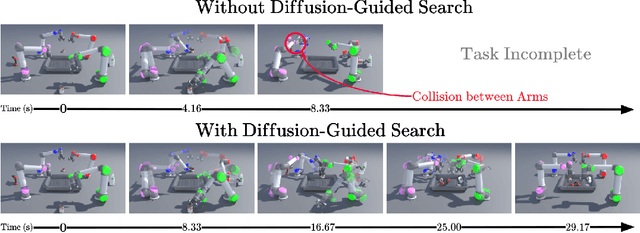
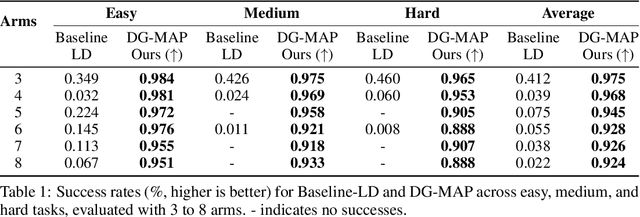
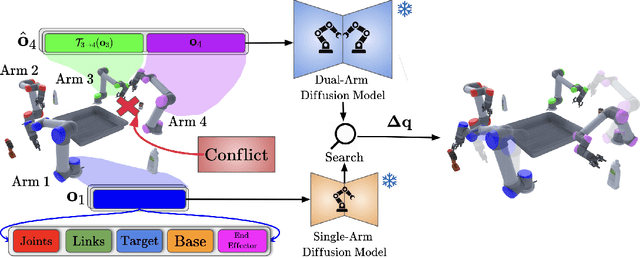
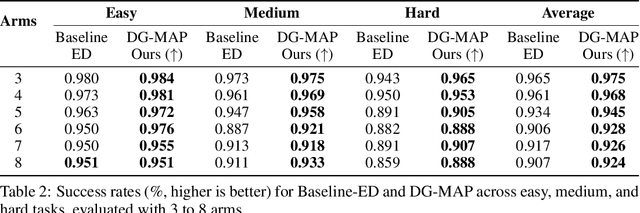
Multi-arm motion planning is fundamental for enabling arms to complete complex long-horizon tasks in shared spaces efficiently but current methods struggle with scalability due to exponential state-space growth and reliance on large training datasets for learned models. Inspired by Multi-Agent Path Finding (MAPF), which decomposes planning into single-agent problems coupled with collision resolution, we propose a novel diffusion-guided multi-arm planner (DG-MAP) that enhances scalability of learning-based models while reducing their reliance on massive multi-arm datasets. Recognizing that collisions are primarily pairwise, we train two conditional diffusion models, one to generate feasible single-arm trajectories, and a second, to model the dual-arm dynamics required for effective pairwise collision resolution. By integrating these specialized generative models within a MAPF-inspired structured decomposition, our planner efficiently scales to larger number of arms. Evaluations against alternative learning-based methods across various team sizes demonstrate our method's effectiveness and practical applicability. Project website can be found at https://diff-mapf-mers.csail.mit.edu
Safe Multi-Agent Navigation guided by Goal-Conditioned Safe Reinforcement Learning
Feb 25, 2025Safe navigation is essential for autonomous systems operating in hazardous environments. Traditional planning methods excel at long-horizon tasks but rely on a predefined graph with fixed distance metrics. In contrast, safe Reinforcement Learning (RL) can learn complex behaviors without relying on manual heuristics but fails to solve long-horizon tasks, particularly in goal-conditioned and multi-agent scenarios. In this paper, we introduce a novel method that integrates the strengths of both planning and safe RL. Our method leverages goal-conditioned RL and safe RL to learn a goal-conditioned policy for navigation while concurrently estimating cumulative distance and safety levels using learned value functions via an automated self-training algorithm. By constructing a graph with states from the replay buffer, our method prunes unsafe edges and generates a waypoint-based plan that the agent follows until reaching its goal, effectively balancing faster and safer routes over extended distances. Utilizing this unified high-level graph and a shared low-level goal-conditioned safe RL policy, we extend this approach to address the multi-agent safe navigation problem. In particular, we leverage Conflict-Based Search (CBS) to create waypoint-based plans for multiple agents allowing for their safe navigation over extended horizons. This integration enhances the scalability of goal-conditioned safe RL in multi-agent scenarios, enabling efficient coordination among agents. Extensive benchmarking against state-of-the-art baselines demonstrates the effectiveness of our method in achieving distance goals safely for multiple agents in complex and hazardous environments. Our code will be released to support future research.