 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Restoration
Image restoration is the process of improving the quality of an image by removing noise, blurring, or other distortions.
Papers and Code
NAUTILUS: A Large Multimodal Model for Underwater Scene Understanding
Oct 31, 2025Underwater exploration offers critical insights into our planet and attracts increasing attention for its broader applications in resource exploration, national security, etc. We study the underwater scene understanding methods, which aim to achieve automated underwater exploration. The underwater scene understanding task demands multi-task perceptions from multiple granularities. However, the absence of large-scale underwater multi-task instruction-tuning datasets hinders the progress of this research. To bridge this gap, we construct NautData, a dataset containing 1.45 M image-text pairs supporting eight underwater scene understanding tasks. It enables the development and thorough evaluation of the underwater scene understanding models. Underwater image degradation is a widely recognized challenge that interferes with underwater tasks. To improve the robustness of underwater scene understanding, we introduce physical priors derived from underwater imaging models and propose a plug-and-play vision feature enhancement (VFE) module, which explicitly restores clear underwater information. We integrate this module into renowned baselines LLaVA-1.5 and Qwen2.5-VL and build our underwater LMM, NAUTILUS. Experiments conducted on the NautData and public underwater datasets demonstrate the effectiveness of the VFE module, consistently improving the performance of both baselines on the majority of supported tasks, thus ensuring the superiority of NAUTILUS in the underwater scene understanding area. Data and models are available at https://github.com/H-EmbodVis/NAUTILUS.
RoGER-SLAM: A Robust Gaussian Splatting SLAM System for Noisy and Low-light Environment Resilience
Oct 26, 2025The reliability of Simultaneous Localization and Mapping (SLAM) is severely constrained in environments where visual inputs suffer from noise and low illumination. Although recent 3D Gaussian Splatting (3DGS) based SLAM frameworks achieve high-fidelity mapping under clean conditions, they remain vulnerable to compounded degradations that degrade mapping and tracking performance. A key observation underlying our work is that the original 3DGS rendering pipeline inherently behaves as an implicit low-pass filter, attenuating high-frequency noise but also risking over-smoothing. Building on this insight, we propose RoGER-SLAM, a robust 3DGS SLAM system tailored for noise and low-light resilience. The framework integrates three innovations: a Structure-Preserving Robust Fusion (SP-RoFusion) mechanism that couples rendered appearance, depth, and edge cues; an adaptive tracking objective with residual balancing regularization; and a Contrastive Language-Image Pretraining (CLIP)-based enhancement module, selectively activated under compounded degradations to restore semantic and structural fidelity. Comprehensive experiments on Replica, TUM, and real-world sequences show that RoGER-SLAM consistently improves trajectory accuracy and reconstruction quality compared with other 3DGS-SLAM systems, especially under adverse imaging conditions.
FideDiff: Efficient Diffusion Model for High-Fidelity Image Motion Deblurring
Oct 02, 2025



Recent advancements in image motion deblurring, driven by CNNs and transformers, have made significant progress. Large-scale pre-trained diffusion models, which are rich in true-world modeling, have shown great promise for high-quality image restoration tasks such as deblurring, demonstrating stronger generative capabilities than CNN and transformer-based methods. However, challenges such as unbearable inference time and compromised fidelity still limit the full potential of the diffusion models. To address this, we introduce FideDiff, a novel single-step diffusion model designed for high-fidelity deblurring. We reformulate motion deblurring as a diffusion-like process where each timestep represents a progressively blurred image, and we train a consistency model that aligns all timesteps to the same clean image. By reconstructing training data with matched blur trajectories, the model learns temporal consistency, enabling accurate one-step deblurring. We further enhance model performance by integrating Kernel ControlNet for blur kernel estimation and introducing adaptive timestep prediction. Our model achieves superior performance on full-reference metrics, surpassing previous diffusion-based methods and matching the performance of other state-of-the-art models. FideDiff offers a new direction for applying pre-trained diffusion models to high-fidelity image restoration tasks, establishing a robust baseline for further advancing diffusion models in real-world industrial applications. Our dataset and code will be available at https://github.com/xyLiu339/FideDiff.
D-GAP: Improving Out-of-Domain Robustness via Dataset-Agnostic and Gradient-Guided Augmentation in Amplitude and Pixel Spaces
Nov 14, 2025Out-of-domain (OOD) robustness is challenging to achieve in real-world computer vision applications, where shifts in image background, style, and acquisition instruments always degrade model performance. Generic augmentations show inconsistent gains under such shifts, whereas dataset-specific augmentations require expert knowledge and prior analysis. Moreover, prior studies show that neural networks adapt poorly to domain shifts because they exhibit a learning bias to domain-specific frequency components. Perturbing frequency values can mitigate such bias but overlooks pixel-level details, leading to suboptimal performance. To address these problems, we propose D-GAP (Dataset-agnostic and Gradient-guided augmentation in Amplitude and Pixel spaces), improving OOD robustness by introducing targeted augmentation in both the amplitude space (frequency space) and pixel space. Unlike conventional handcrafted augmentations, D-GAP computes sensitivity maps in the frequency space from task gradients, which reflect how strongly the model responds to different frequency components, and uses the maps to adaptively interpolate amplitudes between source and target samples. This way, D-GAP reduces the learning bias in frequency space, while a complementary pixel-space blending procedure restores fine spatial details. Extensive experiments on four real-world datasets and three domain-adaptation benchmarks show that D-GAP consistently outperforms both generic and dataset-specific augmentations, improving average OOD performance by +5.3% on real-world datasets and +1.8% on benchmark datasets.
A Geometric Unification of Generative AI with Manifold-Probabilistic Projection Models
Oct 01, 2025The foundational premise of generative AI for images is the assumption that images are inherently low-dimensional objects embedded within a high-dimensional space. Additionally, it is often implicitly assumed that thematic image datasets form smooth or piecewise smooth manifolds. Common approaches overlook the geometric structure and focus solely on probabilistic methods, approximating the probability distribution through universal approximation techniques such as the kernel method. In some generative models, the low dimensional nature of the data manifest itself by the introduction of a lower dimensional latent space. Yet, the probability distribution in the latent or the manifold coordinate space is considered uninteresting and is predefined or considered uniform. This study unifies the geometric and probabilistic perspectives by providing a geometric framework and a kernel-based probabilistic method simultaneously. The resulting framework demystifies diffusion models by interpreting them as a projection mechanism onto the manifold of ``good images''. This interpretation leads to the construction of a new deterministic model, the Manifold-Probabilistic Projection Model (MPPM), which operates in both the representation (pixel) space and the latent space. We demonstrate that the Latent MPPM (LMPPM) outperforms the Latent Diffusion Model (LDM) across various datasets, achieving superior results in terms of image restoration and generation.
Efficient Real-World Deblurring using Single Images: AIM 2025 Challenge Report
Oct 14, 2025This paper reviews the AIM 2025 Efficient Real-World Deblurring using Single Images Challenge, which aims to advance in efficient real-blur restoration. The challenge is based on a new test set based on the well known RSBlur dataset. Pairs of blur and degraded images in this dataset are captured using a double-camera system. Participant were tasked with developing solutions to effectively deblur these type of images while fulfilling strict efficiency constraints: fewer than 5 million model parameters and a computational budget under 200 GMACs. A total of 71 participants registered, with 4 teams finally submitting valid solutions. The top-performing approach achieved a PSNR of 31.1298 dB, showcasing the potential of efficient methods in this domain. This paper provides a comprehensive overview of the challenge, compares the proposed solutions, and serves as a valuable reference for researchers in efficient real-world image deblurring.
BIR-Adapter: A Low-Complexity Diffusion Model Adapter for Blind Image Restoration
Sep 08, 2025This paper introduces BIR-Adapter, a low-complexity blind image restoration adapter for diffusion models. The BIR-Adapter enables the utilization of the prior of pre-trained large-scale diffusion models on blind image restoration without training any auxiliary feature extractor. We take advantage of the robustness of pretrained models. We extract features from degraded images via the model itself and extend the self-attention mechanism with these degraded features. We introduce a sampling guidance mechanism to reduce hallucinations. We perform experiments on synthetic and real-world degradations and demonstrate that BIR-Adapter achieves competitive or better performance compared to state-of-the-art methods while having significantly lower complexity. Additionally, its adapter-based design enables integration into other diffusion models, enabling broader applications in image restoration tasks. We showcase this by extending a super-resolution-only model to perform better under additional unknown degradations.
UniVerse: Unleashing the Scene Prior of Video Diffusion Models for Robust Radiance Field Reconstruction
Oct 02, 2025
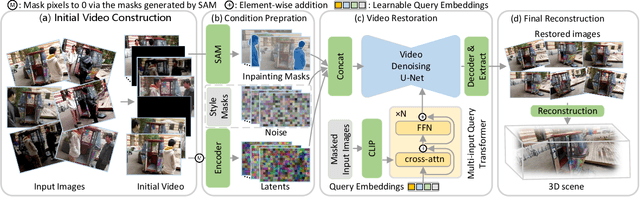
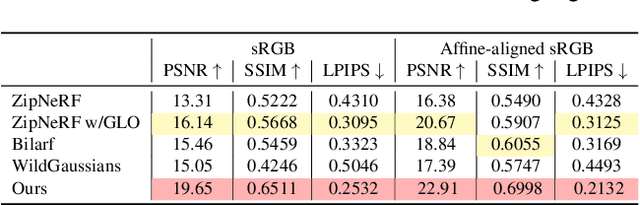

This paper tackles the challenge of robust reconstruction, i.e., the task of reconstructing a 3D scene from a set of inconsistent multi-view images. Some recent works have attempted to simultaneously remove image inconsistencies and perform reconstruction by integrating image degradation modeling into neural 3D scene representations.However, these methods rely heavily on dense observations for robustly optimizing model parameters.To address this issue, we propose to decouple robust reconstruction into two subtasks: restoration and reconstruction, which naturally simplifies the optimization process.To this end, we introduce UniVerse, a unified framework for robust reconstruction based on a video diffusion model. Specifically, UniVerse first converts inconsistent images into initial videos, then uses a specially designed video diffusion model to restore them into consistent images, and finally reconstructs the 3D scenes from these restored images.Compared with case-by-case per-view degradation modeling, the diffusion model learns a general scene prior from large-scale data, making it applicable to diverse image inconsistencies.Extensive experiments on both synthetic and real-world datasets demonstrate the strong generalization capability and superior performance of our method in robust reconstruction. Moreover, UniVerse can control the style of the reconstructed 3D scene. Project page: https://jin-cao-tma.github.io/UniVerse.github.io/
Hebrew Diacritics Restoration using Visual Representation
Oct 30, 2025Diacritics restoration in Hebrew is a fundamental task for ensuring accurate word pronunciation and disambiguating textual meaning. Despite the language's high degree of ambiguity when unvocalized, recent machine learning approaches have significantly advanced performance on this task. In this work, we present DIVRIT, a novel system for Hebrew diacritization that frames the task as a zero-shot classification problem. Our approach operates at the word level, selecting the most appropriate diacritization pattern for each undiacritized word from a dynamically generated candidate set, conditioned on the surrounding textual context. A key innovation of DIVRIT is its use of a Hebrew Visual Language Model, which processes undiacritized text as an image, allowing diacritic information to be embedded directly within the input's vector representation. Through a comprehensive evaluation across various configurations, we demonstrate that the system effectively performs diacritization without relying on complex, explicit linguistic analysis. Notably, in an ``oracle'' setting where the correct diacritized form is guaranteed to be among the provided candidates, DIVRIT achieves a high level of accuracy. Furthermore, strategic architectural enhancements and optimized training methodologies yield significant improvements in the system's overall generalization capabilities. These findings highlight the promising potential of visual representations for accurate and automated Hebrew diacritization.
GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.