 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue State Tracking
Dialogue state tracking consists of determining at each turn of a dialogue the full representation of what the user wants at that point in the dialogue, which contains a goal constraint, a set of requested slots, and the user's dialogue act.
Papers and Code
MoNET: Tackle State Momentum via Noise-Enhanced Training for Dialogue State Tracking
Nov 11, 2022



Dialogue state tracking (DST) aims to convert the dialogue history into dialogue states which consist of slot-value pairs. As condensed structural information memorizing all history information, the dialogue state in the last turn is typically adopted as the input for predicting the current state by DST models. However, these models tend to keep the predicted slot values unchanged, which is defined as state momentum in this paper. Specifically, the models struggle to update slot values that need to be changed and correct wrongly predicted slot values in the last turn. To this end, we propose MoNET to tackle state momentum via noise-enhanced training. First, the previous state of each turn in the training data is noised via replacing some of its slot values. Then, the noised previous state is used as the input to learn to predict the current state, improving the model's ability to update and correct slot values. Furthermore, a contrastive context matching framework is designed to narrow the representation distance between a state and its corresponding noised variant, which reduces the impact of noised state and makes the model better understand the dialogue history. Experimental results on MultiWOZ datasets show that MoNET outperforms previous DST methods. Ablations and analysis verify the effectiveness of MoNET in alleviating state momentum and improving anti-noise ability.
DiSTRICT: Dialogue State Tracking with Retriever Driven In-Context Tuning
Dec 06, 2022Dialogue State Tracking (DST), a key component of task-oriented conversation systems, represents user intentions by determining the values of pre-defined slots in an ongoing dialogue. Existing approaches use hand-crafted templates and additional slot information to fine-tune and prompt large pre-trained language models and elicit slot values from the dialogue context. Significant manual effort and domain knowledge is required to design effective prompts, limiting the generalizability of these approaches to new domains and tasks. In this work, we propose DiSTRICT, a generalizable in-context tuning approach for DST that retrieves highly relevant training examples for a given dialogue to fine-tune the model without any hand-crafted templates. Experiments with the MultiWOZ benchmark datasets show that DiSTRICT outperforms existing approaches in various zero-shot and few-shot settings using a much smaller model, thereby providing an important advantage for real-world deployments that often have limited resource availability.
Leveraging Explicit Procedural Instructions for Data-Efficient Action Prediction
Jun 06, 2023Task-oriented dialogues often require agents to enact complex, multi-step procedures in order to meet user requests. While large language models have found success automating these dialogues in constrained environments, their widespread deployment is limited by the substantial quantities of task-specific data required for training. The following paper presents a data-efficient solution to constructing dialogue systems, leveraging explicit instructions derived from agent guidelines, such as company policies or customer service manuals. Our proposed Knowledge-Augmented Dialogue System (KADS) combines a large language model with a knowledge retrieval module that pulls documents outlining relevant procedures from a predefined set of policies, given a user-agent interaction. To train this system, we introduce a semi-supervised pre-training scheme that employs dialogue-document matching and action-oriented masked language modeling with partial parameter freezing. We evaluate the effectiveness of our approach on prominent task-oriented dialogue datasets, Action-Based Conversations Dataset and Schema-Guided Dialogue, for two dialogue tasks: action state tracking and workflow discovery. Our results demonstrate that procedural knowledge augmentation improves accuracy predicting in- and out-of-distribution actions while preserving high performance in settings with low or sparse data.
Simple LLM Prompting is State-of-the-Art for Robust and Multilingual Dialogue Evaluation
Sep 08, 2023



Despite significant research effort in the development of automatic dialogue evaluation metrics, little thought is given to evaluating dialogues other than in English. At the same time, ensuring metrics are invariant to semantically similar responses is also an overlooked topic. In order to achieve the desired properties of robustness and multilinguality for dialogue evaluation metrics, we propose a novel framework that takes advantage of the strengths of current evaluation models with the newly-established paradigm of prompting Large Language Models (LLMs). Empirical results show our framework achieves state of the art results in terms of mean Spearman correlation scores across several benchmarks and ranks first place on both the Robust and Multilingual tasks of the DSTC11 Track 4 "Automatic Evaluation Metrics for Open-Domain Dialogue Systems", proving the evaluation capabilities of prompted LLMs.
SF-DST: Few-Shot Self-Feeding Reading Comprehension Dialogue State Tracking with Auxiliary Task
Sep 16, 2022
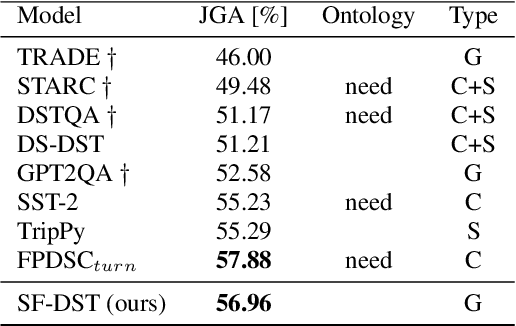


Few-shot dialogue state tracking (DST) model tracks user requests in dialogue with reliable accuracy even with a small amount of data. In this paper, we introduce an ontology-free few-shot DST with self-feeding belief state input. The self-feeding belief state input increases the accuracy in multi-turn dialogue by summarizing previous dialogue. Also, we newly developed a slot-gate auxiliary task. This new auxiliary task helps classify whether a slot is mentioned in the dialogue. Our model achieved the best score in a few-shot setting for four domains on multiWOZ 2.0.
Are LLMs All You Need for Task-Oriented Dialogue?
Apr 13, 2023



Instructions-tuned Large Language Models (LLMs) gained recently huge popularity thanks to their ability to interact with users through conversation. In this work we aim to evaluate their ability to complete multi-turn tasks and interact with external databases in the context of established task-oriented dialogue benchmarks. We show that for explicit belief state tracking, LLMs underperform compared to specialized task-specific models. Nevertheless, they show ability to guide the dialogue to successful ending if given correct slot values. Furthermore this ability improves with access to true belief state distribution or in-domain examples.
CSS: Combining Self-training and Self-supervised Learning for Few-shot Dialogue State Tracking
Oct 11, 2022
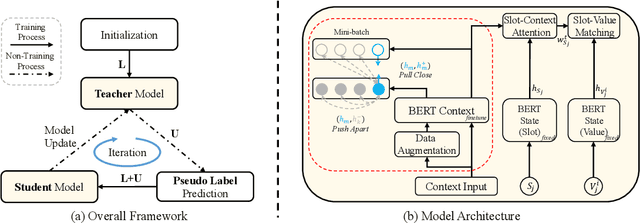
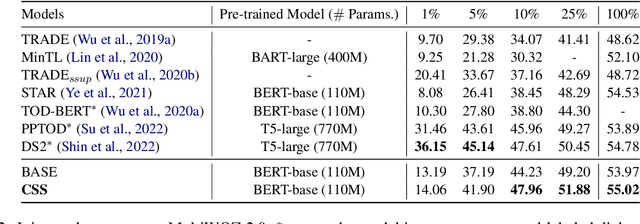
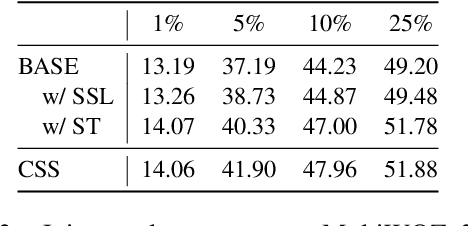
Few-shot dialogue state tracking (DST) is a realistic problem that trains the DST model with limited labeled data. Existing few-shot methods mainly transfer knowledge learned from external labeled dialogue data (e.g., from question answering, dialogue summarization, machine reading comprehension tasks, etc.) into DST, whereas collecting a large amount of external labeled data is laborious, and the external data may not effectively contribute to the DST-specific task. In this paper, we propose a few-shot DST framework called CSS, which Combines Self-training and Self-supervised learning methods. The unlabeled data of the DST task is incorporated into the self-training iterations, where the pseudo labels are predicted by a DST model trained on limited labeled data in advance. Besides, a contrastive self-supervised method is used to learn better representations, where the data is augmented by the dropout operation to train the model. Experimental results on the MultiWOZ dataset show that our proposed CSS achieves competitive performance in several few-shot scenarios.
Zero and Few-Shot Localization of Task-Oriented Dialogue Agents with a Distilled Representation
Feb 18, 2023Task-oriented Dialogue (ToD) agents are mostly limited to a few widely-spoken languages, mainly due to the high cost of acquiring training data for each language. Existing low-cost approaches that rely on cross-lingual embeddings or naive machine translation sacrifice a lot of accuracy for data efficiency, and largely fail in creating a usable dialogue agent. We propose automatic methods that use ToD training data in a source language to build a high-quality functioning dialogue agent in another target language that has no training data (i.e. zero-shot) or a small training set (i.e. few-shot). Unlike most prior work in cross-lingual ToD that only focuses on Dialogue State Tracking (DST), we build an end-to-end agent. We show that our approach closes the accuracy gap between few-shot and existing full-shot methods for ToD agents. We achieve this by (1) improving the dialogue data representation, (2) improving entity-aware machine translation, and (3) automatic filtering of noisy translations. We evaluate our approach on the recent bilingual dialogue dataset BiToD. In Chinese to English transfer, in the zero-shot setting, our method achieves 46.7% and 22.0% in Task Success Rate (TSR) and Dialogue Success Rate (DSR) respectively. In the few-shot setting where 10% of the data in the target language is used, we improve the state-of-the-art by 15.2% and 14.0%, coming within 5% of full-shot training.
Act-Aware Slot-Value Predicting in Multi-Domain Dialogue State Tracking
Aug 04, 2022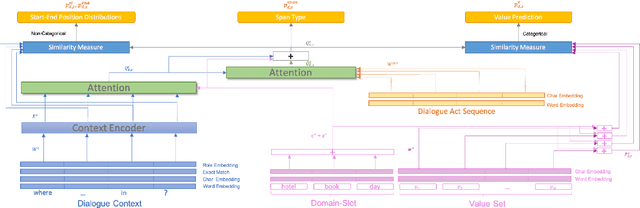
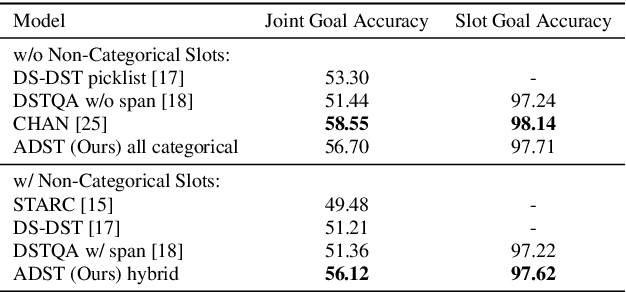
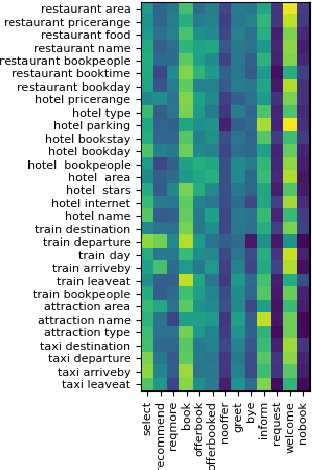
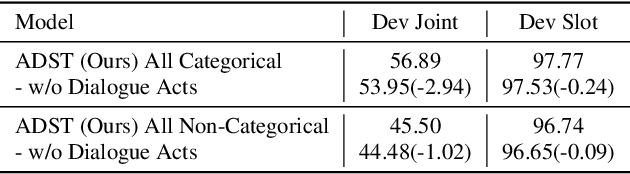
As an essential component in task-oriented dialogue systems, dialogue state tracking (DST) aims to track human-machine interactions and generate state representations for managing the dialogue. Representations of dialogue states are dependent on the domain ontology and the user's goals. In several task-oriented dialogues with a limited scope of objectives, dialogue states can be represented as a set of slot-value pairs. As the capabilities of dialogue systems expand to support increasing naturalness in communication, incorporating dialogue act processing into dialogue model design becomes essential. The lack of such consideration limits the scalability of dialogue state tracking models for dialogues having specific objectives and ontology. To address this issue, we formulate and incorporate dialogue acts, and leverage recent advances in machine reading comprehension to predict both categorical and non-categorical types of slots for multi-domain dialogue state tracking. Experimental results show that our models can improve the overall accuracy of dialogue state tracking on the MultiWOZ 2.1 dataset, and demonstrate that incorporating dialogue acts can guide dialogue state design for future task-oriented dialogue systems.
* Published in Spoken Dialogue Systems I, Interspeech 2021. Code is now publicly available on Github: https://github.com/youlandasu/ACT-AWARE-DST
Controllable User Dialogue Act Augmentation for Dialogue State Tracking
Jul 26, 2022
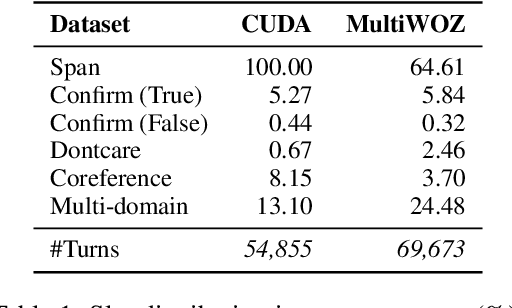
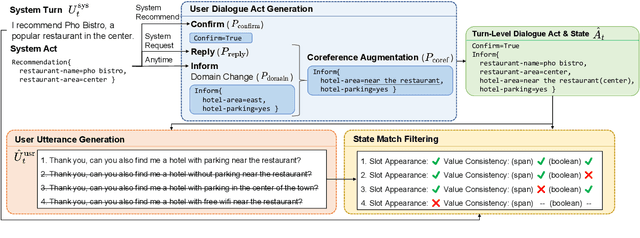
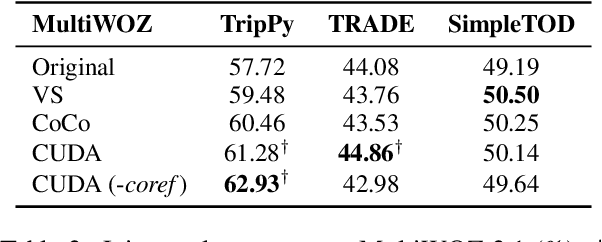
Prior work has demonstrated that data augmentation is useful for improving dialogue state tracking. However, there are many types of user utterances, while the prior method only considered the simplest one for augmentation, raising the concern about poor generalization capability. In order to better cover diverse dialogue acts and control the generation quality, this paper proposes controllable user dialogue act augmentation (CUDA-DST) to augment user utterances with diverse behaviors. With the augmented data, different state trackers gain improvement and show better robustness, achieving the state-of-the-art performance on MultiWOZ 2.1