 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark of (MRI-) Foundation Models to Predict IDH Mutational Status in Glioma
Jun 22, 2026Non-invasive prediction of glioma molecular status from routine magnetic resonance imaging (MRI) has shown promising performance, but model generalization remains challenging given small-scale matched imaging-genomic datasets. Foundation models may address this bottleneck, but a comprehensive benchmark is needed to establish the impact of diverse architectures, pre-training domains, and objectives. Given the use case of isocitrate dehydrogenase (IDH) mutation prediction from FLAIR and post-contrast T1 MRIs, we compared four image-based foundation models, BrainIAC, MRI-CORE, BiomedCLIP, and BrainDINO, against radiomics-based TabPFN and logistic regression baselines. Prediction performance and calibration were assessed across four public adult glioma cohorts and an external post-treatment cohort. Within-cohort, TabPFN matched or outperformed all visual encoders, achieving 0.92 (0.03) AUROC and 0.74 (0.17) AUPRC (mean (SD) across all datasets). Among visual encoders, BiomedCLIP performed best (0.85 (0.08) AUROC), with BrainDINO competitive (0.82 (0.09) AUROC), while MRI-specific encoders (BrainIAC, MRI-CORE) consistently underperformed. Cross-cohort transfer showed moderate AUROC degradation but stronger AUPRC sensitivity to prevalence shifts. On the external cohort, BiomedCLIP achieved the highest AUROC (0.74 (0.07)), whereas TabPFN provided superior calibration (Expected Calibration Error 0.07 (0.01)). These results indicate that representation modality and evaluation context critically influence foundation-model performance in MRI-based molecular prediction. Tabular foundation models on radiomic features provide a strong, well-calibrated baseline, while image foundation models may offer complementary value under clinically distinct distribution shifts. Code available at https://github.com/nathanhollet/idh-status-prediction
Mechanistic Learning with Guided Diffusion Models to Predict Spatio-Temporal Brain Tumor Growth
Sep 11, 2025



Predicting the spatio-temporal progression of brain tumors is essential for guiding clinical decisions in neuro-oncology. We propose a hybrid mechanistic learning framework that combines a mathematical tumor growth model with a guided denoising diffusion implicit model (DDIM) to synthesize anatomically feasible future MRIs from preceding scans. The mechanistic model, formulated as a system of ordinary differential equations, captures temporal tumor dynamics including radiotherapy effects and estimates future tumor burden. These estimates condition a gradient-guided DDIM, enabling image synthesis that aligns with both predicted growth and patient anatomy. We train our model on the BraTS adult and pediatric glioma datasets and evaluate on 60 axial slices of in-house longitudinal pediatric diffuse midline glioma (DMG) cases. Our framework generates realistic follow-up scans based on spatial similarity metrics. It also introduces tumor growth probability maps, which capture both clinically relevant extent and directionality of tumor growth as shown by 95th percentile Hausdorff Distance. The method enables biologically informed image generation in data-limited scenarios, offering generative-space-time predictions that account for mechanistic priors.
Masked Diffusion Language Models with Frequency-Informed Training
Sep 05, 2025We present a masked diffusion language modeling framework for data-efficient training for the BabyLM 2025 Challenge. Our approach applies diffusion training objectives to language modeling under strict data constraints, incorporating frequency-informed masking that prioritizes learning from rare tokens while maintaining theoretical validity. We explore multiple noise scheduling strategies, including two-mode approaches, and investigate different noise weighting schemes within the NELBO objective. We evaluate our method on the BabyLM benchmark suite, measuring linguistic competence, world knowledge, and human-likeness. Results show performance competitive to hybrid autoregressive-masked baselines, demonstrating that diffusion-based training offers a viable alternative for data-restricted language learning.
A Principled Framework for Multi-View Contrastive Learning
Jul 09, 2025Contrastive Learning (CL), a leading paradigm in Self-Supervised Learning (SSL), typically relies on pairs of data views generated through augmentation. While multiple augmentations per instance (more than two) improve generalization in supervised learning, current CL methods handle additional views suboptimally by simply aggregating different pairwise objectives. This approach suffers from four critical limitations: (L1) it utilizes multiple optimization terms per data point resulting to conflicting objectives, (L2) it fails to model all interactions across views and data points, (L3) it inherits fundamental limitations (e.g. alignment-uniformity coupling) from pairwise CL losses, and (L4) it prevents fully realizing the benefits of increased view multiplicity observed in supervised settings. We address these limitations through two novel loss functions: MV-InfoNCE, which extends InfoNCE to incorporate all possible view interactions simultaneously in one term per data point, and MV-DHEL, which decouples alignment from uniformity across views while scaling interaction complexity with view multiplicity. Both approaches are theoretically grounded - we prove they asymptotically optimize for alignment of all views and uniformity, providing principled extensions to multi-view contrastive learning. Our empirical results on ImageNet1K and three other datasets demonstrate that our methods consistently outperform existing multi-view approaches and effectively scale with increasing view multiplicity. We also apply our objectives to multimodal data and show that, in contrast to other contrastive objectives, they can scale beyond just two modalities. Most significantly, ablation studies reveal that MV-DHEL with five or more views effectively mitigates dimensionality collapse by fully utilizing the embedding space, thereby delivering multi-view benefits observed in supervised learning.
MEDUSA: A Multimodal Deep Fusion Multi-Stage Training Framework for Speech Emotion Recognition in Naturalistic Conditions
Jun 11, 2025SER is a challenging task due to the subjective nature of human emotions and their uneven representation under naturalistic conditions. We propose MEDUSA, a multimodal framework with a four-stage training pipeline, which effectively handles class imbalance and emotion ambiguity. The first two stages train an ensemble of classifiers that utilize DeepSER, a novel extension of a deep cross-modal transformer fusion mechanism from pretrained self-supervised acoustic and linguistic representations. Manifold MixUp is employed for further regularization. The last two stages optimize a trainable meta-classifier that combines the ensemble predictions. Our training approach incorporates human annotation scores as soft targets, coupled with balanced data sampling and multitask learning. MEDUSA ranked 1st in Task 1: Categorical Emotion Recognition in the Interspeech 2025: Speech Emotion Recognition in Naturalistic Conditions Challenge.
DeepMLF: Multimodal language model with learnable tokens for deep fusion in sentiment analysis
Apr 15, 2025While multimodal fusion has been extensively studied in Multimodal Sentiment Analysis (MSA), the role of fusion depth and multimodal capacity allocation remains underexplored. In this work, we position fusion depth, scalability, and dedicated multimodal capacity as primary factors for effective fusion. We introduce DeepMLF, a novel multimodal language model (LM) with learnable tokens tailored toward deep fusion. DeepMLF leverages an audiovisual encoder and a pretrained decoder LM augmented with multimodal information across its layers. We append learnable tokens to the LM that: 1) capture modality interactions in a controlled fashion and 2) preserve independent information flow for each modality. These fusion tokens gather linguistic information via causal self-attention in LM Blocks and integrate with audiovisual information through cross-attention MM Blocks. Serving as dedicated multimodal capacity, this design enables progressive fusion across multiple layers, providing depth in the fusion process. Our training recipe combines modality-specific losses and language modelling loss, with the decoder LM tasked to predict ground truth polarity. Across three MSA benchmarks with varying dataset characteristics, DeepMLF achieves state-of-the-art performance. Our results confirm that deeper fusion leads to better performance, with optimal fusion depths (5-7) exceeding those of existing approaches. Additionally, our analysis on the number of fusion tokens reveals that small token sets ($\sim$20) achieve optimal performance. We examine the importance of representation learning order (fusion curriculum) through audiovisual encoder initialization experiments. Our ablation studies demonstrate the superiority of the proposed fusion design and gating while providing a holistic examination of DeepMLF's scalability to LLMs, and the impact of each training objective and embedding regularization.
PowMix: A Versatile Regularizer for Multimodal Sentiment Analysis
Dec 19, 2023Multimodal sentiment analysis (MSA) leverages heterogeneous data sources to interpret the complex nature of human sentiments. Despite significant progress in multimodal architecture design, the field lacks comprehensive regularization methods. This paper introduces PowMix, a versatile embedding space regularizer that builds upon the strengths of unimodal mixing-based regularization approaches and introduces novel algorithmic components that are specifically tailored to multimodal tasks. PowMix is integrated before the fusion stage of multimodal architectures and facilitates intra-modal mixing, such as mixing text with text, to act as a regularizer. PowMix consists of five components: 1) a varying number of generated mixed examples, 2) mixing factor reweighting, 3) anisotropic mixing, 4) dynamic mixing, and 5) cross-modal label mixing. Extensive experimentation across benchmark MSA datasets and a broad spectrum of diverse architectural designs demonstrate the efficacy of PowMix, as evidenced by consistent performance improvements over baselines and existing mixing methods. An in-depth ablation study highlights the critical contribution of each PowMix component and how they synergistically enhance performance. Furthermore, algorithmic analysis demonstrates how PowMix behaves in different scenarios, particularly comparing early versus late fusion architectures. Notably, PowMix enhances overall performance without sacrificing model robustness or magnifying text dominance. It also retains its strong performance in situations of limited data. Our findings position PowMix as a promising versatile regularization strategy for MSA. Code will be made available.
SeqAug: Sequential Feature Resampling as a modality agnostic augmentation method
May 03, 2023



Data augmentation is a prevalent technique for improving performance in various machine learning applications. We propose SeqAug, a modality-agnostic augmentation method that is tailored towards sequences of extracted features. The core idea of SeqAug is to augment the sequence by resampling from the underlying feature distribution. Resampling is performed by randomly selecting feature dimensions and permuting them along the temporal axis. Experiments on CMU-MOSEI verify that SeqAug is modality agnostic; it can be successfully applied to a single modality or multiple modalities. We further verify its compatibility with both recurrent and transformer architectures, and also demonstrate comparable to state-of-the-art results.
Alternating Objectives Generates Stronger PGD-Based Adversarial Attacks
Dec 15, 2022



Designing powerful adversarial attacks is of paramount importance for the evaluation of $\ell_p$-bounded adversarial defenses. Projected Gradient Descent (PGD) is one of the most effective and conceptually simple algorithms to generate such adversaries. The search space of PGD is dictated by the steepest ascent directions of an objective. Despite the plethora of objective function choices, there is no universally superior option and robustness overestimation may arise from ill-suited objective selection. Driven by this observation, we postulate that the combination of different objectives through a simple loss alternating scheme renders PGD more robust towards design choices. We experimentally verify this assertion on a synthetic-data example and by evaluating our proposed method across 25 different $\ell_{\infty}$-robust models and 3 datasets. The performance improvement is consistent, when compared to the single loss counterparts. In the CIFAR-10 dataset, our strongest adversarial attack outperforms all of the white-box components of AutoAttack (AA) ensemble, as well as the most powerful attacks existing on the literature, achieving state-of-the-art results in the computational budget of our study ($T=100$, no restarts).
A Multi-Task BERT Model for Schema-Guided Dialogue State Tracking
Jul 02, 2022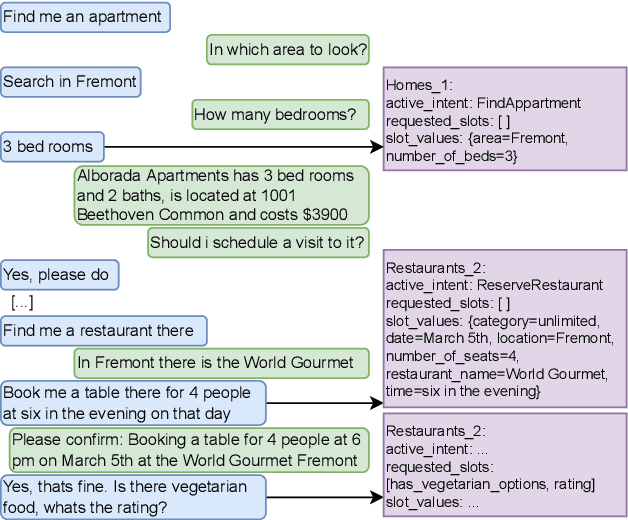
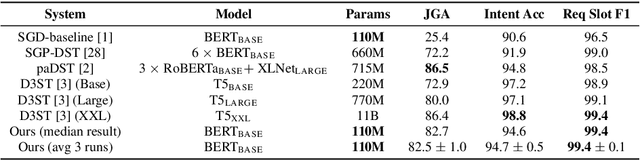
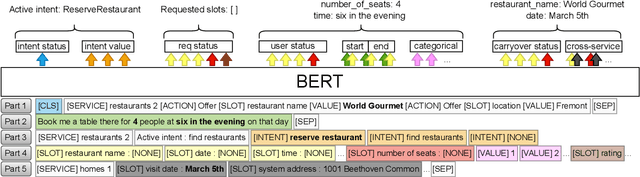
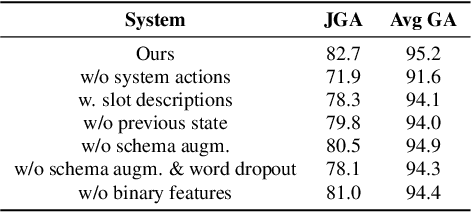
Task-oriented dialogue systems often employ a Dialogue State Tracker (DST) to successfully complete conversations. Recent state-of-the-art DST implementations rely on schemata of diverse services to improve model robustness and handle zero-shot generalization to new domains [1], however such methods [2, 3] typically require multiple large scale transformer models and long input sequences to perform well. We propose a single multi-task BERT-based model that jointly solves the three DST tasks of intent prediction, requested slot prediction and slot filling. Moreover, we propose an efficient and parsimonious encoding of the dialogue history and service schemata that is shown to further improve performance. Evaluation on the SGD dataset shows that our approach outperforms the baseline SGP-DST by a large margin and performs well compared to the state-of-the-art, while being significantly more computationally efficient. Extensive ablation studies are performed to examine the contributing factors to the success of our model.