 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgedriving status recognition
Papers and Code
The Judge Who Never Admits: Hidden Shortcuts in LLM-based Evaluation
Feb 08, 2026Large language models (LLMs) are increasingly used as automatic judges to evaluate system outputs in tasks such as reasoning, question answering, and creative writing. A faithful judge should base its verdicts solely on content quality, remain invariant to irrelevant context, and transparently reflect the factors driving its decisions. We test this ideal via controlled cue perturbations-synthetic metadata labels injected into evaluation prompts-for six judge models: GPT-4o, Gemini-2.0-Flash, Gemma-3-27B, Qwen3-235B, Claude-3-Haiku, and Llama3-70B. Experiments span two complementary datasets with distinct evaluation regimes: ELI5 (factual QA) and LitBench (open-ended creative writing). We study six cue families: source, temporal, age, gender, ethnicity, and educational status. Beyond measuring verdict shift rates (VSR), we introduce cue acknowledgment rate (CAR) to quantify whether judges explicitly reference the injected cues in their natural-language rationales. Across cues with strong behavioral effects-e.g., provenance hierarchies (Expert > Human > LLM > Unknown), recency preferences (New > Old), and educational-status favoritism-CAR is typically at or near zero, indicating that shortcut reliance is largely unreported even when it drives decisions. Crucially, CAR is also dataset-dependent: explicit cue recognition is more likely to surface in the factual ELI5 setting for some models and cues, but often collapses in the open-ended LitBench regime, where large verdict shifts can persist despite zero acknowledgment. The combination of substantial verdict sensitivity and limited cue acknowledgment reveals an explanation gap in LLM-as-judge pipelines, raising concerns about reliability of model-based evaluation in both research and deployment.
Visual Grounding from Event Cameras
Sep 11, 2025Event cameras capture changes in brightness with microsecond precision and remain reliable under motion blur and challenging illumination, offering clear advantages for modeling highly dynamic scenes. Yet, their integration with natural language understanding has received little attention, leaving a gap in multimodal perception. To address this, we introduce Talk2Event, the first large-scale benchmark for language-driven object grounding using event data. Built on real-world driving scenarios, Talk2Event comprises 5,567 scenes, 13,458 annotated objects, and more than 30,000 carefully validated referring expressions. Each expression is enriched with four structured attributes -- appearance, status, relation to the viewer, and relation to surrounding objects -- that explicitly capture spatial, temporal, and relational cues. This attribute-centric design supports interpretable and compositional grounding, enabling analysis that moves beyond simple object recognition to contextual reasoning in dynamic environments. We envision Talk2Event as a foundation for advancing multimodal and temporally-aware perception, with applications spanning robotics, human-AI interaction, and so on.
HausaNLP: Current Status, Challenges and Future Directions for Hausa Natural Language Processing
May 20, 2025Hausa Natural Language Processing (NLP) has gained increasing attention in recent years, yet remains understudied as a low-resource language despite having over 120 million first-language (L1) and 80 million second-language (L2) speakers worldwide. While significant advances have been made in high-resource languages, Hausa NLP faces persistent challenges, including limited open-source datasets and inadequate model representation. This paper presents an overview of the current state of Hausa NLP, systematically examining existing resources, research contributions, and gaps across fundamental NLP tasks: text classification, machine translation, named entity recognition, speech recognition, and question answering. We introduce HausaNLP (https://catalog.hausanlp.org), a curated catalog that aggregates datasets, tools, and research works to enhance accessibility and drive further development. Furthermore, we discuss challenges in integrating Hausa into large language models (LLMs), addressing issues of suboptimal tokenization and dialectal variation. Finally, we propose strategic research directions emphasizing dataset expansion, improved language modeling approaches, and strengthened community collaboration to advance Hausa NLP. Our work provides both a foundation for accelerating Hausa NLP progress and valuable insights for broader multilingual NLP research.
DriveGazen: Event-Based Driving Status Recognition using Conventional Camera
Dec 16, 2024



We introduce a wearable driving status recognition device and our open-source dataset, along with a new real-time method robust to changes in lighting conditions for identifying driving status from eye observations of drivers. The core of our method is generating event frames from conventional intensity frames, and the other is a newly designed Attention Driving State Network (ADSN). Compared to event cameras, conventional cameras offer complete information and lower hardware costs, enabling captured frames to encode rich spatial information. However, these textures lack temporal information, posing challenges in effectively identifying driving status. DriveGazen addresses this issue from three perspectives. First, we utilize video frames to generate realistic synthetic dynamic vision sensor (DVS) events. Second, we adopt a spiking neural network to decode pertinent temporal information. Lastly, ADSN extracts crucial spatial cues from corresponding intensity frames and conveys spatial attention to convolutional spiking layers during both training and inference through a novel guide attention module to guide the feature learning and feature enhancement of the event frame. We specifically collected the Driving Status (DriveGaze) dataset to demonstrate the effectiveness of our approach. Additionally, we validate the superiority of the DriveGazen on the Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first to utilize guide attention spiking neural networks and eye-based event frames generated from conventional cameras for driving status recognition. Please refer to our project page for more details: https://github.com/TooyoungALEX/AAAI25-DriveGazen.
A Unified Approach to Lane Change Intention Recognition and Driving Status Prediction through TCN-LSTM and Multi-Task Learning Models
Apr 25, 2023



Lane change (LC) is a continuous and complex operation process. Accurately detecting and predicting LC processes can help traffic participants better understand their surrounding environment, recognize potential LC safety hazards, and improve traffic safety. This present paper focuses on LC processes, developing an LC intention recognition (LC-IR) model and an LC status prediction (LC-SP) model. A novel ensemble temporal convolutional network with Long Short-Term Memory units (TCN-LSTM) is first proposed to capture long-range dependencies in sequential data. Then, three multi-task models (MTL-LSTM, MTL-TCN, MTL-TCN -LSTM) are developed to capture the intrinsic relationship among output indicators. Furthermore, a unified modeling framework for LC intention recognition and driving status prediction (LC-IR-SP) is developed. To validate the performance of the proposed models, a total number of 1023 vehicle trajectories is extracted from the CitySim dataset. The Pearson coefficient is employed to determine the related indicators. The results indicate that using150 frames as input length, the TCN-LSTM model with 96.67% accuracy outperforms TCN and LSTM models in LC intention classification and provides more balanced results for each class. Three proposed multi-tasking learning models provide markedly increased performance compared to corresponding single-task models, with an average reduction of 24.24% and 22.86% in the Mean Absolute Error (MAE) and Root Mean Square Error (RMSE), respectively. The developed LC-IR-SP model has promising applications for autonomous vehicles to identity lane change behaviors, calculate a real-time traffic conflict index and improve vehicle control strategies.
LightFormer: An End-to-End Model for Intersection Right-of-Way Recognition Using Traffic Light Signals and an Attention Mechanism
Jul 14, 2023For smart vehicles driving through signalised intersections, it is crucial to determine whether the vehicle has right of way given the state of the traffic lights. To address this issue, camera based sensors can be used to determine whether the vehicle has permission to proceed straight, turn left or turn right. This paper proposes a novel end to end intersection right of way recognition model called LightFormer to generate right of way status for available driving directions in complex urban intersections. The model includes a spatial temporal inner structure with an attention mechanism, which incorporates features from past image to contribute to the classification of the current frame right of way status. In addition, a modified, multi weight arcface loss is introduced to enhance the model classification performance. Finally, the proposed LightFormer is trained and tested on two public traffic light datasets with manually augmented labels to demonstrate its effectiveness.
Object Detection in Autonomous Vehicles: Status and Open Challenges
Jan 19, 2022Object detection is a computer vision task that has become an integral part of many consumer applications today such as surveillance and security systems, mobile text recognition, and diagnosing diseases from MRI/CT scans. Object detection is also one of the critical components to support autonomous driving. Autonomous vehicles rely on the perception of their surroundings to ensure safe and robust driving performance. This perception system uses object detection algorithms to accurately determine objects such as pedestrians, vehicles, traffic signs, and barriers in the vehicle's vicinity. Deep learning-based object detectors play a vital role in finding and localizing these objects in real-time. This article discusses the state-of-the-art in object detectors and open challenges for their integration into autonomous vehicles.
The Need and Status of Sea Turtle Conservation and Survey of Associated Computer Vision Advances
Jul 29, 2021



For over hundreds of millions of years, sea turtles and their ancestors have swum in the vast expanses of the ocean. They have undergone a number of evolutionary changes, leading to speciation and sub-speciation. However, in the past few decades, some of the most notable forces driving the genetic variance and population decline have been global warming and anthropogenic impact ranging from large-scale poaching, collecting turtle eggs for food, besides dumping trash including plastic waste into the ocean. This leads to severe detrimental effects in the sea turtle population, driving them to extinction. This research focusses on the forces causing the decline in sea turtle population, the necessity for the global conservation efforts along with its successes and failures, followed by an in-depth analysis of the modern advances in detection and recognition of sea turtles, involving Machine Learning and Computer Vision systems, aiding the conservation efforts.
Mining Personalized Climate Preferences for Assistant Driving
Jun 16, 2020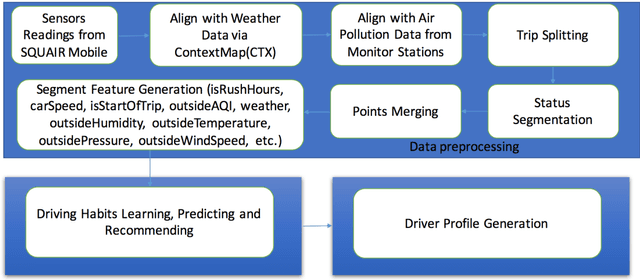
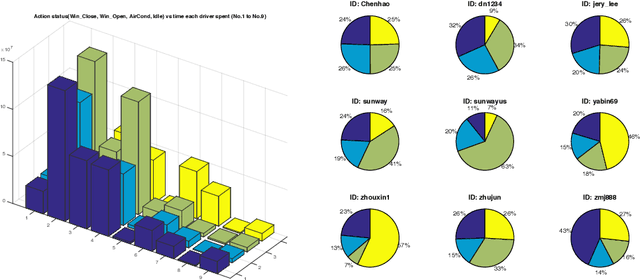
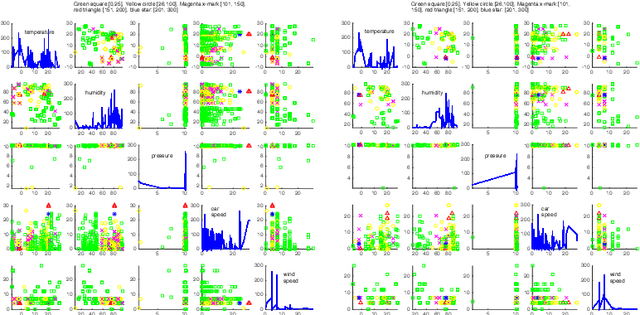
Both assistant driving and self-driving have attracted a great amount of attention in the last few years. However, the majority of research efforts focus on safe driving; few research has been conducted on in-vehicle climate control, or assistant driving based on travellers' personal habits or preferences. In this paper, we propose a novel approach for climate control, driver behavior recognition and driving recommendation for better fitting drivers' preferences in their daily driving. The algorithm consists three components: (1) A in-vehicle sensing and context feature enriching compnent with a Internet of Things (IoT) platform for collecting related environment, vehicle-running, and traffic parameters that affect drivers' behaviors. (2) A non-intrusive intelligent driver behaviour and vehicle status detection component, which can automatically label vehicle's status (open windows, turn on air condition, etc.), based on results of applying further feature extraction and machine learning algorithms. (3) A personalized driver habits learning and preference recommendation component for more healthy and comfortable experiences. A prototype using a client-server architecture with an iOS app and an air-quality monitoring sensor has been developed for collecting heterogeneous data and testing our algorithms. Real-world experiments on driving data of 11,370 km (320 hours) by different drivers in multiple cities worldwide have been conducted, which demonstrate the effective and accuracy of our approach.