 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWsj Benchmark
Papers and Code
Multi-channel multi-speaker transformer for speech recognition
Jan 06, 2026With the development of teleconferencing and in-vehicle voice assistants, far-field multi-speaker speech recognition has become a hot research topic. Recently, a multi-channel transformer (MCT) has been proposed, which demonstrates the ability of the transformer to model far-field acoustic environments. However, MCT cannot encode high-dimensional acoustic features for each speaker from mixed input audio because of the interference between speakers. Based on these, we propose the multi-channel multi-speaker transformer (M2Former) for far-field multi-speaker ASR in this paper. Experiments on the SMS-WSJ benchmark show that the M2Former outperforms the neural beamformer, MCT, dual-path RNN with transform-average-concatenate and multi-channel deep clustering based end-to-end systems by 9.2%, 14.3%, 24.9%, and 52.2% respectively, in terms of relative word error rate reduction.
* Proc. INTERSPEECH 2023, 5 pages
Deformable TDNN with adaptive receptive fields for speech recognition
Apr 30, 2021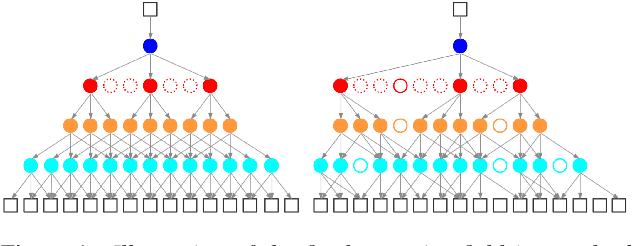
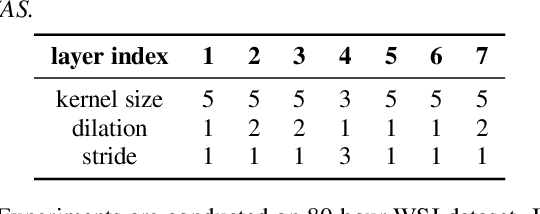
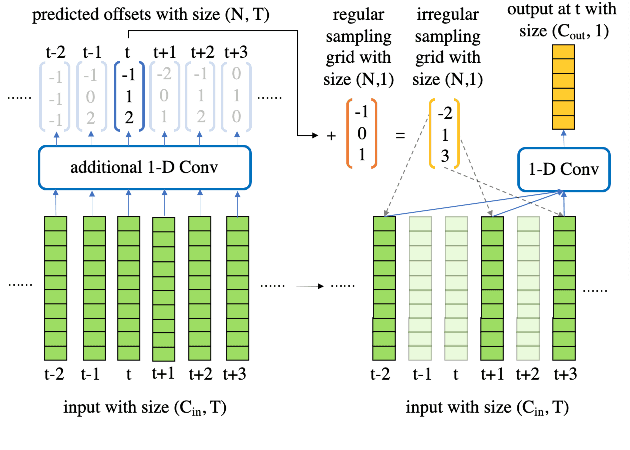
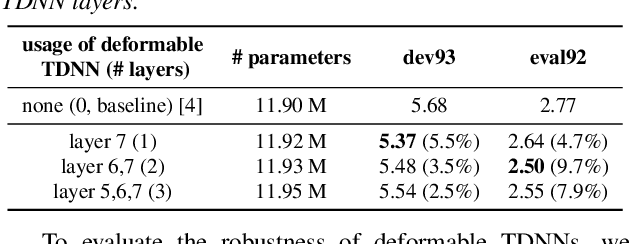
Time Delay Neural Networks (TDNNs) are widely used in both DNN-HMM based hybrid speech recognition systems and recent end-to-end systems. Nevertheless, the receptive fields of TDNNs are limited and fixed, which is not desirable for tasks like speech recognition, where the temporal dynamics of speech are varied and affected by many factors. This paper proposes to use deformable TDNNs for adaptive temporal dynamics modeling in end-to-end speech recognition. Inspired by deformable ConvNets, deformable TDNNs augment the temporal sampling locations with additional offsets and learn the offsets automatically based on the ASR criterion, without additional supervision. Experiments show that deformable TDNNs obtain state-of-the-art results on WSJ benchmarks (1.42\%/3.45\% WER on WSJ eval92/dev93 respectively), outperforming standard TDNNs significantly. Furthermore, we propose the latency control mechanism for deformable TDNNs, which enables deformable TDNNs to do streaming ASR without accuracy degradation.
FeaRLESS: Feature Refinement Loss for Ensembling Self-Supervised Learning Features in Robust End-to-end Speech Recognition
Jun 30, 2022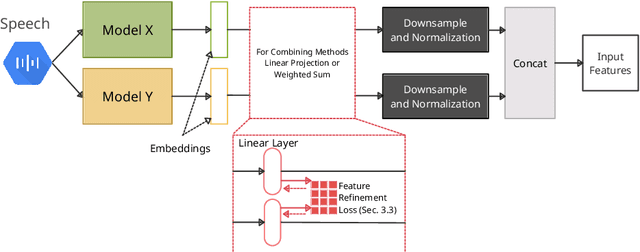
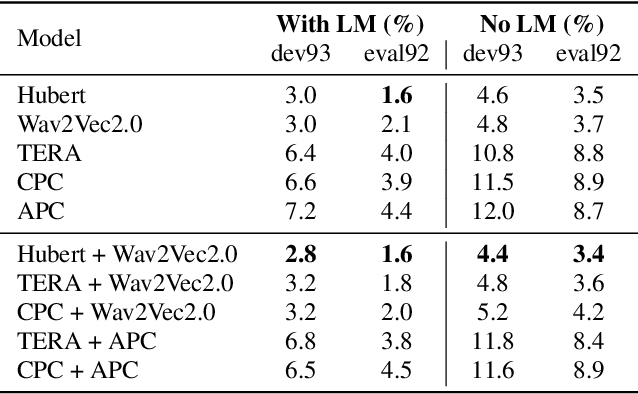
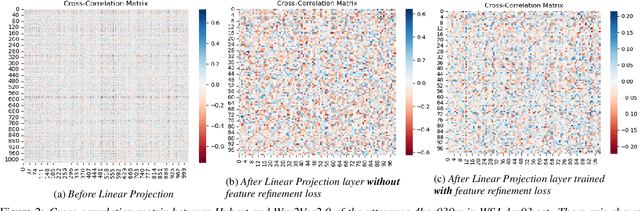
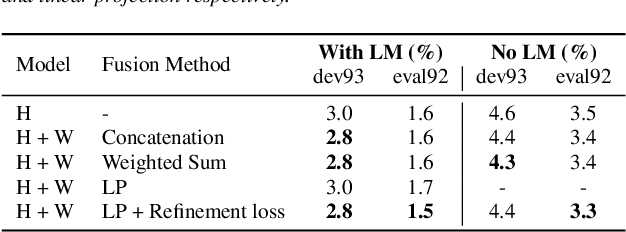
Self-supervised learning representations (SSLR) have resulted in robust features for downstream tasks in many fields. Recently, several SSLRs have shown promising results on automatic speech recognition (ASR) benchmark corpora. However, previous studies have only shown performance for solitary SSLRs as an input feature for ASR models. In this study, we propose to investigate the effectiveness of diverse SSLR combinations using various fusion methods within end-to-end (E2E) ASR models. In addition, we will show there are correlations between these extracted SSLRs. As such, we further propose a feature refinement loss for decorrelation to efficiently combine the set of input features. For evaluation, we show that the proposed 'FeaRLESS learning features' perform better than systems without the proposed feature refinement loss for both the WSJ and Fearless Steps Challenge (FSC) corpora.
Rule Augmented Unsupervised Constituency Parsing
May 21, 2021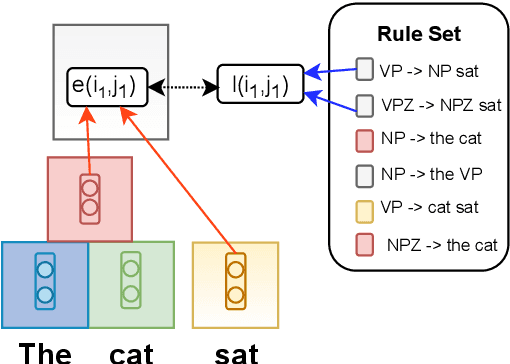
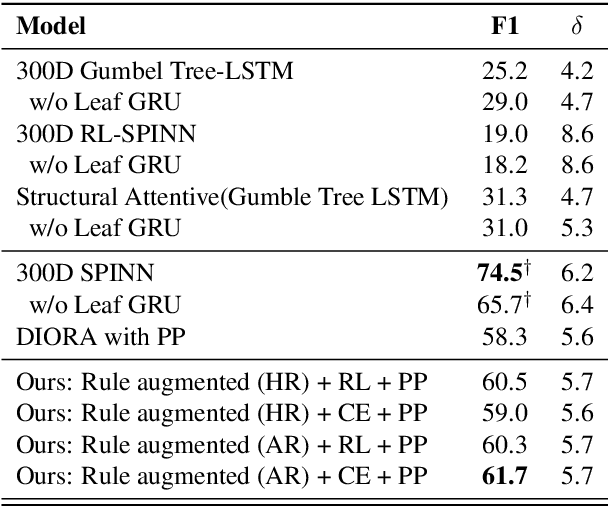
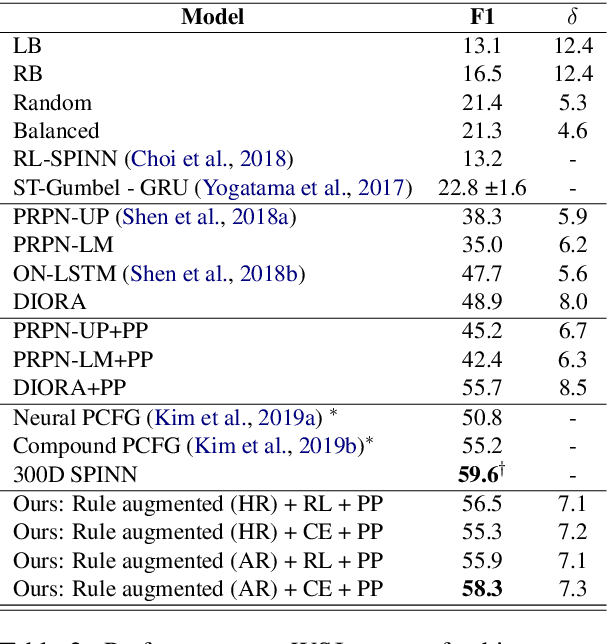
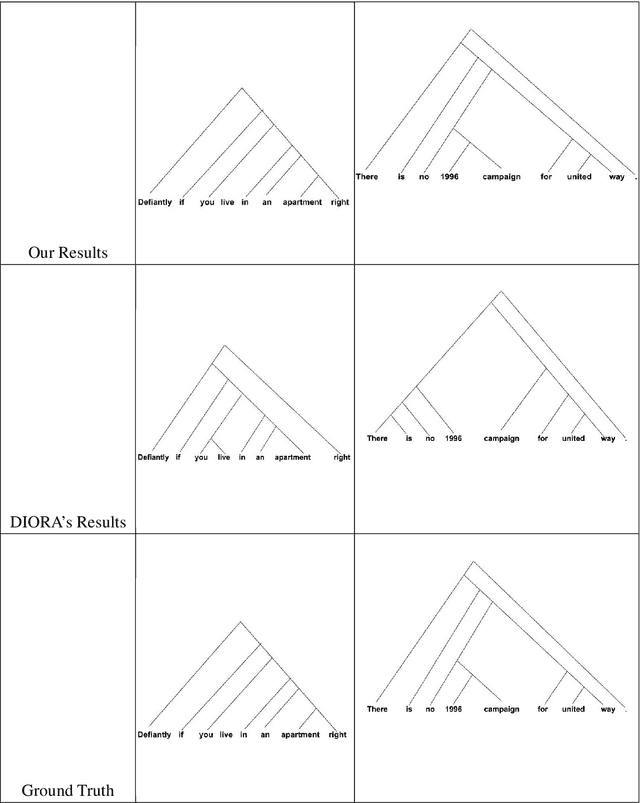
Recently, unsupervised parsing of syntactic trees has gained considerable attention. A prototypical approach to such unsupervised parsing employs reinforcement learning and auto-encoders. However, no mechanism ensures that the learnt model leverages the well-understood language grammar. We propose an approach that utilizes very generic linguistic knowledge of the language present in the form of syntactic rules, thus inducing better syntactic structures. We introduce a novel formulation that takes advantage of the syntactic grammar rules and is independent of the base system. We achieve new state-of-the-art results on two benchmarks datasets, MNLI and WSJ. The source code of the paper is available at https://github.com/anshuln/Diora_with_rules.
Relaxed Attention: A Simple Method to Boost Performance of End-to-End Automatic Speech Recognition
Jul 02, 2021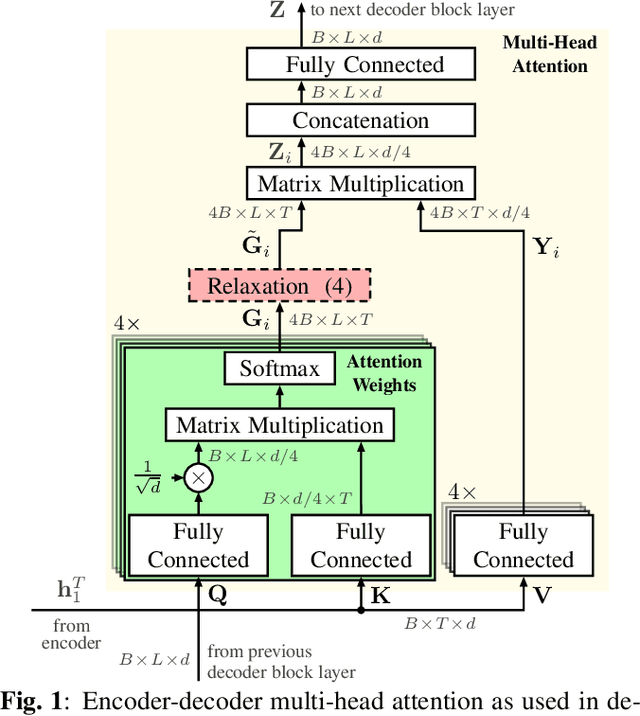
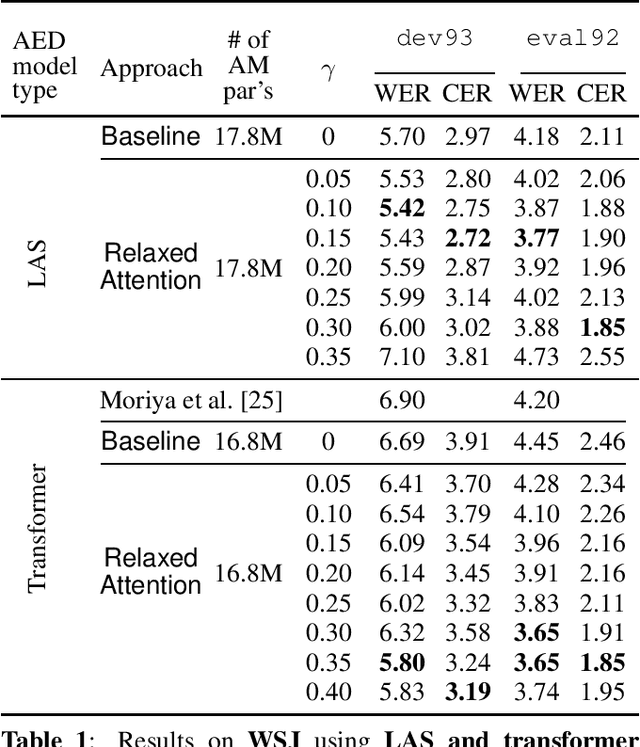
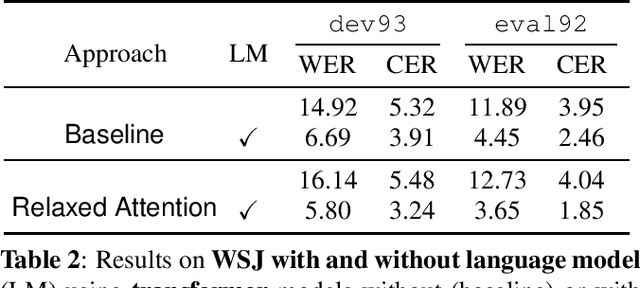
Recently, attention-based encoder-decoder (AED) models have shown high performance for end-to-end automatic speech recognition (ASR) across several tasks. Addressing overconfidence in such models, in this paper we introduce the concept of relaxed attention, which is a simple gradual injection of a uniform distribution to the encoder-decoder attention weights during training that is easily implemented with two lines of code. We investigate the effect of relaxed attention across different AED model architectures and two prominent ASR tasks, Wall Street Journal (WSJ) and Librispeech. We found that transformers trained with relaxed attention outperform the standard baseline models consistently during decoding with external language models. On WSJ, we set a new benchmark for transformer-based end-to-end speech recognition with a word error rate of 3.65%, outperforming state of the art (4.20%) by 13.1% relative, while introducing only a single hyperparameter. Upon acceptance, models will be published on github.
Efficient Neural Architecture Search for End-to-end Speech Recognition via Straight-Through Gradients
Nov 11, 2020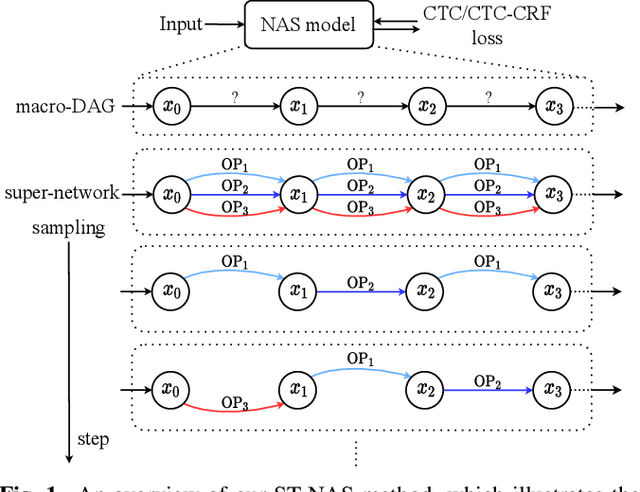
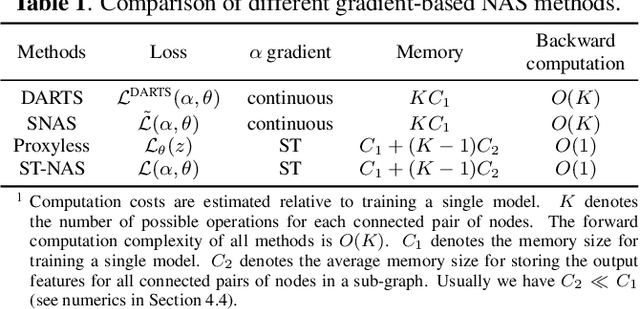
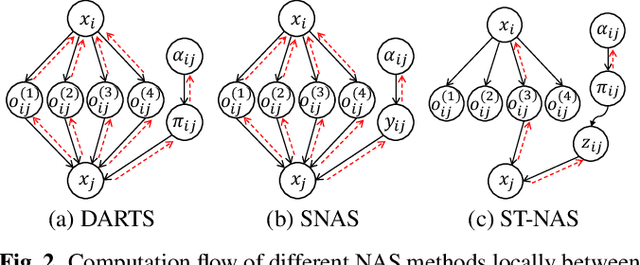
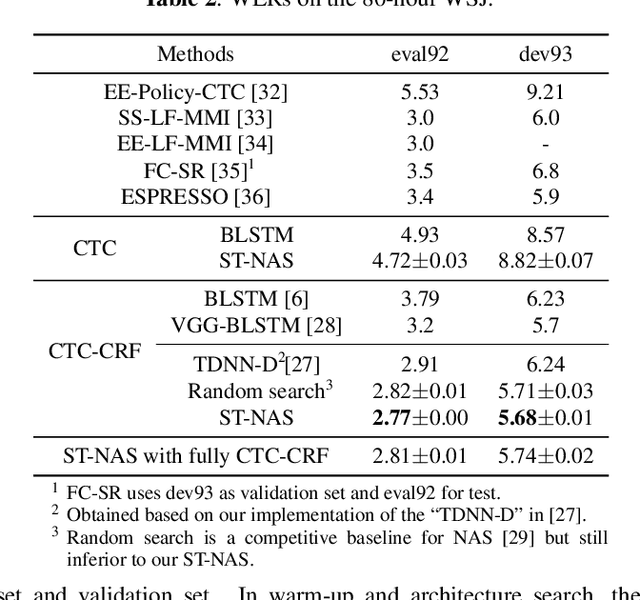
Neural Architecture Search (NAS), the process of automating architecture engineering, is an appealing next step to advancing end-to-end Automatic Speech Recognition (ASR), replacing expert-designed networks with learned, task-specific architectures. In contrast to early computational-demanding NAS methods, recent gradient-based NAS methods, e.g., DARTS (Differentiable ARchiTecture Search), SNAS (Stochastic NAS) and ProxylessNAS, significantly improve the NAS efficiency. In this paper, we make two contributions. First, we rigorously develop an efficient NAS method via Straight-Through (ST) gradients, called ST-NAS. Basically, ST-NAS uses the loss from SNAS but uses ST to back-propagate gradients through discrete variables to optimize the loss, which is not revealed in ProxylessNAS. Using ST gradients to support sub-graph sampling is a core element to achieve efficient NAS beyond DARTS and SNAS. Second, we successfully apply ST-NAS to end-to-end ASR. Experiments over the widely benchmarked 80-hour WSJ and 300-hour Switchboard datasets show that the ST-NAS induced architectures significantly outperform the human-designed architecture across the two datasets. Strengths of ST-NAS such as architecture transferability and low computation cost in memory and time are also reported.
Multi-Encoder Learning and Stream Fusion for Transformer-Based End-to-End Automatic Speech Recognition
Mar 31, 2021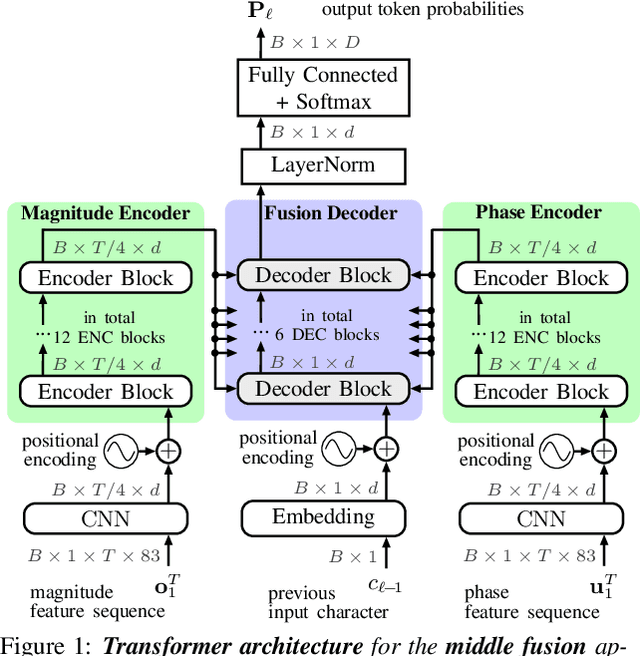
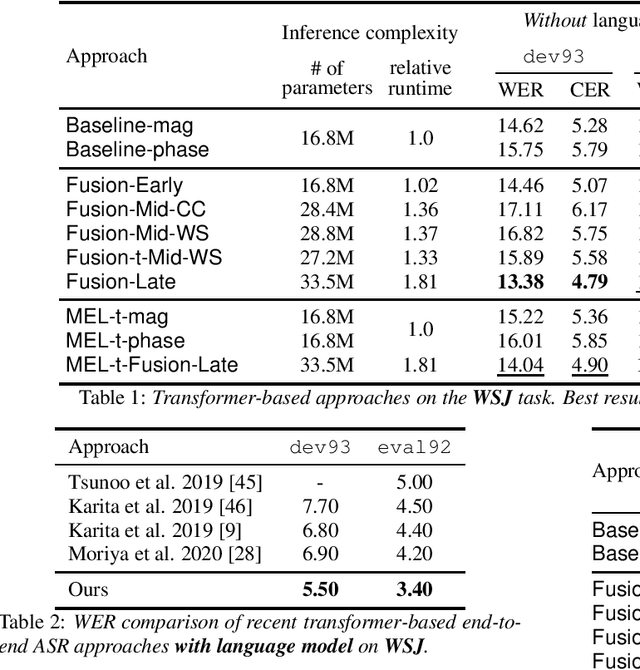
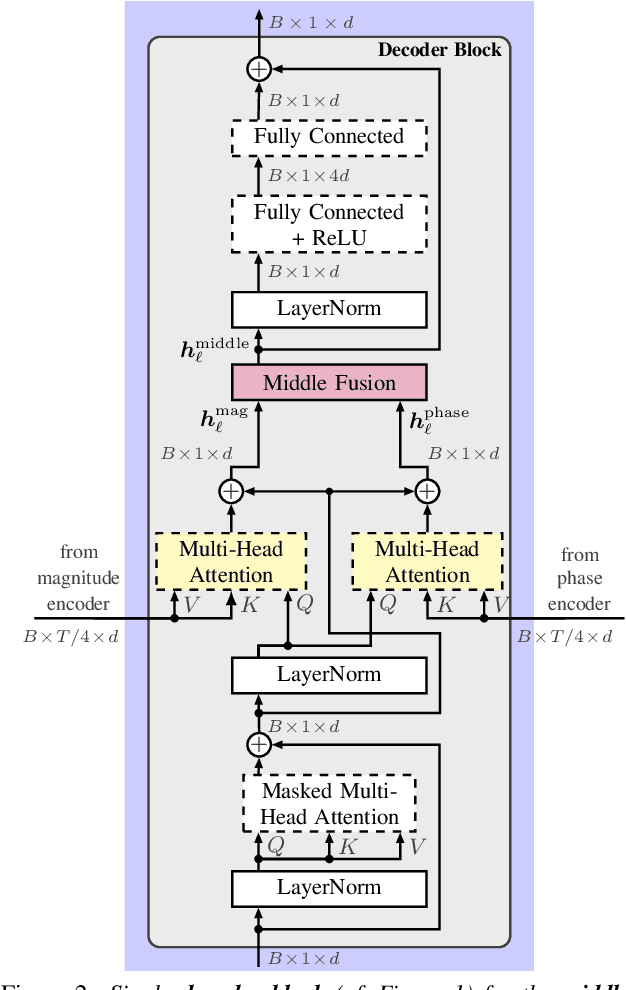
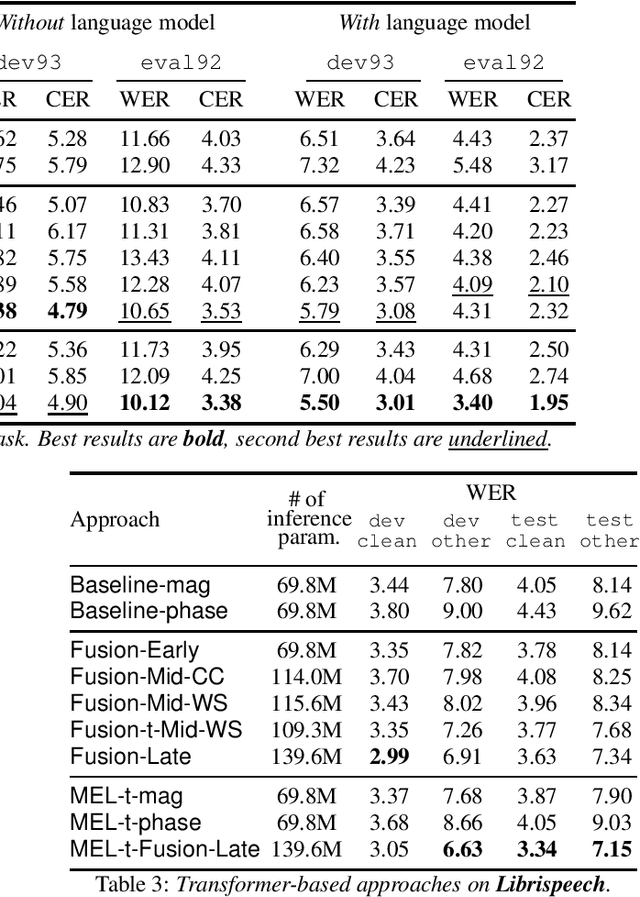
Stream fusion, also known as system combination, is a common technique in automatic speech recognition for traditional hybrid hidden Markov model approaches, yet mostly unexplored for modern deep neural network end-to-end model architectures. Here, we investigate various fusion techniques for the all-attention-based encoder-decoder architecture known as the transformer, striving to achieve optimal fusion by investigating different fusion levels in an example single-microphone setting with fusion of standard magnitude and phase features. We introduce a novel multi-encoder learning method that performs a weighted combination of two encoder-decoder multi-head attention outputs only during training. Employing then only the magnitude feature encoder in inference, we are able to show consistent improvement on Wall Street Journal (WSJ) with language model and on Librispeech, without increase in runtime or parameters. Combining two such multi-encoder trained models by a simple late fusion in inference, we achieve state-of-the-art performance for transformer-based models on WSJ with a significant WER reduction of 19\% relative compared to the current benchmark approach.
An Exploration of Self-Supervised Pretrained Representations for End-to-End Speech Recognition
Oct 09, 2021
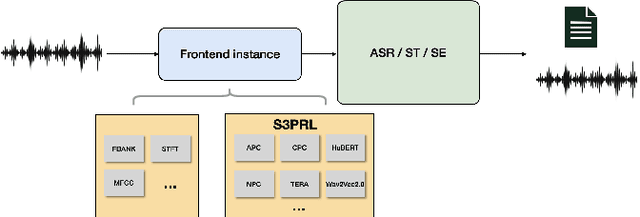
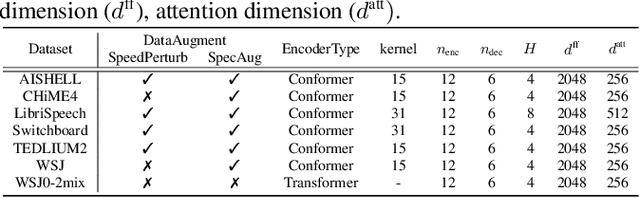
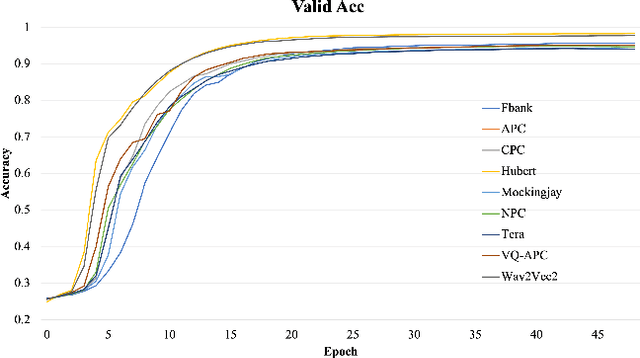
Self-supervised pretraining on speech data has achieved a lot of progress. High-fidelity representation of the speech signal is learned from a lot of untranscribed data and shows promising performance. Recently, there are several works focusing on evaluating the quality of self-supervised pretrained representations on various tasks without domain restriction, e.g. SUPERB. However, such evaluations do not provide a comprehensive comparison among many ASR benchmark corpora. In this paper, we focus on the general applications of pretrained speech representations, on advanced end-to-end automatic speech recognition (E2E-ASR) models. We select several pretrained speech representations and present the experimental results on various open-source and publicly available corpora for E2E-ASR. Without any modification of the back-end model architectures or training strategy, some of the experiments with pretrained representations, e.g., WSJ, WSJ0-2mix with HuBERT, reach or outperform current state-of-the-art (SOTA) recognition performance. Moreover, we further explore more scenarios for whether the pretraining representations are effective, such as the cross-language or overlapped speech. The scripts, configuratons and the trained models have been released in ESPnet to let the community reproduce our experiments and improve them.
Unsupervised Speaker Adaptation using Attention-based Speaker Memory for End-to-End ASR
Feb 14, 2020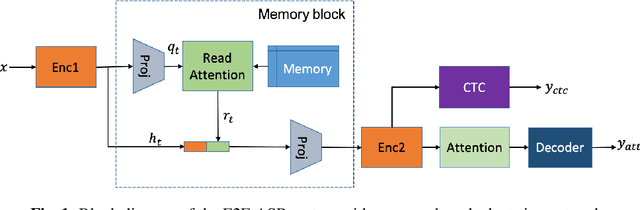
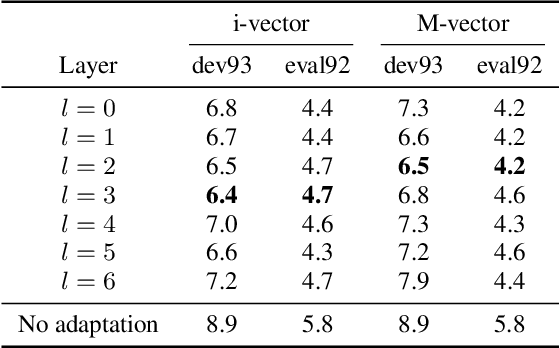
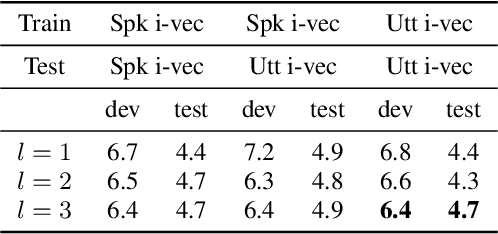

We propose an unsupervised speaker adaptation method inspired by the neural Turing machine for end-to-end (E2E) automatic speech recognition (ASR). The proposed model contains a memory block that holds speaker i-vectors extracted from the training data and reads relevant i-vectors from the memory through an attention mechanism. The resulting memory vector (M-vector) is concatenated to the acoustic features or to the hidden layer activations of an E2E neural network model. The E2E ASR system is based on the joint connectionist temporal classification and attention-based encoder-decoder architecture. M-vector and i-vector results are compared for inserting them at different layers of the encoder neural network using the WSJ and TED-LIUM2 ASR benchmarks. We show that M-vectors, which do not require an auxiliary speaker embedding extraction system at test time, achieve similar word error rates (WERs) compared to i-vectors for single speaker utterances and significantly lower WERs for utterances in which there are speaker changes.
Unsupervised Latent Tree Induction with Deep Inside-Outside Recursive Autoencoders
Apr 04, 2019
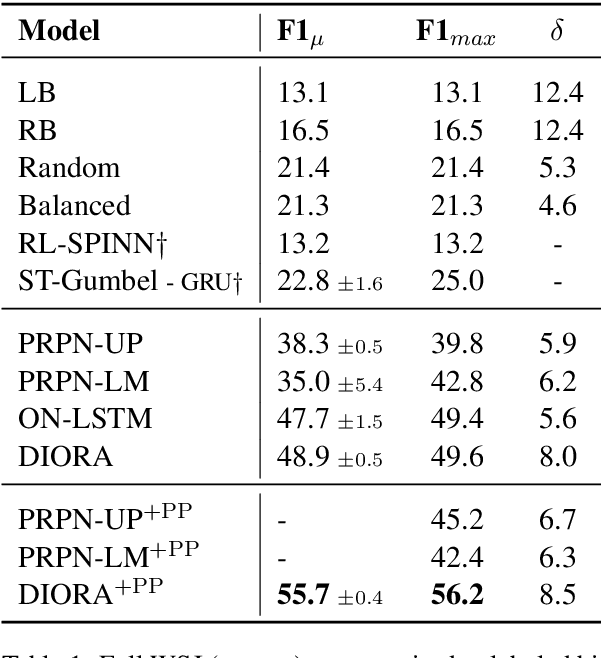
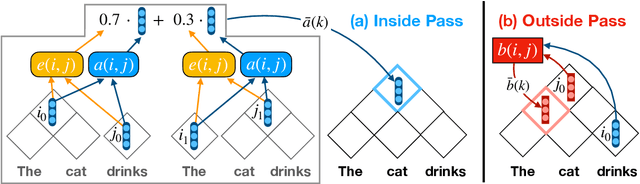
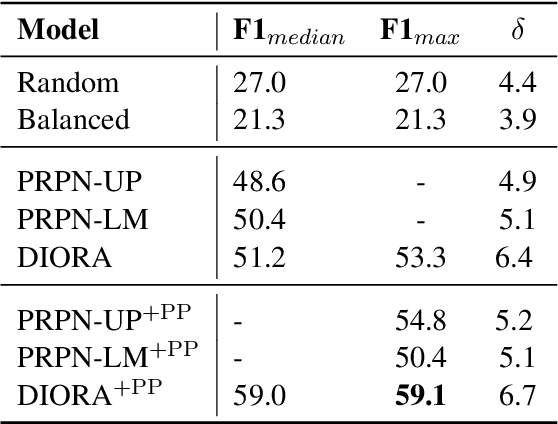
We introduce deep inside-outside recursive autoencoders (DIORA), a fully-unsupervised method for discovering syntax that simultaneously learns representations for constituents within the induced tree. Our approach predicts each word in an input sentence conditioned on the rest of the sentence and uses inside-outside dynamic programming to consider all possible binary trees over the sentence. At test time the CKY algorithm extracts the highest scoring parse. DIORA achieves a new state-of-the-art F1 in unsupervised binary constituency parsing (unlabeled) in two benchmark datasets, WSJ and MultiNLI.