 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiqa
Papers and Code
Relevant CommonSense Subgraphs for "What if..." Procedural Reasoning
Mar 21, 2022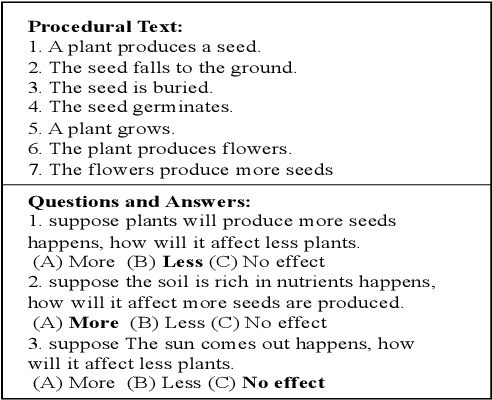
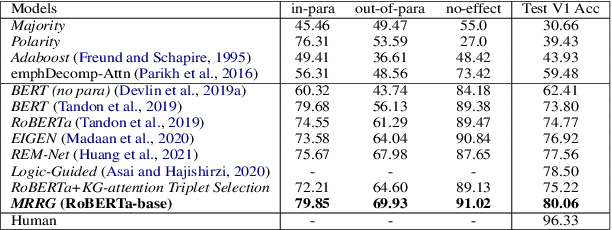
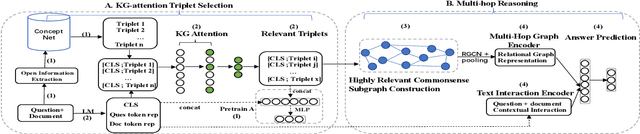
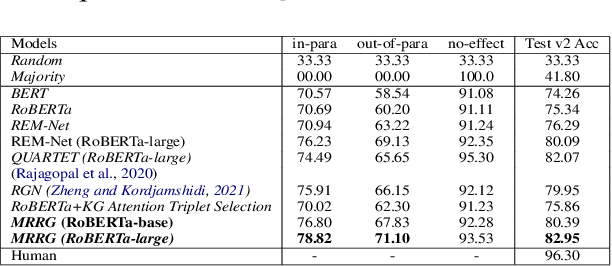
We study the challenge of learning causal reasoning over procedural text to answer "What if..." questions when external commonsense knowledge is required. We propose a novel multi-hop graph reasoning model to 1) efficiently extract a commonsense subgraph with the most relevant information from a large knowledge graph; 2) predict the causal answer by reasoning over the representations obtained from the commonsense subgraph and the contextual interactions between the questions and context. We evaluate our model on WIQA benchmark and achieve state-of-the-art performance compared to the recent models.
elBERto: Self-supervised Commonsense Learning for Question Answering
Mar 17, 2022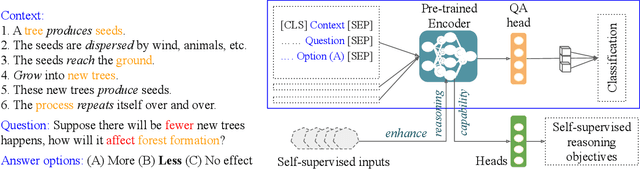

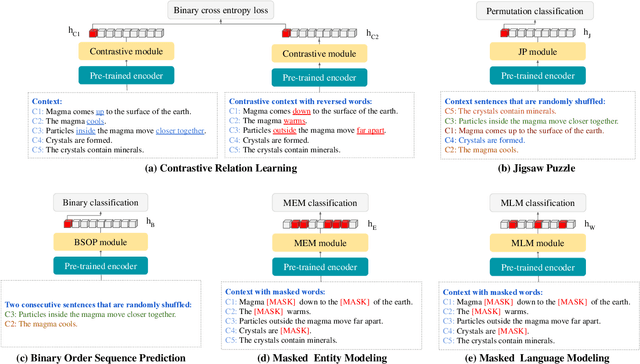
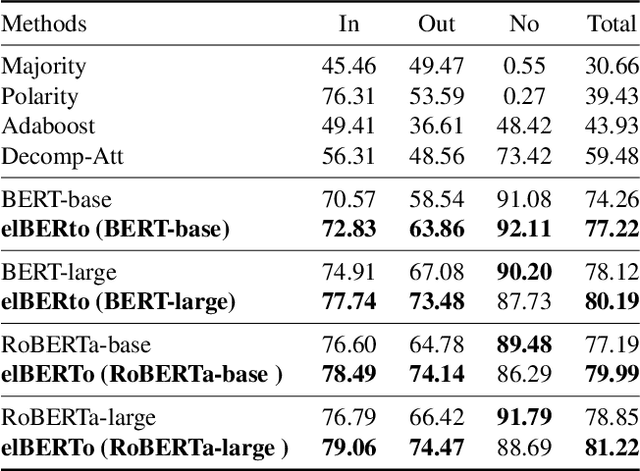
Commonsense question answering requires reasoning about everyday situations and causes and effects implicit in context. Typically, existing approaches first retrieve external evidence and then perform commonsense reasoning using these evidence. In this paper, we propose a Self-supervised Bidirectional Encoder Representation Learning of Commonsense (elBERto) framework, which is compatible with off-the-shelf QA model architectures. The framework comprises five self-supervised tasks to force the model to fully exploit the additional training signals from contexts containing rich commonsense. The tasks include a novel Contrastive Relation Learning task to encourage the model to distinguish between logically contrastive contexts, a new Jigsaw Puzzle task that requires the model to infer logical chains in long contexts, and three classic SSL tasks to maintain pre-trained models language encoding ability. On the representative WIQA, CosmosQA, and ReClor datasets, elBERto outperforms all other methods, including those utilizing explicit graph reasoning and external knowledge retrieval. Moreover, elBERto achieves substantial improvements on out-of-paragraph and no-effect questions where simple lexical similarity comparison does not help, indicating that it successfully learns commonsense and is able to leverage it when given dynamic context.
Relational Gating for "What If" Reasoning
May 27, 2021
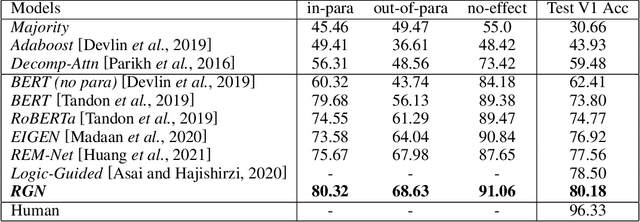
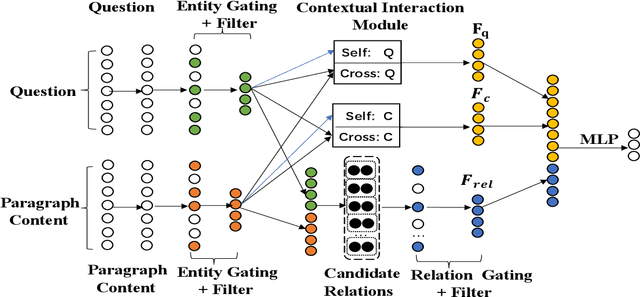
This paper addresses the challenge of learning to do procedural reasoning over text to answer "What if..." questions. We propose a novel relational gating network that learns to filter the key entities and relationships and learns contextual and cross representations of both procedure and question for finding the answer. Our relational gating network contains an entity gating module, relation gating module, and contextual interaction module. These modules help in solving the "What if..." reasoning problem. We show that modeling pairwise relationships helps to capture higher-order relations and find the line of reasoning for causes and effects in the procedural descriptions. Our proposed approach achieves the state-of-the-art results on the WIQA dataset.
CURIE: An Iterative Querying Approach for Reasoning About Situations
Apr 05, 2021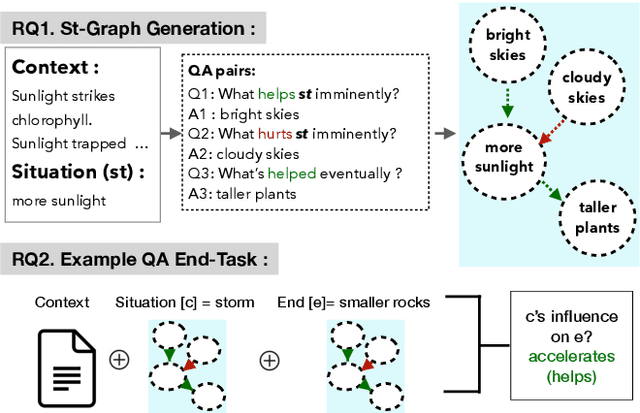
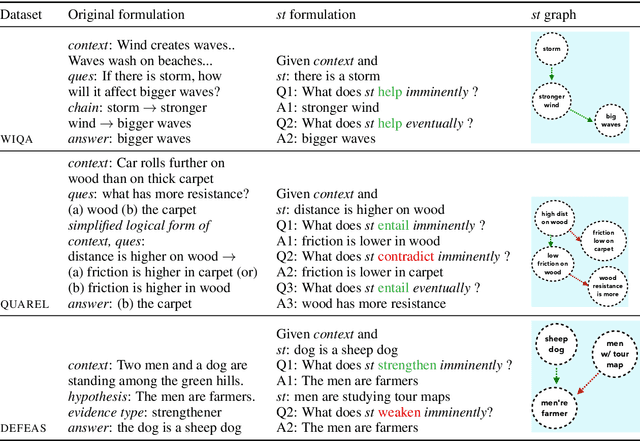
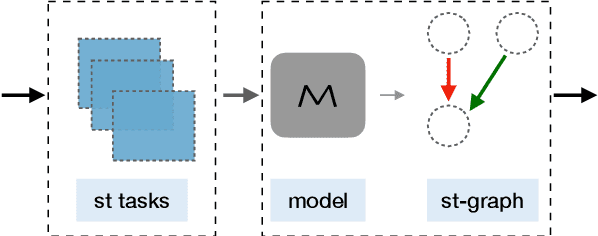
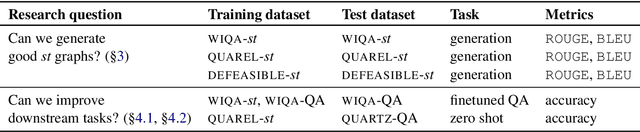
Recently, models have been shown to predict the effects of unexpected situations, e.g., would cloudy skies help or hinder plant growth? Given a context, the goal of such situational reasoning is to elicit the consequences of a new situation (st) that arises in that context. We propose a method to iteratively build a graph of relevant consequences explicitly in a structured situational graph (st-graph) using natural language queries over a finetuned language model (M). Across multiple domains, CURIE generates st-graphs that humans find relevant and meaningful in eliciting the consequences of a new situation. We show that st-graphs generated by CURIE improve a situational reasoning end task (WIQA-QA) by 3 points on accuracy by simply augmenting their input with our generated situational graphs, especially for a hard subset that requires background knowledge and multi-hop reasoning.
REM-Net: Recursive Erasure Memory Network for Commonsense Evidence Refinement
Jan 03, 2021
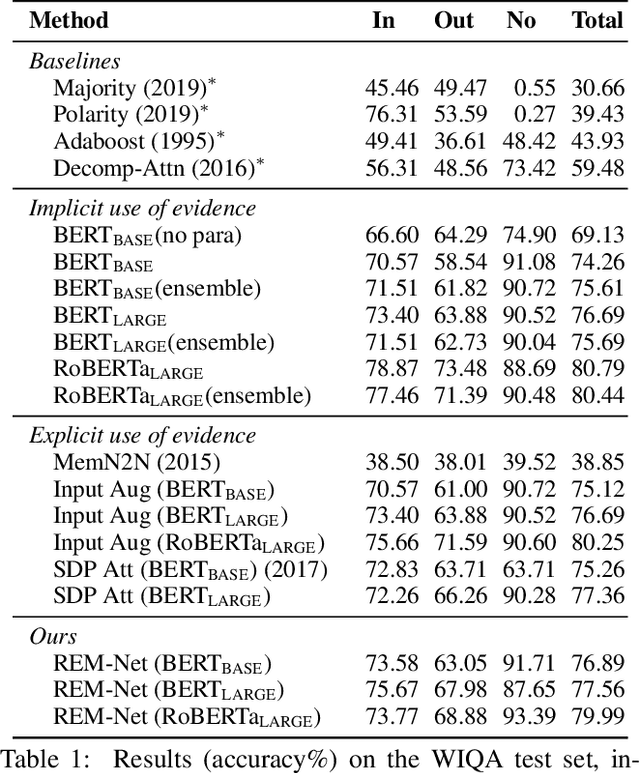
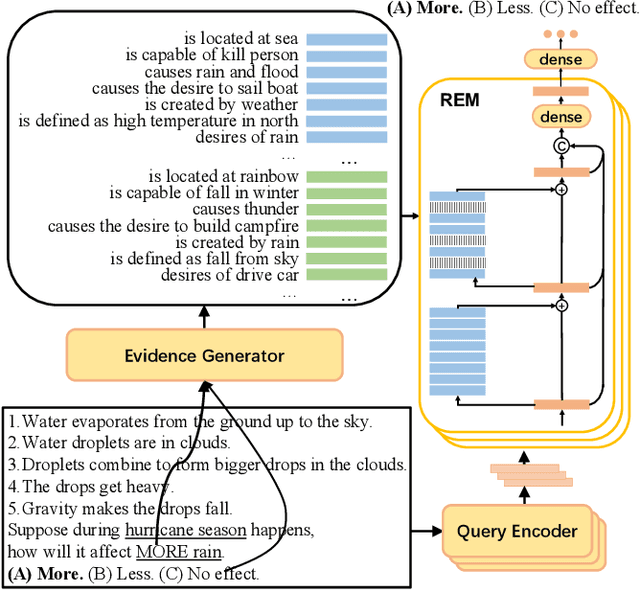

When answering a question, people often draw upon their rich world knowledge in addition to the particular context. While recent works retrieve supporting facts/evidence from commonsense knowledge bases to supply additional information to each question, there is still ample opportunity to advance it on the quality of the evidence. It is crucial since the quality of the evidence is the key to answering commonsense questions, and even determines the upper bound on the QA systems performance. In this paper, we propose a recursive erasure memory network (REM-Net) to cope with the quality improvement of evidence. To address this, REM-Net is equipped with a module to refine the evidence by recursively erasing the low-quality evidence that does not explain the question answering. Besides, instead of retrieving evidence from existing knowledge bases, REM-Net leverages a pre-trained generative model to generate candidate evidence customized for the question. We conduct experiments on two commonsense question answering datasets, WIQA and CosmosQA. The results demonstrate the performance of REM-Net and show that the refined evidence is explainable.
EIGEN: Event Influence GENeration using Pre-trained Language Models
Oct 22, 2020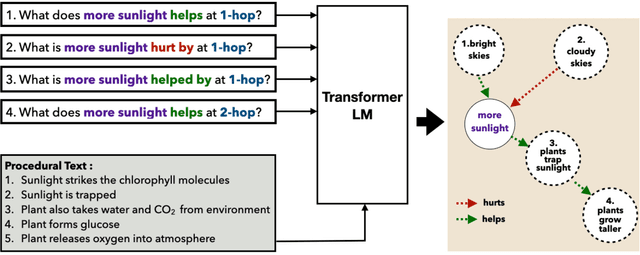
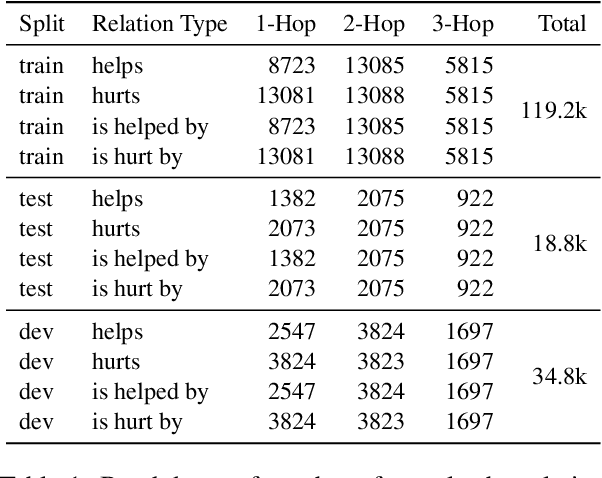

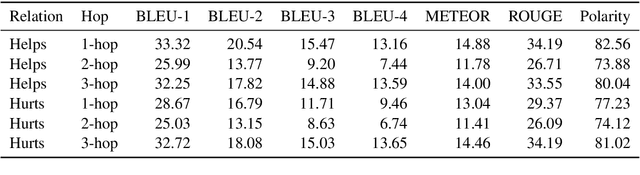
Reasoning about events and tracking their influences is fundamental to understanding processes. In this paper, we present EIGEN - a method to leverage pre-trained language models to generate event influences conditioned on a context, nature of their influence, and the distance in a reasoning chain. We also derive a new dataset for research and evaluation of methods for event influence generation. EIGEN outperforms strong baselines both in terms of automated evaluation metrics (by 10 ROUGE points) and human judgments on closeness to reference and relevance of generations. Furthermore, we show that the event influences generated by EIGEN improve the performance on a "what-if" Question Answering (WIQA) benchmark (over 3% F1), especially for questions that require background knowledge and multi-hop reasoning.
Logic-Guided Data Augmentation and Regularization for Consistent Question Answering
May 25, 2020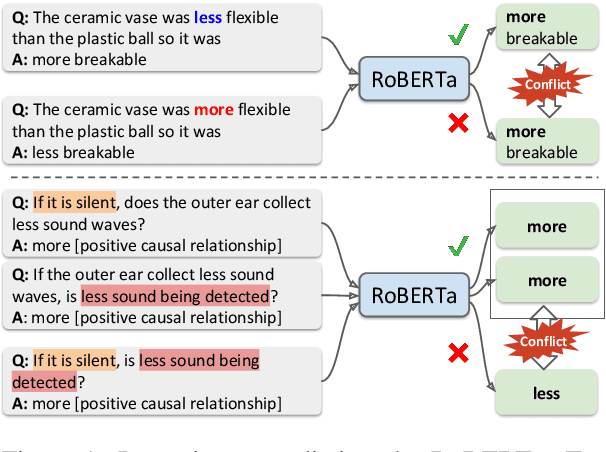
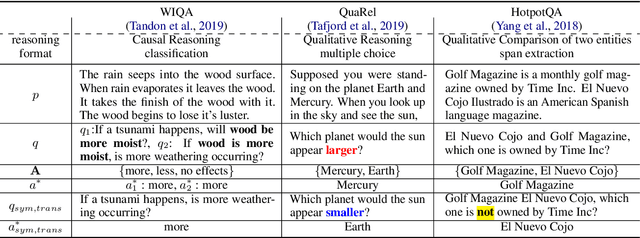
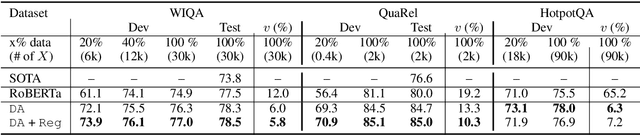
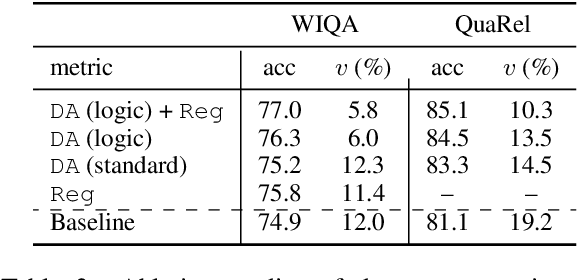
Many natural language questions require qualitative, quantitative or logical comparisons between two entities or events. This paper addresses the problem of improving the accuracy and consistency of responses to comparison questions by integrating logic rules and neural models. Our method leverages logical and linguistic knowledge to augment labeled training data and then uses a consistency-based regularizer to train the model. Improving the global consistency of predictions, our approach achieves large improvements over previous methods in a variety of question answering (QA) tasks including multiple-choice qualitative reasoning, cause-effect reasoning, and extractive machine reading comprehension. In particular, our method significantly improves the performance of RoBERTa-based models by 1-5% across datasets. We advance the state of the art by around 5-8% on WIQA and QuaRel and reduce consistency violations by 58% on HotpotQA. We further demonstrate that our approach can learn effectively from limited data.
WIQA: A dataset for "What if" reasoning over procedural text
Sep 10, 2019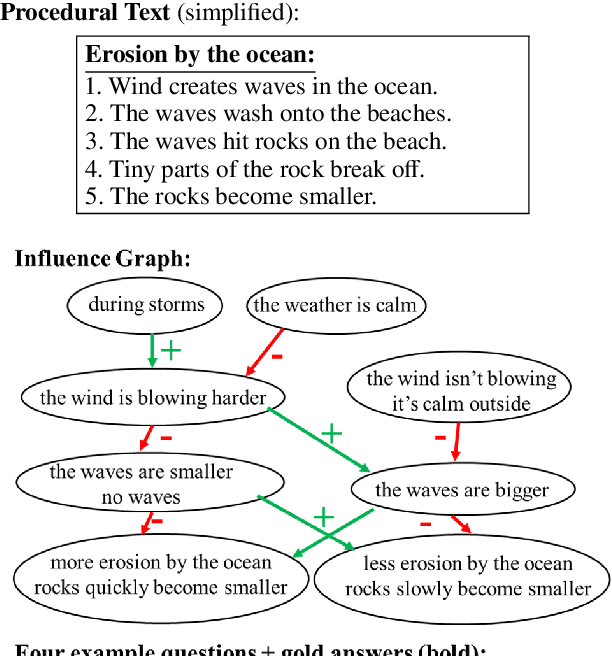
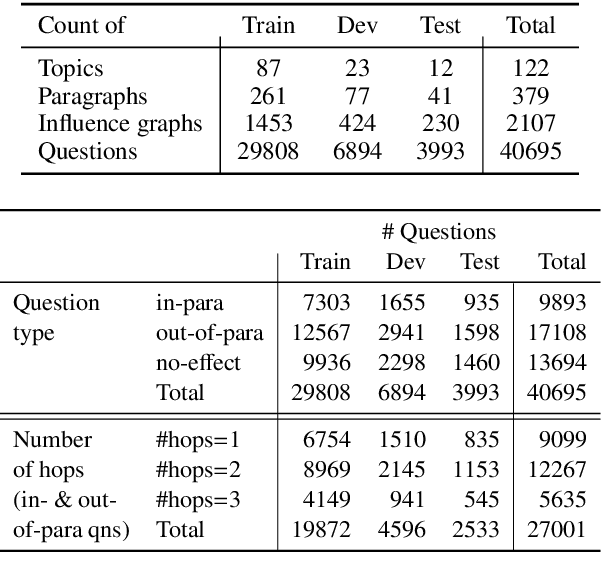
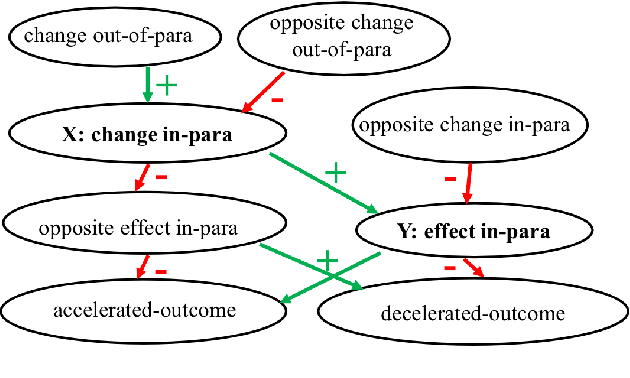
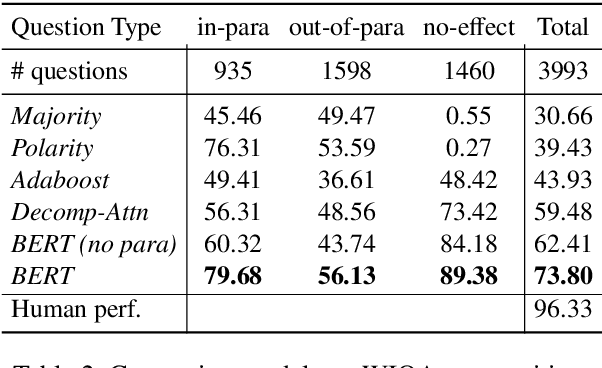
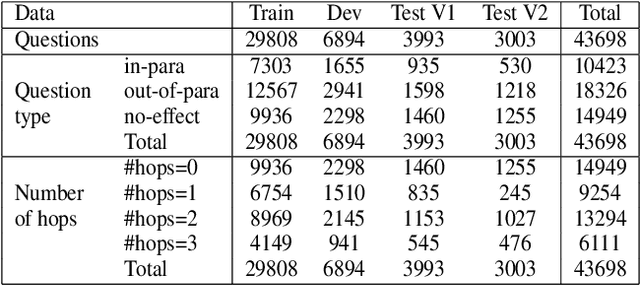
We introduce WIQA, the first large-scale dataset of "What if..." questions over procedural text. WIQA contains three parts: a collection of paragraphs each describing a process, e.g., beach erosion; a set of crowdsourced influence graphs for each paragraph, describing how one change affects another; and a large (40k) collection of "What if...?" multiple-choice questions derived from the graphs. For example, given a paragraph about beach erosion, would stormy weather result in more or less erosion (or have no effect)? The task is to answer the questions, given their associated paragraph. WIQA contains three kinds of questions: perturbations to steps mentioned in the paragraph; external (out-of-paragraph) perturbations requiring commonsense knowledge; and irrelevant (no effect) perturbations. We find that state-of-the-art models achieve 73.8% accuracy, well below the human performance of 96.3%. We analyze the challenges, in particular tracking chains of influences, and present the dataset as an open challenge to the community.