 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScribblekitti
Papers and Code
Multi-modal NeRF Self-Supervision for LiDAR Semantic Segmentation
Nov 05, 2024



LiDAR Semantic Segmentation is a fundamental task in autonomous driving perception consisting of associating each LiDAR point to a semantic label. Fully-supervised models have widely tackled this task, but they require labels for each scan, which either limits their domain or requires impractical amounts of expensive annotations. Camera images, which are generally recorded alongside LiDAR pointclouds, can be processed by the widely available 2D foundation models, which are generic and dataset-agnostic. However, distilling knowledge from 2D data to improve LiDAR perception raises domain adaptation challenges. For example, the classical perspective projection suffers from the parallax effect produced by the position shift between both sensors at their respective capture times. We propose a Semi-Supervised Learning setup to leverage unlabeled LiDAR pointclouds alongside distilled knowledge from the camera images. To self-supervise our model on the unlabeled scans, we add an auxiliary NeRF head and cast rays from the camera viewpoint over the unlabeled voxel features. The NeRF head predicts densities and semantic logits at each sampled ray location which are used for rendering pixel semantics. Concurrently, we query the Segment-Anything (SAM) foundation model with the camera image to generate a set of unlabeled generic masks. We fuse the masks with the rendered pixel semantics from LiDAR to produce pseudo-labels that supervise the pixel predictions. During inference, we drop the NeRF head and run our model with only LiDAR. We show the effectiveness of our approach in three public LiDAR Semantic Segmentation benchmarks: nuScenes, SemanticKITTI and ScribbleKITTI.
Bayesian Self-Training for Semi-Supervised 3D Segmentation
Sep 12, 2024



3D segmentation is a core problem in computer vision and, similarly to many other dense prediction tasks, it requires large amounts of annotated data for adequate training. However, densely labeling 3D point clouds to employ fully-supervised training remains too labor intensive and expensive. Semi-supervised training provides a more practical alternative, where only a small set of labeled data is given, accompanied by a larger unlabeled set. This area thus studies the effective use of unlabeled data to reduce the performance gap that arises due to the lack of annotations. In this work, inspired by Bayesian deep learning, we first propose a Bayesian self-training framework for semi-supervised 3D semantic segmentation. Employing stochastic inference, we generate an initial set of pseudo-labels and then filter these based on estimated point-wise uncertainty. By constructing a heuristic $n$-partite matching algorithm, we extend the method to semi-supervised 3D instance segmentation, and finally, with the same building blocks, to dense 3D visual grounding. We demonstrate state-of-the-art results for our semi-supervised method on SemanticKITTI and ScribbleKITTI for 3D semantic segmentation and on ScanNet and S3DIS for 3D instance segmentation. We further achieve substantial improvements in dense 3D visual grounding over supervised-only baselines on ScanRefer. Our project page is available at ouenal.github.io/bst/.
2D Feature Distillation for Weakly- and Semi-Supervised 3D Semantic Segmentation
Nov 27, 2023As 3D perception problems grow in popularity and the need for large-scale labeled datasets for LiDAR semantic segmentation increase, new methods arise that aim to reduce the necessity for dense annotations by employing weakly-supervised training. However these methods continue to show weak boundary estimation and high false negative rates for small objects and distant sparse regions. We argue that such weaknesses can be compensated by using RGB images which provide a denser representation of the scene. We propose an image-guidance network (IGNet) which builds upon the idea of distilling high level feature information from a domain adapted synthetically trained 2D semantic segmentation network. We further utilize a one-way contrastive learning scheme alongside a novel mixing strategy called FOVMix, to combat the horizontal field-of-view mismatch between the two sensors and enhance the effects of image guidance. IGNet achieves state-of-the-art results for weakly-supervised LiDAR semantic segmentation on ScribbleKITTI, boasting up to 98% relative performance to fully supervised training with only 8% labeled points, while introducing no additional annotation burden or computational/memory cost during inference. Furthermore, we show that our contributions also prove effective for semi-supervised training, where IGNet claims state-of-the-art results on both ScribbleKITTI and SemanticKITTI.
Less is More: Reducing Task and Model Complexity for 3D Point Cloud Semantic Segmentation
Mar 28, 2023Whilst the availability of 3D LiDAR point cloud data has significantly grown in recent years, annotation remains expensive and time-consuming, leading to a demand for semi-supervised semantic segmentation methods with application domains such as autonomous driving. Existing work very often employs relatively large segmentation backbone networks to improve segmentation accuracy, at the expense of computational costs. In addition, many use uniform sampling to reduce ground truth data requirements for learning needed, often resulting in sub-optimal performance. To address these issues, we propose a new pipeline that employs a smaller architecture, requiring fewer ground-truth annotations to achieve superior segmentation accuracy compared to contemporary approaches. This is facilitated via a novel Sparse Depthwise Separable Convolution module that significantly reduces the network parameter count while retaining overall task performance. To effectively sub-sample our training data, we propose a new Spatio-Temporal Redundant Frame Downsampling (ST-RFD) method that leverages knowledge of sensor motion within the environment to extract a more diverse subset of training data frame samples. To leverage the use of limited annotated data samples, we further propose a soft pseudo-label method informed by LiDAR reflectivity. Our method outperforms contemporary semi-supervised work in terms of mIoU, using less labeled data, on the SemanticKITTI (59.5@5%) and ScribbleKITTI (58.1@5%) benchmark datasets, based on a 2.3x reduction in model parameters and 641x fewer multiply-add operations whilst also demonstrating significant performance improvement on limited training data (i.e., Less is More).
Rethinking Range View Representation for LiDAR Segmentation
Mar 18, 2023LiDAR segmentation is crucial for autonomous driving perception. Recent trends favor point- or voxel-based methods as they often yield better performance than the traditional range view representation. In this work, we unveil several key factors in building powerful range view models. We observe that the "many-to-one" mapping, semantic incoherence, and shape deformation are possible impediments against effective learning from range view projections. We present RangeFormer -- a full-cycle framework comprising novel designs across network architecture, data augmentation, and post-processing -- that better handles the learning and processing of LiDAR point clouds from the range view. We further introduce a Scalable Training from Range view (STR) strategy that trains on arbitrary low-resolution 2D range images, while still maintaining satisfactory 3D segmentation accuracy. We show that, for the first time, a range view method is able to surpass the point, voxel, and multi-view fusion counterparts in the competing LiDAR semantic and panoptic segmentation benchmarks, i.e., SemanticKITTI, nuScenes, and ScribbleKITTI.
LaserMix for Semi-Supervised LiDAR Semantic Segmentation
Jun 30, 2022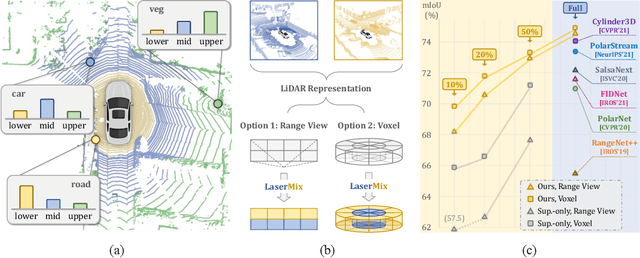
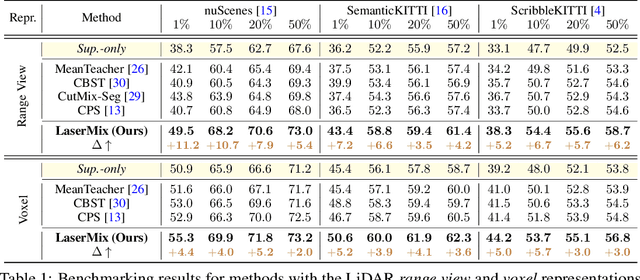

Densely annotating LiDAR point clouds is costly, which restrains the scalability of fully-supervised learning methods. In this work, we study the underexplored semi-supervised learning (SSL) in LiDAR segmentation. Our core idea is to leverage the strong spatial cues of LiDAR point clouds to better exploit unlabeled data. We propose LaserMix to mix laser beams from different LiDAR scans, and then encourage the model to make consistent and confident predictions before and after mixing. Our framework has three appealing properties: 1) Generic: LaserMix is agnostic to LiDAR representations (e.g., range view and voxel), and hence our SSL framework can be universally applied. 2) Statistically grounded: We provide a detailed analysis to theoretically explain the applicability of the proposed framework. 3) Effective: Comprehensive experimental analysis on popular LiDAR segmentation datasets (nuScenes, SemanticKITTI, and ScribbleKITTI) demonstrates our effectiveness and superiority. Notably, we achieve competitive results over fully-supervised counterparts with 2x to 5x fewer labels and improve the supervised-only baseline significantly by 10.8% on average. We hope this concise yet high-performing framework could facilitate future research in semi-supervised LiDAR segmentation. Code will be publicly available.
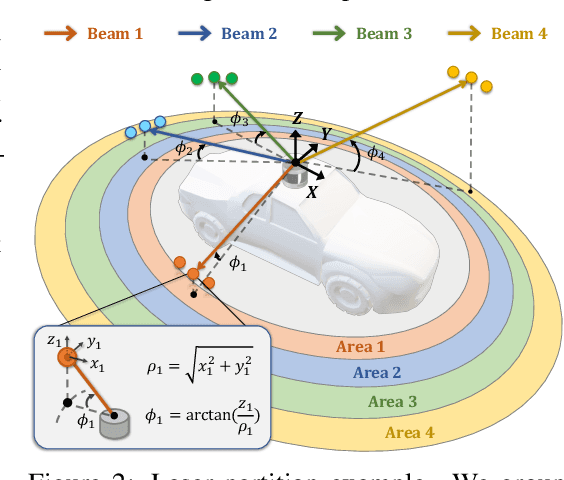
Scribble-Supervised LiDAR Semantic Segmentation
Mar 31, 2022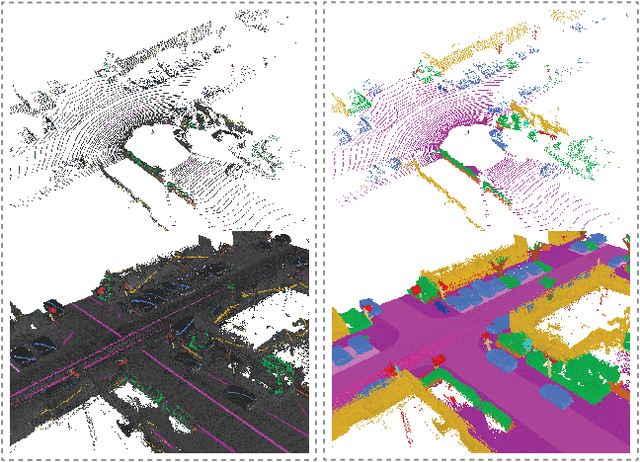
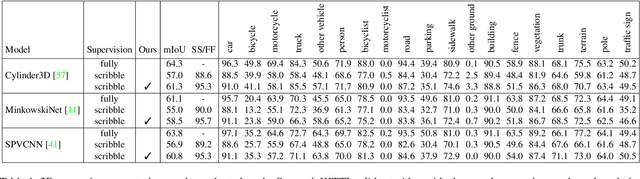
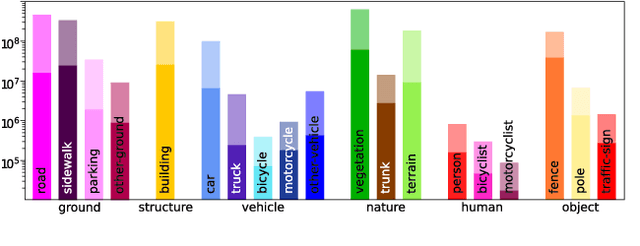
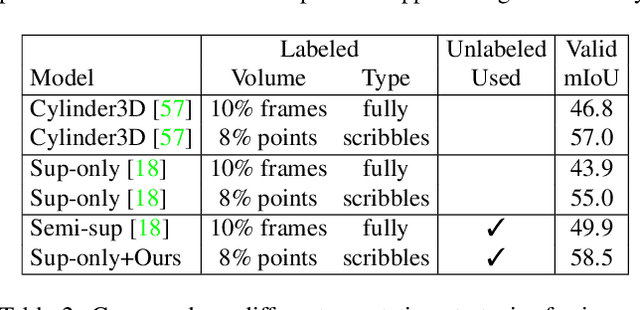
Densely annotating LiDAR point clouds remains too expensive and time-consuming to keep up with the ever growing volume of data. While current literature focuses on fully-supervised performance, developing efficient methods that take advantage of realistic weak supervision have yet to be explored. In this paper, we propose using scribbles to annotate LiDAR point clouds and release ScribbleKITTI, the first scribble-annotated dataset for LiDAR semantic segmentation. Furthermore, we present a pipeline to reduce the performance gap that arises when using such weak annotations. Our pipeline comprises of three stand-alone contributions that can be combined with any LiDAR semantic segmentation model to achieve up to 95.7% of the fully-supervised performance while using only 8% labeled points. Our scribble annotations and code are available at github.com/ouenal/scribblekitti.