 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopularity Forecasting
Papers and Code
Following the TRAIL: Predicting and Explaining Tomorrow's Hits with a Fine-Tuned LLM
Feb 04, 2026Large Language Models (LLMs) have been widely applied across multiple domains for their broad knowledge and strong reasoning capabilities. However, applying them to recommendation systems is challenging since it is hard for LLMs to extract user preferences from large, sparse user-item logs, and real-time per-user ranking over the full catalog is too time-consuming to be practical. Moreover, many existing recommender systems focus solely on ranking items while overlooking explanations, which could help improve predictive accuracy and make recommendations more convincing to users. Inspired by recent works that achieve strong recommendation performance by forecasting near-term item popularity, we propose TRAIL (TRend and explAnation Integrated Learner). TRAIL is a fine-tuned LLM that jointly predicts short-term item popularity and generates faithful natural-language explanations. It employs contrastive learning with positive and negative pairs to align its scores and explanations with structured trend signals, yielding accurate and explainable popularity predictions. Extensive experiments show that TRAIL outperforms strong baselines and produces coherent, well-grounded explanations.
Intermittent time series forecasting: local vs global models
Jan 20, 2026Intermittent time series, characterised by the presence of a significant amount of zeros, constitute a large percentage of inventory items in supply chain. Probabilistic forecasts are needed to plan the inventory levels; the predictive distribution should cover non-negative values, have a mass in zero and a long upper tail. Intermittent time series are commonly forecast using local models, which are trained individually on each time series. In the last years global models, which are trained on a large collection of time series, have become popular for time series forecasting. Global models are often based on neural networks. However, they have not yet been exhaustively tested on intermittent time series. We carry out the first study comparing state-of-the-art local (iETS, TweedieGP) and global models (D-Linear, DeepAR, Transformers) on intermittent time series. For neural networks models we consider three different distribution heads suitable for intermittent time series: negative binomial, hurdle-shifted negative binomial and Tweedie. We use, for the first time, the last two distribution heads with neural networks. We perform experiments on five large datasets comprising more than 40'000 real-world time series. Among neural networks D-Linear provides best accuracy; it also consistently outperforms the local models. Moreover, it has also low computational requirements. Transformers-based architectures are instead much more computationally demanding and less accurate. Among the distribution heads, the Tweedie provides the best estimates of the highest quantiles, while the negative binomial offers overall the best performance.
FutureOmni: Evaluating Future Forecasting from Omni-Modal Context for Multimodal LLMs
Jan 20, 2026Although Multimodal Large Language Models (MLLMs) demonstrate strong omni-modal perception, their ability to forecast future events from audio-visual cues remains largely unexplored, as existing benchmarks focus mainly on retrospective understanding. To bridge this gap, we introduce FutureOmni, the first benchmark designed to evaluate omni-modal future forecasting from audio-visual environments. The evaluated models are required to perform cross-modal causal and temporal reasoning, as well as effectively leverage internal knowledge to predict future events. FutureOmni is constructed via a scalable LLM-assisted, human-in-the-loop pipeline and contains 919 videos and 1,034 multiple-choice QA pairs across 8 primary domains. Evaluations on 13 omni-modal and 7 video-only models show that current systems struggle with audio-visual future prediction, particularly in speech-heavy scenarios, with the best accuracy of 64.8% achieved by Gemini 3 Flash. To mitigate this limitation, we curate a 7K-sample instruction-tuning dataset and propose an Omni-Modal Future Forecasting (OFF) training strategy. Evaluations on FutureOmni and popular audio-visual and video-only benchmarks demonstrate that OFF enhances future forecasting and generalization. We publicly release all code (https://github.com/OpenMOSS/FutureOmni) and datasets (https://huggingface.co/datasets/OpenMOSS-Team/FutureOmni).
Adversarial News and Lost Profits: Manipulating Headlines in LLM-Driven Algorithmic Trading
Jan 19, 2026Large Language Models (LLMs) are increasingly adopted in the financial domain. Their exceptional capabilities to analyse textual data make them well-suited for inferring the sentiment of finance-related news. Such feedback can be leveraged by algorithmic trading systems (ATS) to guide buy/sell decisions. However, this practice bears the risk that a threat actor may craft "adversarial news" intended to mislead an LLM. In particular, the news headline may include "malicious" content that remains invisible to human readers but which is still ingested by the LLM. Although prior work has studied textual adversarial examples, their system-wide impact on LLM-supported ATS has not yet been quantified in terms of monetary risk. To address this threat, we consider an adversary with no direct access to an ATS but able to alter stock-related news headlines on a single day. We evaluate two human-imperceptible manipulations in a financial context: Unicode homoglyph substitutions that misroute models during stock-name recognition, and hidden-text clauses that alter the sentiment of the news headline. We implement a realistic ATS in Backtrader that fuses an LSTM-based price forecast with LLM-derived sentiment (FinBERT, FinGPT, FinLLaMA, and six general-purpose LLMs), and quantify monetary impact using portfolio metrics. Experiments on real-world data show that manipulating a one-day attack over 14 months can reliably mislead LLMs and reduce annual returns by up to 17.7 percentage points. To assess real-world feasibility, we analyze popular scraping libraries and trading platforms and survey 27 FinTech practitioners, confirming our hypotheses. We notified trading platform owners of this security issue.
Scaling Open-Ended Reasoning to Predict the Future
Dec 31, 2025High-stakes decision making involves reasoning under uncertainty about the future. In this work, we train language models to make predictions on open-ended forecasting questions. To scale up training data, we synthesize novel forecasting questions from global events reported in daily news, using a fully automated, careful curation recipe. We train the Qwen3 thinking models on our dataset, OpenForesight. To prevent leakage of future information during training and evaluation, we use an offline news corpus, both for data generation and retrieval in our forecasting system. Guided by a small validation set, we show the benefits of retrieval, and an improved reward function for reinforcement learning (RL). Once we obtain our final forecasting system, we perform held-out testing between May to August 2025. Our specialized model, OpenForecaster 8B, matches much larger proprietary models, with our training improving the accuracy, calibration, and consistency of predictions. We find calibration improvements from forecasting training generalize across popular benchmarks. We open-source all our models, code, and data to make research on language model forecasting broadly accessible.
Toward Better Temporal Structures for Geopolitical Events Forecasting
Jan 01, 2026Forecasting on geopolitical temporal knowledge graphs (TKGs) through the lens of large language models (LLMs) has recently gained traction. While TKGs and their generalization, hyper-relational temporal knowledge graphs (HTKGs), offer a straightforward structure to represent simple temporal relationships, they lack the expressive power to convey complex facts efficiently. One of the critical limitations of HTKGs is a lack of support for more than two primary entities in temporal facts, which commonly occur in real-world events. To address this limitation, in this work, we study a generalization of HTKGs, Hyper-Relational Temporal Knowledge Generalized Hypergraphs (HTKGHs). We first derive a formalization for HTKGHs, demonstrating their backward compatibility while supporting two complex types of facts commonly found in geopolitical incidents. Then, utilizing this formalization, we introduce the htkgh-polecat dataset, built upon the global event database POLECAT. Finally, we benchmark and analyze popular LLMs on the relation prediction task, providing insights into their adaptability and capabilities in complex forecasting scenarios.
What Matters in Deep Learning for Time Series Forecasting?
Dec 27, 2025Deep learning models have grown increasingly popular in time series applications. However, the large quantity of newly proposed architectures, together with often contradictory empirical results, makes it difficult to assess which components contribute significantly to final performance. We aim to make sense of the current design space of deep learning architectures for time series forecasting by discussing the design dimensions and trade-offs that can explain, often unexpected, observed results. This paper discusses the necessity of grounding model design on principles for forecasting groups of time series and how such principles can be applied to current models. In particular, we assess how concepts such as locality and globality apply to recent forecasting architectures. We show that accounting for these aspects can be more relevant for achieving accurate results than adopting specific sequence modeling layers and that simple, well-designed forecasting architectures can often match the state of the art. We discuss how overlooked implementation details in existing architectures (1) fundamentally change the class of the resulting forecasting method and (2) drastically affect the observed empirical results. Our results call for rethinking current faulty benchmarking practices and the need to focus on the foundational aspects of the forecasting problem when designing architectures. As a step in this direction, we propose an auxiliary forecasting model card, whose fields serve to characterize existing and new forecasting architectures based on key design choices.
RefineBridge: Generative Bridge Models Improve Financial Forecasting by Foundation Models
Dec 25, 2025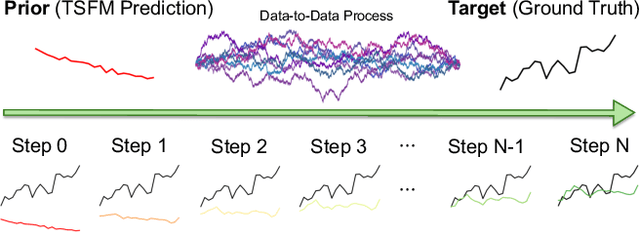
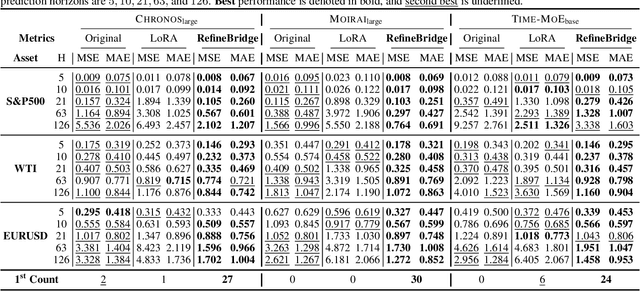
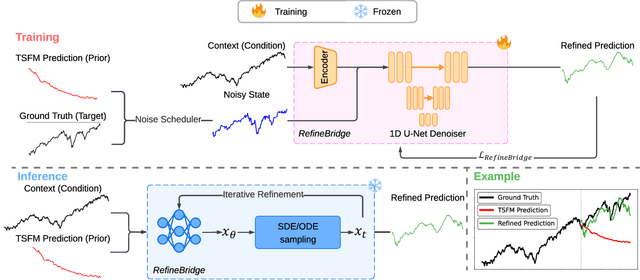
Financial time series forecasting is particularly challenging for transformer-based time series foundation models (TSFMs) due to non-stationarity, heavy-tailed distributions, and high-frequency noise present in data. Low-rank adaptation (LoRA) has become a popular parameter-efficient method for adapting pre-trained TSFMs to downstream data domains. However, it still underperforms in financial data, as it preserves the network architecture and training objective of TSFMs rather than complementing the foundation model. To further enhance TSFMs, we propose a novel refinement module, RefineBridge, built upon a tractable Schrödinger Bridge (SB) generative framework. Given the forecasts of TSFM as generative prior and the observed ground truths as targets, RefineBridge learns context-conditioned stochastic transport maps to improve TSFM predictions, iteratively approaching the ground-truth target from even a low-quality prior. Simulations on multiple financial benchmarks demonstrate that RefineBridge consistently improves the performance of state-of-the-art TSFMs across different prediction horizons.
Explainable time-series forecasting with sampling-free SHAP for Transformers
Dec 23, 2025



Time-series forecasts are essential for planning and decision-making in many domains. Explainability is key to building user trust and meeting transparency requirements. Shapley Additive Explanations (SHAP) is a popular explainable AI framework, but it lacks efficient implementations for time series and often assumes feature independence when sampling counterfactuals. We introduce SHAPformer, an accurate, fast and sampling-free explainable time-series forecasting model based on the Transformer architecture. It leverages attention manipulation to make predictions based on feature subsets. SHAPformer generates explanations in under one second, several orders of magnitude faster than the SHAP Permutation Explainer. On synthetic data with ground truth explanations, SHAPformer provides explanations that are true to the data. Applied to real-world electrical load data, it achieves competitive predictive performance and delivers meaningful local and global insights, such as identifying the past load as the key predictor and revealing a distinct model behavior during the Christmas period.
Electric Vehicle Charging Load Forecasting: An Experimental Comparison of Machine Learning Methods
Dec 19, 2025With the growing popularity of electric vehicles as a means of addressing climate change, concerns have emerged regarding their impact on electric grid management. As a result, predicting EV charging demand has become a timely and important research problem. While substantial research has addressed energy load forecasting in transportation, relatively few studies systematically compare multiple forecasting methods across different temporal horizons and spatial aggregation levels in diverse urban settings. This work investigates the effectiveness of five time series forecasting models, ranging from traditional statistical approaches to machine learning and deep learning methods. Forecasting performance is evaluated for short-, mid-, and long-term horizons (on the order of minutes, hours, and days, respectively), and across spatial scales ranging from individual charging stations to regional and city-level aggregations. The analysis is conducted on four publicly available real-world datasets, with results reported independently for each dataset. To the best of our knowledge, this is the first work to systematically evaluate EV charging demand forecasting across such a wide range of temporal horizons and spatial aggregation levels using multiple real-world datasets.