 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFg Net
Papers and Code
Overcoming Occlusions in the Wild: A Multi-Task Age Head Approach to Age Estimation
Jun 16, 2025Facial age estimation has achieved considerable success under controlled conditions. However, in unconstrained real-world scenarios, which are often referred to as 'in the wild', age estimation remains challenging, especially when faces are partially occluded, which may obscure their visibility. To address this limitation, we propose a new approach integrating generative adversarial networks (GANs) and transformer architectures to enable robust age estimation from occluded faces. We employ an SN-Patch GAN to effectively remove occlusions, while an Attentive Residual Convolution Module (ARCM), paired with a Swin Transformer, enhances feature representation. Additionally, we introduce a Multi-Task Age Head (MTAH) that combines regression and distribution learning, further improving age estimation under occlusion. Experimental results on the FG-NET, UTKFace, and MORPH datasets demonstrate that our proposed approach surpasses existing state-of-the-art techniques for occluded facial age estimation by achieving an MAE of $3.00$, $4.54$, and $2.53$ years, respectively.
FG-Net: Facial Action Unit Detection with Generalizable Pyramidal Features
Aug 23, 2023



Automatic detection of facial Action Units (AUs) allows for objective facial expression analysis. Due to the high cost of AU labeling and the limited size of existing benchmarks, previous AU detection methods tend to overfit the dataset, resulting in a significant performance loss when evaluated across corpora. To address this problem, we propose FG-Net for generalizable facial action unit detection. Specifically, FG-Net extracts feature maps from a StyleGAN2 model pre-trained on a large and diverse face image dataset. Then, these features are used to detect AUs with a Pyramid CNN Interpreter, making the training efficient and capturing essential local features. The proposed FG-Net achieves a strong generalization ability for heatmap-based AU detection thanks to the generalizable and semantic-rich features extracted from the pre-trained generative model. Extensive experiments are conducted to evaluate within- and cross-corpus AU detection with the widely-used DISFA and BP4D datasets. Compared with the state-of-the-art, the proposed method achieves superior cross-domain performance while maintaining competitive within-domain performance. In addition, FG-Net is data-efficient and achieves competitive performance even when trained on 1000 samples. Our code will be released at \url{https://github.com/ihp-lab/FG-Net}
Age Prediction From Face Images Via Contrastive Learning
Aug 23, 2023



This paper presents a novel approach for accurately estimating age from face images, which overcomes the challenge of collecting a large dataset of individuals with the same identity at different ages. Instead, we leverage readily available face datasets of different people at different ages and aim to extract age-related features using contrastive learning. Our method emphasizes these relevant features while suppressing identity-related features using a combination of cosine similarity and triplet margin losses. We demonstrate the effectiveness of our proposed approach by achieving state-of-the-art performance on two public datasets, FG-NET and MORPH-II.
TAA-GCN: A Temporally Aware Adaptive Graph Convolutional Network for Age Estimation
May 15, 2023



This paper proposes a novel age estimation algorithm, the Temporally-Aware Adaptive Graph Convolutional Network (TAA-GCN). Using a new representation based on graphs, the TAA-GCN utilizes skeletal, posture, clothing, and facial information to enrich the feature set associated with various ages. Such a novel graph representation has several advantages: First, reduced sensitivity to facial expression and other appearance variances; Second, robustness to partial occlusion and non-frontal-planar viewpoint, which is commonplace in real-world applications such as video surveillance. The TAA-GCN employs two novel components, (1) the Temporal Memory Module (TMM) to compute temporal dependencies in age; (2) Adaptive Graph Convolutional Layer (AGCL) to refine the graphs and accommodate the variance in appearance. The TAA-GCN outperforms the state-of-the-art methods on four public benchmarks, UTKFace, MORPHII, CACD, and FG-NET. Moreover, the TAA-GCN showed reliability in different camera viewpoints and reduced quality images.
M$^3$Net: Multi-view Encoding, Matching, and Fusion for Few-shot Fine-grained Action Recognition
Aug 06, 2023



Due to the scarcity of manually annotated data required for fine-grained video understanding, few-shot fine-grained (FS-FG) action recognition has gained significant attention, with the aim of classifying novel fine-grained action categories with only a few labeled instances. Despite the progress made in FS coarse-grained action recognition, current approaches encounter two challenges when dealing with the fine-grained action categories: the inability to capture subtle action details and the insufficiency of learning from limited data that exhibit high intra-class variance and inter-class similarity. To address these limitations, we propose M$^3$Net, a matching-based framework for FS-FG action recognition, which incorporates \textit{multi-view encoding}, \textit{multi-view matching}, and \textit{multi-view fusion} to facilitate embedding encoding, similarity matching, and decision making across multiple viewpoints. \textit{Multi-view encoding} captures rich contextual details from the intra-frame, intra-video, and intra-episode perspectives, generating customized higher-order embeddings for fine-grained data. \textit{Multi-view matching} integrates various matching functions enabling flexible relation modeling within limited samples to handle multi-scale spatio-temporal variations by leveraging the instance-specific, category-specific, and task-specific perspectives. \textit{Multi-view fusion} consists of matching-predictions fusion and matching-losses fusion over the above views, where the former promotes mutual complementarity and the latter enhances embedding generalizability by employing multi-task collaborative learning. Explainable visualizations and experimental results on three challenging benchmarks demonstrate the superiority of M$^3$Net in capturing fine-grained action details and achieving state-of-the-art performance for FS-FG action recognition.
FG-Depth: Flow-Guided Unsupervised Monocular Depth Estimation
Jan 20, 2023



The great potential of unsupervised monocular depth estimation has been demonstrated by many works due to low annotation cost and impressive accuracy comparable to supervised methods. To further improve the performance, recent works mainly focus on designing more complex network structures and exploiting extra supervised information, e.g., semantic segmentation. These methods optimize the models by exploiting the reconstructed relationship between the target and reference images in varying degrees. However, previous methods prove that this image reconstruction optimization is prone to get trapped in local minima. In this paper, our core idea is to guide the optimization with prior knowledge from pretrained Flow-Net. And we show that the bottleneck of unsupervised monocular depth estimation can be broken with our simple but effective framework named FG-Depth. In particular, we propose (i) a flow distillation loss to replace the typical photometric loss that limits the capacity of the model and (ii) a prior flow based mask to remove invalid pixels that bring the noise in training loss. Extensive experiments demonstrate the effectiveness of each component, and our approach achieves state-of-the-art results on both KITTI and NYU-Depth-v2 datasets.
Adaptive Mean-Residue Loss for Robust Facial Age Estimation
Mar 31, 2022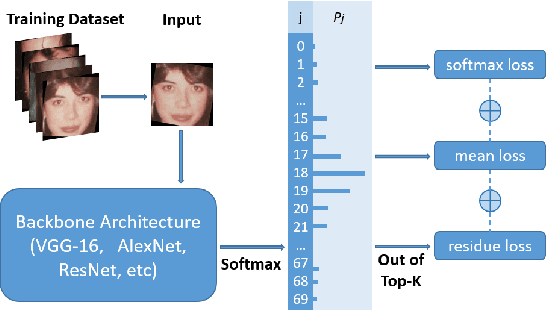
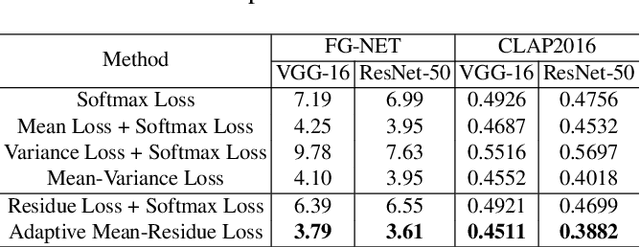
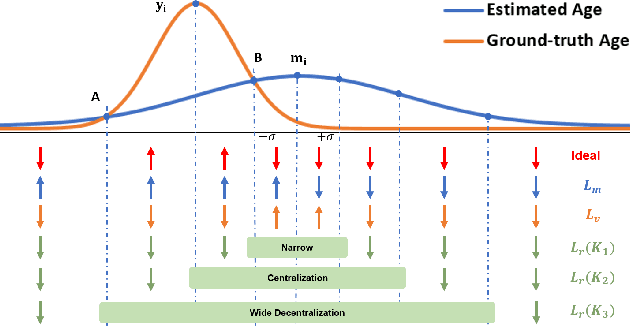
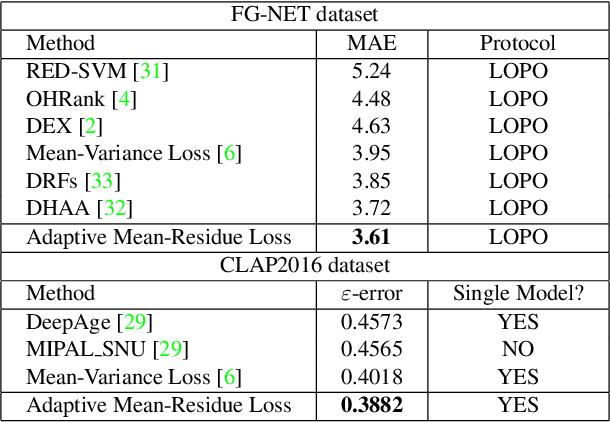
Automated facial age estimation has diverse real-world applications in multimedia analysis, e.g., video surveillance, and human-computer interaction. However, due to the randomness and ambiguity of the aging process, age assessment is challenging. Most research work over the topic regards the task as one of age regression, classification, and ranking problems, and cannot well leverage age distribution in representing labels with age ambiguity. In this work, we propose a simple yet effective loss function for robust facial age estimation via distribution learning, i.e., adaptive mean-residue loss, in which, the mean loss penalizes the difference between the estimated age distribution's mean and the ground-truth age, whereas the residue loss penalizes the entropy of age probability out of dynamic top-K in the distribution. Experimental results in the datasets FG-NET and CLAP2016 have validated the effectiveness of the proposed loss. Our code is available at https://github.com/jacobzhaoziyuan/AMR-Loss.
Applying Artificial Intelligence for Age Estimation in Digital Forensic Investigations
Jan 09, 2022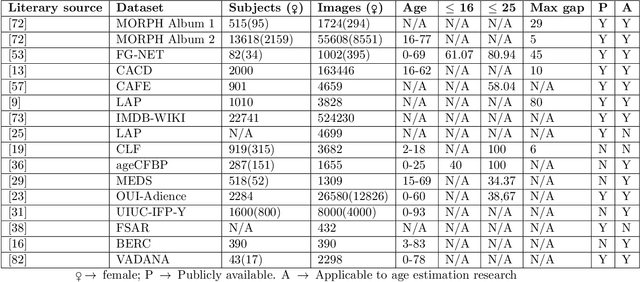
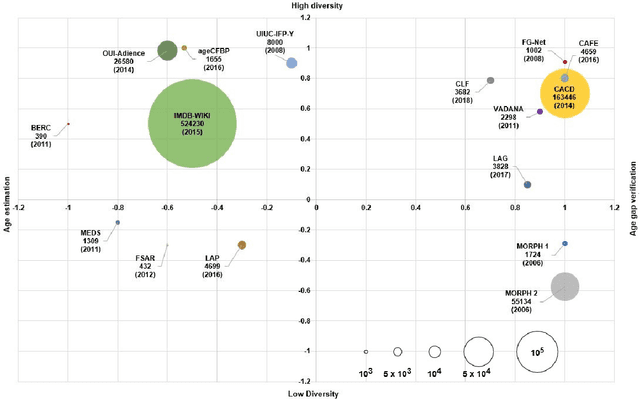

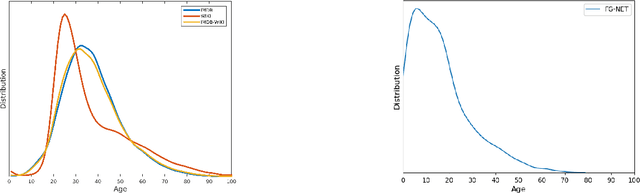
The precise age estimation of child sexual abuse and exploitation (CSAE) victims is one of the most significant digital forensic challenges. Investigators often need to determine the age of victims by looking at images and interpreting the sexual development stages and other human characteristics. The main priority - safeguarding children -- is often negatively impacted by a huge forensic backlog, cognitive bias and the immense psychological stress that this work can entail. This paper evaluates existing facial image datasets and proposes a new dataset tailored to the needs of similar digital forensic research contributions. This small, diverse dataset of 0 to 20-year-old individuals contains 245 images and is merged with 82 unique images from the FG-NET dataset, thus achieving a total of 327 images with high image diversity and low age range density. The new dataset is tested on the Deep EXpectation (DEX) algorithm pre-trained on the IMDB-WIKI dataset. The overall results for young adolescents aged 10 to 15 and older adolescents/adults aged 16 to 20 are very encouraging -- achieving MAEs as low as 1.79, but also suggest that the accuracy for children aged 0 to 10 needs further work. In order to determine the efficacy of the prototype, valuable input of four digital forensic experts, including two forensic investigators, has been taken into account to improve age estimation results. Further research is required to extend datasets both concerning image density and the equal distribution of factors such as gender and racial diversity.
Robust Image Protection Countering Cropping Manipulation
Jun 06, 2022



Image cropping is an inexpensive and effective operation of maliciously altering image contents. Existing cropping detection mechanisms analyze the fundamental traces of image cropping, for example, chromatic aberration and vignetting to uncover cropping attack, yet fragile to common post-processing attacks which deceive forensics by removing such cues. Besides, they ignore the fact that recovering the cropped-out contents can unveil the purpose of the behaved cropping attack. This paper presents a novel robust watermarking scheme for image Cropping Localization and Recovery (CLR-Net). We first protect the original image by introducing imperceptible perturbations. Then, typical image post-processing attacks are simulated to erode the protected image. On the recipient's side, we predict the cropping mask and recover the original image. We propose two plug-and-play networks to improve the real-world robustness of CLR-Net, namely, the Fine-Grained generative JPEG simulator (FG-JPEG) and the Siamese image pre-processing network. To the best of our knowledge, we are the first to address the combined challenge of image cropping localization and entire image recovery from a fragment. Experiments demonstrate that CLR-Net can accurately localize the cropping as well as recover the details of the cropped-out regions with both high quality and fidelity, despite of the presence of image processing attacks of varied types.
Fine-Grained Named Entity Typing over Distantly Supervised Data via Refinement in Hyperbolic Space
Jan 27, 2021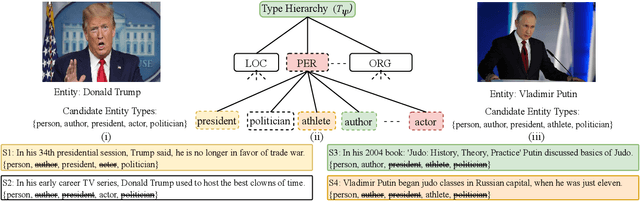
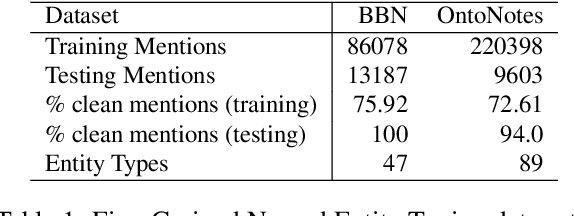
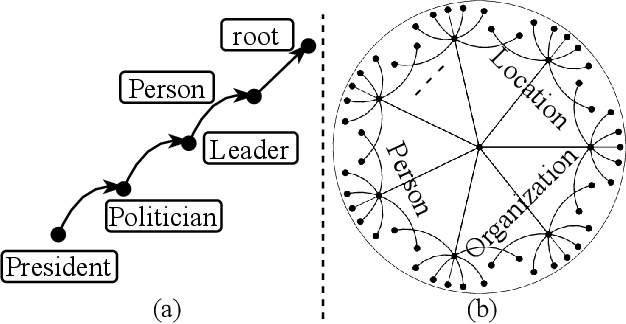
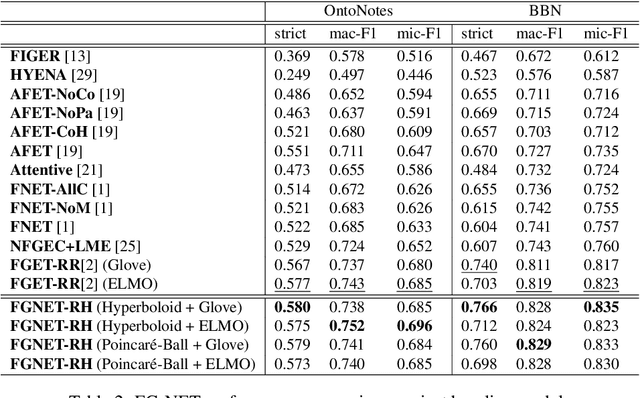
Fine-Grained Named Entity Typing (FG-NET) aims at classifying the entity mentions into a wide range of entity types (usually hundreds) depending upon the context. While distant supervision is the most common way to acquire supervised training data, it brings in label noise, as it assigns type labels to the entity mentions irrespective of mentions' context. In attempts to deal with the label noise, leading research on the FG-NET assumes that the fine-grained entity typing data possesses a euclidean nature, which restraints the ability of the existing models in combating the label noise. Given the fact that the fine-grained type hierarchy exhibits a hierarchal structure, it makes hyperbolic space a natural choice to model the FG-NET data. In this research, we propose FGNET-HR, a novel framework that benefits from the hyperbolic geometry in combination with the graph structures to perform entity typing in a performance-enhanced fashion. FGNET-HR initially uses LSTM networks to encode the mention in relation with its context, later it forms a graph to distill/refine the mention's encodings in the hyperbolic space. Finally, the refined mention encoding is used for entity typing. Experimentation using different benchmark datasets shows that FGNET-HR improves the performance on FG-NET by up to 3.5% in terms of strict accuracy.