 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEMIX: Dual-Encoder Latent Masking Framework for Mixed Noise Reduction in Ultrasound Imaging
Feb 06, 2026Ultrasound imaging is widely used in noninvasive medical diagnostics due to its efficiency, portability, and avoidance of ionizing radiation. However, its utility is limited by the quality of the signal. Signal-dependent speckle noise, signal-independent sensor noise, and non-uniform spatial blurring caused by the transducer and modeled by the point spread function (PSF) degrade the image quality. These degradations challenge conventional image restoration methods, which assume simplified noise models, and highlight the need for specialized algorithms capable of effectively reducing the degradations while preserving fine structural details. We propose DEMIX, a novel dual-encoder denoising framework with a masked gated fusion mechanism, for denoising ultrasound images degraded by mixed noise and further degraded by PSF-induced distortions. DEMIX is inspired by diffusion models and is characterized by a forward process and a deterministic reverse process. DEMIX adaptively assesses the different noise components, disentangles them in the latent space, and suppresses these components while compensating for PSF degradations. Extensive experiments on two ultrasound datasets, along with a downstream segmentation task, demonstrate that DEMIX consistently outperforms state-of-the-art baselines, achieving superior noise suppression and preserving structural details. The code will be made publicly available.
Deep Temporal Sequence Classification and Mathematical Modeling for Cell Tracking in Dense 3D Microscopy Videos of Bacterial Biofilms
Jun 27, 2024Automatic cell tracking in dense environments is plagued by inaccurate correspondences and misidentification of parent-offspring relationships. In this paper, we introduce a novel cell tracking algorithm named DenseTrack, which integrates deep learning with mathematical model-based strategies to effectively establish correspondences between consecutive frames and detect cell division events in crowded scenarios. We formulate the cell tracking problem as a deep learning-based temporal sequence classification task followed by solving a constrained one-to-one matching optimization problem exploiting the classifier's confidence scores. Additionally, we present an eigendecomposition-based cell division detection strategy that leverages knowledge of cellular geometry. The performance of the proposed approach has been evaluated by tracking densely packed cells in 3D time-lapse image sequences of bacterial biofilm development. The experimental results on simulated as well as experimental fluorescence image sequences suggest that the proposed tracking method achieves superior performance in terms of both qualitative and quantitative evaluation measures compared to recent state-of-the-art cell tracking approaches.
A Semantic and Motion-Aware Spatiotemporal Transformer Network for Action Detection
May 13, 2024



This paper presents a novel spatiotemporal transformer network that introduces several original components to detect actions in untrimmed videos. First, the multi-feature selective semantic attention model calculates the correlations between spatial and motion features to model spatiotemporal interactions between different action semantics properly. Second, the motion-aware network encodes the locations of action semantics in video frames utilizing the motion-aware 2D positional encoding algorithm. Such a motion-aware mechanism memorizes the dynamic spatiotemporal variations in action frames that current methods cannot exploit. Third, the sequence-based temporal attention model captures the heterogeneous temporal dependencies in action frames. In contrast to standard temporal attention used in natural language processing, primarily aimed at finding similarities between linguistic words, the proposed sequence-based temporal attention is designed to determine both the differences and similarities between video frames that jointly define the meaning of actions. The proposed approach outperforms the state-of-the-art solutions on four spatiotemporal action datasets: AVA 2.2, AVA 2.1, UCF101-24, and EPIC-Kitchens.
SDDPM: Speckle Denoising Diffusion Probabilistic Models
Nov 17, 2023



Coherent imaging systems, such as medical ultrasound and synthetic aperture radar (SAR), are subject to corruption from speckle due to sub-resolution scatterers. Since speckle is multiplicative in nature, the constituent image regions become corrupted to different extents. The task of denoising such images requires algorithms specifically designed for removing signal-dependent noise. This paper proposes a novel image denoising algorithm for removing signal-dependent multiplicative noise with diffusion models, called Speckle Denoising Diffusion Probabilistic Models (SDDPM). We derive the mathematical formulations for the forward process, the reverse process, and the training objective. In the forward process, we apply multiplicative noise to a given image and prove that the forward process is Gaussian. We show that the reverse process is also Gaussian and the final training objective can be expressed as the Kullback Leibler (KL) divergence between the forward and reverse processes. As derived in the paper, the final denoising task is a single step process, thereby reducing the denoising time significantly. We have trained our model with natural land-use images and ultrasound images for different noise levels. Extensive experiments centered around two different applications show that SDDPM is robust and performs significantly better than the comparative models even when the images are severely corrupted.
A Multi-Modal Transformer Network for Action Detection
May 31, 2023



This paper proposes a novel multi-modal transformer network for detecting actions in untrimmed videos. To enrich the action features, our transformer network utilizes a new multi-modal attention mechanism that computes the correlations between different spatial and motion modalities combinations. Exploring such correlations for actions has not been attempted previously. To use the motion and spatial modality more effectively, we suggest an algorithm that corrects the motion distortion caused by camera movement. Such motion distortion, common in untrimmed videos, severely reduces the expressive power of motion features such as optical flow fields. Our proposed algorithm outperforms the state-of-the-art methods on two public benchmarks, THUMOS14 and ActivityNet. We also conducted comparative experiments on our new instructional activity dataset, including a large set of challenging classroom videos captured from elementary schools.
TAA-GCN: A Temporally Aware Adaptive Graph Convolutional Network for Age Estimation
May 15, 2023



This paper proposes a novel age estimation algorithm, the Temporally-Aware Adaptive Graph Convolutional Network (TAA-GCN). Using a new representation based on graphs, the TAA-GCN utilizes skeletal, posture, clothing, and facial information to enrich the feature set associated with various ages. Such a novel graph representation has several advantages: First, reduced sensitivity to facial expression and other appearance variances; Second, robustness to partial occlusion and non-frontal-planar viewpoint, which is commonplace in real-world applications such as video surveillance. The TAA-GCN employs two novel components, (1) the Temporal Memory Module (TMM) to compute temporal dependencies in age; (2) Adaptive Graph Convolutional Layer (AGCL) to refine the graphs and accommodate the variance in appearance. The TAA-GCN outperforms the state-of-the-art methods on four public benchmarks, UTKFace, MORPHII, CACD, and FG-NET. Moreover, the TAA-GCN showed reliability in different camera viewpoints and reduced quality images.
An Efficient Convolutional Neural Network for Coronary Heart Disease Prediction
Sep 01, 2019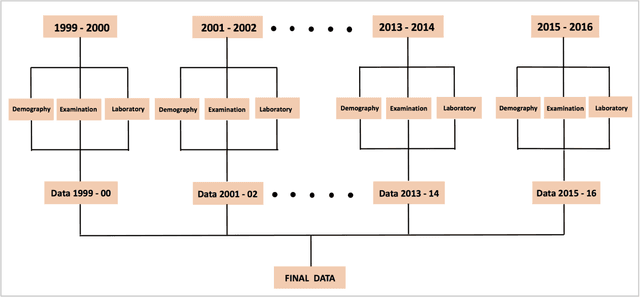
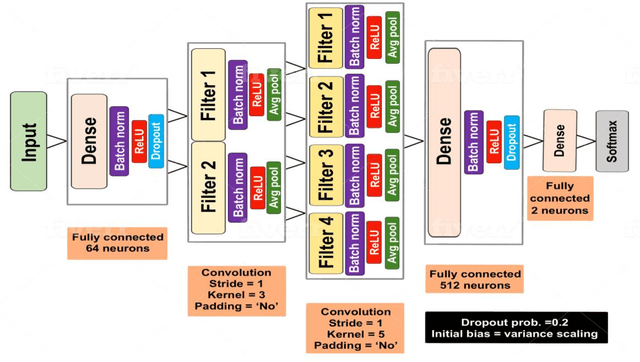
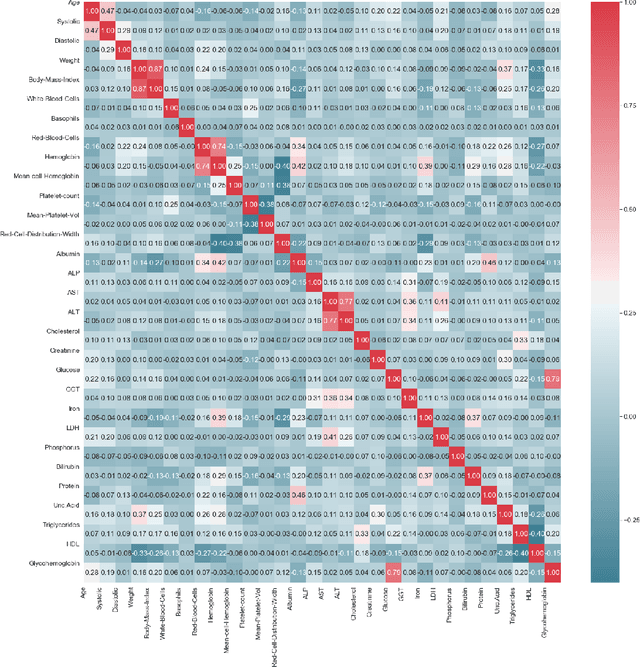
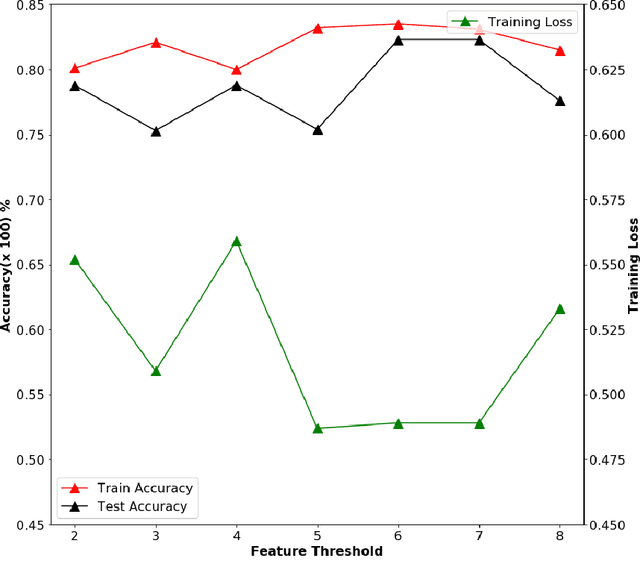
This study proposes an efficient neural network with convolutional layers to classify significantly class-imbalanced clinical data. The data are curated from the National Health and Nutritional Examination Survey (NHANES) with the goal of predicting the occurrence of Coronary Heart Disease (CHD). While the majority of the existing machine learning models that have been used on this class of data are vulnerable to class imbalance even after the adjustment of class-specific weights, our simple two-layer CNN exhibits resilience to the imbalance with fair harmony in class-specific performance. In order to obtain significant improvement in classification accuracy under supervised learning settings, it is a common practice to train a neural network architecture with a massive data and thereafter, test the resulting network on a comparatively smaller amount of data. However, given a highly imbalanced dataset, it is often challenging to achieve a high class 1 (true CHD prediction rate) accuracy as the testing data size increases. We adopt a two-step approach: first, we employ least absolute shrinkage and selection operator (LASSO) based feature weight assessment followed by majority-voting based identification of important features. Next, the important features are homogenized by using a fully connected layer, a crucial step before passing the output of the layer to successive convolutional stages. We also propose a training routine per epoch, akin to a simulated annealing process, to boost the classification accuracy. Despite a 35:1 (Non-CHD:CHD) ratio in the NHANES dataset, the investigation confirms that our proposed CNN architecture has the classification power of 77% to correctly classify the presence of CHD and 81.8% the absence of CHD cases on a testing data, which is 85.70% of the total dataset. ( (<1920 characters)Please check the paper for full abstract)
GlidarCo: gait recognition by 3D skeleton estimation and biometric feature correction of flash lidar data
May 20, 2019
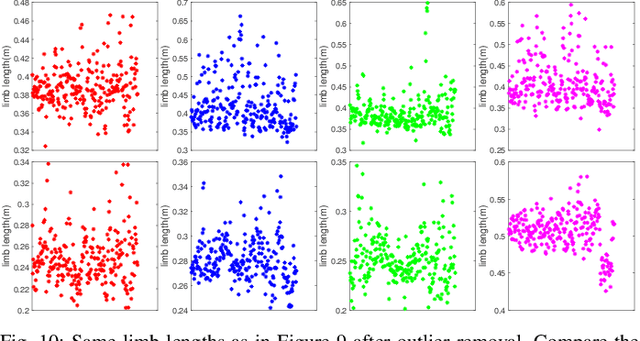
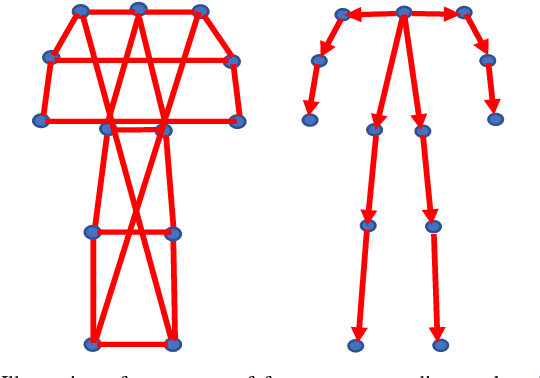
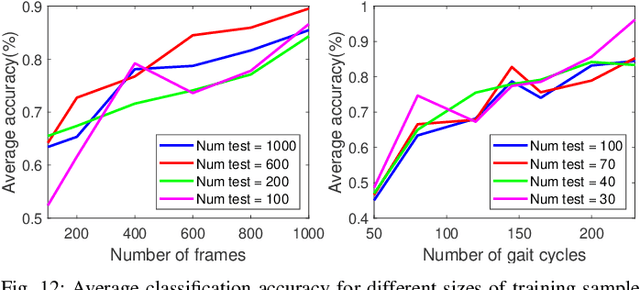
Gait recognition using noninvasively acquired data has been attracting an increasing interest in the last decade. Among various modalities of data sources, it is experimentally found that the data involving skeletal representation are amenable for reliable feature compaction and fast processing. Model-based gait recognition methods that exploit features from a fitted model, like skeleton, are recognized for their view and scale-invariant properties. We propose a model-based gait recognition method, using sequences recorded by a single flash lidar. Existing state-of-the-art model-based approaches that exploit features from high quality skeletal data collected by Kinect and Mocap are limited to controlled laboratory environments. The performance of conventional research efforts is negatively affected by poor data quality. We address the problem of gait recognition under challenging scenarios, such as lower quality and noisy imaging process of lidar, that degrades the performance of state-of-the-art skeleton-based systems. We present GlidarCo to attain high accuracy on gait recognition under the described conditions. A filtering mechanism corrects faulty skeleton joint measurements, and robust statistics are integrated to conventional feature moments to encode the dynamic of the motion. As a comparison, length-based and vector-based features extracted from the noisy skeletons are investigated for outlier removal. Experimental results illustrate the efficacy of the proposed methodology in improving gait recognition given noisy low resolution lidar data.