 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Occlusions in the Wild: A Multi-Task Age Head Approach to Age Estimation
Jun 16, 2025Facial age estimation has achieved considerable success under controlled conditions. However, in unconstrained real-world scenarios, which are often referred to as 'in the wild', age estimation remains challenging, especially when faces are partially occluded, which may obscure their visibility. To address this limitation, we propose a new approach integrating generative adversarial networks (GANs) and transformer architectures to enable robust age estimation from occluded faces. We employ an SN-Patch GAN to effectively remove occlusions, while an Attentive Residual Convolution Module (ARCM), paired with a Swin Transformer, enhances feature representation. Additionally, we introduce a Multi-Task Age Head (MTAH) that combines regression and distribution learning, further improving age estimation under occlusion. Experimental results on the FG-NET, UTKFace, and MORPH datasets demonstrate that our proposed approach surpasses existing state-of-the-art techniques for occluded facial age estimation by achieving an MAE of $3.00$, $4.54$, and $2.53$ years, respectively.
MeWEHV: Mel and Wave Embeddings for Human Voice Tasks
Sep 28, 2022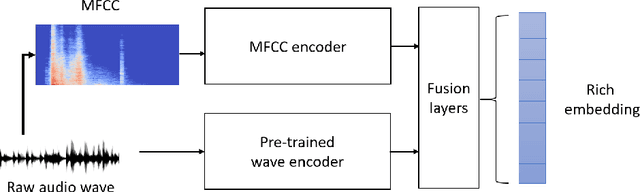
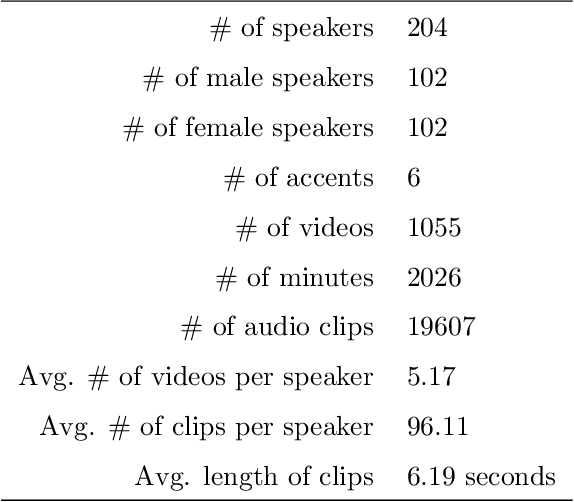
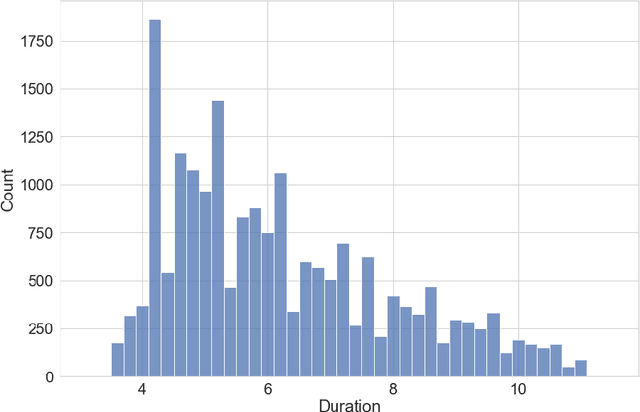
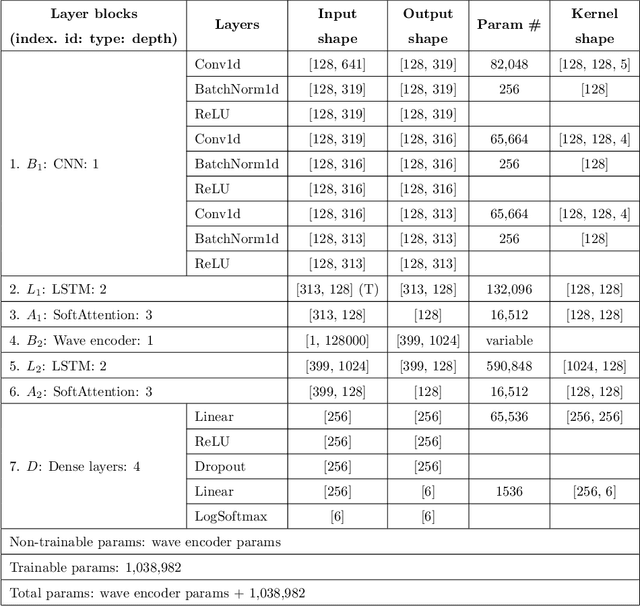
A recent trend in speech processing is the use of embeddings created through machine learning models trained on a specific task with large datasets. By leveraging the knowledge already acquired, these models can be reused in new tasks where the amount of available data is small. This paper proposes a pipeline to create a new model, called Mel and Wave Embeddings for Human Voice Tasks (MeWEHV), capable of generating robust embeddings for speech processing. MeWEHV combines the embeddings generated by a pre-trained raw audio waveform encoder model, and deep features extracted from Mel Frequency Cepstral Coefficients (MFCCs) using Convolutional Neural Networks (CNNs). We evaluate the performance of MeWEHV on three tasks: speaker, language, and accent identification. For the first one, we use the VoxCeleb1 dataset and present YouSpeakers204, a new and publicly available dataset for English speaker identification that contains 19607 audio clips from 204 persons speaking in six different accents, allowing other researchers to work with a very balanced dataset, and to create new models that are robust to multiple accents. For evaluating the language identification task, we use the VoxForge and Common Language datasets. Finally, for accent identification, we use the Latin American Spanish Corpora (LASC) and Common Voice datasets. Our approach allows a significant increase in the performance of state-of-the-art models on all the tested datasets, with a low additional computational cost.