 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDidi Dataset
Papers and Code
EdgeDAM: Real-time Object Tracking for Mobile Devices
Mar 05, 2026Single-object tracking (SOT) on edge devices is a critical computer vision task, requiring accurate and continuous target localization across video frames under occlusion, distractor interference, and fast motion. However, recent state-of-the-art distractor-aware memory mechanisms are largely built on segmentation-based trackers and rely on mask prediction and attention-driven memory updates, which introduce substantial computational overhead and limit real-time deployment on resource-constrained hardware; meanwhile, lightweight trackers sustain high throughput but are prone to drift when visually similar distractors appear. To address these challenges, we propose EdgeDAM, a lightweight detection-guided tracking framework that reformulates distractor-aware memory for bounding-box tracking under strict edge constraints. EdgeDAM introduces two key strategies: (1) Dual-Buffer Distractor-Aware Memory (DAM), which integrates a Recent-Aware Memory to preserve temporally consistent target hypotheses and a Distractor-Resolving Memory to explicitly store hard negative candidates and penalize their re-selection during recovery; and (2) Confidence-Driven Switching with Held-Box Stabilization, where tracker reliability and temporal consistency criteria adaptively activate detection and memory-guided re-identification during occlusion, while a held-box mechanism temporarily freezes and expands the estimate to suppress distractor contamination. Extensive experiments on five benchmarks, including the distractor-focused DiDi dataset, demonstrate improved robustness under occlusion and fast motion while maintaining real-time performance on mobile devices, achieving 88.2% accuracy on DiDi and 25 FPS on an iPhone 15. Code will be released.
Enhancing Ride-Hailing Forecasting at DiDi with Multi-View Geospatial Representation Learning from the Web
Feb 11, 2026The proliferation of ride-hailing services has fundamentally transformed urban mobility patterns, making accurate ride-hailing forecasting crucial for optimizing passenger experience and urban transportation efficiency. However, ride-hailing forecasting faces significant challenges due to geospatial heterogeneity and high susceptibility to external events. This paper proposes MVGR-Net(Multi-View Geospatial Representation Learning), a novel framework that addresses these challenges through a two-stage approach. In the pretraining stage, we learn comprehensive geospatial representations by integrating Points-of-Interest and temporal mobility patterns to capture regional characteristics from both semantic attribute and temporal mobility pattern views. The forecasting stage leverages these representations through a prompt-empowered framework that fine-tunes Large Language Models while incorporating external events. Extensive experiments on DiDi's real-world datasets demonstrate the state-of-the-art performance.
MixTTE: Multi-Level Mixture-of-Experts for Scalable and Adaptive Travel Time Estimation
Jan 06, 2026Accurate Travel Time Estimation (TTE) is critical for ride-hailing platforms, where errors directly impact user experience and operational efficiency. While existing production systems excel at holistic route-level dependency modeling, they struggle to capture city-scale traffic dynamics and long-tail scenarios, leading to unreliable predictions in large urban networks. In this paper, we propose \model, a scalable and adaptive framework that synergistically integrates link-level modeling with industrial route-level TTE systems. Specifically, we propose a spatio-temporal external attention module to capture global traffic dynamic dependencies across million-scale road networks efficiently. Moreover, we construct a stabilized graph mixture-of-experts network to handle heterogeneous traffic patterns while maintaining inference efficiency. Furthermore, an asynchronous incremental learning strategy is tailored to enable real-time and stable adaptation to dynamic traffic distribution shifts. Experiments on real-world datasets validate MixTTE significantly reduces prediction errors compared to seven baselines. MixTTE has been deployed in DiDi, substantially improving the accuracy and stability of the TTE service.
Distractor-Aware Memory-Based Visual Object Tracking
Sep 17, 2025
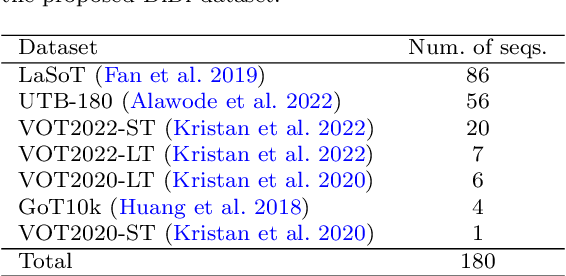

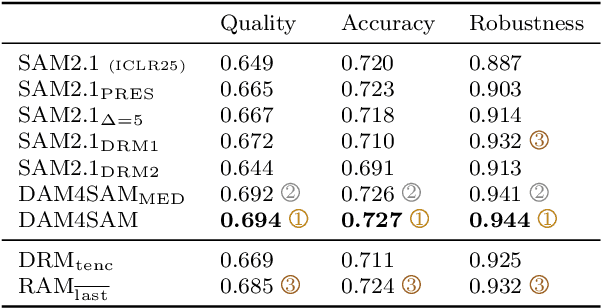
Recent emergence of memory-based video segmentation methods such as SAM2 has led to models with excellent performance in segmentation tasks, achieving leading results on numerous benchmarks. However, these modes are not fully adjusted for visual object tracking, where distractors (i.e., objects visually similar to the target) pose a key challenge. In this paper we propose a distractor-aware drop-in memory module and introspection-based management method for SAM2, leading to DAM4SAM. Our design effectively reduces the tracking drift toward distractors and improves redetection capability after object occlusion. To facilitate the analysis of tracking in the presence of distractors, we construct DiDi, a Distractor-Distilled dataset. DAM4SAM outperforms SAM2.1 on thirteen benchmarks and sets new state-of-the-art results on ten. Furthermore, integrating the proposed distractor-aware memory into a real-time tracker EfficientTAM leads to 11% improvement and matches tracking quality of the non-real-time SAM2.1-L on multiple tracking and segmentation benchmarks, while integration with edge-based tracker EdgeTAM delivers 4% performance boost, demonstrating a very good generalization across architectures.
A Distractor-Aware Memory for Visual Object Tracking with SAM2
Nov 26, 2024Memory-based trackers are video object segmentation methods that form the target model by concatenating recently tracked frames into a memory buffer and localize the target by attending the current image to the buffered frames. While already achieving top performance on many benchmarks, it was the recent release of SAM2 that placed memory-based trackers into focus of the visual object tracking community. Nevertheless, modern trackers still struggle in the presence of distractors. We argue that a more sophisticated memory model is required, and propose a new distractor-aware memory model for SAM2 and an introspection-based update strategy that jointly addresses the segmentation accuracy as well as tracking robustness. The resulting tracker is denoted as SAM2.1++. We also propose a new distractor-distilled DiDi dataset to study the distractor problem better. SAM2.1++ outperforms SAM2.1 and related SAM memory extensions on seven benchmarks and sets a solid new state-of-the-art on six of them.
Interpretable Cascading Mixture-of-Experts for Urban Traffic Congestion Prediction
Jun 14, 2024



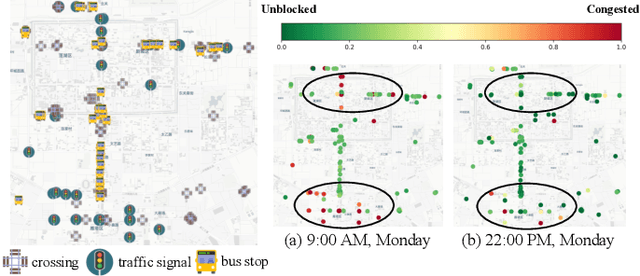
Rapid urbanization has significantly escalated traffic congestion, underscoring the need for advanced congestion prediction services to bolster intelligent transportation systems. As one of the world's largest ride-hailing platforms, DiDi places great emphasis on the accuracy of congestion prediction to enhance the effectiveness and reliability of their real-time services, such as travel time estimation and route planning. Despite numerous efforts have been made on congestion prediction, most of them fall short in handling heterogeneous and dynamic spatio-temporal dependencies (e.g., periodic and non-periodic congestions), particularly in the presence of noisy and incomplete traffic data. In this paper, we introduce a Congestion Prediction Mixture-of-Experts, CP-MoE, to address the above challenges. We first propose a sparsely-gated Mixture of Adaptive Graph Learners (MAGLs) with congestion-aware inductive biases to improve the model capacity for efficiently capturing complex spatio-temporal dependencies in varying traffic scenarios. Then, we devise two specialized experts to help identify stable trends and periodic patterns within the traffic data, respectively. By cascading these experts with MAGLs, CP-MoE delivers congestion predictions in a more robust and interpretable manner. Furthermore, an ordinal regression strategy is adopted to facilitate effective collaboration among diverse experts. Extensive experiments on real-world datasets demonstrate the superiority of our proposed method compared with state-of-the-art spatio-temporal prediction models. More importantly, CP-MoE has been deployed in DiDi to improve the accuracy and reliability of the travel time estimation system.
GOF-TTE: Generative Online Federated Learning Framework for Travel Time Estimation
Jul 02, 2022
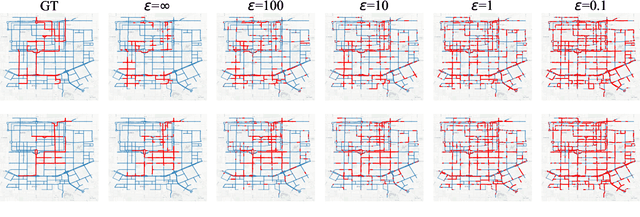
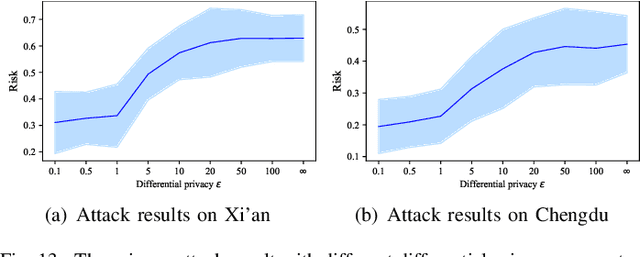
Estimating the travel time of a path is an essential topic for intelligent transportation systems. It serves as the foundation for real-world applications, such as traffic monitoring, route planning, and taxi dispatching. However, building a model for such a data-driven task requires a large amount of users' travel information, which directly relates to their privacy and thus is less likely to be shared. The non-Independent and Identically Distributed (non-IID) trajectory data across data owners also make a predictive model extremely challenging to be personalized if we directly apply federated learning. Finally, previous work on travel time estimation does not consider the real-time traffic state of roads, which we argue can significantly influence the prediction. To address the above challenges, we introduce GOF-TTE for the mobile user group, Generative Online Federated Learning Framework for Travel Time Estimation, which I) utilizes the federated learning approach, allowing private data to be kept on client devices while training, and designs the global model as an online generative model shared by all clients to infer the real-time road traffic state. II) apart from sharing a base model at the server, adapts a fine-tuned personalized model for every client to study their personal driving habits, making up for the residual error made by localized global model prediction. % III) designs the global model as an online generative model shared by all clients to infer the real-time road traffic state. We also employ a simple privacy attack to our framework and implement the differential privacy mechanism to further guarantee privacy safety. Finally, we conduct experiments on two real-world public taxi datasets of DiDi Chengdu and Xi'an. The experimental results demonstrate the effectiveness of our proposed framework.
Evaluating Dynamic Conditional Quantile Treatment Effects with Applications in Ridesharing
May 17, 2023



Many modern tech companies, such as Google, Uber, and Didi, utilize online experiments (also known as A/B testing) to evaluate new policies against existing ones. While most studies concentrate on average treatment effects, situations with skewed and heavy-tailed outcome distributions may benefit from alternative criteria, such as quantiles. However, assessing dynamic quantile treatment effects (QTE) remains a challenge, particularly when dealing with data from ride-sourcing platforms that involve sequential decision-making across time and space. In this paper, we establish a formal framework to calculate QTE conditional on characteristics independent of the treatment. Under specific model assumptions, we demonstrate that the dynamic conditional QTE (CQTE) equals the sum of individual CQTEs across time, even though the conditional quantile of cumulative rewards may not necessarily equate to the sum of conditional quantiles of individual rewards. This crucial insight significantly streamlines the estimation and inference processes for our target causal estimand. We then introduce two varying coefficient decision process (VCDP) models and devise an innovative method to test the dynamic CQTE. Moreover, we expand our approach to accommodate data from spatiotemporal dependent experiments and examine both conditional quantile direct and indirect effects. To showcase the practical utility of our method, we apply it to three real-world datasets from a ride-sourcing platform. Theoretical findings and comprehensive simulation studies further substantiate our proposal.
Learning to integrate vision data into road network data
Dec 20, 2021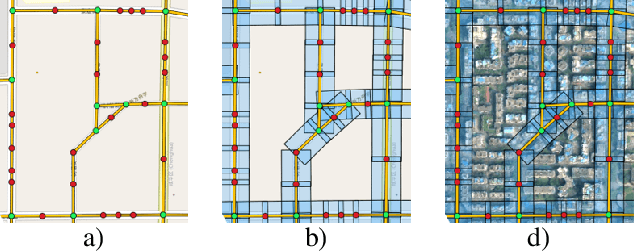
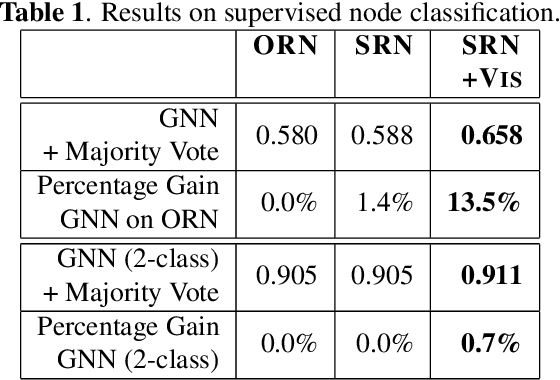
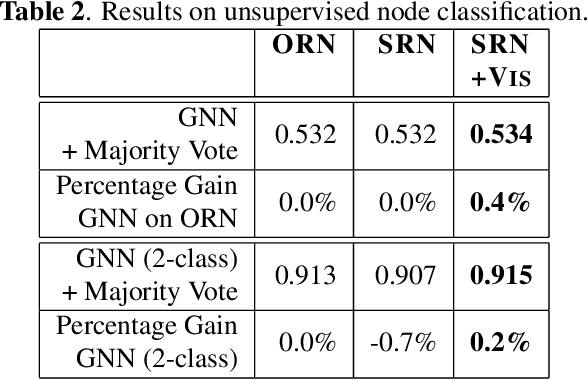
Road networks are the core infrastructure for connected and autonomous vehicles, but creating meaningful representations for machine learning applications is a challenging task. In this work, we propose to integrate remote sensing vision data into road network data for improved embeddings with graph neural networks. We present a segmentation of road edges based on spatio-temporal road and traffic characteristics, which allows to enrich the attribute set of road networks with visual features of satellite imagery and digital surface models. We show that both, the segmentation and the integration of vision data can increase performance on a road type classification task, and we achieve state-of-the-art performance on the OSM+DiDi Chuxing dataset on Chengdu, China.
GCF: Generalized Causal Forest for Heterogeneous Treatment Effect Estimation in Online Marketplace
Mar 21, 2022

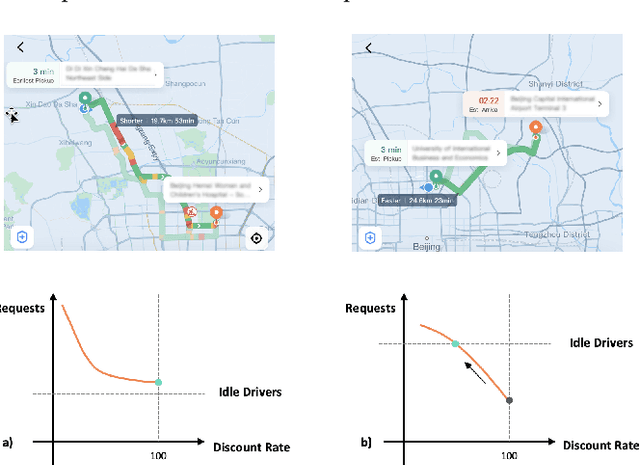
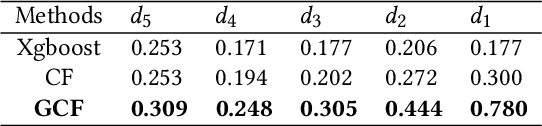
Uplift modeling is a rapidly growing approach that utilizes machine learning and causal inference methods to estimate the heterogeneous treatment effects. It has been widely adopted and applied to online marketplaces to assist large-scale decision-making in recent years. The existing popular methods, like forest-based modeling, either work only for discrete treatments or make partially linear or parametric assumptions that may suffer from model misspecification. To alleviate these problems, we extend causal forest (CF) with non-parametric dose-response functions (DRFs) that can be estimated locally using a kernel-based doubly robust estimator. Moreover, we propose a distance-based splitting criterion in the functional space of conditional DRFs to capture the heterogeneity for the continuous treatments. We call the proposed algorithm generalized causal forest (GCF) as it generalizes the use case of CF to a much broader setup. We show the effectiveness of GCF by comparing it to popular uplift modeling models on both synthetic and real-world datasets. We implement GCF in Spark and successfully deploy it into DiDi's real-time pricing system. Online A/B testing results further validate the superiority of GCF.