 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrime Prediction
Crime prediction, also known as predictive policing, is the forecasting of future criminal activities based on analysis of historical crime data and other relevant factors. The goal is to help law enforcement agencies prevent crimes before they happen by identifying trends and patterns based on past crimes and forecasting where and when crime is likely to occur.
Papers and Code
Decoupled Sensitivity-Consistency Learning for Weakly Supervised Video Anomaly Detection
Mar 20, 2026Recent weakly supervised video anomaly detection methods have achieved significant advances by employing unified frameworks for joint optimization. However, this paradigm is limited by a fundamental sensitivity-stability trade-off, as the conflicting objectives for detecting transient and sustained anomalies lead to either fragmented predictions or over-smoothed responses. To address this limitation, we propose DeSC, a novel Decoupled Sensitivity-Consistency framework that trains two specialized streams using distinct optimization strategies. The temporal sensitivity stream adopts an aggressive optimization strategy to capture high-frequency abrupt changes, whereas the semantic consistency stream applies robust constraints to maintain long-term coherence and reduce noise. Their complementary strengths are fused through a collaborative inference mechanism that reduces individual biases and produces balanced predictions. Extensive experiments demonstrate that DeSC establishes new state-of-the-art performance by achieving 89.37% AUC on UCF-Crime (+1.29%) and 87.18% AP on XD-Violence (+2.22%). Code is available at https://github.com/imzht/DeSC.
Unmasking Algorithmic Bias in Predictive Policing: A GAN-Based Simulation Framework with Multi-City Temporal Analysis
Mar 19, 2026Predictive policing systems that direct patrol resources based on algorithmically generated crime forecasts have been widely deployed across US cities, yet their tendency to encode and amplify racial disparities remains poorly understood in quantitative terms. We present a reproducible simulation framework that couples a Generative Adversarial Network GAN with a Noisy OR patrol detection model to measure how racial bias propagates through the full enforcement pipeline from crime occurrence to police contact. Using 145000 plus Part 1 crime records from Baltimore 2017 to 2019 and 233000 plus records from Chicago 2022, augmented with US Census ACS demographic data, we compute four monthly bias metrics across 264 city year mode observations: the Disparate Impact Ratio DIR, Demographic Parity Gap, Gini Coefficient, and a composite Bias Amplification Score. Our experiments reveal extreme and year variant bias in Baltimores detected mode, with mean annual DIR up to 15714 in 2019, moderate under detection of Black residents in Chicago DIR equals 0.22, and persistent Gini coefficients of 0.43 to 0.62 across all conditions. We further demonstrate that a Conditional Tabular GAN CTGAN debiasing approach partially redistributes detection rates but cannot eliminate structural disparity without accompanying policy intervention. Socioeconomic regression analysis confirms strong correlations between neighborhood racial composition and detection likelihood Pearson r equals 0.83 for percent White and r equals negative 0.81 for percent Black. A sensitivity analysis over patrol radius, officer count, and citizen reporting probability reveals that outcomes are most sensitive to officer deployment levels. The code and data are publicly available at this repository.
Predictive Hotspot Mapping for Data-driven Crime Prediction
Feb 27, 2026Predictive hotspot mapping is an important problem in crime prediction and control. An accurate hotspot mapping helps in appropriately targeting the available resources to manage crime in cities. With an aim to make data-driven decisions and automate policing and patrolling operations, police departments across the world are moving towards predictive approaches relying on historical data. In this paper, we create a non-parametric model using a spatio-temporal kernel density formulation for the purpose of crime prediction based on historical data. The proposed approach is also able to incorporate expert inputs coming from humans through alternate sources. The approach has been extensively evaluated in a real-world setting by collaborating with the Delhi police department to make crime predictions that would help in effective assignment of patrol vehicles to control street crime. The results obtained in the paper are promising and can be easily applied in other settings. We release the algorithm and the dataset (masked) used in our study to support future research that will be useful in achieving further improvements.
Geometry-Aware Semantic Reasoning for Training Free Video Anomaly Detection
Mar 10, 2026Training-free video anomaly detection (VAD) has recently emerged as a scalable alternative to supervised approaches, yet existing methods largely rely on static prompting and geometry-agnostic feature fusion. As a result, anomaly inference is often reduced to shallow similarity matching over Euclidean embeddings, leading to unstable predictions and limited interpretability, especially in complex or hierarchically structured scenes. We introduce MM-VAD, a geometry-aware semantic reasoning framework for training free VAD that reframes anomaly detection as adaptive test-time inference rather than fixed feature comparison. Our approach projects caption-derived scene representations into hyperbolic space to better preserve hierarchical structure and performs anomaly assessment through an adaptive question answering process over a frozen large language model. A lightweight, learnable prompt is optimised at test time using an unsupervised confidence-sparsity objective, enabling context-specific calibration without updating any backbone parameters. To further ground semantic predictions in visual evidence, we incorporate a covariance-aware Mahalanobis refinement that stabilises cross-modal alignment. Across four benchmarks, MM-VAD consistently improves over prior training-free methods, achieving 90.03% AUC on XD-Violence and 83.24%, 96.95%, and 98.81% on UCF-Crime, ShanghaiTech, and UCSD Ped2, respectively. Our results demonstrate that geometry-aware representation and adaptive semantic calibration provide a principled and effective alternative to static Euclidean matching in training-free VAD.
ToPT: Task-Oriented Prompt Tuning for Urban Region Representation Learning
Feb 02, 2026Learning effective region embeddings from heterogeneous urban data underpins key urban computing tasks (e.g., crime prediction, resource allocation). However, prevailing two-stage methods yield task-agnostic representations, decoupling them from downstream objectives. Recent prompt-based approaches attempt to fix this but introduce two challenges: they often lack explicit spatial priors, causing spatially incoherent inter-region modeling, and they lack robust mechanisms for explicit task-semantic alignment. We propose ToPT, a two-stage framework that delivers spatially consistent fusion and explicit task alignment. ToPT consists of two modules: spatial-aware region embedding learning (SREL) and task-aware prompting for region embeddings (Prompt4RE). SREL employs a Graphormer-based fusion module that injects spatial priors-distance and regional centrality-as learnable attention biases to capture coherent, interpretable inter-region interactions. Prompt4RE performs task-oriented prompting: a frozen multimodal large language model (MLLM) processes task-specific templates to obtain semantic vectors, which are aligned with region embeddings via multi-head cross-attention for stable task conditioning. Experiments across multiple tasks and cities show state-of-the-art performance, with improvements of up to 64.2\%, validating the necessity and complementarity of spatial priors and prompt-region alignment. The code is available at https://github.com/townSeven/Prompt4RE.git.
Logic-Guided Multistage Inference for Explainable Multidefendant Judgment Prediction
Jan 19, 2026Crime disrupts societal stability, making law essential for balance. In multidefendant cases, assigning responsibility is complex and challenges fairness, requiring precise role differentiation. However, judicial phrasing often obscures the roles of the defendants, hindering effective AI-driven analyses. To address this issue, we incorporate sentencing logic into a pretrained Transformer encoder framework to enhance the intelligent assistance in multidefendant cases while ensuring legal interpretability. Within this framework an oriented masking mechanism clarifies roles and a comparative data construction strategy improves the model's sensitivity to culpability distinctions between principals and accomplices. Predicted guilt labels are further incorporated into a regression model through broadcasting, consolidating crime descriptions and court views. Our proposed masked multistage inference (MMSI) framework, evaluated on the custom IMLJP dataset for intentional injury cases, achieves significant accuracy improvements, outperforming baselines in role-based culpability differentiation. This work offers a robust solution for enhancing intelligent judicial systems, with publicly code available.
Failing on Bias Mitigation: Investigating Why Predictive Models Struggle with Government Data
Jan 21, 2026The potential for bias and unfairness in AI-supporting government services raises ethical and legal concerns. Using crime rate prediction with the Bristol City Council data as a case study, we examine how these issues persist. Rather than auditing real-world deployed systems, our goal is to understand why widely adopted bias mitigation techniques often fail when applied to government data. Our findings reveal that bias mitigation approaches applied to government data are not always effective -- not because of flaws in model architecture or metric selection, but due to the inherent properties of the data itself. Through comparing a set of comprehensive models and fairness methods, our experiments consistently show that the mitigation efforts cannot overcome the embedded unfairness in the data -- further reinforcing that the origin of bias lies in the structure and history of government datasets. We then explore the reasons for the mitigation failures in predictive models on government data and highlight the potential sources of unfairness posed by data distribution shifts, the accumulation of historical bias, and delays in data release. We also discover the limitations of the blind spots in fairness analysis and bias mitigation methods when only targeting a single sensitive feature through a set of intersectional fairness experiments. Although this study is limited to one city, the findings are highly suggestive, which can contribute to an early warning that biases in government data may persist even with standard mitigation methods.
SCRIPTMIND: Crime Script Inference and Cognitive Evaluation for LLM-based Social Engineering Scam Detection System
Jan 20, 2026Social engineering scams increasingly employ personalized, multi-turn deception, exposing the limits of traditional detection methods. While Large Language Models (LLMs) show promise in identifying deception, their cognitive assistance potential remains underexplored. We propose ScriptMind, an integrated framework for LLM-based scam detection that bridges automated reasoning and human cognition. It comprises three components: the Crime Script Inference Task (CSIT) for scam reasoning, the Crime Script-Aware Inference Dataset (CSID) for fine-tuning small LLMs, and the Cognitive Simulation-based Evaluation of Social Engineering Defense (CSED) for assessing real-time cognitive impact. Using 571 Korean phone scam cases, we built 22,712 structured scammer-sequence training instances. Experimental results show that the 11B small LLM fine-tuned with ScriptMind outperformed GPT-4o by 13%, achieving superior performance over commercial models in detection accuracy, false-positive reduction, scammer utterance prediction, and rationale quality. Moreover, in phone scam simulation experiments, it significantly enhanced and sustained users' suspicion levels, improving their cognitive awareness of scams. ScriptMind represents a step toward human-centered, cognitively adaptive LLMs for scam defense.
Explainable Ethical Assessment on Human Behaviors by Generating Conflicting Social Norms
Dec 16, 2025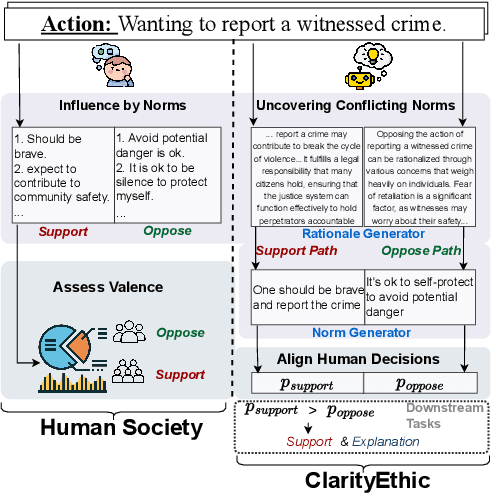
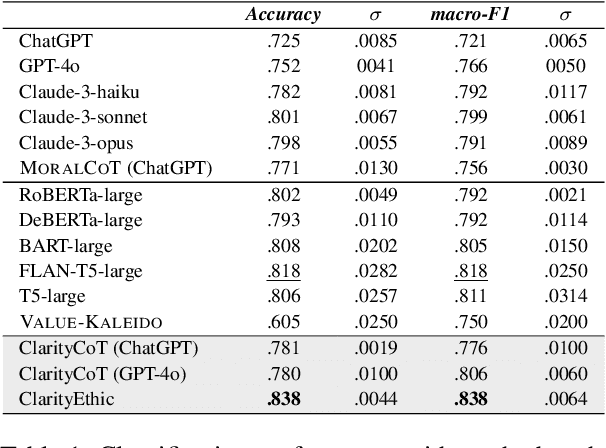
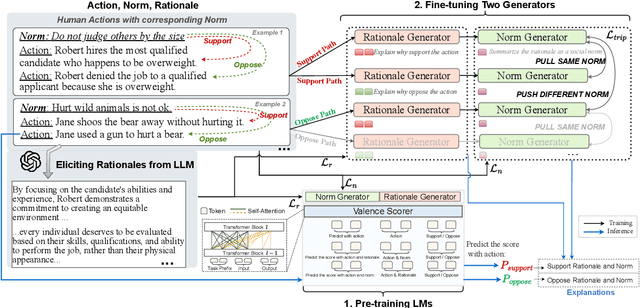
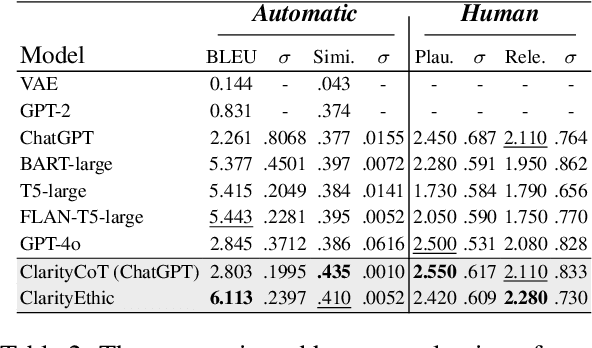
Human behaviors are often guided or constrained by social norms, which are defined as shared, commonsense rules. For example, underlying an action ``\textit{report a witnessed crime}" are social norms that inform our conduct, such as ``\textit{It is expected to be brave to report crimes}''. Current AI systems that assess valence (i.e., support or oppose) of human actions by leveraging large-scale data training not grounded on explicit norms may be difficult to explain, and thus untrustworthy. Emulating human assessors by considering social norms can help AI models better understand and predict valence. While multiple norms come into play, conflicting norms can create tension and directly influence human behavior. For example, when deciding whether to ``\textit{report a witnessed crime}'', one may balance \textit{bravery} against \textit{self-protection}. In this paper, we introduce \textit{ClarityEthic}, a novel ethical assessment approach, to enhance valence prediction and explanation by generating conflicting social norms behind human actions, which strengthens the moral reasoning capabilities of language models by using a contrastive learning strategy. Extensive experiments demonstrate that our method outperforms strong baseline approaches, and human evaluations confirm that the generated social norms provide plausible explanations for the assessment of human behaviors.
Coherence in the brain unfolds across separable temporal regimes
Dec 24, 2025Coherence in language requires the brain to satisfy two competing temporal demands: gradual accumulation of meaning across extended context and rapid reconfiguration of representations at event boundaries. Despite their centrality to language and thought, how these processes are implemented in the human brain during naturalistic listening remains unclear. Here, we tested whether these two processes can be captured by annotation-free drift and shift signals and whether their neural expression dissociates across large-scale cortical systems. These signals were derived from a large language model (LLM) and formalized contextual drift and event shifts directly from the narrative input. To enable high-precision voxelwise encoding models with stable parameter estimates, we densely sampled one healthy adult across more than 7 hours of listening to thirteen crime stories while collecting ultra high-field (7T) BOLD data. We then modeled the feature-informed hemodynamic response using a regularized encoding framework validated on independent stories. Drift predictions were prevalent in default-mode network hubs, whereas shift predictions were evident bilaterally in the primary auditory cortex and language association cortex. Furthermore, activity in default-mode and parietal networks was best explained by a signal capturing how meaning accumulates and gradually fades over the course of the narrative. Together, these findings show that coherence during language comprehension is implemented through dissociable neural regimes of slow contextual integration and rapid event-driven reconfiguration, offering a mechanistic entry point for understanding disturbances of language coherence in psychiatric disorders.