 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlibi
Papers and Code
What DINO saw: ALiBi positional encoding reduces positional bias in Vision Transformers
Mar 17, 2026Vision transformers (ViTs) - especially feature foundation models like DINOv2 - learn rich representations useful for many downstream tasks. However, architectural choices (such as positional encoding) can lead to these models displaying positional biases and artefacts independent of semantic content. This makes zero-shot adaption difficult in fields like material science, where images are often cross-sections of homogeneous microstructure (i.e. having no preferred direction). In this work, we investigate the positional bias in ViTs via linear probing, finding it present across a range of objectives and positional encodings, and subsequently reduce it by finetuning models to use ALiBi relative positional encoding. We demonstrate that these models retain desirable general semantics and their unbiased features can be used successfully in trainable segmentation of complex microscopy images.
Surgical Repair of Collapsed Attention Heads in ALiBi Transformers
Mar 10, 2026We identify a systematic attention collapse pathology in the BLOOM family of transformer language models, where ALiBi positional encoding causes 31-44% of attention heads to attend almost entirely to the beginning-of-sequence token. The collapse follows a predictable pattern across four model scales (560M to 7.1B parameters), concentrating in head indices where ALiBi's slope schedule imposes the steepest distance penalties. We introduce surgical reinitialization: targeted Q/K/V reinitialization with zeroed output projections and gradient-masked freezing of all non-surgical parameters. Applied to BLOOM-1b7 on a single consumer GPU, the technique recovers 98.7% operational head capacity (242 to 379 of 384 heads) in two passes. A controlled comparison with C4 training data confirms that reinitialization -- not corpus content -- drives recovery, and reveals two distinct post-surgical phenomena: early global functional redistribution that improves the model, and late local degradation that accumulates under noisy training signal. An extended experiment reinitializing mostly-healthy heads alongside collapsed ones produces a model that transiently outperforms stock BLOOM-1b7 by 25% on training perplexity (12.70 vs. 16.99), suggesting that pretrained attention configurations are suboptimal local minima. Code, checkpoints, and diagnostic tools are released as open-source software.
Position Encoding with Random Float Sampling Enhances Length Generalization of Transformers
Feb 15, 2026Length generalization is the ability of language models to maintain performance on inputs longer than those seen during pretraining. In this work, we introduce a simple yet powerful position encoding (PE) strategy, Random Float Sampling (RFS), that generalizes well to lengths unseen during pretraining or fine-tuning. In particular, instead of selecting position indices from a predefined discrete set, RFS uses randomly sampled continuous values, thereby avoiding out-of-distribution (OOD) issues on unseen lengths by exposing the model to diverse indices during training. Since assigning indices to tokens is a common and fundamental procedure in widely used PEs, the advantage of RFS can easily be incorporated into, for instance, the absolute sinusoidal encoding, RoPE, and ALiBi. Experiments corroborate its effectiveness by showing that RFS results in superior performance in length generalization tasks as well as zero-shot commonsense reasoning benchmarks.
Mitigating Position-Shift Failures in Text-Based Modular Arithmetic via Position Curriculum and Template Diversity
Jan 07, 2026Building on insights from the grokking literature, we study character-level Transformers trained to compute modular addition from text, and focus on robustness under input-format variation rather than only in-distribution accuracy. We identify a previously under-emphasized failure mode: models that achieve high in-distribution accuracy can fail catastrophically when the same expression is shifted to different absolute character positions ("position shift") or presented under out-of-distribution natural-language templates. Using a disjoint-pair split over all ordered pairs for p=97, we show that a baseline model reaches strong in-distribution performance yet collapses under position shift and template OOD. We then introduce a simple training recipe that combines (i) explicit expression boundary markers, (ii) position curriculum that broadens the range of absolute positions seen during training, (iii) diverse template mixtures, and (iv) consistency training across multiple variants per example. Across three seeds, this intervention substantially improves robustness to position shift and template OOD while maintaining high in-distribution accuracy, whereas an ALiBi-style ablation fails to learn the task under our setup. Our results suggest that steering procedural generalization under noisy supervision benefits from explicitly training invariances that are otherwise absent from the data distribution, and we provide a reproducible evaluation protocol and artifacts.
Group Representational Position Encoding
Dec 08, 2025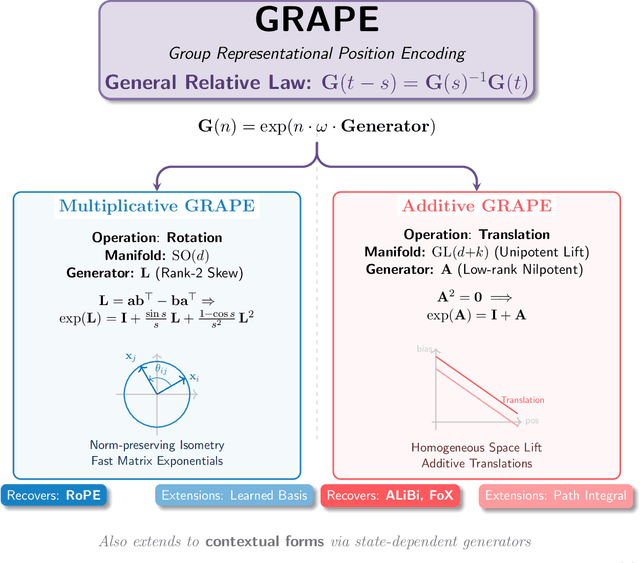
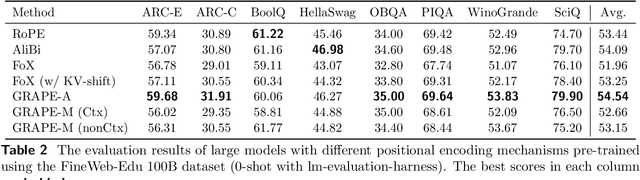
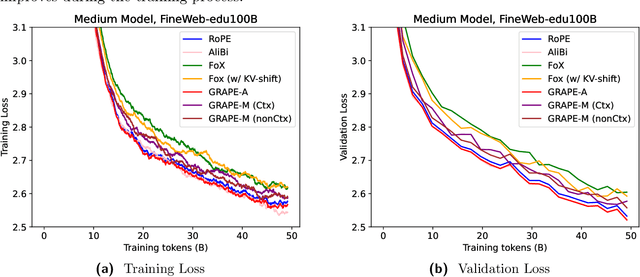

We present GRAPE (Group RepresentAtional Position Encoding), a unified framework for positional encoding based on group actions. GRAPE brings together two families of mechanisms: (i) multiplicative rotations (Multiplicative GRAPE) in $\mathrm{SO}(d)$ and (ii) additive logit biases (Additive GRAPE) arising from unipotent actions in the general linear group $\mathrm{GL}$. In Multiplicative GRAPE, a position $n \in \mathbb{Z}$ (or $t \in \mathbb{R}$) acts as $\mathbf{G}(n)=\exp(n\,ω\,\mathbf{L})$ with a rank-2 skew generator $\mathbf{L} \in \mathbb{R}^{d \times d}$, yielding a relative, compositional, norm-preserving map with a closed-form matrix exponential. RoPE is recovered exactly when the $d/2$ planes are the canonical coordinate pairs with log-uniform spectrum. Learned commuting subspaces and compact non-commuting mixtures strictly extend this geometry to capture cross-subspace feature coupling at $O(d)$ and $O(r d)$ cost per head, respectively. In Additive GRAPE, additive logits arise as rank-1 (or low-rank) unipotent actions, recovering ALiBi and the Forgetting Transformer (FoX) as exact special cases while preserving an exact relative law and streaming cacheability. Altogether, GRAPE supplies a principled design space for positional geometry in long-context models, subsuming RoPE and ALiBi as special cases. Project Page: https://github.com/model-architectures/GRAPE.
HoPE: Hyperbolic Rotary Positional Encoding for Stable Long-Range Dependency Modeling in Large Language Models
Sep 05, 2025Positional encoding mechanisms enable Transformers to model sequential structure and long-range dependencies in text. While absolute positional encodings struggle with extrapolation to longer sequences due to fixed positional representations, and relative approaches like Alibi exhibit performance degradation on extremely long contexts, the widely-used Rotary Positional Encoding (RoPE) introduces oscillatory attention patterns that hinder stable long-distance dependency modelling. We address these limitations through a geometric reformulation of positional encoding. Drawing inspiration from Lorentz transformations in hyperbolic geometry, we propose Hyperbolic Rotary Positional Encoding (HoPE), which leverages hyperbolic functions to implement Lorentz rotations on token representations. Theoretical analysis demonstrates that RoPE is a special case of our generalized formulation. HoPE fundamentally resolves RoPE's slation issues by enforcing monotonic decay of attention weights with increasing token distances. Extensive experimental results, including perplexity evaluations under several extended sequence benchmarks, show that HoPE consistently exceeds existing positional encoding methods. These findings underscore HoPE's enhanced capacity for representing and generalizing long-range dependencies. Data and code will be available.
A standard transformer and attention with linear biases for molecular conformer generation
Jun 24, 2025Sampling low-energy molecular conformations, spatial arrangements of atoms in a molecule, is a critical task for many different calculations performed in the drug discovery and optimization process. Numerous specialized equivariant networks have been designed to generate molecular conformations from 2D molecular graphs. Recently, non-equivariant transformer models have emerged as a viable alternative due to their capability to scale to improve generalization. However, the concern has been that non-equivariant models require a large model size to compensate the lack of equivariant bias. In this paper, we demonstrate that a well-chosen positional encoding effectively addresses these size limitations. A standard transformer model incorporating relative positional encoding for molecular graphs when scaled to 25 million parameters surpasses the current state-of-the-art non-equivariant base model with 64 million parameters on the GEOM-DRUGS benchmark. We implemented relative positional encoding as a negative attention bias that linearly increases with the shortest path distances between graph nodes at varying slopes for different attention heads, similar to ALiBi, a widely adopted relative positional encoding technique in the NLP domain. This architecture has the potential to serve as a foundation for a novel class of generative models for molecular conformations.
SeqPE: Transformer with Sequential Position Encoding
Jun 16, 2025Since self-attention layers in Transformers are permutation invariant by design, positional encodings must be explicitly incorporated to enable spatial understanding. However, fixed-size lookup tables used in traditional learnable position embeddings (PEs) limit extrapolation capabilities beyond pre-trained sequence lengths. Expert-designed methods such as ALiBi and RoPE, mitigate this limitation but demand extensive modifications for adapting to new modalities, underscoring fundamental challenges in adaptability and scalability. In this work, we present SeqPE, a unified and fully learnable position encoding framework that represents each $n$-dimensional position index as a symbolic sequence and employs a lightweight sequential position encoder to learn their embeddings in an end-to-end manner. To regularize SeqPE's embedding space, we introduce two complementary objectives: a contrastive objective that aligns embedding distances with a predefined position-distance function, and a knowledge distillation loss that anchors out-of-distribution position embeddings to in-distribution teacher representations, further enhancing extrapolation performance. Experiments across language modeling, long-context question answering, and 2D image classification demonstrate that SeqPE not only surpasses strong baselines in perplexity, exact match (EM), and accuracy--particularly under context length extrapolation--but also enables seamless generalization to multi-dimensional inputs without requiring manual architectural redesign. We release our code, data, and checkpoints at https://github.com/ghrua/seqpe.
Theoretical Analysis of Positional Encodings in Transformer Models: Impact on Expressiveness and Generalization
Jun 05, 2025



Positional encodings are a core part of transformer-based models, enabling processing of sequential data without recurrence. This paper presents a theoretical framework to analyze how various positional encoding methods, including sinusoidal, learned, relative, and bias-based methods like Attention with Linear Biases (ALiBi), impact a transformer's expressiveness, generalization ability, and extrapolation to longer sequences. Expressiveness is defined via function approximation, generalization bounds are established using Rademacher complexity, and new encoding methods based on orthogonal functions, such as wavelets and Legendre polynomials, are proposed. The extrapolation capacity of existing and proposed encodings is analyzed, extending ALiBi's biasing approach to a unified theoretical context. Experimental evaluation on synthetic sequence-to-sequence tasks shows that orthogonal transform-based encodings outperform traditional sinusoidal encodings in generalization and extrapolation. This work addresses a critical gap in transformer theory, providing insights for design choices in natural language processing, computer vision, and other transformer applications.
Bayesian Attention Mechanism: A Probabilistic Framework for Positional Encoding and Context Length Extrapolation
May 28, 2025Transformer-based language models rely on positional encoding (PE) to handle token order and support context length extrapolation. However, existing PE methods lack theoretical clarity and rely on limited evaluation metrics to substantiate their extrapolation claims. We propose the Bayesian Attention Mechanism (BAM), a theoretical framework that formulates positional encoding as a prior within a probabilistic model. BAM unifies existing methods (e.g., NoPE and ALiBi) and motivates a new Generalized Gaussian positional prior that substantially improves long-context generalization. Empirically, BAM enables accurate information retrieval at $500\times$ the training context length, outperforming previous state-of-the-art context length generalization in long context retrieval accuracy while maintaining comparable perplexity and introducing minimal additional parameters.