 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Facial Expression Recognition
Papers and Code
Combining facial videos and biosignals for stress estimation during driving
Jan 07, 2026Reliable stress recognition from facial videos is challenging due to stress's subjective nature and voluntary facial control. While most methods rely on Facial Action Units, the role of disentangled 3D facial geometry remains underexplored. We address this by analyzing stress during distracted driving using EMOCA-derived 3D expression and pose coefficients. Paired hypothesis tests between baseline and stressor phases reveal that 41 of 56 coefficients show consistent, phase-specific stress responses comparable to physiological markers. Building on this, we propose a Transformer-based temporal modeling framework and assess unimodal, early-fusion, and cross-modal attention strategies. Cross-Modal Attention fusion of EMOCA and physiological signals achieves best performance (AUROC 92\%, Accuracy 86.7\%), with EMOCA-gaze fusion also competitive (AUROC 91.8\%). This highlights the effectiveness of temporal modeling and cross-modal attention for stress recognition.
A survey of facial recognition techniques
Jan 09, 2026As multimedia content is quickly growing, the field of facial recognition has become one of the major research fields, particularly in the recent years. The most problematic area to researchers in image processing and computer vision is the human face which is a complex object with myriads of distinctive features that can be used to identify the face. The survey of this survey is particularly focused on most challenging facial characteristics, including differences in the light, ageing, variation in poses, partial occlusion, and facial expression and presents methodological solutions. The factors, therefore, are inevitable in the creation of effective facial recognition mechanisms used on facial images. This paper reviews the most sophisticated methods of facial detection which are Hidden Markov Models, Principal Component Analysis (PCA), Elastic Cluster Plot Matching, Support Vector Machine (SVM), Gabor Waves, Artificial Neural Networks (ANN), Eigenfaces, Independent Component Analysis (ICA), and 3D Morphable Model. Alongside the works mentioned above, we have also analyzed the images of a number of facial databases, namely JAFEE, FEI, Yale, LFW, AT&T (then called ORL), and AR (created by Martinez and Benavente), to analyze the results. However, this survey is aimed at giving a thorough literature review of face recognition, and its applications, and some experimental results are provided at the end after a detailed discussion.
* 12 pages, 12 figures, article
Multi-Track Multimodal Learning on iMiGUE: Micro-Gesture and Emotion Recognition
Dec 29, 2025Micro-gesture recognition and behavior-based emotion prediction are both highly challenging tasks that require modeling subtle, fine-grained human behaviors, primarily leveraging video and skeletal pose data. In this work, we present two multimodal frameworks designed to tackle both problems on the iMiGUE dataset. For micro-gesture classification, we explore the complementary strengths of RGB and 3D pose-based representations to capture nuanced spatio-temporal patterns. To comprehensively represent gestures, video, and skeletal embeddings are extracted using MViTv2-S and 2s-AGCN, respectively. Then, they are integrated through a Cross-Modal Token Fusion module to combine spatial and pose information. For emotion recognition, our framework extends to behavior-based emotion prediction, a binary classification task identifying emotional states based on visual cues. We leverage facial and contextual embeddings extracted using SwinFace and MViTv2-S models and fuse them through an InterFusion module designed to capture emotional expressions and body gestures. Experiments conducted on the iMiGUE dataset, within the scope of the MiGA 2025 Challenge, demonstrate the robust performance and accuracy of our method in the behavior-based emotion prediction task, where our approach secured 2nd place.
Evaluation of Generative Models for Emotional 3D Animation Generation in VR
Dec 18, 2025Social interactions incorporate nonverbal signals to convey emotions alongside speech, including facial expressions and body gestures. Generative models have demonstrated promising results in creating full-body nonverbal animations synchronized with speech; however, evaluations using statistical metrics in 2D settings fail to fully capture user-perceived emotions, limiting our understanding of model effectiveness. To address this, we evaluate emotional 3D animation generative models within a Virtual Reality (VR) environment, emphasizing user-centric metrics emotional arousal realism, naturalness, enjoyment, diversity, and interaction quality in a real-time human-agent interaction scenario. Through a user study (N=48), we examine perceived emotional quality for three state of the art speech-driven 3D animation methods across two emotions happiness (high arousal) and neutral (mid arousal). Additionally, we compare these generative models against real human expressions obtained via a reconstruction-based method to assess both their strengths and limitations and how closely they replicate real human facial and body expressions. Our results demonstrate that methods explicitly modeling emotions lead to higher recognition accuracy compared to those focusing solely on speech-driven synchrony. Users rated the realism and naturalness of happy animations significantly higher than those of neutral animations, highlighting the limitations of current generative models in handling subtle emotional states. Generative models underperformed compared to reconstruction-based methods in facial expression quality, and all methods received relatively low ratings for animation enjoyment and interaction quality, emphasizing the importance of incorporating user-centric evaluations into generative model development. Finally, participants positively recognized animation diversity across all generative models.
CS3D: An Efficient Facial Expression Recognition via Event Vision
Dec 10, 2025Responsive and accurate facial expression recognition is crucial to human-robot interaction for daily service robots. Nowadays, event cameras are becoming more widely adopted as they surpass RGB cameras in capturing facial expression changes due to their high temporal resolution, low latency, computational efficiency, and robustness in low-light conditions. Despite these advantages, event-based approaches still encounter practical challenges, particularly in adopting mainstream deep learning models. Traditional deep learning methods for facial expression analysis are energy-intensive, making them difficult to deploy on edge computing devices and thereby increasing costs, especially for high-frequency, dynamic, event vision-based approaches. To address this challenging issue, we proposed the CS3D framework by decomposing the Convolutional 3D method to reduce the computational complexity and energy consumption. Additionally, by utilizing soft spiking neurons and a spatial-temporal attention mechanism, the ability to retain information is enhanced, thus improving the accuracy of facial expression detection. Experimental results indicate that our proposed CS3D method attains higher accuracy on multiple datasets compared to architectures such as the RNN, Transformer, and C3D, while the energy consumption of the CS3D method is just 21.97\% of the original C3D required on the same device.
DAP-MAE: Domain-Adaptive Point Cloud Masked Autoencoder for Effective Cross-Domain Learning
Oct 24, 2025Compared to 2D data, the scale of point cloud data in different domains available for training, is quite limited. Researchers have been trying to combine these data of different domains for masked autoencoder (MAE) pre-training to leverage such a data scarcity issue. However, the prior knowledge learned from mixed domains may not align well with the downstream 3D point cloud analysis tasks, leading to degraded performance. To address such an issue, we propose the Domain-Adaptive Point Cloud Masked Autoencoder (DAP-MAE), an MAE pre-training method, to adaptively integrate the knowledge of cross-domain datasets for general point cloud analysis. In DAP-MAE, we design a heterogeneous domain adapter that utilizes an adaptation mode during pre-training, enabling the model to comprehensively learn information from point clouds across different domains, while employing a fusion mode in the fine-tuning to enhance point cloud features. Meanwhile, DAP-MAE incorporates a domain feature generator to guide the adaptation of point cloud features to various downstream tasks. With only one pre-training, DAP-MAE achieves excellent performance across four different point cloud analysis tasks, reaching 95.18% in object classification on ScanObjectNN and 88.45% in facial expression recognition on Bosphorus.
* 14 pages, 7 figures, conference
Emotion Recognition from Skeleton Data: A Comprehensive Survey
Jul 24, 2025Emotion recognition through body movements has emerged as a compelling and privacy-preserving alternative to traditional methods that rely on facial expressions or physiological signals. Recent advancements in 3D skeleton acquisition technologies and pose estimation algorithms have significantly enhanced the feasibility of emotion recognition based on full-body motion. This survey provides a comprehensive and systematic review of skeleton-based emotion recognition techniques. First, we introduce psychological models of emotion and examine the relationship between bodily movements and emotional expression. Next, we summarize publicly available datasets, highlighting the differences in data acquisition methods and emotion labeling strategies. We then categorize existing methods into posture-based and gait-based approaches, analyzing them from both data-driven and technical perspectives. In particular, we propose a unified taxonomy that encompasses four primary technical paradigms: Traditional approaches, Feat2Net, FeatFusionNet, and End2EndNet. Representative works within each category are reviewed and compared, with benchmarking results across commonly used datasets. Finally, we explore the extended applications of emotion recognition in mental health assessment, such as detecting depression and autism, and discuss the open challenges and future research directions in this rapidly evolving field.
Facial Emotion Learning with Text-Guided Multiview Fusion via Vision-Language Model for 3D/4D Facial Expression Recognition
Jul 02, 2025



Facial expression recognition (FER) in 3D and 4D domains presents a significant challenge in affective computing due to the complexity of spatial and temporal facial dynamics. Its success is crucial for advancing applications in human behavior understanding, healthcare monitoring, and human-computer interaction. In this work, we propose FACET-VLM, a vision-language framework for 3D/4D FER that integrates multiview facial representation learning with semantic guidance from natural language prompts. FACET-VLM introduces three key components: Cross-View Semantic Aggregation (CVSA) for view-consistent fusion, Multiview Text-Guided Fusion (MTGF) for semantically aligned facial emotions, and a multiview consistency loss to enforce structural coherence across views. Our model achieves state-of-the-art accuracy across multiple benchmarks, including BU-3DFE, Bosphorus, BU-4DFE, and BP4D-Spontaneous. We further extend FACET-VLM to 4D micro-expression recognition (MER) on the 4DME dataset, demonstrating strong performance in capturing subtle, short-lived emotional cues. The extensive experimental results confirm the effectiveness and substantial contributions of each individual component within the framework. Overall, FACET-VLM offers a robust, extensible, and high-performing solution for multimodal FER in both posed and spontaneous settings.
AU-Blendshape for Fine-grained Stylized 3D Facial Expression Manipulation
Jul 16, 2025



While 3D facial animation has made impressive progress, challenges still exist in realizing fine-grained stylized 3D facial expression manipulation due to the lack of appropriate datasets. In this paper, we introduce the AUBlendSet, a 3D facial dataset based on AU-Blendshape representation for fine-grained facial expression manipulation across identities. AUBlendSet is a blendshape data collection based on 32 standard facial action units (AUs) across 500 identities, along with an additional set of facial postures annotated with detailed AUs. Based on AUBlendSet, we propose AUBlendNet to learn AU-Blendshape basis vectors for different character styles. AUBlendNet predicts, in parallel, the AU-Blendshape basis vectors of the corresponding style for a given identity mesh, thereby achieving stylized 3D emotional facial manipulation. We comprehensively validate the effectiveness of AUBlendSet and AUBlendNet through tasks such as stylized facial expression manipulation, speech-driven emotional facial animation, and emotion recognition data augmentation. Through a series of qualitative and quantitative experiments, we demonstrate the potential and importance of AUBlendSet and AUBlendNet in 3D facial animation tasks. To the best of our knowledge, AUBlendSet is the first dataset, and AUBlendNet is the first network for continuous 3D facial expression manipulation for any identity through facial AUs. Our source code is available at https://github.com/wslh852/AUBlendNet.git.
MienCap: Realtime Performance-Based Facial Animation with Live Mood Dynamics
Aug 06, 2025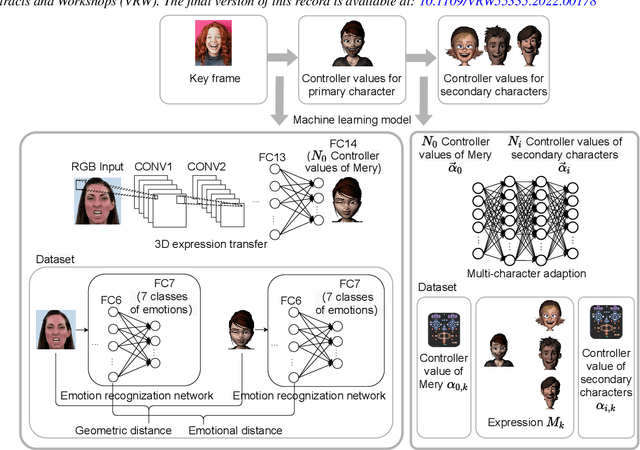
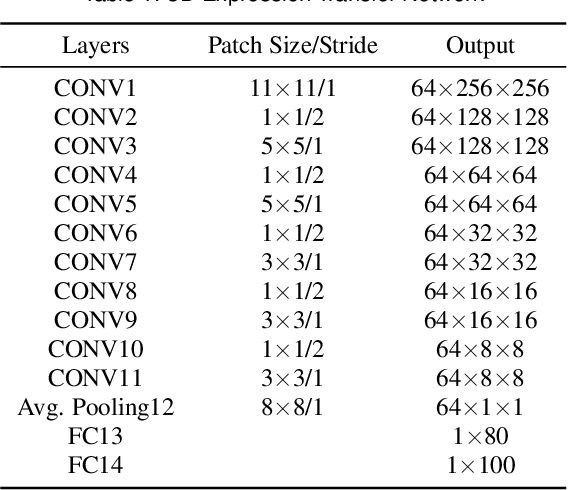
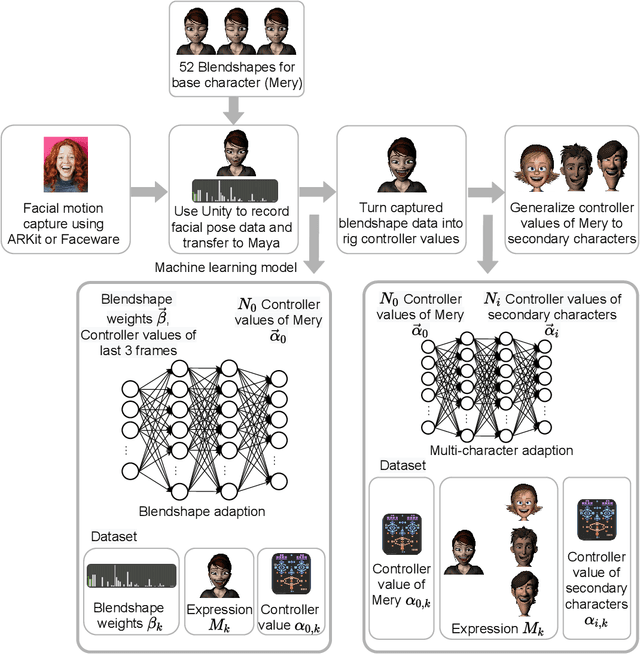

Our purpose is to improve performance-based animation which can drive believable 3D stylized characters that are truly perceptual. By combining traditional blendshape animation techniques with multiple machine learning models, we present both non-real time and real time solutions which drive character expressions in a geometrically consistent and perceptually valid way. For the non-real time system, we propose a 3D emotion transfer network makes use of a 2D human image to generate a stylized 3D rig parameters. For the real time system, we propose a blendshape adaption network which generates the character rig parameter motions with geometric consistency and temporally stability. We demonstrate the effectiveness of our system by comparing to a commercial product Faceware. Results reveal that ratings of the recognition, intensity, and attractiveness of expressions depicted for animated characters via our systems are statistically higher than Faceware. Our results may be implemented into the animation pipeline, and provide animators with a system for creating the expressions they wish to use more quickly and accurately.