 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Generative Models for Emotional 3D Animation Generation in VR
Dec 18, 2025Social interactions incorporate nonverbal signals to convey emotions alongside speech, including facial expressions and body gestures. Generative models have demonstrated promising results in creating full-body nonverbal animations synchronized with speech; however, evaluations using statistical metrics in 2D settings fail to fully capture user-perceived emotions, limiting our understanding of model effectiveness. To address this, we evaluate emotional 3D animation generative models within a Virtual Reality (VR) environment, emphasizing user-centric metrics emotional arousal realism, naturalness, enjoyment, diversity, and interaction quality in a real-time human-agent interaction scenario. Through a user study (N=48), we examine perceived emotional quality for three state of the art speech-driven 3D animation methods across two emotions happiness (high arousal) and neutral (mid arousal). Additionally, we compare these generative models against real human expressions obtained via a reconstruction-based method to assess both their strengths and limitations and how closely they replicate real human facial and body expressions. Our results demonstrate that methods explicitly modeling emotions lead to higher recognition accuracy compared to those focusing solely on speech-driven synchrony. Users rated the realism and naturalness of happy animations significantly higher than those of neutral animations, highlighting the limitations of current generative models in handling subtle emotional states. Generative models underperformed compared to reconstruction-based methods in facial expression quality, and all methods received relatively low ratings for animation enjoyment and interaction quality, emphasizing the importance of incorporating user-centric evaluations into generative model development. Finally, participants positively recognized animation diversity across all generative models.
Implementación de Navegación en Plataforma Robótica Móvil Basada en ROS y Gazebo
Oct 25, 2024This research focused on utilizing ROS2 and Gazebo for simulating the TurtleBot3 robot, with the aim of exploring autonomous navigation capabilities. While the study did not achieve full autonomous navigation, it successfully established the connection between ROS2 and Gazebo and enabled manual simulation of the robot's movements. The primary objective was to understand how these tools can be integrated to support autonomous functions, providing valuable insights into the development process. The results of this work lay the groundwork for future research into autonomous robotics. The topic is particularly engaging for both teenagers and adults interested in discovering how robots function independently and the underlying technology involved. This research highlights the potential for further advancements in autonomous systems and serves as a stepping stone for more in-depth studies in the field.
Configuração e operação da plataforma Clearpath Husky A200 e Manipulador Cobot UR5 2-Finger Gripper
Oct 22, 2024This article presents initial configuration work and use of the robotic platform and manipulator in question. The development of the ideal configuration for using this robot serves as a guide for new users and also validates its functionality for use in projects. Husky is a large payload capacity and power systems robotics development platform that accommodates a wide variety of payloads, customized to meet research needs. Together with the Cobot UR5 Manipulator attached to its base, it expands the application area of its capacity in projects. Advances in robots and mobile manipulators have revolutionized industries by automating tasks that previously required human intervention. These innovations alone increase productivity but also reduce operating costs, which makes the company more competitive in an evolving global market. Therefore, this article investigates the functionalities of this robot to validate its execution in robotics projects.
De la Extensión a la Investigación: Como La Robótica Estimula el Interés Académico en Estudiantes de Grado
Oct 22, 2024This research examines the impact of robotics groups in higher education, focusing on how these activities influence the development of transversal skills and academic motivation. While robotics goes beyond just technical knowledge, participation in these groups has been observed to significantly improve skills such as teamwork, creativity, and problem-solving. The study, conducted with the UruBots group, shows that students involved in robotics not only reinforce their theoretical knowledge but also increase their interest in research and academic commitment. These results highlight the potential of educational robotics to transform the learning experience by promoting active and collaborative learning. This work lays the groundwork for future research on how robotics can continue to enhance higher education and motivate students in their academic and professional careers
UruBots Autonomous Car Team Two: Team Description Paper for FIRA 2024
Jun 13, 2024



This paper proposes a mini autonomous car to be used by the team UruBots for the 2024 FIRA Autonomous Cars Race Challenge. The vehicle is proposed focusing on a low cost and light weight setup. Powered by a Raspberry PI4 and with a total weight of 1.15 Kilograms, we show that our vehicle manages to race a track of approximately 13 meters in 11 seconds at the best evaluation that was carried out, with an average speed of 1.2m/s in average. That performance was achieved after training a convolutional neural network with 1500 samples for a total amount of 60 epochs. Overall, we believe that our vehicle are suited to perform at the FIRA Autonomous Cars Race Challenge 2024, helping the development of the field of study and the category in the competition.
UruBots Autonomous Cars Team One Description Paper for FIRA 2024
Jun 13, 2024This document presents the design of an autonomous car developed by the UruBots team for the 2024 FIRA Autonomous Cars Race Challenge. The project involves creating an RC-car sized electric vehicle capable of navigating race tracks with in an autonomous manner. It integrates mechanical and electronic systems alongside artificial intelligence based algorithms for the navigation and real-time decision-making. The core of our project include the utilization of an AI-based algorithm to learn information from a camera and act in the robot to perform the navigation. We show that by creating a dataset with more than five thousand samples and a five-layered CNN we managed to achieve promissing performance we our proposed hardware setup. Overall, this paper aims to demonstrate the autonomous capabilities of our car, highlighting its readiness for the 2024 FIRA challenge, helping to contribute to the field of autonomous vehicle research.
Emotional Speech-driven 3D Body Animation via Disentangled Latent Diffusion
Dec 07, 2023



Existing methods for synthesizing 3D human gestures from speech have shown promising results, but they do not explicitly model the impact of emotions on the generated gestures. Instead, these methods directly output animations from speech without control over the expressed emotion. To address this limitation, we present AMUSE, an emotional speech-driven body animation model based on latent diffusion. Our observation is that content (i.e., gestures related to speech rhythm and word utterances), emotion, and personal style are separable. To account for this, AMUSE maps the driving audio to three disentangled latent vectors: one for content, one for emotion, and one for personal style. A latent diffusion model, trained to generate gesture motion sequences, is then conditioned on these latent vectors. Once trained, AMUSE synthesizes 3D human gestures directly from speech with control over the expressed emotions and style by combining the content from the driving speech with the emotion and style of another speech sequence. Randomly sampling the noise of the diffusion model further generates variations of the gesture with the same emotional expressivity. Qualitative, quantitative, and perceptual evaluations demonstrate that AMUSE outputs realistic gesture sequences. Compared to the state of the art, the generated gestures are better synchronized with the speech content and better represent the emotion expressed by the input speech. Our project website is amuse.is.tue.mpg.de.
Social Behavior Learning with Realistic Reward Shaping
Oct 22, 2018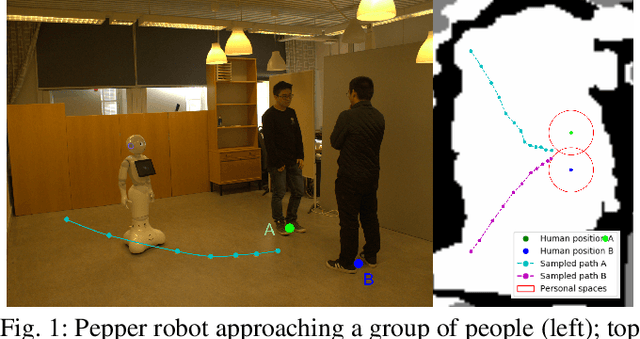



Deep reinforcement learning has been widely applied in the field of robotics recently to study tasks like locomotion and grasping, but applying it to social robotics remains a challenge. In this paper, we present a deep learning scheme that acquires a prior model of robot behavior in a simulator as a first phase to be further refined through learning from subsequent real-world interactions involving physical robots. The scheme, which we refer to as Staged Social Behavior Learning (SSBL), considers different stages of learning in social scenarios. Based on this scheme, we implement robot approaching behaviors towards a small group generated from F-formation and evaluate the performance of different configurations using objective and subjective measures. We found that our model generates more socially-considerate behavior compared to a state-of-the-art model, i.e. social force model. We also suggest that SSBL could be applied to a wide class of social robotics applications.