 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockDance: Reuse Structurally Similar Spatio-Temporal Features to Accelerate Diffusion Transformers
Mar 20, 2025Diffusion models have demonstrated impressive generation capabilities, particularly with recent advancements leveraging transformer architectures to improve both visual and artistic quality. However, Diffusion Transformers (DiTs) continue to encounter challenges related to low inference speed, primarily due to the iterative denoising process. To address this issue, we propose BlockDance, a training-free approach that explores feature similarities at adjacent time steps to accelerate DiTs. Unlike previous feature-reuse methods that lack tailored reuse strategies for features at different scales, BlockDance prioritizes the identification of the most structurally similar features, referred to as Structurally Similar Spatio-Temporal (STSS) features. These features are primarily located within the structure-focused blocks of the transformer during the later stages of denoising. BlockDance caches and reuses these highly similar features to mitigate redundant computation, thereby accelerating DiTs while maximizing consistency with the generated results of the original model. Furthermore, considering the diversity of generated content and the varying distributions of redundant features, we introduce BlockDance-Ada, a lightweight decision-making network tailored for instance-specific acceleration. BlockDance-Ada dynamically allocates resources and provides superior content quality. Both BlockDance and BlockDance-Ada have proven effective across various generation tasks and models, achieving accelerations between 25% and 50% while maintaining generation quality.
MagicMotion: Controllable Video Generation with Dense-to-Sparse Trajectory Guidance
Mar 20, 2025Recent advances in video generation have led to remarkable improvements in visual quality and temporal coherence. Upon this, trajectory-controllable video generation has emerged to enable precise object motion control through explicitly defined spatial paths. However, existing methods struggle with complex object movements and multi-object motion control, resulting in imprecise trajectory adherence, poor object consistency, and compromised visual quality. Furthermore, these methods only support trajectory control in a single format, limiting their applicability in diverse scenarios. Additionally, there is no publicly available dataset or benchmark specifically tailored for trajectory-controllable video generation, hindering robust training and systematic evaluation. To address these challenges, we introduce MagicMotion, a novel image-to-video generation framework that enables trajectory control through three levels of conditions from dense to sparse: masks, bounding boxes, and sparse boxes. Given an input image and trajectories, MagicMotion seamlessly animates objects along defined trajectories while maintaining object consistency and visual quality. Furthermore, we present MagicData, a large-scale trajectory-controlled video dataset, along with an automated pipeline for annotation and filtering. We also introduce MagicBench, a comprehensive benchmark that assesses both video quality and trajectory control accuracy across different numbers of objects. Extensive experiments demonstrate that MagicMotion outperforms previous methods across various metrics. Our project page are publicly available at https://quanhaol.github.io/magicmotion-site.
Hydra-MDP++: Advancing End-to-End Driving via Expert-Guided Hydra-Distillation
Mar 17, 2025Hydra-MDP++ introduces a novel teacher-student knowledge distillation framework with a multi-head decoder that learns from human demonstrations and rule-based experts. Using a lightweight ResNet-34 network without complex components, the framework incorporates expanded evaluation metrics, including traffic light compliance (TL), lane-keeping ability (LK), and extended comfort (EC) to address unsafe behaviors not captured by traditional NAVSIM-derived teachers. Like other end-to-end autonomous driving approaches, \hydra processes raw images directly without relying on privileged perception signals. Hydra-MDP++ achieves state-of-the-art performance by integrating these components with a 91.0% drive score on NAVSIM through scaling to a V2-99 image encoder, demonstrating its effectiveness in handling diverse driving scenarios while maintaining computational efficiency.
Hydra-NeXt: Robust Closed-Loop Driving with Open-Loop Training
Mar 15, 2025End-to-end autonomous driving research currently faces a critical challenge in bridging the gap between open-loop training and closed-loop deployment. Current approaches are trained to predict trajectories in an open-loop environment, which struggle with quick reactions to other agents in closed-loop environments and risk generating kinematically infeasible plans due to the gap between open-loop training and closed-loop driving. In this paper, we introduce Hydra-NeXt, a novel multi-branch planning framework that unifies trajectory prediction, control prediction, and a trajectory refinement network in one model. Unlike current open-loop trajectory prediction models that only handle general-case planning, Hydra-NeXt further utilizes a control decoder to focus on short-term actions, which enables faster responses to dynamic situations and reactive agents. Moreover, we propose the Trajectory Refinement module to augment and refine the planning decisions by effectively adhering to kinematic constraints in closed-loop environments. This unified approach bridges the gap between open-loop training and closed-loop driving, demonstrating superior performance of 65.89 Driving Score (DS) and 48.20% Success Rate (SR) on the Bench2Drive dataset without relying on external experts for data collection. Hydra-NeXt surpasses the previous state-of-the-art by 22.98 DS and 17.49 SR, marking a significant advancement in autonomous driving. Code will be available at https://github.com/woxihuanjiangguo/Hydra-NeXt.
Achieving More with Less: Additive Prompt Tuning for Rehearsal-Free Class-Incremental Learning
Mar 11, 2025



Class-incremental learning (CIL) enables models to learn new classes progressively while preserving knowledge of previously learned ones. Recent advances in this field have shifted towards parameter-efficient fine-tuning techniques, with many approaches building upon the framework that maintains a pool of learnable prompts. Although effective, these methods introduce substantial computational overhead, primarily due to prompt pool querying and increased input sequence lengths from prompt concatenation. In this work, we present a novel prompt-based approach that addresses this limitation. Our method trains a single set of shared prompts across all tasks and, rather than concatenating prompts to the input, directly modifies the CLS token's attention computation by adding the prompts to it. This simple and lightweight design not only significantly reduces computational complexity-both in terms of inference costs and the number of trainable parameters-but also eliminates the need to optimize prompt lengths for different downstream tasks, offering a more efficient yet powerful solution for rehearsal-free class-incremental learning. Extensive experiments across a diverse range of CIL benchmarks demonstrate the effectiveness of our approach, highlighting its potential to establish a new prompt-based CIL paradigm. Furthermore, experiments on general recognition benchmarks beyond the CIL setting also show strong performance, positioning our method as a promising candidate for a general parameter-efficient fine-tuning approach.
Human2Robot: Learning Robot Actions from Paired Human-Robot Videos
Feb 23, 2025



Distilling knowledge from human demonstrations is a promising way for robots to learn and act. Existing work often overlooks the differences between humans and robots, producing unsatisfactory results. In this paper, we study how perfectly aligned human-robot pairs benefit robot learning. Capitalizing on VR-based teleportation, we introduce H\&R, a third-person dataset with 2,600 episodes, each of which captures the fine-grained correspondence between human hands and robot gripper. Inspired by the recent success of diffusion models, we introduce Human2Robot, an end-to-end diffusion framework that formulates learning from human demonstrates as a generative task. Human2Robot fully explores temporal dynamics in human videos to generate robot videos and predict actions at the same time. Through comprehensive evaluations of 8 seen, changed and unseen tasks in real-world settings, we demonstrate that Human2Robot can not only generate high-quality robot videos but also excel in seen tasks and generalize to unseen objects, backgrounds and even new tasks effortlessly.
Pix2Cap-COCO: Advancing Visual Comprehension via Pixel-Level Captioning
Jan 23, 2025



We present Pix2Cap-COCO, the first panoptic pixel-level caption dataset designed to advance fine-grained visual understanding. To achieve this, we carefully design an automated annotation pipeline that prompts GPT-4V to generate pixel-aligned, instance-specific captions for individual objects within images, enabling models to learn more granular relationships between objects and their contexts. This approach results in 167,254 detailed captions, with an average of 22.94 words per caption. Building on Pix2Cap-COCO, we introduce a novel task, panoptic segmentation-captioning, which challenges models to recognize instances in an image and provide detailed descriptions for each simultaneously. To benchmark this task, we design a robust baseline based on X-Decoder. The experimental results demonstrate that Pix2Cap-COCO is a particularly challenging dataset, as it requires models to excel in both fine-grained visual understanding and detailed language generation. Furthermore, we leverage Pix2Cap-COCO for Supervised Fine-Tuning (SFT) on large multimodal models (LMMs) to enhance their performance. For example, training with Pix2Cap-COCO significantly improves the performance of GPT4RoI, yielding gains in CIDEr +1.4%, ROUGE +0.4%, and SPICE +0.5% on Visual Genome dataset, and strengthens its region understanding ability on the ViP-BENCH, with an overall improvement of +5.1%, including notable increases in recognition accuracy +11.2% and language generation quality +22.2%.
FNIN: A Fourier Neural Operator-based Numerical Integration Network for Surface-form-gradients
Jan 21, 2025



Surface-from-gradients (SfG) aims to recover a three-dimensional (3D) surface from its gradients. Traditional methods encounter significant challenges in achieving high accuracy and handling high-resolution inputs, particularly facing the complex nature of discontinuities and the inefficiencies associated with large-scale linear solvers. Although recent advances in deep learning, such as photometric stereo, have enhanced normal estimation accuracy, they do not fully address the intricacies of gradient-based surface reconstruction. To overcome these limitations, we propose a Fourier neural operator-based Numerical Integration Network (FNIN) within a two-stage optimization framework. In the first stage, our approach employs an iterative architecture for numerical integration, harnessing an advanced Fourier neural operator to approximate the solution operator in Fourier space. Additionally, a self-learning attention mechanism is incorporated to effectively detect and handle discontinuities. In the second stage, we refine the surface reconstruction by formulating a weighted least squares problem, addressing the identified discontinuities rationally. Extensive experiments demonstrate that our method achieves significant improvements in both accuracy and efficiency compared to current state-of-the-art solvers. This is particularly evident in handling high-resolution images with complex data, achieving errors of fewer than 0.1 mm on tested objects.
FOCUS: Towards Universal Foreground Segmentation
Jan 09, 2025



Foreground segmentation is a fundamental task in computer vision, encompassing various subdivision tasks. Previous research has typically designed task-specific architectures for each task, leading to a lack of unification. Moreover, they primarily focus on recognizing foreground objects without effectively distinguishing them from the background. In this paper, we emphasize the importance of the background and its relationship with the foreground. We introduce FOCUS, the Foreground ObjeCts Universal Segmentation framework that can handle multiple foreground tasks. We develop a multi-scale semantic network using the edge information of objects to enhance image features. To achieve boundary-aware segmentation, we propose a novel distillation method, integrating the contrastive learning strategy to refine the prediction mask in multi-modal feature space. We conduct extensive experiments on a total of 13 datasets across 5 tasks, and the results demonstrate that FOCUS consistently outperforms the state-of-the-art task-specific models on most metrics.
VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
Dec 24, 2024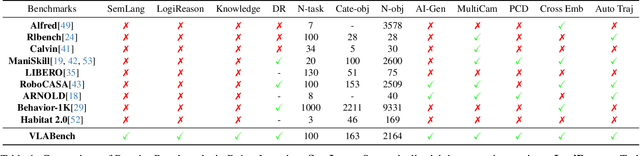
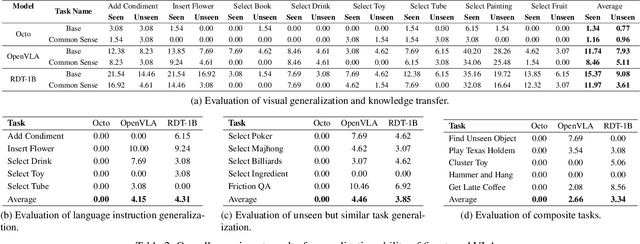

General-purposed embodied agents are designed to understand the users' natural instructions or intentions and act precisely to complete universal tasks. Recently, methods based on foundation models especially Vision-Language-Action models (VLAs) have shown a substantial potential to solve language-conditioned manipulation (LCM) tasks well. However, existing benchmarks do not adequately meet the needs of VLAs and relative algorithms. To better define such general-purpose tasks in the context of LLMs and advance the research in VLAs, we present VLABench, an open-source benchmark for evaluating universal LCM task learning. VLABench provides 100 carefully designed categories of tasks, with strong randomization in each category of task and a total of 2000+ objects. VLABench stands out from previous benchmarks in four key aspects: 1) tasks requiring world knowledge and common sense transfer, 2) natural language instructions with implicit human intentions rather than templates, 3) long-horizon tasks demanding multi-step reasoning, and 4) evaluation of both action policies and language model capabilities. The benchmark assesses multiple competencies including understanding of mesh\&texture, spatial relationship, semantic instruction, physical laws, knowledge transfer and reasoning, etc. To support the downstream finetuning, we provide high-quality training data collected via an automated framework incorporating heuristic skills and prior information. The experimental results indicate that both the current state-of-the-art pretrained VLAs and the workflow based on VLMs face challenges in our tasks.