 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-Coder-Next Technical Report
Feb 28, 2026We present Qwen3-Coder-Next, an open-weight language model specialized for coding agents. Qwen3-Coder-Next is an 80-billion-parameter model that activates only 3 billion parameters during inference, enabling strong coding capability with efficient inference. In this work, we explore how far strong training recipes can push the capability limits of models with small parameter footprints. To achieve this, we perform agentic training through large-scale synthesis of verifiable coding tasks paired with executable environments, allowing learning directly from environment feedback via mid-training and reinforcement learning. Across agent-centric benchmarks including SWE-Bench and Terminal-Bench, Qwen3-Coder-Next achieves competitive performance relative to its active parameter count. We release both base and instruction-tuned open-weight versions to support research and real-world coding agent development.
Scaling Agentic Verifier for Competitive Coding
Feb 04, 2026Large language models (LLMs) have demonstrated strong coding capabilities but still struggle to solve competitive programming problems correctly in a single attempt. Execution-based re-ranking offers a promising test-time scaling strategy, yet existing methods are constrained by either difficult test case generation or inefficient random input sampling. To address this limitation, we propose Agentic Verifier, an execution-based agent that actively reasons about program behaviors and searches for highly discriminative test inputs that expose behavioral discrepancies among candidate solutions. Through multi-turn interaction with code execution environments, the verifier iteratively refines the candidate input generator and produces targeted counterexamples rather than blindly sampling inputs. We train the verifier to acquire this discriminative input generation capability via a scalable pipeline combining large-scale data synthesis, rejection fine-tuning, and agentic reinforcement learning. Extensive experiments across five competitive programming benchmarks demonstrate consistent improvements over strong execution-based baselines, achieving up to +10-15% absolute gains in Best@K accuracy. Further analysis reveals clear test-time scaling behavior and highlights the verifier's broader potential beyond reranking.
SWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
Mitigating Hallucination in VideoLLMs via Temporal-Aware Activation Engineering
May 19, 2025Multimodal large language models (MLLMs) have achieved remarkable progress in video understanding.However, hallucination, where the model generates plausible yet incorrect outputs, persists as a significant and under-addressed challenge in the video domain. Among existing solutions, activation engineering has proven successful in mitigating hallucinations in LLMs and ImageLLMs, yet its applicability to VideoLLMs remains largely unexplored. In this work, we are the first to systematically investigate the effectiveness and underlying mechanisms of activation engineering for mitigating hallucinations in VideoLLMs. We initially conduct an investigation of the key factors affecting the performance of activation engineering and find that a model's sensitivity to hallucination depends on $\textbf{temporal variation}$ rather than task type. Moreover, selecting appropriate internal modules and dataset for activation engineering is critical for reducing hallucination. Guided by these findings, we propose a temporal-aware activation engineering framework for VideoLLMs, which adaptively identifies and manipulates hallucination-sensitive modules based on the temporal variation characteristic, substantially mitigating hallucinations without additional LLM fine-tuning. Experiments across multiple models and benchmarks demonstrate that our method markedly reduces hallucination in VideoLLMs, thereby validating the robustness of our findings.
BoolQuestions: Does Dense Retrieval Understand Boolean Logic in Language?
Nov 19, 2024



Dense retrieval, which aims to encode the semantic information of arbitrary text into dense vector representations or embeddings, has emerged as an effective and efficient paradigm for text retrieval, consequently becoming an essential component in various natural language processing systems. These systems typically focus on optimizing the embedding space by attending to the relevance of text pairs, while overlooking the Boolean logic inherent in language, which may not be captured by current training objectives. In this work, we first investigate whether current retrieval systems can comprehend the Boolean logic implied in language. To answer this question, we formulate the task of Boolean Dense Retrieval and collect a benchmark dataset, BoolQuestions, which covers complex queries containing basic Boolean logic and corresponding annotated passages. Through extensive experimental results on the proposed task and benchmark dataset, we draw the conclusion that current dense retrieval systems do not fully understand Boolean logic in language, and there is a long way to go to improve our dense retrieval systems. Furthermore, to promote further research on enhancing the understanding of Boolean logic for language models, we explore Boolean operation on decomposed query and propose a contrastive continual training method that serves as a strong baseline for the research community.
* Findings of the Association for Computational Linguistics: EMNLP 2024
Trustworthy Alignment of Retrieval-Augmented Large Language Models via Reinforcement Learning
Oct 22, 2024



Trustworthiness is an essential prerequisite for the real-world application of large language models. In this paper, we focus on the trustworthiness of language models with respect to retrieval augmentation. Despite being supported with external evidence, retrieval-augmented generation still suffers from hallucinations, one primary cause of which is the conflict between contextual and parametric knowledge. We deem that retrieval-augmented language models have the inherent capabilities of supplying response according to both contextual and parametric knowledge. Inspired by aligning language models with human preference, we take the first step towards aligning retrieval-augmented language models to a status where it responds relying merely on the external evidence and disregards the interference of parametric knowledge. Specifically, we propose a reinforcement learning based algorithm Trustworthy-Alignment, theoretically and experimentally demonstrating large language models' capability of reaching a trustworthy status without explicit supervision on how to respond. Our work highlights the potential of large language models on exploring its intrinsic abilities by its own and expands the application scenarios of alignment from fulfilling human preference to creating trustworthy agents.
* ICML 2024
Hybrid and Collaborative Passage Reranking
May 16, 2023



In passage retrieval system, the initial passage retrieval results may be unsatisfactory, which can be refined by a reranking scheme. Existing solutions to passage reranking focus on enriching the interaction between query and each passage separately, neglecting the context among the top-ranked passages in the initial retrieval list. To tackle this problem, we propose a Hybrid and Collaborative Passage Reranking (HybRank) method, which leverages the substantial similarity measurements of upstream retrievers for passage collaboration and incorporates the lexical and semantic properties of sparse and dense retrievers for reranking. Besides, built on off-the-shelf retriever features, HybRank is a plug-in reranker capable of enhancing arbitrary passage lists including previously reranked ones. Extensive experiments demonstrate the stable improvements of performance over prevalent retrieval and reranking methods, and verify the effectiveness of the core components of HybRank.
Multi-Modal Interaction Graph Convolutional Network for Temporal Language Localization in Videos
Oct 12, 2021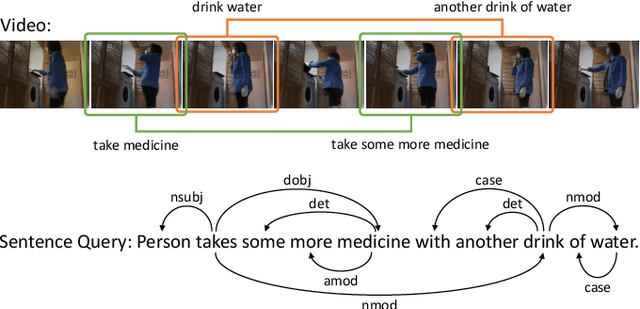
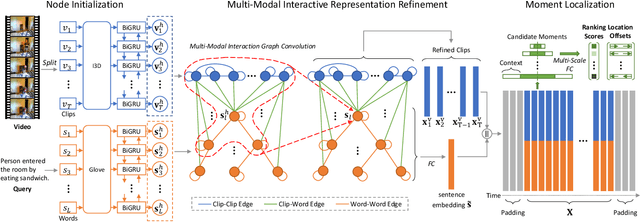
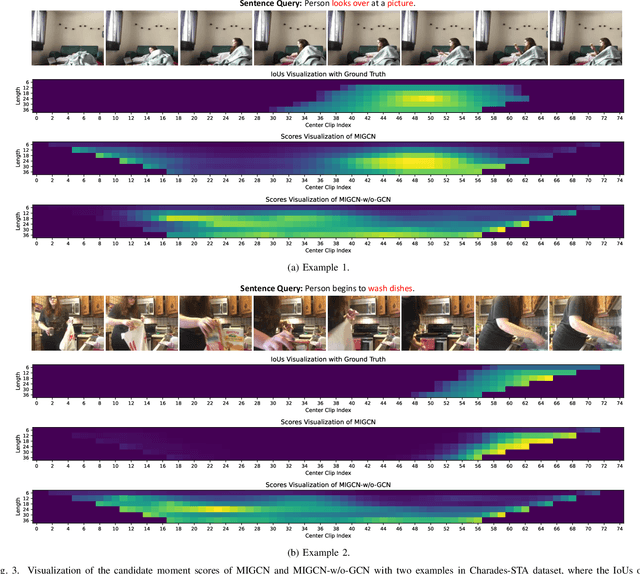

This paper focuses on tackling the problem of temporal language localization in videos, which aims to identify the start and end points of a moment described by a natural language sentence in an untrimmed video. However, it is non-trivial since it requires not only the comprehensive understanding of the video and sentence query, but also the accurate semantic correspondence capture between them. Existing efforts are mainly centered on exploring the sequential relation among video clips and query words to reason the video and sentence query, neglecting the other intra-modal relations (e.g., semantic similarity among video clips and syntactic dependency among the query words). Towards this end, in this work, we propose a Multi-modal Interaction Graph Convolutional Network (MIGCN), which jointly explores the complex intra-modal relations and inter-modal interactions residing in the video and sentence query to facilitate the understanding and semantic correspondence capture of the video and sentence query. In addition, we devise an adaptive context-aware localization method, where the context information is taken into the candidate moments and the multi-scale fully connected layers are designed to rank and adjust the boundary of the generated coarse candidate moments with different lengths. Extensive experiments on Charades-STA and ActivityNet datasets demonstrate the promising performance and superior efficiency of our model.
* Accepted by IEEE Transactions on Image Processing