 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAL: Resolving Knowledge Conflicts in Knowledge-Intensive Visual Question Answering via Reasoning-Pivot Alignment
Feb 15, 2026Knowledge-intensive Visual Question Answering (KI-VQA) frequently suffers from severe knowledge conflicts caused by the inherent limitations of open-domain retrieval. However, existing paradigms face critical limitations due to the lack of generalizable conflict detection and intra-model constraint mechanisms to handle conflicting evidence. To address these challenges, we propose the REAL (Reasoning-Pivot Alignment) framework centered on the novel concept of the Reasoning-Pivot. Distinct from reasoning steps that prioritize internal self-derivation, a reasoning-pivot serves as an atomic unit (node or edge) in the reasoning chain that emphasizes knowledge linkage, and it typically relies on external evidence to complete the reasoning. Supported by our constructed REAL-VQA dataset, our approach integrates Reasoning-Pivot Aware SFT (RPA-SFT) to train a generalizable discriminator by aligning conflicts with pivot extraction, and employs Reasoning-Pivot Guided Decoding (RPGD), an intra-model decoding strategy that leverages these pivots for targeted conflict mitigation. Extensive experiments across diverse benchmarks demonstrate that REAL significantly enhances discrimination accuracy and achieves state-of-the-art performance, validating the effectiveness of our pivot-driven resolution paradigm.
Doc-CoB: Enhancing Multi-Modal Document Understanding with Visual Chain-of-Boxes Reasoning
May 24, 2025



Multimodal large language models (MLLMs) have made significant progress in document understanding. However, the information-dense nature of document images still poses challenges, as most queries depend on only a few relevant regions, with the rest being redundant. Existing one-pass MLLMs process entire document images without considering query relevance, often failing to focus on critical regions and producing unfaithful responses. Inspired by the human coarse-to-fine reading pattern, we introduce Doc-CoB (Chain-of-Box), a simple-yet-effective mechanism that integrates human-style visual reasoning into MLLM without modifying its architecture. Our method allows the model to autonomously select the set of regions (boxes) most relevant to the query, and then focus attention on them for further understanding. We first design a fully automatic pipeline, integrating a commercial MLLM with a layout analyzer, to generate 249k training samples with intermediate visual reasoning supervision. Then we incorporate two enabling tasks that improve box identification and box-query reasoning, which together enhance document understanding. Extensive experiments on seven benchmarks with four popular models show that Doc-CoB significantly improves performance, demonstrating its effectiveness and wide applicability. All code, data, and models will be released publicly.
MP-GUI: Modality Perception with MLLMs for GUI Understanding
Mar 18, 2025Graphical user interface (GUI) has become integral to modern society, making it crucial to be understood for human-centric systems. However, unlike natural images or documents, GUIs comprise artificially designed graphical elements arranged to convey specific semantic meanings. Current multi-modal large language models (MLLMs) already proficient in processing graphical and textual components suffer from hurdles in GUI understanding due to the lack of explicit spatial structure modeling. Moreover, obtaining high-quality spatial structure data is challenging due to privacy issues and noisy environments. To address these challenges, we present MP-GUI, a specially designed MLLM for GUI understanding. MP-GUI features three precisely specialized perceivers to extract graphical, textual, and spatial modalities from the screen as GUI-tailored visual clues, with spatial structure refinement strategy and adaptively combined via a fusion gate to meet the specific preferences of different GUI understanding tasks. To cope with the scarcity of training data, we also introduce a pipeline for automatically data collecting. Extensive experiments demonstrate that MP-GUI achieves impressive results on various GUI understanding tasks with limited data.
Is Cognition consistent with Perception? Assessing and Mitigating Multimodal Knowledge Conflicts in Document Understanding
Nov 12, 2024



Multimodal large language models (MLLMs) have shown impressive capabilities in document understanding, a rapidly growing research area with significant industrial demand in recent years. As a multimodal task, document understanding requires models to possess both perceptual and cognitive abilities. However, current MLLMs often face conflicts between perception and cognition. Taking a document VQA task (cognition) as an example, an MLLM might generate answers that do not match the corresponding visual content identified by its OCR (perception). This conflict suggests that the MLLM might struggle to establish an intrinsic connection between the information it "sees" and what it "understands." Such conflicts challenge the intuitive notion that cognition is consistent with perception, hindering the performance and explainability of MLLMs. In this paper, we define the conflicts between cognition and perception as Cognition and Perception (C&P) knowledge conflicts, a form of multimodal knowledge conflicts, and systematically assess them with a focus on document understanding. Our analysis reveals that even GPT-4o, a leading MLLM, achieves only 68.6% C&P consistency. To mitigate the C&P knowledge conflicts, we propose a novel method called Multimodal Knowledge Consistency Fine-tuning. This method first ensures task-specific consistency and then connects the cognitive and perceptual knowledge. Our method significantly reduces C&P knowledge conflicts across all tested MLLMs and enhances their performance in both cognitive and perceptual tasks in most scenarios.
WebRPG: Automatic Web Rendering Parameters Generation for Visual Presentation
Jul 22, 2024



In the era of content creation revolution propelled by advancements in generative models, the field of web design remains unexplored despite its critical role in modern digital communication. The web design process is complex and often time-consuming, especially for those with limited expertise. In this paper, we introduce Web Rendering Parameters Generation (WebRPG), a new task that aims at automating the generation for visual presentation of web pages based on their HTML code. WebRPG would contribute to a faster web development workflow. Since there is no existing benchmark available, we develop a new dataset for WebRPG through an automated pipeline. Moreover, we present baseline models, utilizing VAE to manage numerous elements and rendering parameters, along with custom HTML embedding for capturing essential semantic and hierarchical information from HTML. Extensive experiments, including customized quantitative evaluations for this specific task, are conducted to evaluate the quality of the generated results.
SentiPrompt: Sentiment Knowledge Enhanced Prompt-Tuning for Aspect-Based Sentiment Analysis
Sep 17, 2021

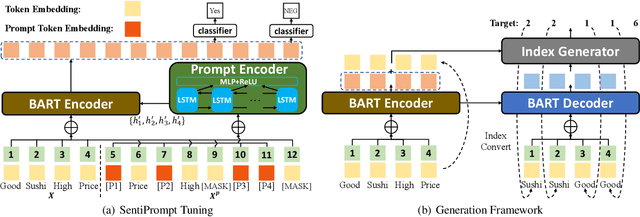
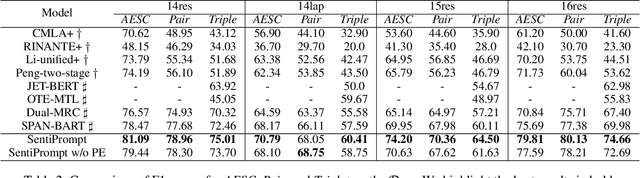
Aspect-based sentiment analysis (ABSA) is an emerging fine-grained sentiment analysis task that aims to extract aspects, classify corresponding sentiment polarities and find opinions as the causes of sentiment. The latest research tends to solve the ABSA task in a unified way with end-to-end frameworks. Yet, these frameworks get fine-tuned from downstream tasks without any task-adaptive modification. Specifically, they do not use task-related knowledge well or explicitly model relations between aspect and opinion terms, hindering them from better performance. In this paper, we propose SentiPrompt to use sentiment knowledge enhanced prompts to tune the language model in the unified framework. We inject sentiment knowledge regarding aspects, opinions, and polarities into prompt and explicitly model term relations via constructing consistency and polarity judgment templates from the ground truth triplets. Experimental results demonstrate that our approach can outperform strong baselines on Triplet Extraction, Pair Extraction, and Aspect Term Extraction with Sentiment Classification by a notable margin.