 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterMaker: Towards High-Quality Product Poster Generation with Accurate Text Rendering
Apr 09, 2025Product posters, which integrate subject, scene, and text, are crucial promotional tools for attracting customers. Creating such posters using modern image generation methods is valuable, while the main challenge lies in accurately rendering text, especially for complex writing systems like Chinese, which contains over 10,000 individual characters. In this work, we identify the key to precise text rendering as constructing a character-discriminative visual feature as a control signal. Based on this insight, we propose a robust character-wise representation as control and we develop TextRenderNet, which achieves a high text rendering accuracy of over 90%. Another challenge in poster generation is maintaining the fidelity of user-specific products. We address this by introducing SceneGenNet, an inpainting-based model, and propose subject fidelity feedback learning to further enhance fidelity. Based on TextRenderNet and SceneGenNet, we present PosterMaker, an end-to-end generation framework. To optimize PosterMaker efficiently, we implement a two-stage training strategy that decouples text rendering and background generation learning. Experimental results show that PosterMaker outperforms existing baselines by a remarkable margin, which demonstrates its effectiveness.
SceneBooth: Diffusion-based Framework for Subject-preserved Text-to-Image Generation
Jan 07, 2025



Due to the demand for personalizing image generation, subject-driven text-to-image generation method, which creates novel renditions of an input subject based on text prompts, has received growing research interest. Existing methods often learn subject representation and incorporate it into the prompt embedding to guide image generation, but they struggle with preserving subject fidelity. To solve this issue, this paper approaches a novel framework named SceneBooth for subject-preserved text-to-image generation, which consumes inputs of a subject image, object phrases and text prompts. Instead of learning the subject representation and generating a subject, our SceneBooth fixes the given subject image and generates its background image guided by the text prompts. To this end, our SceneBooth introduces two key components, i.e., a multimodal layout generation module and a background painting module. The former determines the position and scale of the subject by generating appropriate scene layouts that align with text captions, object phrases, and subject visual information. The latter integrates two adapters (ControlNet and Gated Self-Attention) into the latent diffusion model to generate a background that harmonizes with the subject guided by scene layouts and text descriptions. In this manner, our SceneBooth ensures accurate preservation of the subject's appearance in the output. Quantitative and qualitative experimental results demonstrate that SceneBooth significantly outperforms baseline methods in terms of subject preservation, image harmonization and overall quality.
SynopGround: A Large-Scale Dataset for Multi-Paragraph Video Grounding from TV Dramas and Synopses
Aug 07, 2024



Video grounding is a fundamental problem in multimodal content understanding, aiming to localize specific natural language queries in an untrimmed video. However, current video grounding datasets merely focus on simple events and are either limited to shorter videos or brief sentences, which hinders the model from evolving toward stronger multimodal understanding capabilities. To address these limitations, we present a large-scale video grounding dataset named SynopGround, in which more than 2800 hours of videos are sourced from popular TV dramas and are paired with accurately localized human-written synopses. Each paragraph in the synopsis serves as a language query and is manually annotated with precise temporal boundaries in the long video. These paragraph queries are tightly correlated to each other and contain a wealth of abstract expressions summarizing video storylines and specific descriptions portraying event details, which enables the model to learn multimodal perception on more intricate concepts over longer context dependencies. Based on the dataset, we further introduce a more complex setting of video grounding dubbed Multi-Paragraph Video Grounding (MPVG), which takes as input multiple paragraphs and a long video for grounding each paragraph query to its temporal interval. In addition, we propose a novel Local-Global Multimodal Reasoner (LGMR) to explicitly model the local-global structures of long-term multimodal inputs for MPVG. Our method provides an effective baseline solution to the multi-paragraph video grounding problem. Extensive experiments verify the proposed model's effectiveness as well as its superiority in long-term multi-paragraph video grounding over prior state-of-the-arts. Dataset and code are publicly available. Project page: https://synopground.github.io/.
STVGFormer: Spatio-Temporal Video Grounding with Static-Dynamic Cross-Modal Understanding
Jul 06, 2022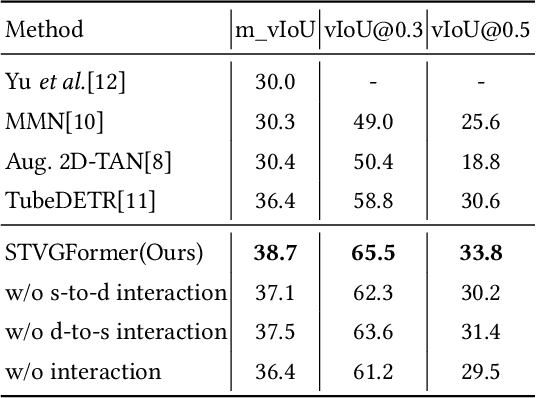
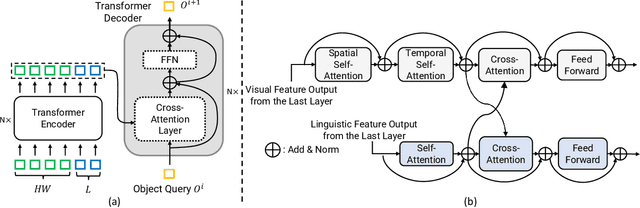
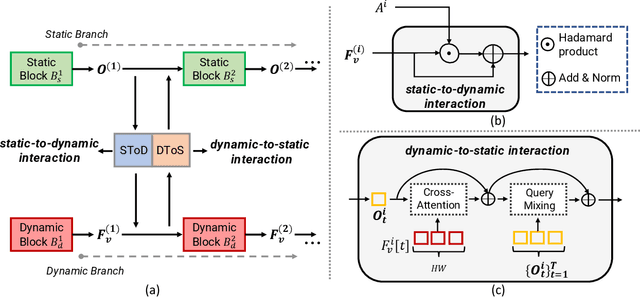
In this technical report, we introduce our solution to human-centric spatio-temporal video grounding task. We propose a concise and effective framework named STVGFormer, which models spatiotemporal visual-linguistic dependencies with a static branch and a dynamic branch. The static branch performs cross-modal understanding in a single frame and learns to localize the target object spatially according to intra-frame visual cues like object appearances. The dynamic branch performs cross-modal understanding across multiple frames. It learns to predict the starting and ending time of the target moment according to dynamic visual cues like motions. Both the static and dynamic branches are designed as cross-modal transformers. We further design a novel static-dynamic interaction block to enable the static and dynamic branches to transfer useful and complementary information from each other, which is shown to be effective to improve the prediction on hard cases. Our proposed method achieved 39.6% vIoU and won the first place in the HC-STVG track of the 4th Person in Context Challenge.
Augmented 2D-TAN: A Two-stage Approach for Human-centric Spatio-Temporal Video Grounding
Jun 20, 2021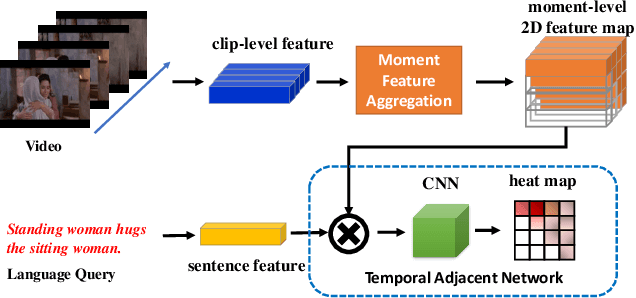
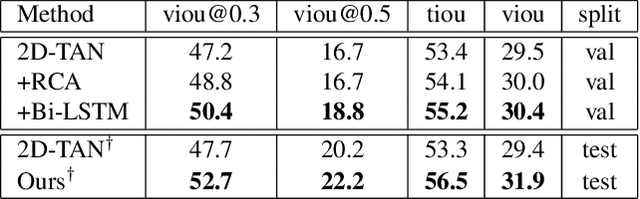
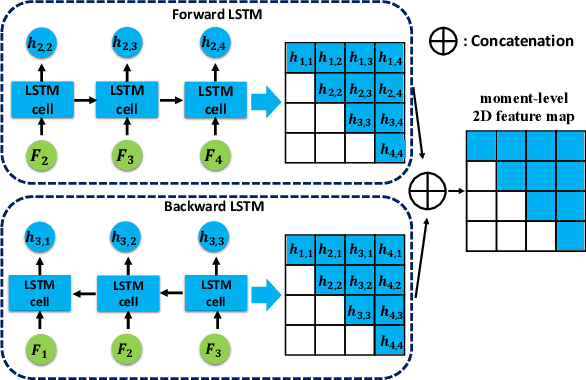
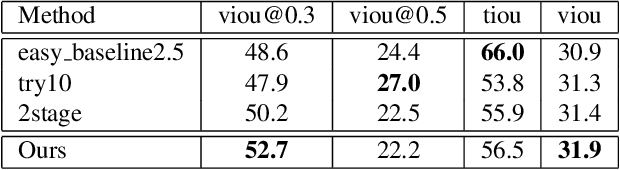
We propose an effective two-stage approach to tackle the problem of language-based Human-centric Spatio-Temporal Video Grounding (HC-STVG) task. In the first stage, we propose an Augmented 2D Temporal Adjacent Network (Augmented 2D-TAN) to temporally ground the target moment corresponding to the given description. Primarily, we improve the original 2D-TAN from two aspects: First, a temporal context-aware Bi-LSTM Aggregation Module is developed to aggregate clip-level representations, replacing the original max-pooling. Second, we propose to employ Random Concatenation Augmentation (RCA) mechanism during the training phase. In the second stage, we use pretrained MDETR model to generate per-frame bounding boxes via language query, and design a set of hand-crafted rules to select the best matching bounding box outputted by MDETR for each frame within the grounded moment.
Level-aware Haze Image Synthesis by Self-Supervised Content-Style Disentanglement
Mar 11, 2021
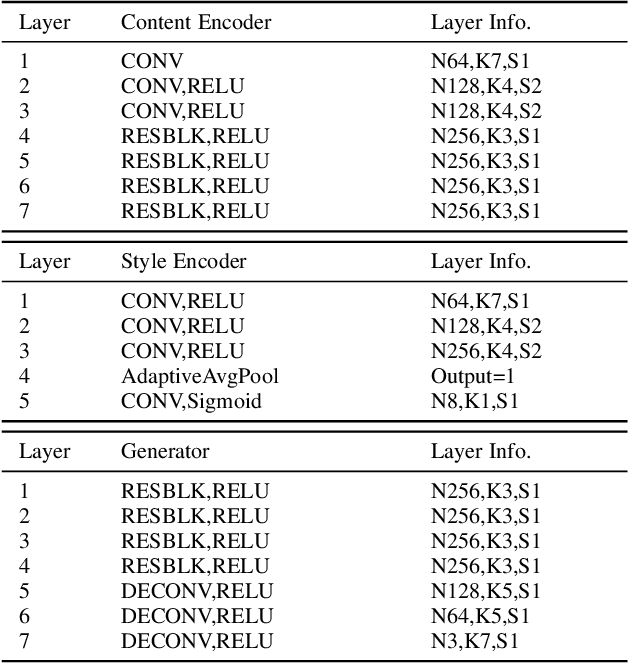
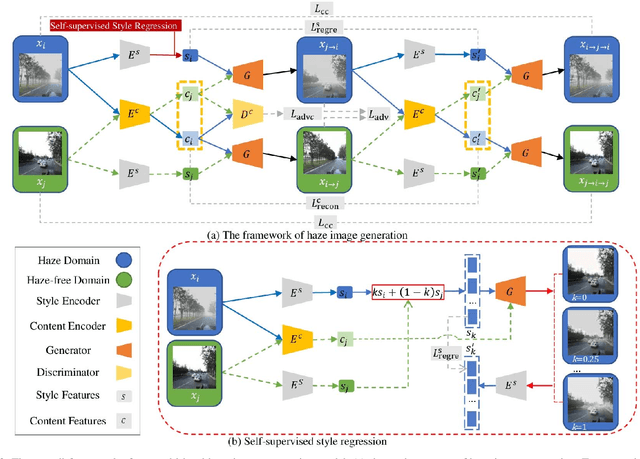
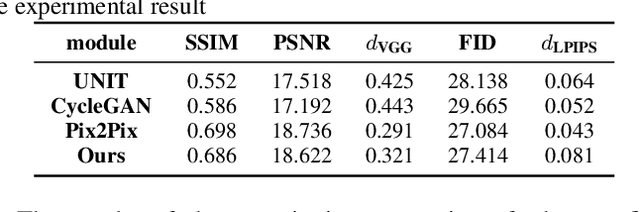
The key procedure of haze image translation through adversarial training lies in the disentanglement between the feature only involved in haze synthesis, i.e.style feature, and the feature representing the invariant semantic content, i.e. content feature. Previous methods separate content feature apart by utilizing it to classify haze image during the training process. However, in this paper we recognize the incompleteness of the content-style disentanglement in such technical routine. The flawed style feature entangled with content information inevitably leads the ill-rendering of the haze images. To address, we propose a self-supervised style regression via stochastic linear interpolation to reduce the content information in style feature. The ablative experiments demonstrate the disentangling completeness and its superiority in level-aware haze image synthesis. Moreover, the generated haze data are applied in the testing generalization of vehicle detectors. Further study between haze-level and detection performance shows that haze has obvious impact on the generalization of the vehicle detectors and such performance degrading level is linearly correlated to the haze-level, which, in turn, validates the effectiveness of the proposed method.