 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink When Needed: Model-Aware Reasoning Routing for LLM-based Ranking
Jan 26, 2026Large language models (LLMs) are increasingly applied to ranking tasks in retrieval and recommendation. Although reasoning prompting can enhance ranking utility, our preliminary exploration reveals that its benefits are inconsistent and come at a substantial computational cost, suggesting that when to reason is as crucial as how to reason. To address this issue, we propose a reasoning routing framework that employs a lightweight, plug-and-play router head to decide whether to use direct inference (Non-Think) or reasoning (Think) for each instance before generation. The router head relies solely on pre-generation signals: i) compact ranking-aware features (e.g., candidate dispersion) and ii) model-aware difficulty signals derived from a diagnostic checklist reflecting the model's estimated need for reasoning. By leveraging these features before generation, the router outputs a controllable token that determines whether to apply the Think mode. Furthermore, the router can adaptively select its operating policy along the validation Pareto frontier during deployment, enabling dynamic allocation of computational resources toward instances most likely to benefit from Think under varying system constraints. Experiments on three public ranking datasets with different scales of open-source LLMs show consistent improvements in ranking utility with reduced token consumption (e.g., +6.3\% NDCG@10 with -49.5\% tokens on MovieLens with Qwen3-4B), demonstrating reasoning routing as a practical solution to the accuracy-efficiency trade-off.
MMGRid: Navigating Temporal-aware and Cross-domain Generative Recommendation via Model Merging
Jan 22, 2026Model merging (MM) offers an efficient mechanism for integrating multiple specialized models without access to original training data or costly retraining. While MM has demonstrated success in domains like computer vision, its role in recommender systems (RSs) remains largely unexplored. Recently, Generative Recommendation (GR) has emerged as a new paradigm in RSs, characterized by rapidly growing model scales and substantial computational costs, making MM particularly appealing for cost-sensitive deployment scenarios. In this work, we present the first systematic study of MM in GR through a contextual lens. We focus on a fundamental yet underexplored challenge in real-world: how to merge generative recommenders specialized to different real-world contexts, arising from temporal evolving user behaviors and heterogeneous application domains. To this end, we propose a unified framework MMGRid, a structured contextual grid of GR checkpoints that organizes models trained under diverse contexts induced by temporal evolution and domain diversity. All checkpoints are derived from a shared base LLM but fine-tuned on context-specific data, forming a realistic and controlled model space for systematically analyzing MM across GR paradigms and merging algorithms. Our investigation reveals several key insights. First, training GR models from LLMs can introduce parameter conflicts during merging due to token distribution shifts and objective disparities; such conflicts can be alleviated by disentangling task-aware and context-specific parameter changes via base model replacement. Second, incremental training across contexts induces recency bias, which can be effectively balanced through weighted contextual merging. Notably, we observe that optimal merging weights correlate with context-dependent interaction characteristics, offering practical guidance for weight selection in real-world deployments.
iTIMO: An LLM-empowered Synthesis Dataset for Travel Itinerary Modification
Jan 15, 2026Addressing itinerary modification is crucial for enhancing the travel experience as it is a frequent requirement during traveling. However, existing research mainly focuses on fixed itinerary planning, leaving modification underexplored. To bridge this gap, we formally define the itinerary modification task and introduce iTIMO, a dataset specifically tailored for this purpose. We identify the lack of {\itshape need-to-modify} itinerary data as the critical bottleneck hindering research on this task and propose a general pipeline to overcome it. This pipeline frames the generation of such data as an intent-driven perturbation task. It instructs large language models to perturb real world itineraries using three atomic editing operations: REPLACE, ADD, and DELETE. Each perturbation is grounded in three intents, including disruptions of popularity, spatial distance, and category diversity. Furthermore, a hybrid evaluation metric is designed to ensure perturbation effectiveness. We conduct comprehensive experiments on iTIMO, revealing the limitations of current LLMs and lead to several valuable directions for future research. Dataset and corresponding code are available at https://github.com/zelo2/iTIMO.
A Comparative Study of Traditional Machine Learning, Deep Learning, and Large Language Models for Mental Health Forecasting using Smartphone Sensing Data
Jan 07, 2026Smartphone sensing offers an unobtrusive and scalable way to track daily behaviors linked to mental health, capturing changes in sleep, mobility, and phone use that often precede symptoms of stress, anxiety, or depression. While most prior studies focus on detection that responds to existing conditions, forecasting mental health enables proactive support through Just-in-Time Adaptive Interventions. In this paper, we present the first comprehensive benchmarking study comparing traditional machine learning (ML), deep learning (DL), and large language model (LLM) approaches for mental health forecasting using the College Experience Sensing (CES) dataset, the most extensive longitudinal dataset of college student mental health to date. We systematically evaluate models across temporal windows, feature granularities, personalization strategies, and class imbalance handling. Our results show that DL models, particularly Transformer (Macro-F1 = 0.58), achieve the best overall performance, while LLMs show strength in contextual reasoning but weaker temporal modeling. Personalization substantially improves forecasts of severe mental health states. By revealing how different modeling approaches interpret phone sensing behavioral data over time, this work lays the groundwork for next-generation, adaptive, and human-centered mental health technologies that can advance both research and real-world well-being.
Scoring, Reasoning, and Selecting the Best! Ensembling Large Language Models via a Peer-Review Process
Dec 29, 2025We propose LLM-PeerReview, an unsupervised LLM Ensemble method that selects the most ideal response from multiple LLM-generated candidates for each query, harnessing the collective wisdom of multiple models with diverse strengths. LLM-PeerReview is built on a novel, peer-review-inspired framework that offers a clear and interpretable mechanism, while remaining fully unsupervised for flexible adaptability and generalization. Specifically, it operates in three stages: For scoring, we use the emerging LLM-as-a-Judge technique to evaluate each response by reusing multiple LLMs at hand; For reasoning, we can apply a principled graphical model-based truth inference algorithm or a straightforward averaging strategy to aggregate multiple scores to produce a final score for each response; Finally, the highest-scoring response is selected as the best ensemble output. LLM-PeerReview is conceptually simple and empirically powerful. The two variants of the proposed approach obtain strong results across four datasets, including outperforming the recent advanced model Smoothie-Global by 6.9% and 7.3% points, respectively.
HyMoERec: Hybrid Mixture-of-Experts for Sequential Recommendation
Nov 09, 2025We propose HyMoERec, a novel sequential recommendation framework that addresses the limitations of uniform Position-wise Feed-Forward Networks in existing models. Current approaches treat all user interactions and items equally, overlooking the heterogeneity in user behavior patterns and diversity in item complexity. HyMoERec initially introduces a hybrid mixture-of-experts architecture that combines shared and specialized expert branches with an adaptive expert fusion mechanism for the sequential recommendation task. This design captures diverse reasoning for varied users and items while ensuring stable training. Experiments on MovieLens-1M and Beauty datasets demonstrate that HyMoERec consistently outperforms state-of-the-art baselines.
Mirroring Users: Towards Building Preference-aligned User Simulator with User Feedback in Recommendation
Aug 25, 2025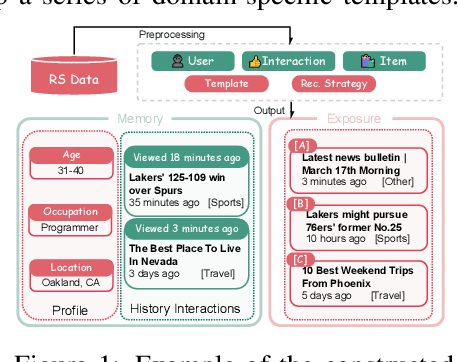
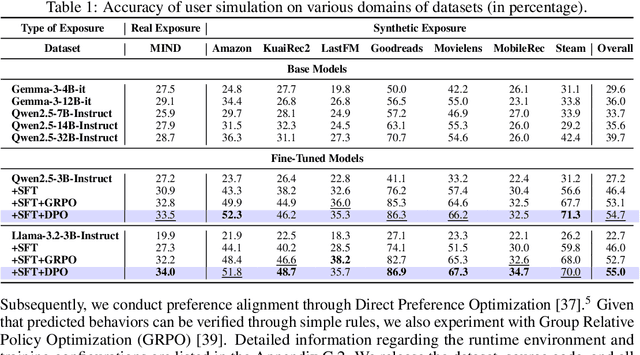
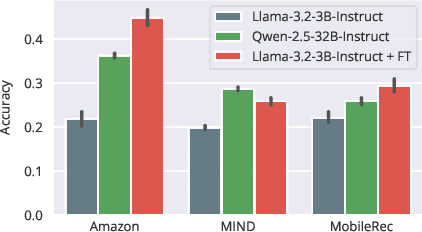
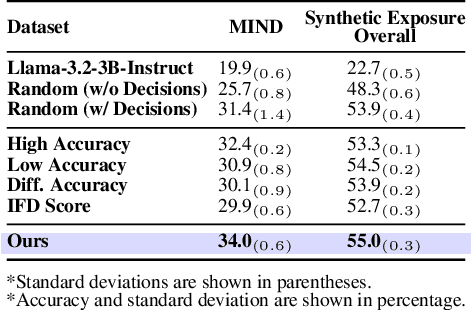
User simulation is increasingly vital to develop and evaluate recommender systems (RSs). While Large Language Models (LLMs) offer promising avenues to simulate user behavior, they often struggle with the absence of specific domain alignment required for RSs and the efficiency demands of large-scale simulation. A vast yet underutilized resource for enhancing this alignment is the extensive user feedback inherent in RSs. However, directly leveraging such feedback presents two significant challenges. First, user feedback in RSs is often ambiguous and noisy, which negatively impacts effective preference alignment. Second, the massive volume of feedback largely hinders the efficiency of preference alignment, necessitating an efficient filtering mechanism to identify more informative samples. To overcome these hurdles, we introduce a novel data construction framework that leverages user feedback in RSs with advanced LLM capabilities to generate high-quality simulation data. Our framework unfolds in two key phases: (1) employing LLMs to generate cognitive decision-making processes on constructed simulation samples, reducing ambiguity in raw user feedback; (2) data distillation based on uncertainty estimation and behavior sampling to filter challenging yet denoised simulation samples. Accordingly, we fine-tune lightweight LLMs, as user simulators, using such high-quality dataset with corresponding decision-making processes. Extensive experiments verify that our framework significantly boosts the alignment with human preferences and in-domain reasoning capabilities of fine-tuned LLMs, and provides more insightful and interpretable signals when interacting with RSs. We believe our work will advance the RS community and offer valuable insights for broader human-centric AI research.
Routing Distilled Knowledge via Mixture of LoRA Experts for Large Language Model based Bundle Generation
Aug 24, 2025Large Language Models (LLMs) have shown potential in automatic bundle generation but suffer from prohibitive computational costs. Although knowledge distillation offers a pathway to more efficient student models, our preliminary study reveals that naively integrating diverse types of distilled knowledge from teacher LLMs into student LLMs leads to knowledge conflict, negatively impacting the performance of bundle generation. To address this, we propose RouteDK, a framework for routing distilled knowledge through a mixture of LoRA expert architecture. Specifically, we first distill knowledge from the teacher LLM for bundle generation in two complementary types: high-level knowledge (generalizable rules) and fine-grained knowledge (session-specific reasoning). We then train knowledge-specific LoRA experts for each type of knowledge together with a base LoRA expert. For effective integration, we propose a dynamic fusion module, featuring an input-aware router, where the router balances expert contributions by dynamically determining optimal weights based on input, thereby effectively mitigating knowledge conflicts. To further improve inference reliability, we design an inference-time enhancement module to reduce variance and mitigate suboptimal reasoning. Experiments on three public datasets show that our RouteDK achieves accuracy comparable to or even better than the teacher LLM, while maintaining strong computational efficiency. In addition, it outperforms state-of-the-art approaches for bundle generation.
Diagnostic-Guided Dynamic Profile Optimization for LLM-based User Simulators in Sequential Recommendation
Aug 18, 2025Recent advances in large language models (LLMs) have enabled realistic user simulators for developing and evaluating recommender systems (RSs). However, existing LLM-based simulators for RSs face two major limitations: (1) static and single-step prompt-based inference that leads to inaccurate and incomplete user profile construction; (2) unrealistic and single-round recommendation-feedback interaction pattern that fails to capture real-world scenarios. To address these limitations, we propose DGDPO (Diagnostic-Guided Dynamic Profile Optimization), a novel framework that constructs user profile through a dynamic and iterative optimization process to enhance the simulation fidelity. Specifically, DGDPO incorporates two core modules within each optimization loop: firstly, a specialized LLM-based diagnostic module, calibrated through our novel training strategy, accurately identifies specific defects in the user profile. Subsequently, a generalized LLM-based treatment module analyzes the diagnosed defect and generates targeted suggestions to refine the profile. Furthermore, unlike existing LLM-based user simulators that are limited to single-round interactions, we are the first to integrate DGDPO with sequential recommenders, enabling a bidirectional evolution where user profiles and recommendation strategies adapt to each other over multi-round interactions. Extensive experiments conducted on three real-world datasets demonstrate the effectiveness of our proposed framework.
Context-Adaptive Graph Neural Networks for Next POI Recommendation
Jun 12, 2025Next Point-of-Interest (POI) recommendation is a critical task in location-based services, aiming to predict users' next visits based on their check-in histories. While many existing methods leverage Graph Neural Networks (GNNs) to incorporate collaborative information and improve recommendation accuracy, most of them model each type of context using separate graphs, treating different factors in isolation. This limits their ability to model the co-influence of multiple contextual factors on user transitions during message propagation, resulting in suboptimal attention weights and recommendation performance. Furthermore, they often prioritize sequential components as the primary predictor, potentially undermining the semantic and structural information encoded in the POI embeddings learned by GNNs. To address these limitations, we propose a Context-Adaptive Graph Neural Networks (CAGNN) for next POI recommendation, which dynamically adjusts attention weights using edge-specific contextual factors and enables mutual enhancement between graph-based and sequential components. Specifically, CAGNN introduces (1) a context-adaptive attention mechanism that jointly incorporates different types of contextual factors into the attention computation during graph propagation, enabling the model to dynamically capture collaborative and context-dependent transition patterns; (2) a graph-sequential mutual enhancement module, which aligns the outputs of the graph- and sequential-based modules via the KL divergence, enabling mutual enhancement of both components. Experimental results on three real-world datasets demonstrate that CAGNN consistently outperforms state-of-the-art methods. Meanwhile, theoretical guarantees are provided that our context-adaptive attention mechanism improves the expressiveness of POI representations.