 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReparameterized Sampling for Generative Adversarial Networks
Jul 01, 2021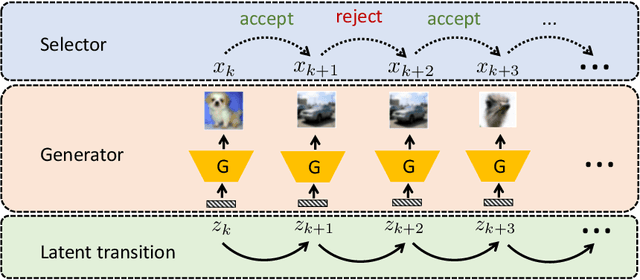
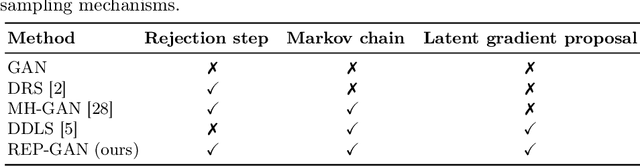
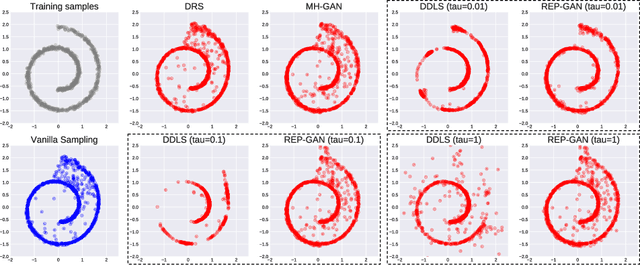
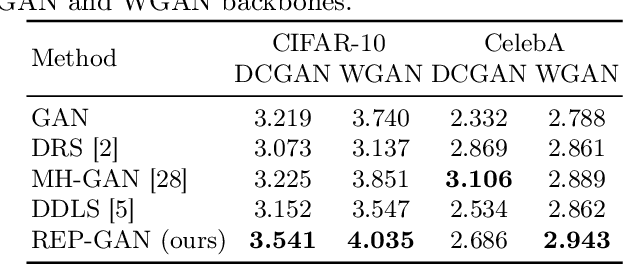
Recently, sampling methods have been successfully applied to enhance the sample quality of Generative Adversarial Networks (GANs). However, in practice, they typically have poor sample efficiency because of the independent proposal sampling from the generator. In this work, we propose REP-GAN, a novel sampling method that allows general dependent proposals by REParameterizing the Markov chains into the latent space of the generator. Theoretically, we show that our reparameterized proposal admits a closed-form Metropolis-Hastings acceptance ratio. Empirically, extensive experiments on synthetic and real datasets demonstrate that our REP-GAN largely improves the sample efficiency and obtains better sample quality simultaneously.
Quantized Neural Networks via {-1, +1} Encoding Decomposition and Acceleration
Jun 18, 2021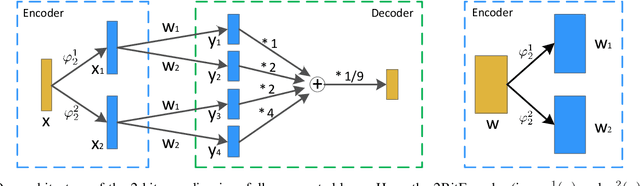
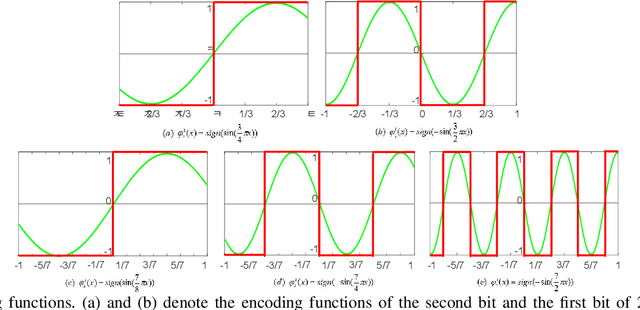


The training of deep neural networks (DNNs) always requires intensive resources for both computation and data storage. Thus, DNNs cannot be efficiently applied to mobile phones and embedded devices, which severely limits their applicability in industrial applications. To address this issue, we propose a novel encoding scheme using {-1, +1} to decompose quantized neural networks (QNNs) into multi-branch binary networks, which can be efficiently implemented by bitwise operations (i.e., xnor and bitcount) to achieve model compression, computational acceleration, and resource saving. By using our method, users can achieve different encoding precisions arbitrarily according to their requirements and hardware resources. The proposed mechanism is highly suitable for the use of FPGA and ASIC in terms of data storage and computation, which provides a feasible idea for smart chips. We validate the effectiveness of our method on large-scale image classification (e.g., ImageNet), object detection, and semantic segmentation tasks. In particular, our method with low-bit encoding can still achieve almost the same performance as its high-bit counterparts.
GBHT: Gradient Boosting Histogram Transform for Density Estimation
Jun 10, 2021
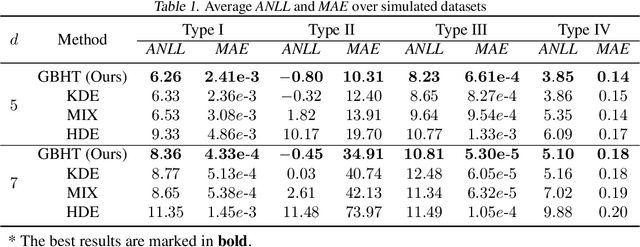
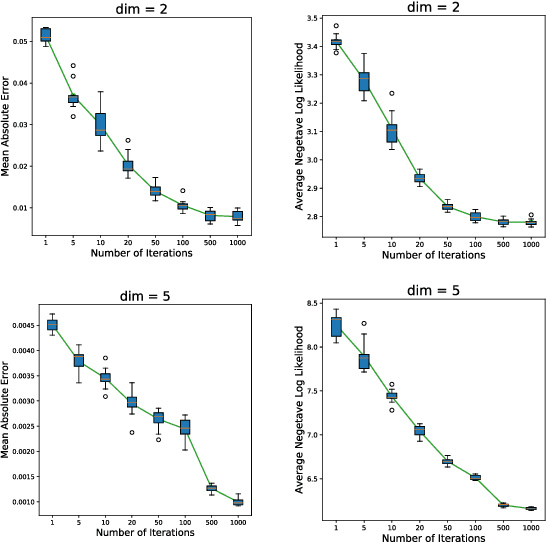
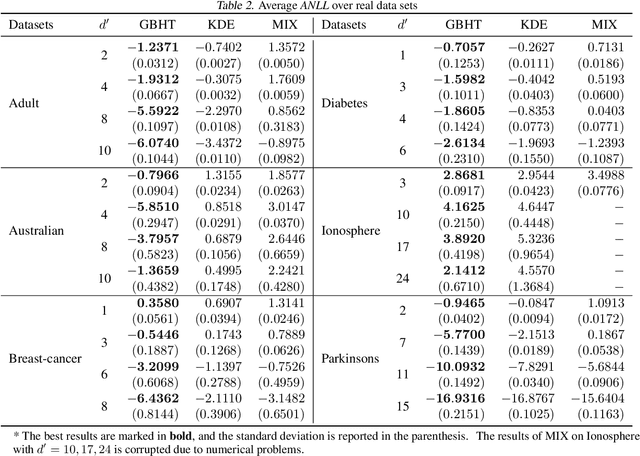
In this paper, we propose a density estimation algorithm called \textit{Gradient Boosting Histogram Transform} (GBHT), where we adopt the \textit{Negative Log Likelihood} as the loss function to make the boosting procedure available for the unsupervised tasks. From a learning theory viewpoint, we first prove fast convergence rates for GBHT with the smoothness assumption that the underlying density function lies in the space $C^{0,\alpha}$. Then when the target density function lies in spaces $C^{1,\alpha}$, we present an upper bound for GBHT which is smaller than the lower bound of its corresponding base learner, in the sense of convergence rates. To the best of our knowledge, we make the first attempt to theoretically explain why boosting can enhance the performance of its base learners for density estimation problems. In experiments, we not only conduct performance comparisons with the widely used KDE, but also apply GBHT to anomaly detection to showcase a further application of GBHT.
Leveraged Weighted Loss for Partial Label Learning
Jun 10, 2021
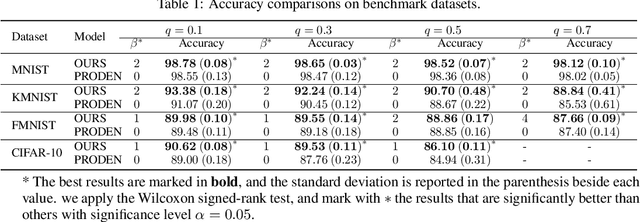
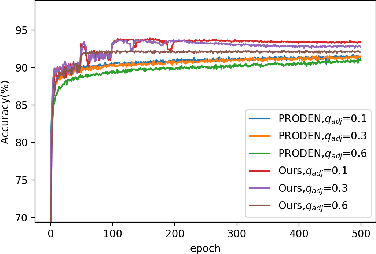
As an important branch of weakly supervised learning, partial label learning deals with data where each instance is assigned with a set of candidate labels, whereas only one of them is true. Despite many methodology studies on learning from partial labels, there still lacks theoretical understandings of their risk consistent properties under relatively weak assumptions, especially on the link between theoretical results and the empirical choice of parameters. In this paper, we propose a family of loss functions named \textit{Leveraged Weighted} (LW) loss, which for the first time introduces the leverage parameter $\beta$ to consider the trade-off between losses on partial labels and non-partial ones. From the theoretical side, we derive a generalized result of risk consistency for the LW loss in learning from partial labels, based on which we provide guidance to the choice of the leverage parameter $\beta$. In experiments, we verify the theoretical guidance, and show the high effectiveness of our proposed LW loss on both benchmark and real datasets compared with other state-of-the-art partial label learning algorithms.
Optimization Induced Equilibrium Networks
Jun 07, 2021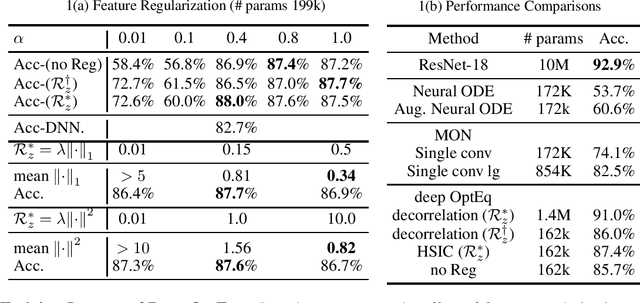


Implicit equilibrium models, i.e., deep neural networks (DNNs) defined by implicit equations, have been becoming more and more attractive recently. In this paper, we investigate an emerging question: can an implicit equilibrium model's equilibrium point be regarded as the solution of an optimization problem? To this end, we first decompose DNNs into a new class of unit layer that is the proximal operator of an implicit convex function while keeping its output unchanged. Then, the equilibrium model of the unit layer can be derived, named Optimization Induced Equilibrium Networks (OptEq), which can be easily extended to deep layers. The equilibrium point of OptEq can be theoretically connected to the solution of its corresponding convex optimization problem with explicit objectives. Based on this, we can flexibly introduce prior properties to the equilibrium points: 1) modifying the underlying convex problems explicitly so as to change the architectures of OptEq; and 2) merging the information into the fixed point iteration, which guarantees to choose the desired equilibrium point when the fixed point set is non-singleton. We show that deep OptEq outperforms previous implicit models even with fewer parameters. This work establishes the first step towards the optimization-guided design of deep models.
Gradient Boosted Binary Histogram Ensemble for Large-scale Regression
Jun 03, 2021
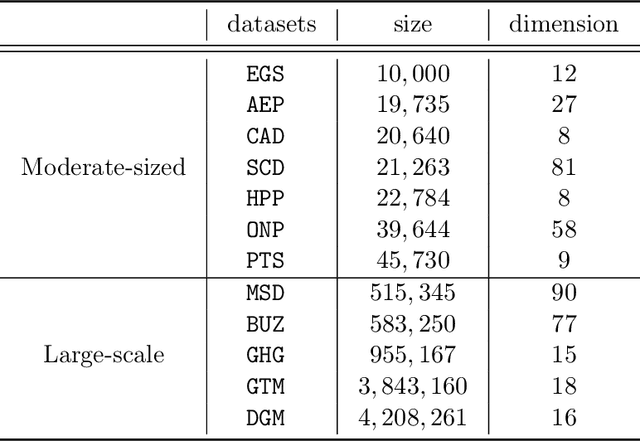
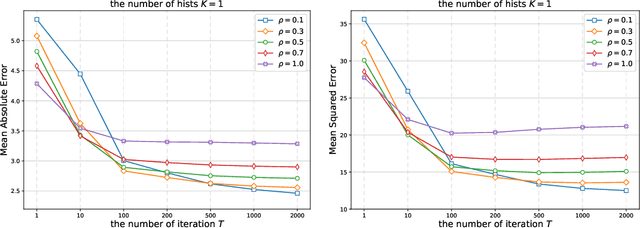
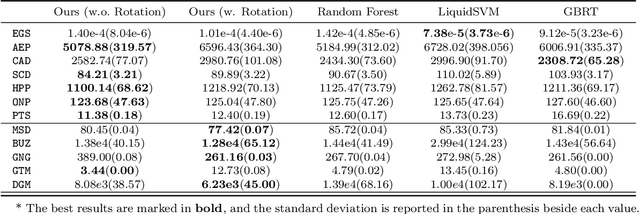
In this paper, we propose a gradient boosting algorithm for large-scale regression problems called \textit{Gradient Boosted Binary Histogram Ensemble} (GBBHE) based on binary histogram partition and ensemble learning. From the theoretical perspective, by assuming the H\"{o}lder continuity of the target function, we establish the statistical convergence rate of GBBHE in the space $C^{0,\alpha}$ and $C^{1,0}$, where a lower bound of the convergence rate for the base learner demonstrates the advantage of boosting. Moreover, in the space $C^{1,0}$, we prove that the number of iterations to achieve the fast convergence rate can be reduced by using ensemble regressor as the base learner, which improves the computational efficiency. In the experiments, compared with other state-of-the-art algorithms such as gradient boosted regression tree (GBRT), Breiman's forest, and kernel-based methods, our GBBHE algorithm shows promising performance with less running time on large-scale datasets.
Accelerated Gradient Tracking over Time-varying Graphs for Decentralized Optimization
May 05, 2021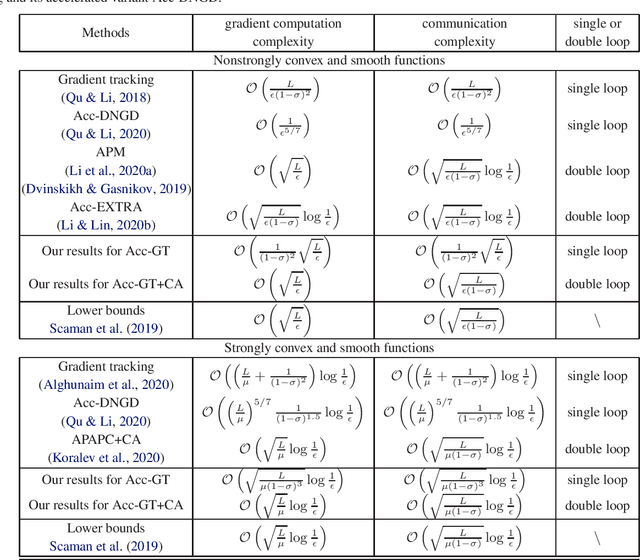
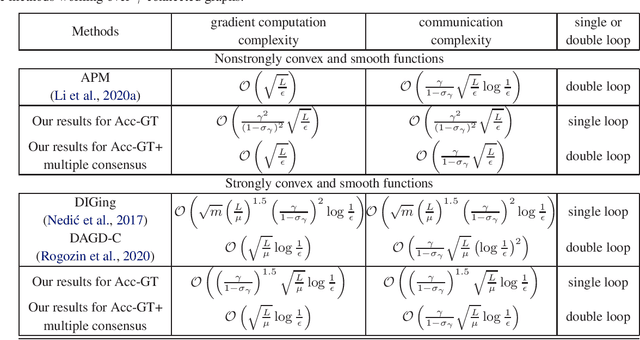
Decentralized optimization over time-varying graphs has been increasingly common in modern machine learning with massive data stored on millions of mobile devices, such as in federated learning. This paper revisits the widely used accelerated gradient tracking and extends it to time-varying graphs. We prove the $O((\frac{\gamma}{1-\sigma_{\gamma}})^2\sqrt{\frac{L}{\epsilon}})$ and $O((\frac{\gamma}{1-\sigma_{\gamma}})^{1.5}\sqrt{\frac{L}{\mu}}\log\frac{1}{\epsilon})$ complexities for the practical single loop accelerated gradient tracking over time-varying graphs when the problems are nonstrongly convex and strongly convex, respectively, where $\gamma$ and $\sigma_{\gamma}$ are two common constants charactering the network connectivity, $\epsilon$ is the desired precision, and $L$ and $\mu$ are the smoothness and strong convexity constants, respectively. Our complexities improve significantly over the ones of $O(\frac{1}{\epsilon^{5/7}})$ and $O((\frac{L}{\mu})^{5/7}\frac{1}{(1-\sigma)^{1.5}}\log\frac{1}{\epsilon})$, respectively, which were proved in the original literature only for static graphs, where $\frac{1}{1-\sigma}$ equals $\frac{\gamma}{1-\sigma_{\gamma}}$ when the network is time-invariant. When combining with a multiple consensus subroutine, the dependence on the network connectivity constants can be further improved to $O(1)$ and $O(\frac{\gamma}{1-\sigma_{\gamma}})$ for the computation and communication complexities, respectively. When the network is static, by employing the Chebyshev acceleration, our complexities exactly match the lower bounds without hiding any poly-logarithmic factor for both nonstrongly convex and strongly convex problems.
PDO-e$\text{S}^\text{2}$CNNs: Partial Differential Operator Based Equivariant Spherical CNNs
Apr 08, 2021
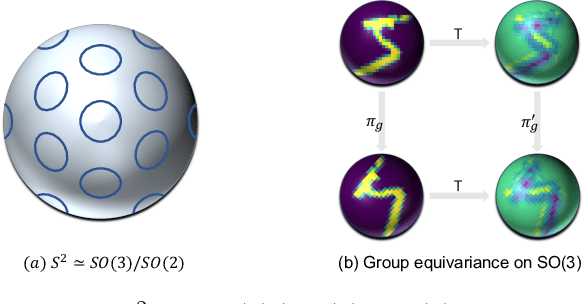
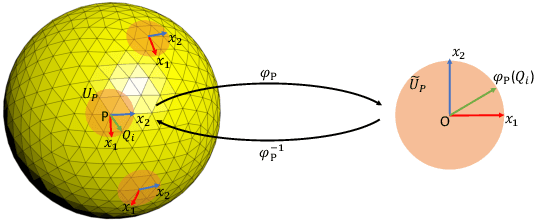
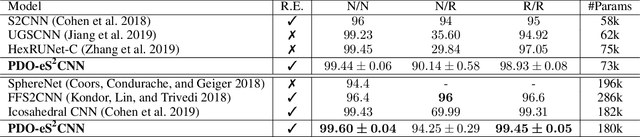
Spherical signals exist in many applications, e.g., planetary data, LiDAR scans and digitalization of 3D objects, calling for models that can process spherical data effectively. It does not perform well when simply projecting spherical data into the 2D plane and then using planar convolution neural networks (CNNs), because of the distortion from projection and ineffective translation equivariance. Actually, good principles of designing spherical CNNs are avoiding distortions and converting the shift equivariance property in planar CNNs to rotation equivariance in the spherical domain. In this work, we use partial differential operators (PDOs) to design a spherical equivariant CNN, PDO-e$\text{S}^\text{2}$CNN, which is exactly rotation equivariant in the continuous domain. We then discretize PDO-e$\text{S}^\text{2}$CNNs, and analyze the equivariance error resulted from discretization. This is the first time that the equivariance error is theoretically analyzed in the spherical domain. In experiments, PDO-e$\text{S}^\text{2}$CNNs show greater parameter efficiency and outperform other spherical CNNs significantly on several tasks.
Graph Contrastive Clustering
Apr 03, 2021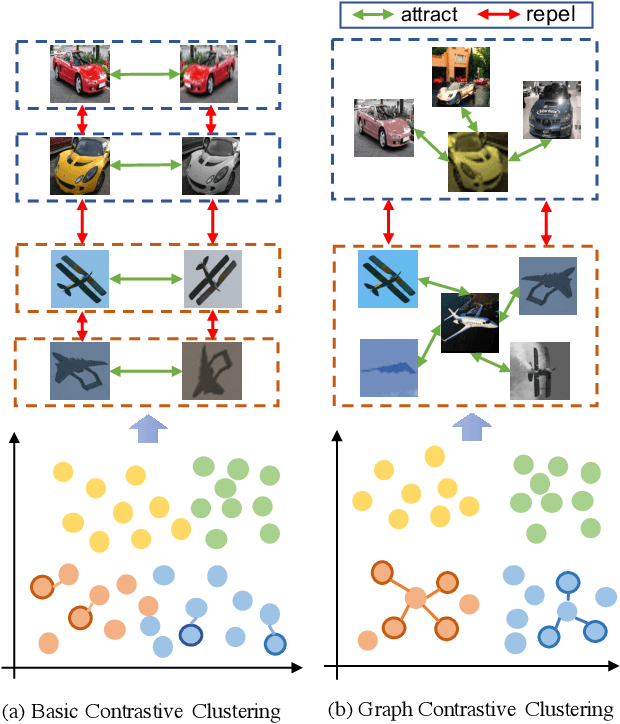
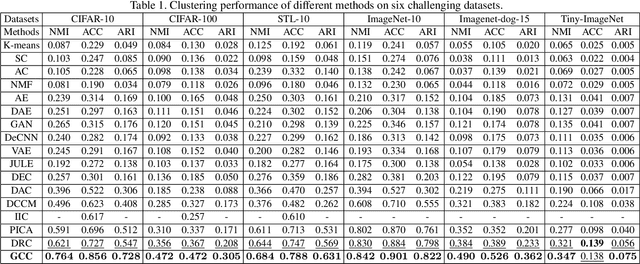
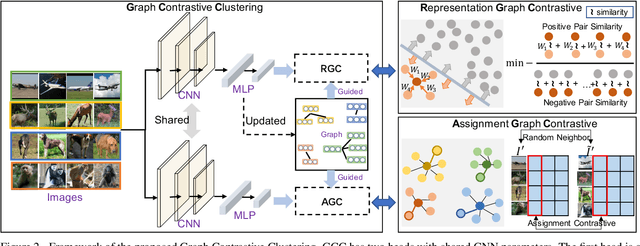
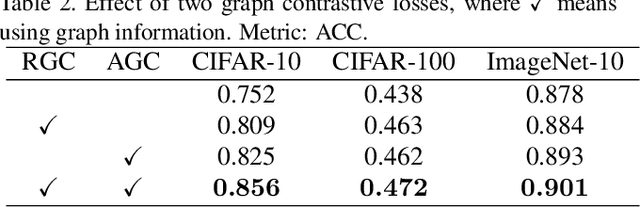
Recently, some contrastive learning methods have been proposed to simultaneously learn representations and clustering assignments, achieving significant improvements. However, these methods do not take the category information and clustering objective into consideration, thus the learned representations are not optimal for clustering and the performance might be limited. Towards this issue, we first propose a novel graph contrastive learning framework, which is then applied to the clustering task and we come up with the Graph Constrastive Clustering~(GCC) method. Different from basic contrastive clustering that only assumes an image and its augmentation should share similar representation and clustering assignments, we lift the instance-level consistency to the cluster-level consistency with the assumption that samples in one cluster and their augmentations should all be similar. Specifically, on the one hand, the graph Laplacian based contrastive loss is proposed to learn more discriminative and clustering-friendly features. On the other hand, a novel graph-based contrastive learning strategy is proposed to learn more compact clustering assignments. Both of them incorporate the latent category information to reduce the intra-cluster variance while increasing the inter-cluster variance. Experiments on six commonly used datasets demonstrate the superiority of our proposed approach over the state-of-the-art methods.
PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
Mar 11, 2021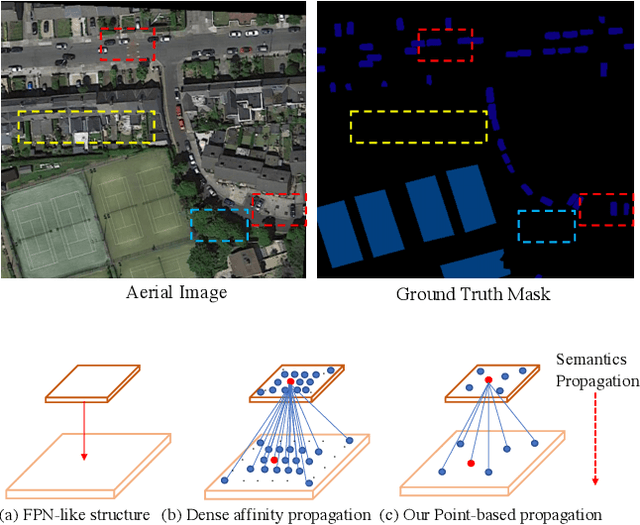
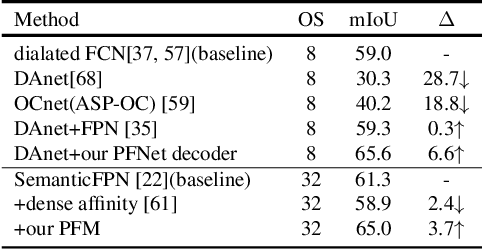
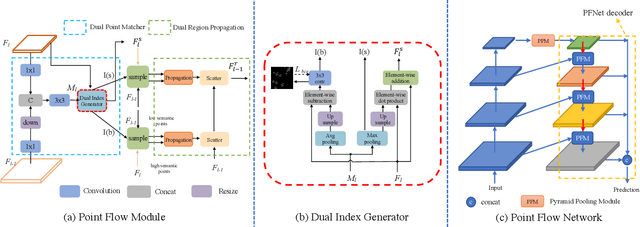
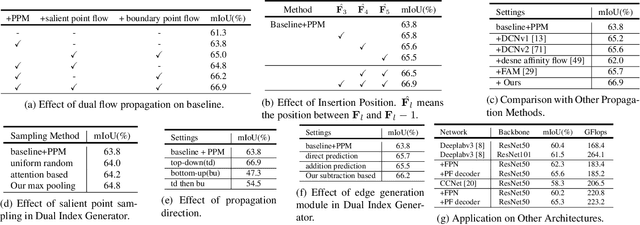
Aerial Image Segmentation is a particular semantic segmentation problem and has several challenging characteristics that general semantic segmentation does not have. There are two critical issues: The one is an extremely foreground-background imbalanced distribution, and the other is multiple small objects along with the complex background. Such problems make the recent dense affinity context modeling perform poorly even compared with baselines due to over-introduced background context. To handle these problems, we propose a point-wise affinity propagation module based on the Feature Pyramid Network (FPN) framework, named PointFlow. Rather than dense affinity learning, a sparse affinity map is generated upon selected points between the adjacent features, which reduces the noise introduced by the background while keeping efficiency. In particular, we design a dual point matcher to select points from the salient area and object boundaries, respectively. Experimental results on three different aerial segmentation datasets suggest that the proposed method is more effective and efficient than state-of-the-art general semantic segmentation methods. Especially, our methods achieve the best speed and accuracy trade-off on three aerial benchmarks. Further experiments on three general semantic segmentation datasets prove the generality of our method. Code will be provided in (https: //github.com/lxtGH/PFSegNets).