 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChaos is a Ladder: A New Theoretical Understanding of Contrastive Learning via Augmentation Overlap
Mar 25, 2022
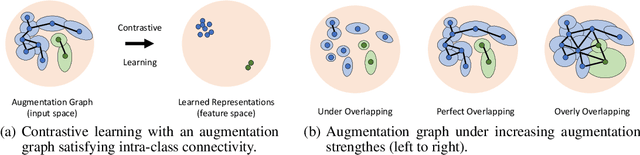
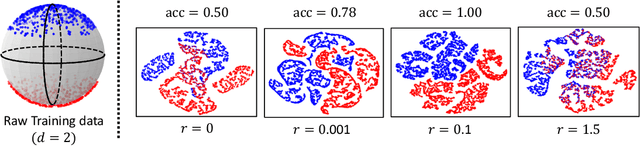
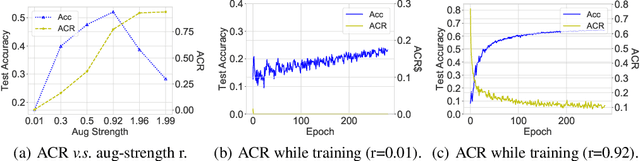
Recently, contrastive learning has risen to be a promising approach for large-scale self-supervised learning. However, theoretical understanding of how it works is still unclear. In this paper, we propose a new guarantee on the downstream performance without resorting to the conditional independence assumption that is widely adopted in previous work but hardly holds in practice. Our new theory hinges on the insight that the support of different intra-class samples will become more overlapped under aggressive data augmentations, thus simply aligning the positive samples (augmented views of the same sample) could make contrastive learning cluster intra-class samples together. Based on this augmentation overlap perspective, theoretically, we obtain asymptotically closed bounds for downstream performance under weaker assumptions, and empirically, we propose an unsupervised model selection metric ARC that aligns well with downstream accuracy. Our theory suggests an alternative understanding of contrastive learning: the role of aligning positive samples is more like a surrogate task than an ultimate goal, and the overlapped augmented views (i.e., the chaos) create a ladder for contrastive learning to gradually learn class-separated representations. The code for computing ARC is available at https://github.com/zhangq327/ARC.
A Unified Contrastive Energy-based Model for Understanding the Generative Ability of Adversarial Training
Mar 25, 2022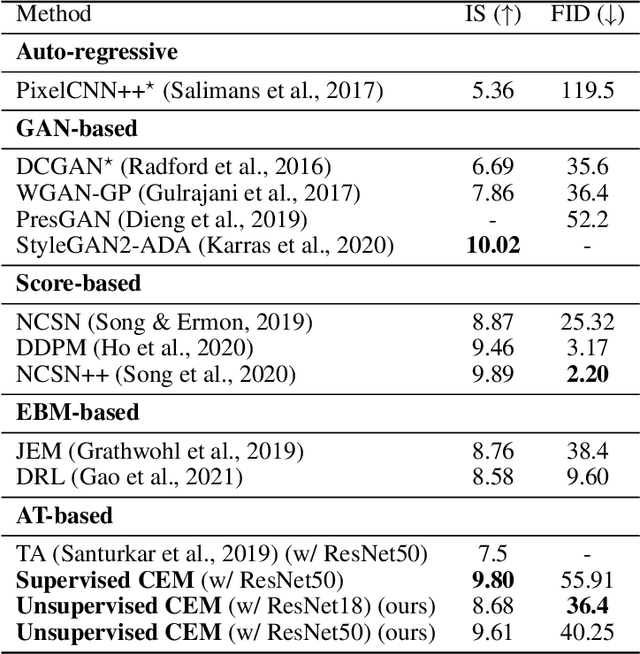
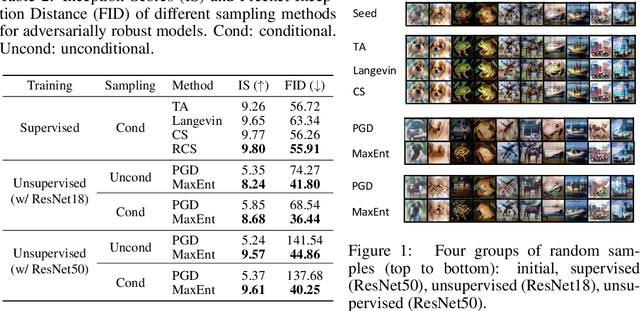
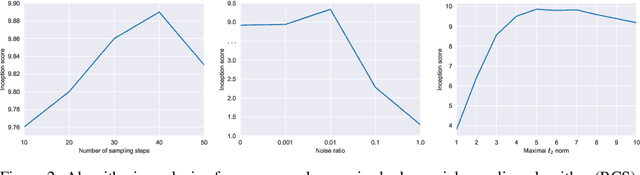
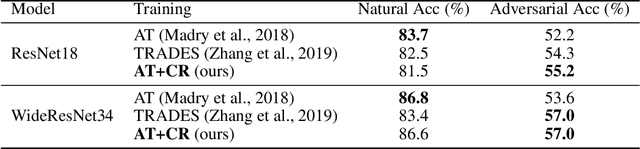
Adversarial Training (AT) is known as an effective approach to enhance the robustness of deep neural networks. Recently researchers notice that robust models with AT have good generative ability and can synthesize realistic images, while the reason behind it is yet under-explored. In this paper, we demystify this phenomenon by developing a unified probabilistic framework, called Contrastive Energy-based Models (CEM). On the one hand, we provide the first probabilistic characterization of AT through a unified understanding of robustness and generative ability. On the other hand, our unified framework can be extended to the unsupervised scenario, which interprets unsupervised contrastive learning as an important sampling of CEM. Based on these, we propose a principled method to develop adversarial learning and sampling methods. Experiments show that the sampling methods derived from our framework improve the sample quality in both supervised and unsupervised learning. Notably, our unsupervised adversarial sampling method achieves an Inception score of 9.61 on CIFAR-10, which is superior to previous energy-based models and comparable to state-of-the-art generative models.
Do We Really Need a Learnable Classifier at the End of Deep Neural Network?
Mar 17, 2022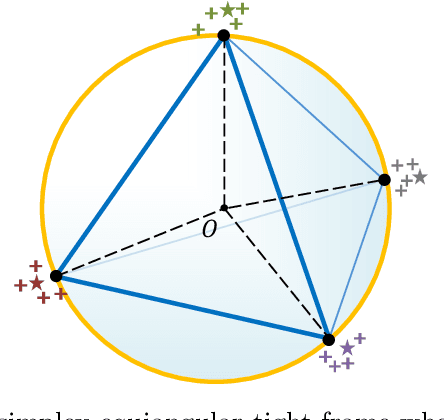

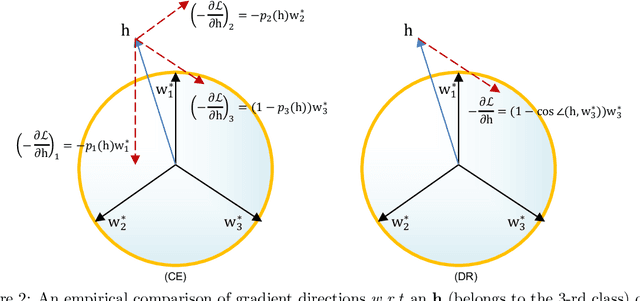
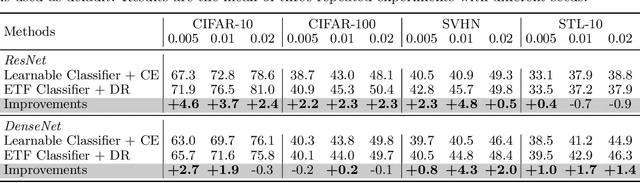
Modern deep neural networks for classification usually jointly learn a backbone for representation and a linear classifier to output the logit of each class. A recent study has shown a phenomenon called neural collapse that the within-class means of features and the classifier vectors converge to the vertices of a simplex equiangular tight frame (ETF) at the terminal phase of training on a balanced dataset. Since the ETF geometric structure maximally separates the pair-wise angles of all classes in the classifier, it is natural to raise the question, why do we spend an effort to learn a classifier when we know its optimal geometric structure? In this paper, we study the potential of learning a neural network for classification with the classifier randomly initialized as an ETF and fixed during training. Our analytical work based on the layer-peeled model indicates that the feature learning with a fixed ETF classifier naturally leads to the neural collapse state even when the dataset is imbalanced among classes. We further show that in this case the cross entropy (CE) loss is not necessary and can be replaced by a simple squared loss that shares the same global optimality but enjoys a more accurate gradient and better convergence property. Our experimental results show that our method is able to achieve similar performances on image classification for balanced datasets, and bring significant improvements in the long-tailed and fine-grained classification tasks.
Restarted Nonconvex Accelerated Gradient Descent: No More Polylogarithmic Factor in the $O(ε^{-7/4})$ Complexity
Feb 16, 2022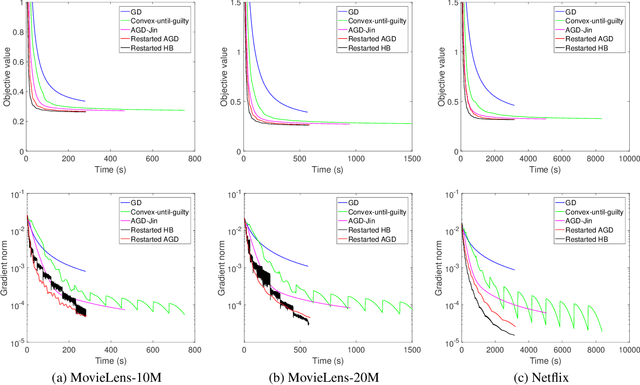
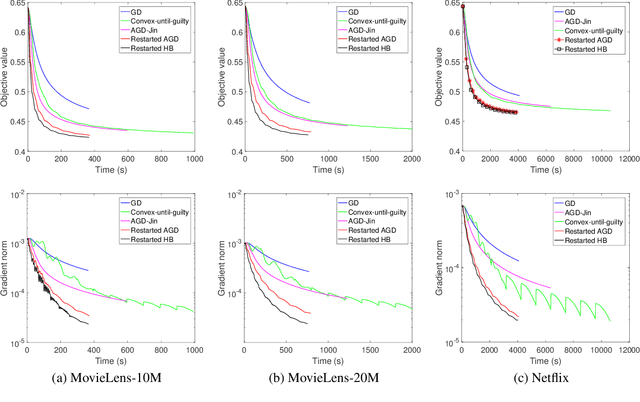
This paper studies the accelerated gradient descent for general nonconvex problems under the gradient Lipschitz and Hessian Lipschitz assumptions. We establish that a simple restarted accelerated gradient descent (AGD) finds an $\epsilon$-approximate first-order stationary point in $O(\epsilon^{-7/4})$ gradient computations with simple proofs. Our complexity does not hide any polylogarithmic factors, and thus it improves over the state-of-the-art one by the $O(\log\frac{1}{\epsilon})$ factor. Our simple algorithm only consists of Nesterov's classical AGD and a restart mechanism, and it does not need the negative curvature exploitation or the optimization of regularized surrogate functions. Technically, our simple proof does not invoke the analysis for the strongly convex AGD, which is crucial to remove the $O(\log\frac{1}{\epsilon})$ factor.
On Training Implicit Models
Nov 24, 2021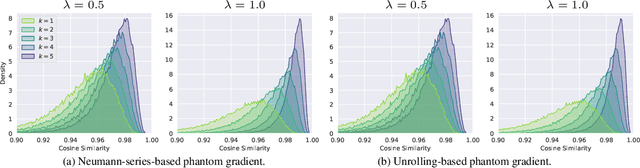
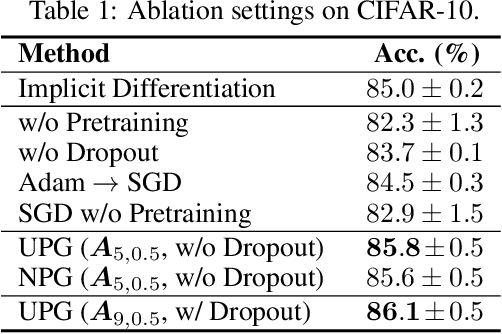
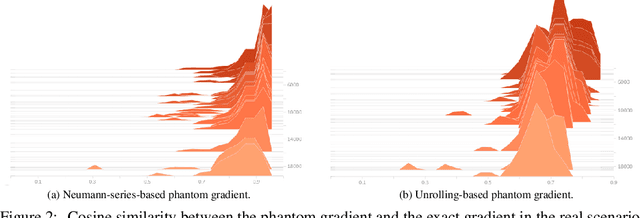
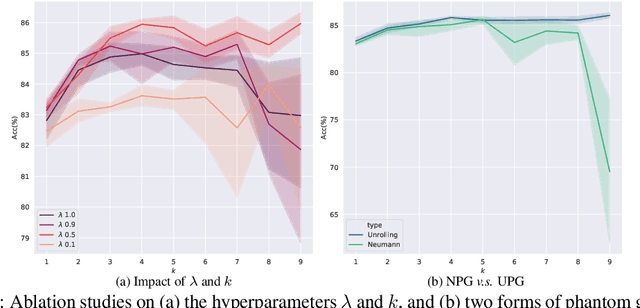
This paper focuses on training implicit models of infinite layers. Specifically, previous works employ implicit differentiation and solve the exact gradient for the backward propagation. However, is it necessary to compute such an exact but expensive gradient for training? In this work, we propose a novel gradient estimate for implicit models, named phantom gradient, that 1) forgoes the costly computation of the exact gradient; and 2) provides an update direction empirically preferable to the implicit model training. We theoretically analyze the condition under which an ascent direction of the loss landscape could be found, and provide two specific instantiations of the phantom gradient based on the damped unrolling and Neumann series. Experiments on large-scale tasks demonstrate that these lightweight phantom gradients significantly accelerate the backward passes in training implicit models by roughly 1.7 times, and even boost the performance over approaches based on the exact gradient on ImageNet.
Pareto Adversarial Robustness: Balancing Spatial Robustness and Sensitivity-based Robustness
Nov 03, 2021
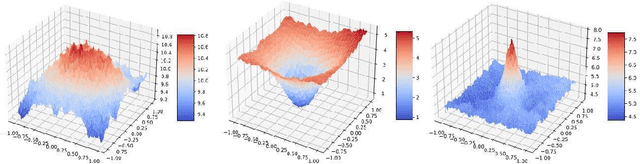
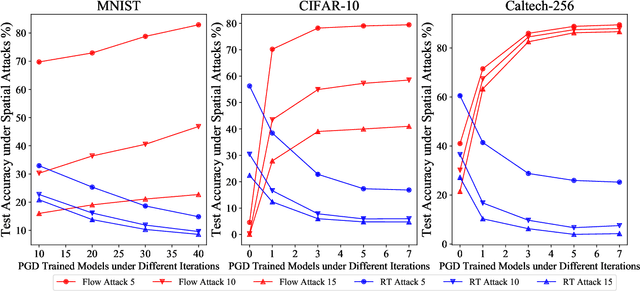
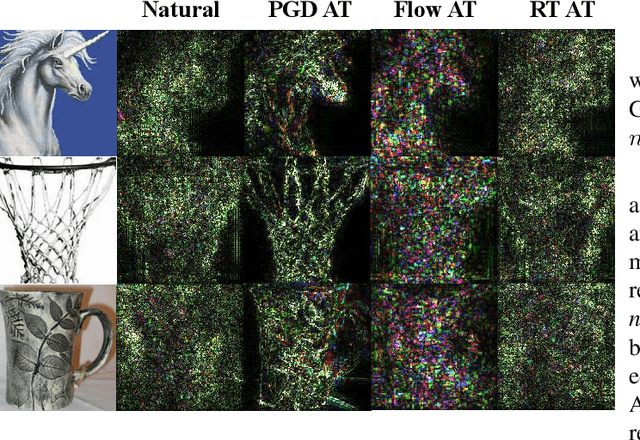
Adversarial robustness, which mainly contains sensitivity-based robustness and spatial robustness, plays an integral part in the robust generalization. In this paper, we endeavor to design strategies to achieve universal adversarial robustness. To hit this target, we firstly investigate the less-studied spatial robustness and then integrate existing spatial robustness methods by incorporating both local and global spatial vulnerability into one spatial attack and adversarial training. Based on this exploration, we further present a comprehensive relationship between natural accuracy, sensitivity-based and different spatial robustness, supported by the strong evidence from the perspective of robust representation. More importantly, in order to balance these mutual impacts of different robustness into one unified framework, we incorporate \textit{Pareto criterion} into the adversarial robustness analysis, yielding a novel strategy called \textit{Pareto Adversarial Training} towards universal robustness. The resulting Pareto front, the set of optimal solutions, provides the set of optimal balance among natural accuracy and different adversarial robustness, shedding light on solutions towards universal robustness in the future. To the best of our knowledge, we are the first to consider the universal adversarial robustness via multi-objective optimization.
Residual Relaxation for Multi-view Representation Learning
Oct 28, 2021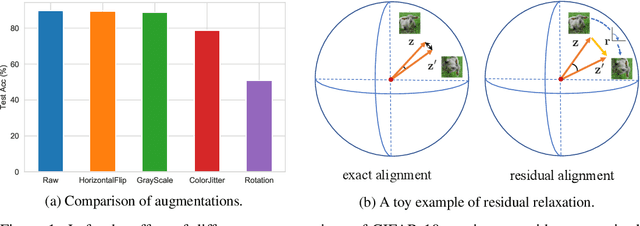
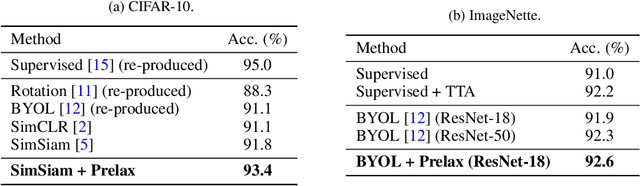
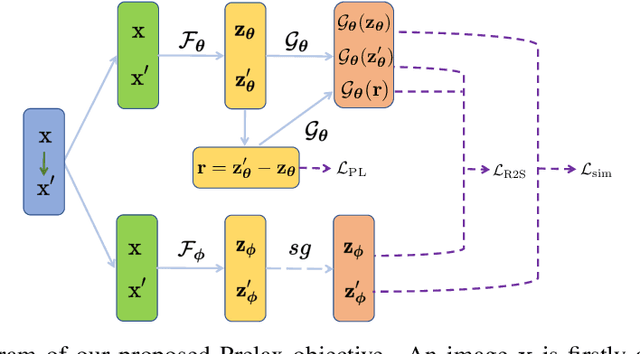
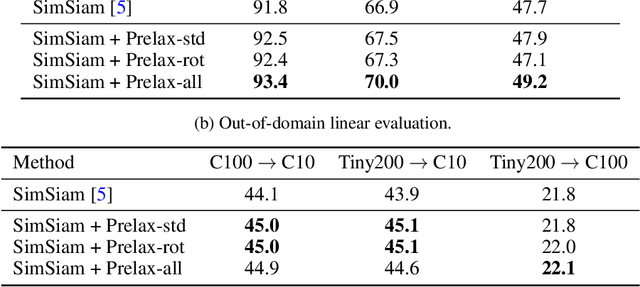
Multi-view methods learn representations by aligning multiple views of the same image and their performance largely depends on the choice of data augmentation. In this paper, we notice that some other useful augmentations, such as image rotation, are harmful for multi-view methods because they cause a semantic shift that is too large to be aligned well. This observation motivates us to relax the exact alignment objective to better cultivate stronger augmentations. Taking image rotation as a case study, we develop a generic approach, Pretext-aware Residual Relaxation (Prelax), that relaxes the exact alignment by allowing an adaptive residual vector between different views and encoding the semantic shift through pretext-aware learning. Extensive experiments on different backbones show that our method can not only improve multi-view methods with existing augmentations, but also benefit from stronger image augmentations like rotation.
Training Feedback Spiking Neural Networks by Implicit Differentiation on the Equilibrium State
Sep 29, 2021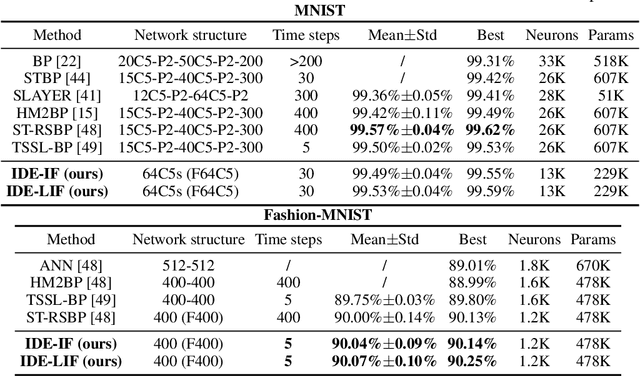
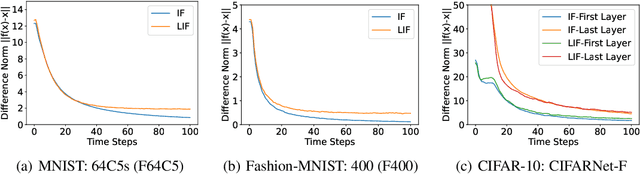
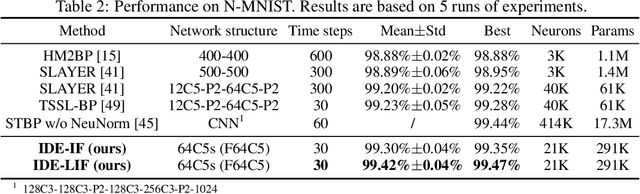
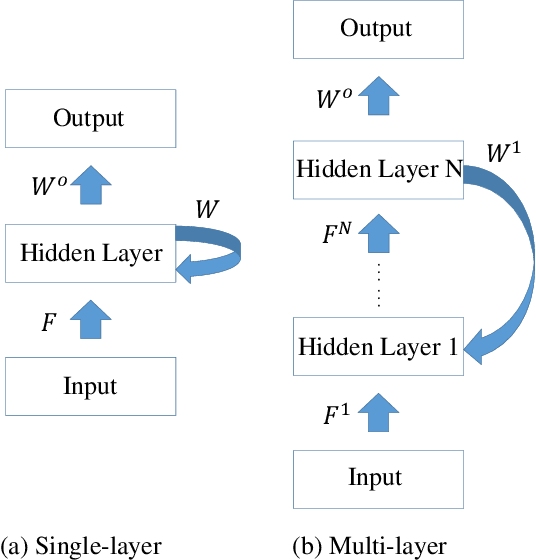
Spiking neural networks (SNNs) are brain-inspired models that enable energy-efficient implementation on neuromorphic hardware. However, the supervised training of SNNs remains a hard problem due to the discontinuity of the spiking neuron model. Most existing methods imitate the backpropagation framework and feedforward architectures for artificial neural networks, and use surrogate derivatives or compute gradients with respect to the spiking time to deal with the problem. These approaches either accumulate approximation errors or only propagate information limitedly through existing spikes, and usually require information propagation along time steps with large memory costs and biological implausibility. In this work, we consider feedback spiking neural networks, which are more brain-like, and propose a novel training method that does not rely on the exact reverse of the forward computation. First, we show that the average firing rates of SNNs with feedback connections would gradually evolve to an equilibrium state along time, which follows a fixed-point equation. Then by viewing the forward computation of feedback SNNs as a black-box solver for this equation, and leveraging the implicit differentiation on the equation, we can compute the gradient for parameters without considering the exact forward procedure. In this way, the forward and backward procedures are decoupled and therefore the problem of non-differentiable spiking functions is avoided. We also briefly discuss the biological plausibility of implicit differentiation, which only requires computing another equilibrium. Extensive experiments on MNIST, Fashion-MNIST, N-MNIST, CIFAR-10, and CIFAR-100 demonstrate the superior performance of our method for feedback models with fewer neurons and parameters in a small number of time steps. Our code is avaiable at https://github.com/pkuxmq/IDE-FSNN.
Is Attention Better Than Matrix Decomposition?
Sep 09, 2021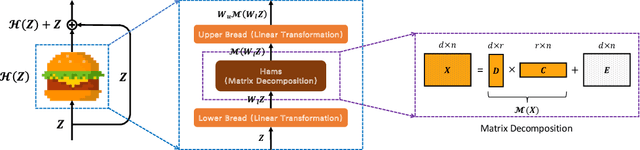

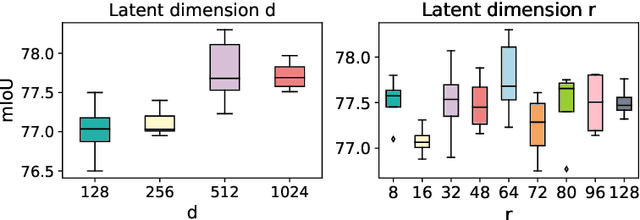
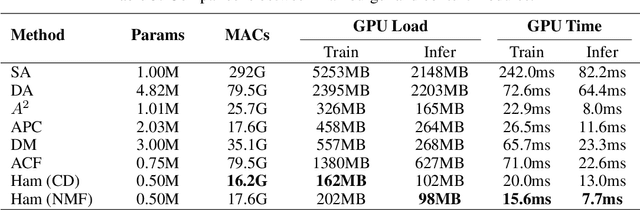
As an essential ingredient of modern deep learning, attention mechanism, especially self-attention, plays a vital role in the global correlation discovery. However, is hand-crafted attention irreplaceable when modeling the global context? Our intriguing finding is that self-attention is not better than the matrix decomposition (MD) model developed 20 years ago regarding the performance and computational cost for encoding the long-distance dependencies. We model the global context issue as a low-rank recovery problem and show that its optimization algorithms can help design global information blocks. This paper then proposes a series of Hamburgers, in which we employ the optimization algorithms for solving MDs to factorize the input representations into sub-matrices and reconstruct a low-rank embedding. Hamburgers with different MDs can perform favorably against the popular global context module self-attention when carefully coping with gradients back-propagated through MDs. Comprehensive experiments are conducted in the vision tasks where it is crucial to learn the global context, including semantic segmentation and image generation, demonstrating significant improvements over self-attention and its variants.
Under-bagging Nearest Neighbors for Imbalanced Classification
Sep 01, 2021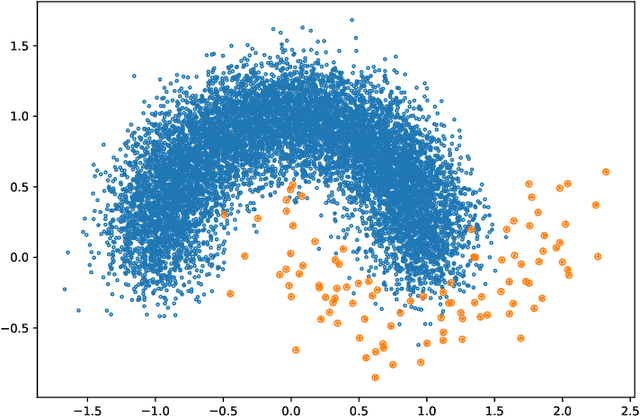
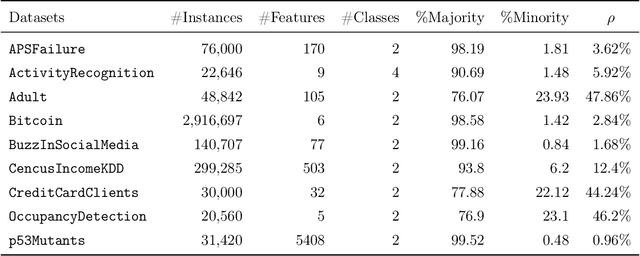
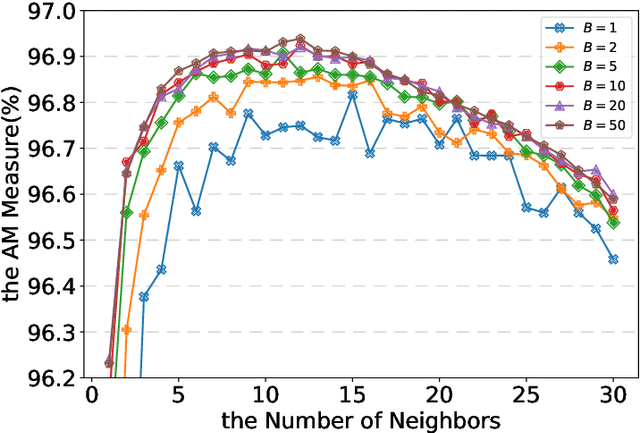
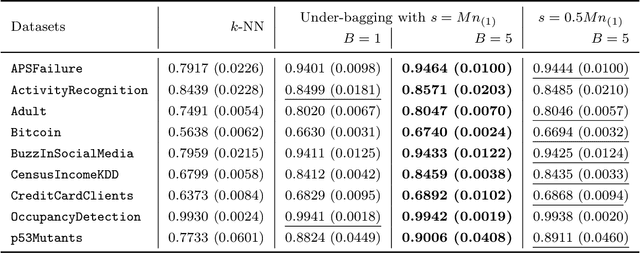
In this paper, we propose an ensemble learning algorithm called \textit{under-bagging $k$-nearest neighbors} (\textit{under-bagging $k$-NN}) for imbalanced classification problems. On the theoretical side, by developing a new learning theory analysis, we show that with properly chosen parameters, i.e., the number of nearest neighbors $k$, the expected sub-sample size $s$, and the bagging rounds $B$, optimal convergence rates for under-bagging $k$-NN can be achieved under mild assumptions w.r.t.~the arithmetic mean (AM) of recalls. Moreover, we show that with a relatively small $B$, the expected sub-sample size $s$ can be much smaller than the number of training data $n$ at each bagging round, and the number of nearest neighbors $k$ can be reduced simultaneously, especially when the data are highly imbalanced, which leads to substantially lower time complexity and roughly the same space complexity. On the practical side, we conduct numerical experiments to verify the theoretical results on the benefits of the under-bagging technique by the promising AM performance and efficiency of our proposed algorithm.