 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvertible Rescaling Network and Its Extensions
Oct 09, 2022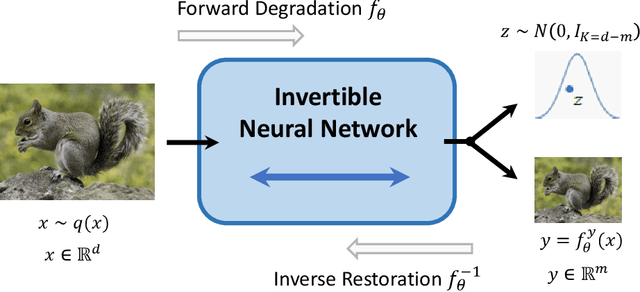
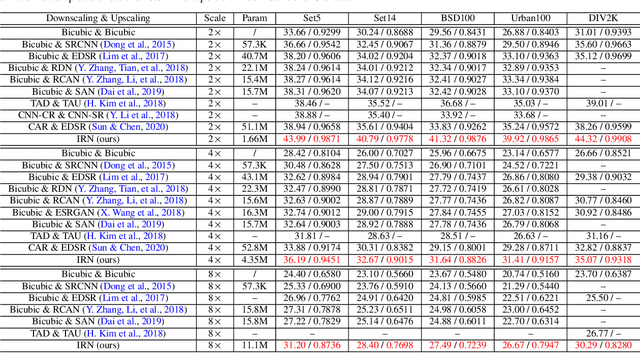
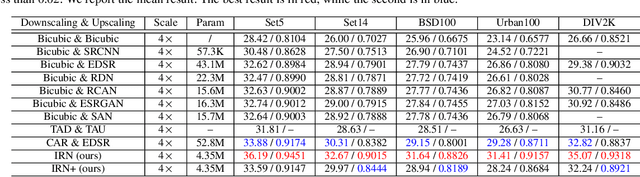
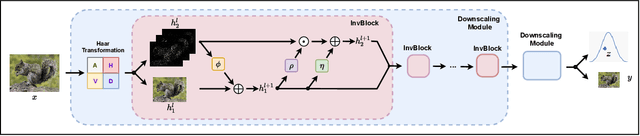
Image rescaling is a commonly used bidirectional operation, which first downscales high-resolution images to fit various display screens or to be storage- and bandwidth-friendly, and afterward upscales the corresponding low-resolution images to recover the original resolution or the details in the zoom-in images. However, the non-injective downscaling mapping discards high-frequency contents, leading to the ill-posed problem for the inverse restoration task. This can be abstracted as a general image degradation-restoration problem with information loss. In this work, we propose a novel invertible framework to handle this general problem, which models the bidirectional degradation and restoration from a new perspective, i.e. invertible bijective transformation. The invertibility enables the framework to model the information loss of pre-degradation in the form of distribution, which could mitigate the ill-posed problem during post-restoration. To be specific, we develop invertible models to generate valid degraded images and meanwhile transform the distribution of lost contents to the fixed distribution of a latent variable during the forward degradation. Then restoration is made tractable by applying the inverse transformation on the generated degraded image together with a randomly-drawn latent variable. We start from image rescaling and instantiate the model as Invertible Rescaling Network (IRN), which can be easily extended to the similar decolorization-colorization task. We further propose to combine the invertible framework with existing degradation methods such as image compression for wider applications. Experimental results demonstrate the significant improvement of our model over existing methods in terms of both quantitative and qualitative evaluations of upscaling and colorizing reconstruction from downscaled and decolorized images, and rate-distortion of image compression.
Online Training Through Time for Spiking Neural Networks
Oct 09, 2022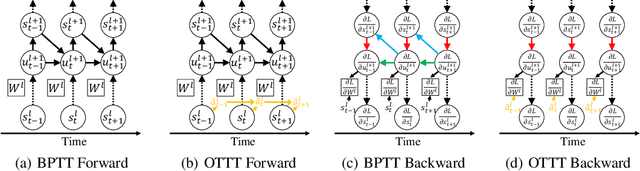
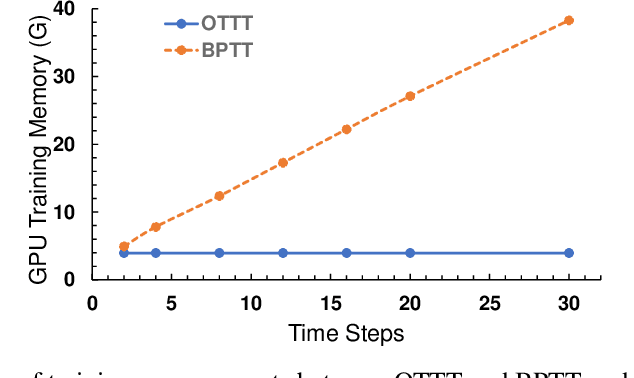
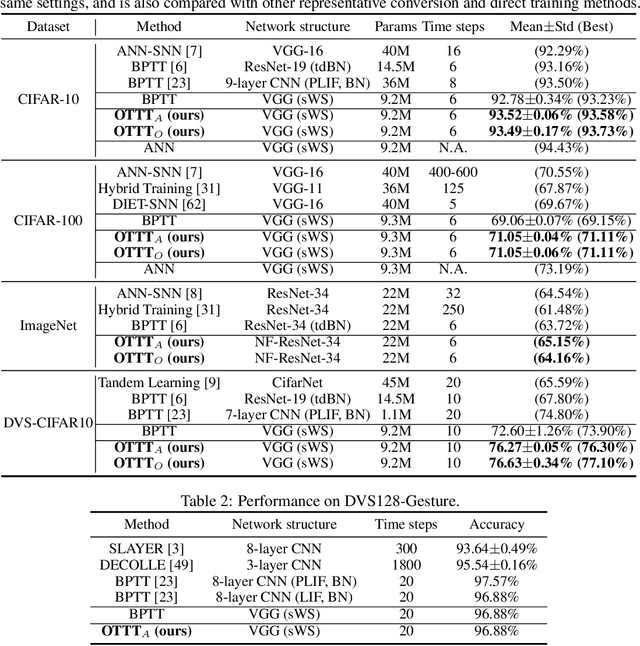
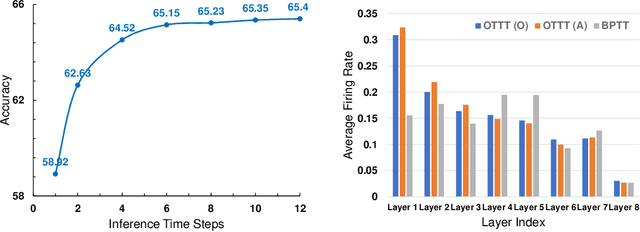
Spiking neural networks (SNNs) are promising brain-inspired energy-efficient models. Recent progress in training methods has enabled successful deep SNNs on large-scale tasks with low latency. Particularly, backpropagation through time (BPTT) with surrogate gradients (SG) is popularly used to achieve high performance in a very small number of time steps. However, it is at the cost of large memory consumption for training, lack of theoretical clarity for optimization, and inconsistency with the online property of biological learning and rules on neuromorphic hardware. Other works connect spike representations of SNNs with equivalent artificial neural network formulation and train SNNs by gradients from equivalent mappings to ensure descent directions. But they fail to achieve low latency and are also not online. In this work, we propose online training through time (OTTT) for SNNs, which is derived from BPTT to enable forward-in-time learning by tracking presynaptic activities and leveraging instantaneous loss and gradients. Meanwhile, we theoretically analyze and prove that gradients of OTTT can provide a similar descent direction for optimization as gradients based on spike representations under both feedforward and recurrent conditions. OTTT only requires constant training memory costs agnostic to time steps, avoiding the significant memory costs of BPTT for GPU training. Furthermore, the update rule of OTTT is in the form of three-factor Hebbian learning, which could pave a path for online on-chip learning. With OTTT, it is the first time that two mainstream supervised SNN training methods, BPTT with SG and spike representation-based training, are connected, and meanwhile in a biologically plausible form. Experiments on CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS demonstrate the superior performance of our method on large-scale static and neuromorphic datasets in small time steps.
Rethinking Knowledge Graph Evaluation Under the Open-World Assumption
Sep 19, 2022
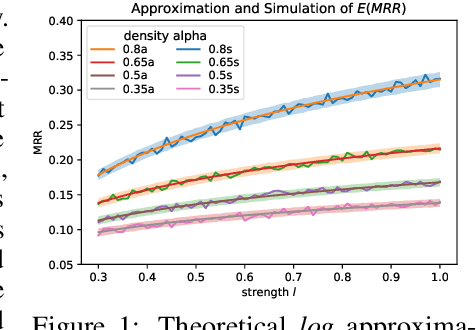
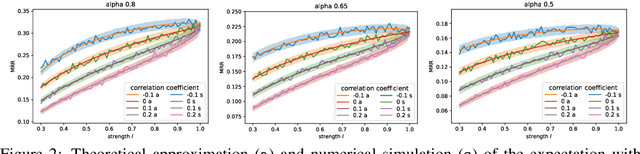
Most knowledge graphs (KGs) are incomplete, which motivates one important research topic on automatically complementing knowledge graphs. However, evaluation of knowledge graph completion (KGC) models often ignores the incompleteness -- facts in the test set are ranked against all unknown triplets which may contain a large number of missing facts not included in the KG yet. Treating all unknown triplets as false is called the closed-world assumption. This closed-world assumption might negatively affect the fairness and consistency of the evaluation metrics. In this paper, we study KGC evaluation under a more realistic setting, namely the open-world assumption, where unknown triplets are considered to include many missing facts not included in the training or test sets. For the currently most used metrics such as mean reciprocal rank (MRR) and Hits@K, we point out that their behavior may be unexpected under the open-world assumption. Specifically, with not many missing facts, their numbers show a logarithmic trend with respect to the true strength of the model, and thus, the metric increase could be insignificant in terms of reflecting the true model improvement. Further, considering the variance, we show that the degradation in the reported numbers may result in incorrect comparisons between different models, where stronger models may have lower metric numbers. We validate the phenomenon both theoretically and experimentally. Finally, we suggest possible causes and solutions for this problem. Our code and data are available at https://github.com/GraphPKU/Open-World-KG .
Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models
Sep 01, 2022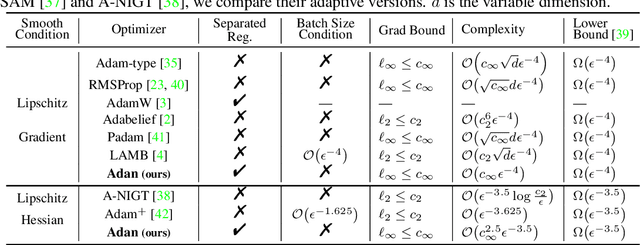
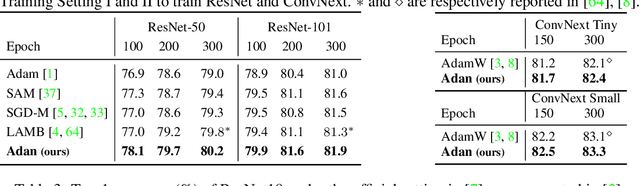
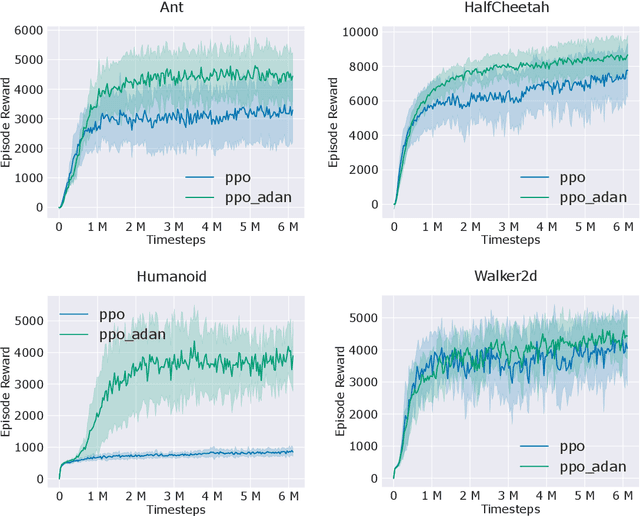
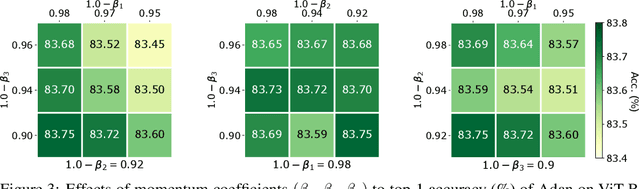
Adaptive gradient algorithms borrow the moving average idea of heavy ball acceleration to estimate accurate first- and second-order moments of gradient for accelerating convergence. However, Nesterov acceleration which converges faster than heavy ball acceleration in theory and also in many empirical cases is much less investigated under the adaptive gradient setting. In this work, we propose the ADAptive Nesterov momentum algorithm, Adan for short, to speed up the training of deep neural networks effectively. Adan first reformulates the vanilla Nesterov acceleration to develop a new Nesterov momentum estimation (NME) method, which avoids the extra computation and memory overhead of computing gradient at the extrapolation point. Then Adan adopts NME to estimate the first- and second-order moments of the gradient in adaptive gradient algorithms for convergence acceleration. Besides, we prove that Adan finds an $\epsilon$-approximate first-order stationary point within $O(\epsilon^{-3.5})$ stochastic gradient complexity on the nonconvex stochastic problems (e.g., deep learning problems), matching the best-known lower bound. Extensive experimental results show that Adan surpasses the corresponding SoTA optimizers on both vision transformers (ViTs) and CNNs, and sets new SoTAs for many popular networks, e.g., ResNet, ConvNext, ViT, Swin, MAE, LSTM, Transformer-XL, and BERT. More surprisingly, Adan can use half of the training cost (epochs) of SoTA optimizers to achieve higher or comparable performance on ViT and ResNet, e.t.c., and also shows great tolerance to a large range of minibatch size, e.g., from 1k to 32k. We hope Adan can contribute to the development of deep learning by reducing training cost and relieving engineering burden of trying different optimizers on various architectures. Code is released at https://github.com/sail-sg/Adan.
PDO-s3DCNNs: Partial Differential Operator Based Steerable 3D CNNs
Aug 07, 2022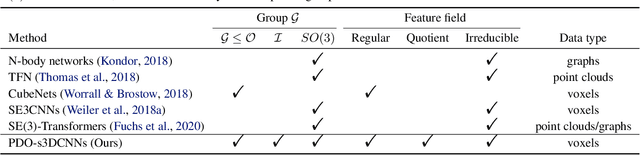
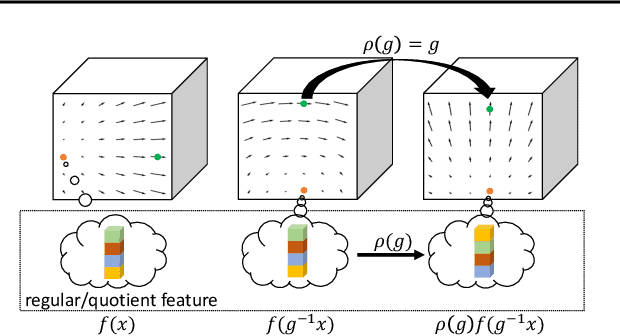

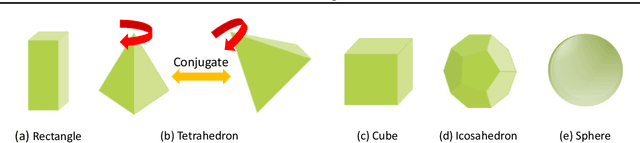
Steerable models can provide very general and flexible equivariance by formulating equivariance requirements in the language of representation theory and feature fields, which has been recognized to be effective for many vision tasks. However, deriving steerable models for 3D rotations is much more difficult than that in the 2D case, due to more complicated mathematics of 3D rotations. In this work, we employ partial differential operators (PDOs) to model 3D filters, and derive general steerable 3D CNNs, which are called PDO-s3DCNNs. We prove that the equivariant filters are subject to linear constraints, which can be solved efficiently under various conditions. As far as we know, PDO-s3DCNNs are the most general steerable CNNs for 3D rotations, in the sense that they cover all common subgroups of $SO(3)$ and their representations, while existing methods can only be applied to specific groups and representations. Extensive experiments show that our models can preserve equivariance well in the discrete domain, and outperform previous works on SHREC'17 retrieval and ISBI 2012 segmentation tasks with a low network complexity.
Optimization-Induced Graph Implicit Nonlinear Diffusion
Jun 29, 2022
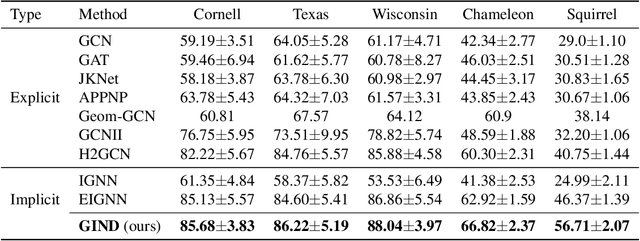
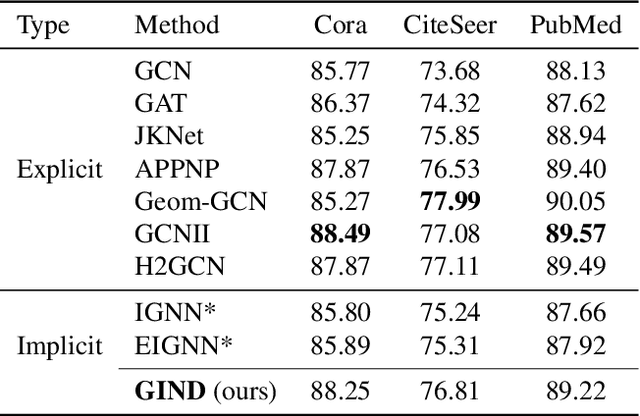
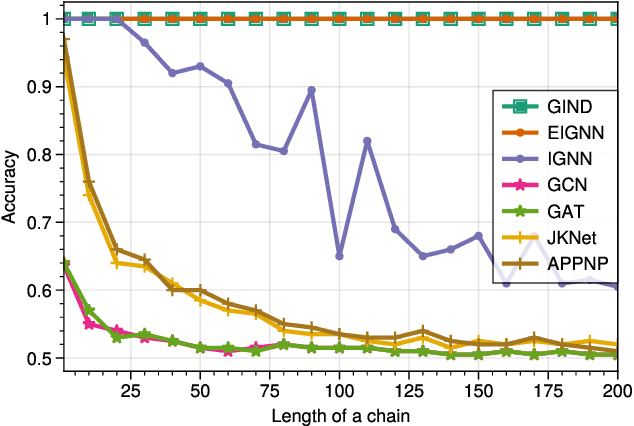
Due to the over-smoothing issue, most existing graph neural networks can only capture limited dependencies with their inherently finite aggregation layers. To overcome this limitation, we propose a new kind of graph convolution, called Graph Implicit Nonlinear Diffusion (GIND), which implicitly has access to infinite hops of neighbors while adaptively aggregating features with nonlinear diffusion to prevent over-smoothing. Notably, we show that the learned representation can be formalized as the minimizer of an explicit convex optimization objective. With this property, we can theoretically characterize the equilibrium of our GIND from an optimization perspective. More interestingly, we can induce new structural variants by modifying the corresponding optimization objective. To be specific, we can embed prior properties to the equilibrium, as well as introducing skip connections to promote training stability. Extensive experiments show that GIND is good at capturing long-range dependencies, and performs well on both homophilic and heterophilic graphs with nonlinear diffusion. Moreover, we show that the optimization-induced variants of our models can boost the performance and improve training stability and efficiency as well. As a result, our GIND obtains significant improvements on both node-level and graph-level tasks.
Two-Dimensional Weisfeiler-Lehman Graph Neural Networks for Link Prediction
Jun 20, 2022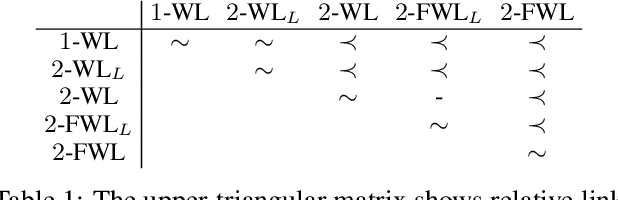


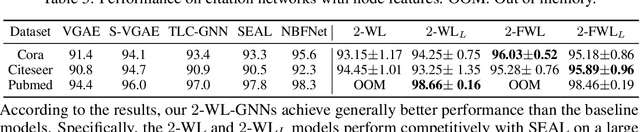
Link prediction is one important application of graph neural networks (GNNs). Most existing GNNs for link prediction are based on one-dimensional Weisfeiler-Lehman (1-WL) test. 1-WL-GNNs first compute node representations by iteratively passing neighboring node features to the center, and then obtain link representations by aggregating the pairwise node representations. As pointed out by previous works, this two-step procedure results in low discriminating power, as 1-WL-GNNs by nature learn node-level representations instead of link-level. In this paper, we study a completely different approach which can directly obtain node pair (link) representations based on \textit{two-dimensional Weisfeiler-Lehman (2-WL) tests}. 2-WL tests directly use links (2-tuples) as message passing units instead of nodes, and thus can directly obtain link representations. We theoretically analyze the expressive power of 2-WL tests to discriminate non-isomorphic links, and prove their superior link discriminating power than 1-WL. Based on different 2-WL variants, we propose a series of novel 2-WL-GNN models for link prediction. Experiments on a wide range of real-world datasets demonstrate their competitive performance to state-of-the-art baselines and superiority over plain 1-WL-GNNs.
Global Convergence of Over-parameterized Deep Equilibrium Models
May 27, 2022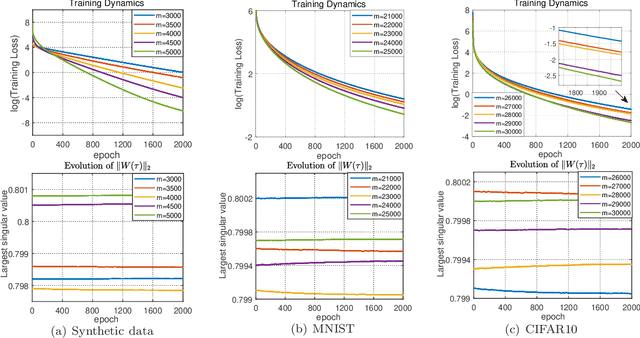
A deep equilibrium model (DEQ) is implicitly defined through an equilibrium point of an infinite-depth weight-tied model with an input-injection. Instead of infinite computations, it solves an equilibrium point directly with root-finding and computes gradients with implicit differentiation. The training dynamics of over-parameterized DEQs are investigated in this study. By supposing a condition on the initial equilibrium point, we show that the unique equilibrium point always exists during the training process, and the gradient descent is proved to converge to a globally optimal solution at a linear convergence rate for the quadratic loss function. In order to show that the required initial condition is satisfied via mild over-parameterization, we perform a fine-grained analysis on random DEQs. We propose a novel probabilistic framework to overcome the technical difficulty in the non-asymptotic analysis of infinite-depth weight-tied models.
SymNMF-Net for The Symmetric NMF Problem
May 26, 2022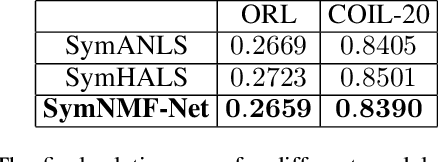
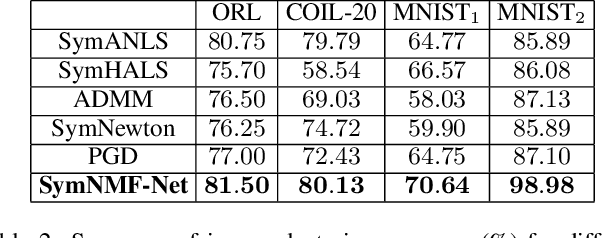
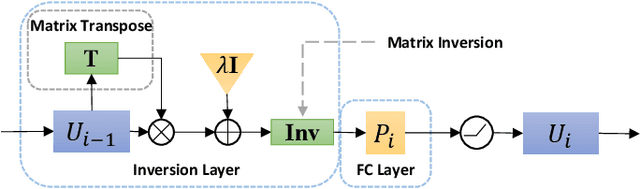
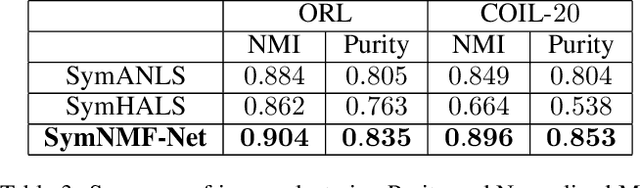
Recently, many works have demonstrated that Symmetric Non-negative Matrix Factorization~(SymNMF) enjoys a great superiority for various clustering tasks. Although the state-of-the-art algorithms for SymNMF perform well on synthetic data, they cannot consistently obtain satisfactory results with desirable properties and may fail on real-world tasks like clustering. Considering the flexibility and strong representation ability of the neural network, in this paper, we propose a neural network called SymNMF-Net for the Symmetric NMF problem to overcome the shortcomings of traditional optimization algorithms. Each block of SymNMF-Net is a differentiable architecture with an inversion layer, a linear layer and ReLU, which are inspired by a traditional update scheme for SymNMF. We show that the inference of each block corresponds to a single iteration of the optimization. Furthermore, we analyze the constraints of the inversion layer to ensure the output stability of the network to a certain extent. Empirical results on real-world datasets demonstrate the superiority of our SymNMF-Net and confirm the sufficiency of our theoretical analysis.
Training High-Performance Low-Latency Spiking Neural Networks by Differentiation on Spike Representation
May 01, 2022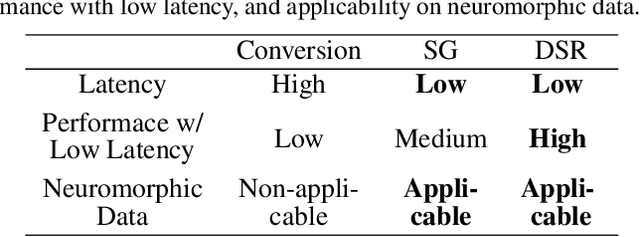
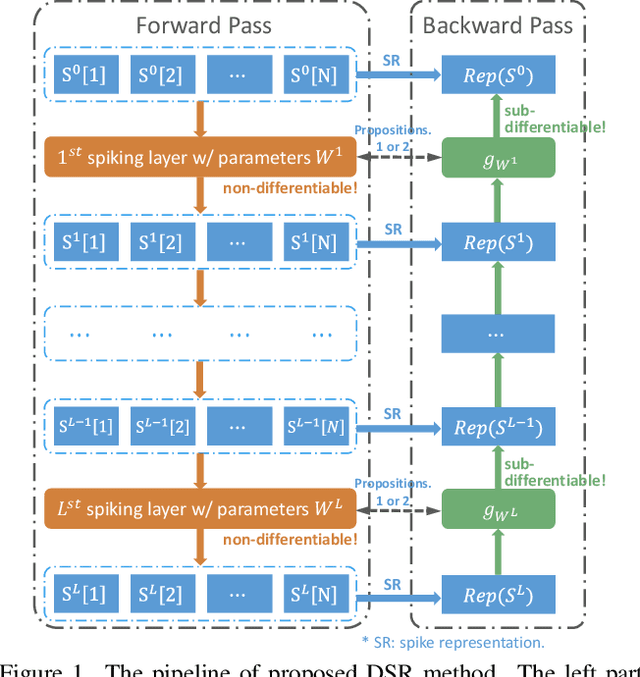
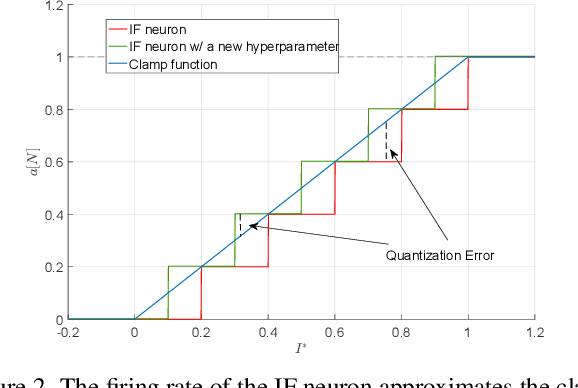
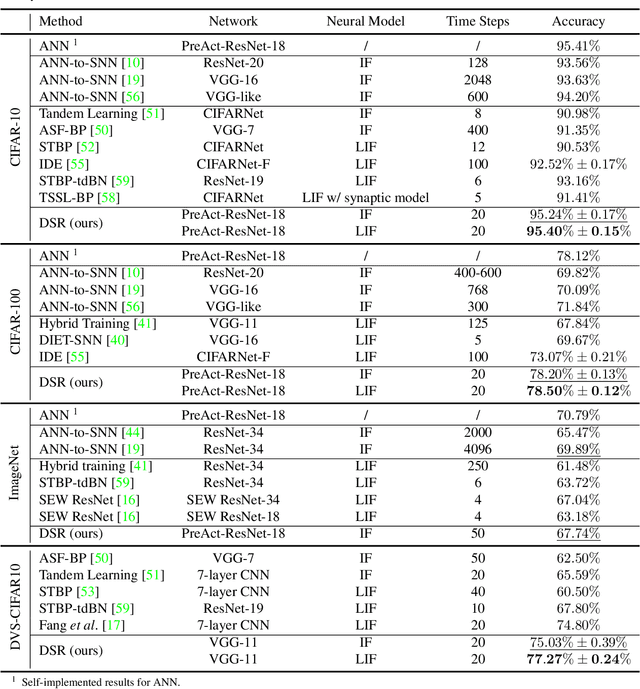
Spiking Neural Network (SNN) is a promising energy-efficient AI model when implemented on neuromorphic hardware. However, it is a challenge to efficiently train SNNs due to their non-differentiability. Most existing methods either suffer from high latency (i.e., long simulation time steps), or cannot achieve as high performance as Artificial Neural Networks (ANNs). In this paper, we propose the Differentiation on Spike Representation (DSR) method, which could achieve high performance that is competitive to ANNs yet with low latency. First, we encode the spike trains into spike representation using (weighted) firing rate coding. Based on the spike representation, we systematically derive that the spiking dynamics with common neural models can be represented as some sub-differentiable mapping. With this viewpoint, our proposed DSR method trains SNNs through gradients of the mapping and avoids the common non-differentiability problem in SNN training. Then we analyze the error when representing the specific mapping with the forward computation of the SNN. To reduce such error, we propose to train the spike threshold in each layer, and to introduce a new hyperparameter for the neural models. With these components, the DSR method can achieve state-of-the-art SNN performance with low latency on both static and neuromorphic datasets, including CIFAR-10, CIFAR-100, ImageNet, and DVS-CIFAR10.