 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Analysis for Nonconvex SGD Escaping from Saddle Points
Feb 01, 2019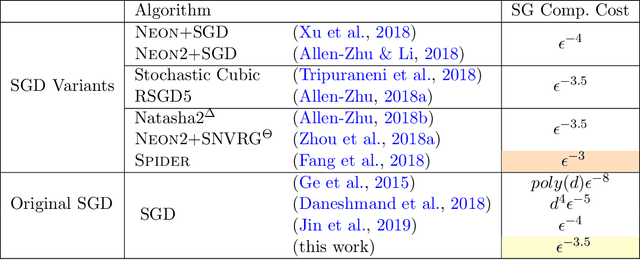
In this paper, we prove that the simplest Stochastic Gradient Descent (SGD) algorithm is able to efficiently escape from saddle points and find an $(\epsilon, O(\epsilon^{0.5}))$-approximate second-order stationary point in $\tilde{O}(\epsilon^{-3.5})$ stochastic gradient computations for generic nonconvex optimization problems, under both gradient-Lipschitz and Hessian-Lipschitz assumptions. This unexpected result subverts the classical belief that SGD requires at least $O(\epsilon^{-4})$ stochastic gradient computations for obtaining an $(\epsilon, O(\epsilon ^{0.5}))$-approximate second-order stationary point. Such SGD rate matches, up to a polylogarithmic factor of problem-dependent parameters, the rate of most accelerated nonconvex stochastic optimization algorithms that adopt additional techniques, such as Nesterov's momentum acceleration, negative curvature search, as well as quadratic and cubic regularization tricks. Our novel analysis gives new insights into nonconvex SGD and can be potentially generalized to a broad class of stochastic optimization algorithms.
Lifted Proximal Operator Machines
Nov 05, 2018
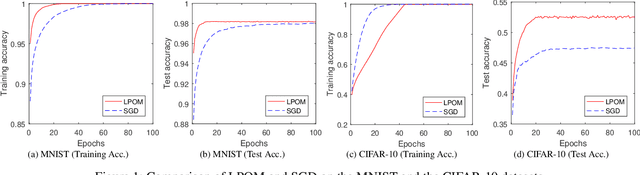

We propose a new optimization method for training feed-forward neural networks. By rewriting the activation function as an equivalent proximal operator, we approximate a feed-forward neural network by adding the proximal operators to the objective function as penalties, hence we call the lifted proximal operator machine (LPOM). LPOM is block multi-convex in all layer-wise weights and activations. This allows us to use block coordinate descent to update the layer-wise weights and activations in parallel. Most notably, we only use the mapping of the activation function itself, rather than its derivatives, thus avoiding the gradient vanishing or blow-up issues in gradient based training methods. So our method is applicable to various non-decreasing Lipschitz continuous activation functions, which can be saturating and non-differentiable. LPOM does not require more auxiliary variables than the layer-wise activations, thus using roughly the same amount of memory as stochastic gradient descent (SGD) does. We further prove the convergence of updating the layer-wise weights and activations. Experiments on MNIST and CIFAR-10 datasets testify to the advantages of LPOM.
Joint Sub-bands Learning with Clique Structures for Wavelet Domain Super-Resolution
Oct 25, 2018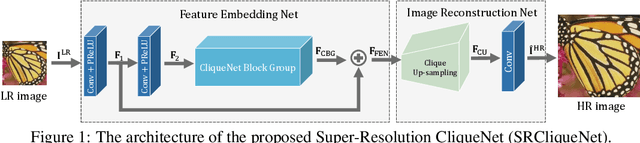
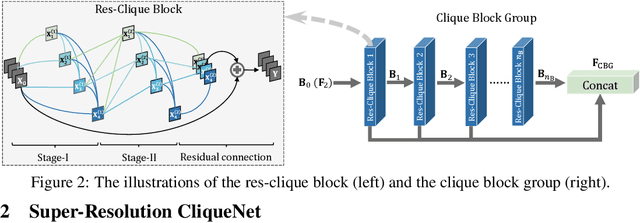
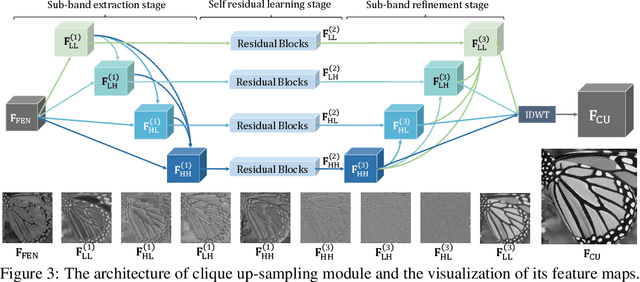
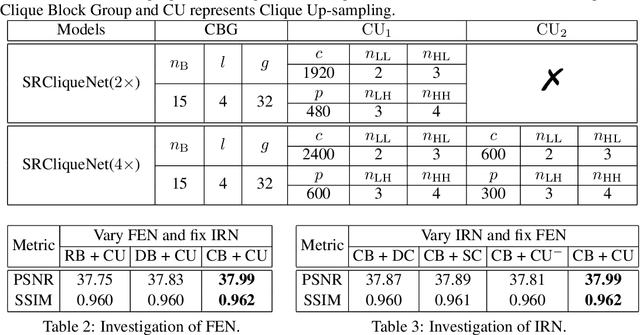
Convolutional neural networks (CNNs) have recently achieved great success in single-image super-resolution (SISR). However, these methods tend to produce over-smoothed outputs and miss some textural details. To solve these problems, we propose the Super-Resolution CliqueNet (SRCliqueNet) to reconstruct the high resolution (HR) image with better textural details in the wavelet domain. The proposed SRCliqueNet firstly extracts a set of feature maps from the low resolution (LR) image by the clique blocks group. Then we send the set of feature maps to the clique up-sampling module to reconstruct the HR image. The clique up-sampling module consists of four sub-nets which predict the high resolution wavelet coefficients of four sub-bands. Since we consider the edge feature properties of four sub-bands, the four sub-nets are connected to the others so that they can learn the coefficients of four sub-bands jointly. Finally we apply inverse discrete wavelet transform (IDWT) to the output of four sub-nets at the end of the clique up-sampling module to increase the resolution and reconstruct the HR image. Extensive quantitative and qualitative experiments on benchmark datasets show that our method achieves superior performance over the state-of-the-art methods.
SPIDER: Near-Optimal Non-Convex Optimization via Stochastic Path Integrated Differential Estimator
Oct 17, 2018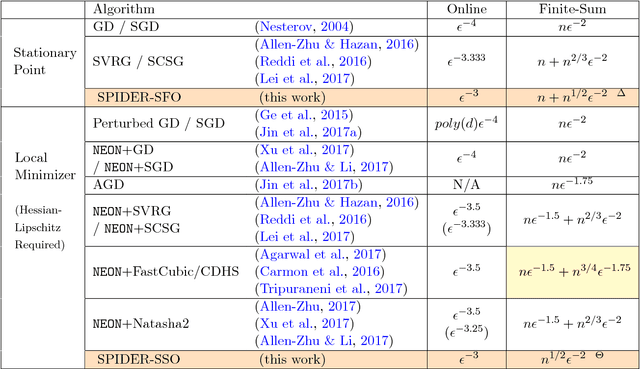
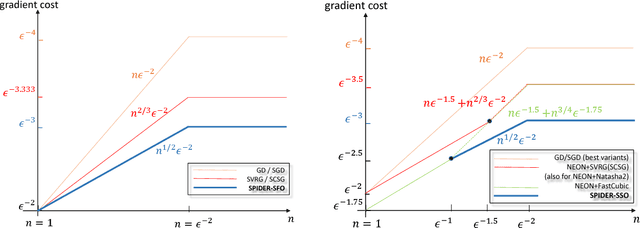
In this paper, we propose a new technique named \textit{Stochastic Path-Integrated Differential EstimatoR} (SPIDER), which can be used to track many deterministic quantities of interest with significantly reduced computational cost. We apply SPIDER to two tasks, namely the stochastic first-order and zeroth-order methods. For stochastic first-order method, combining SPIDER with normalized gradient descent, we propose two new algorithms, namely SPIDER-SFO and SPIDER-SFO\textsuperscript{+}, that solve non-convex stochastic optimization problems using stochastic gradients only. We provide sharp error-bound results on their convergence rates. In special, we prove that the SPIDER-SFO and SPIDER-SFO\textsuperscript{+} algorithms achieve a record-breaking gradient computation cost of $\mathcal{O}\left( \min( n^{1/2} \epsilon^{-2}, \epsilon^{-3} ) \right)$ for finding an $\epsilon$-approximate first-order and $\tilde{\mathcal{O}}\left( \min( n^{1/2} \epsilon^{-2}+\epsilon^{-2.5}, \epsilon^{-3} ) \right)$ for finding an $(\epsilon, \mathcal{O}(\epsilon^{0.5}))$-approximate second-order stationary point, respectively. In addition, we prove that SPIDER-SFO nearly matches the algorithmic lower bound for finding approximate first-order stationary points under the gradient Lipschitz assumption in the finite-sum setting. For stochastic zeroth-order method, we prove a cost of $\mathcal{O}( d \min( n^{1/2} \epsilon^{-2}, \epsilon^{-3}) )$ which outperforms all existing results.
Bilinear Factor Matrix Norm Minimization for Robust PCA: Algorithms and Applications
Oct 11, 2018

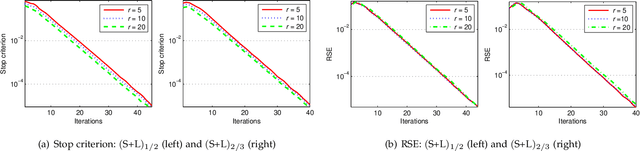
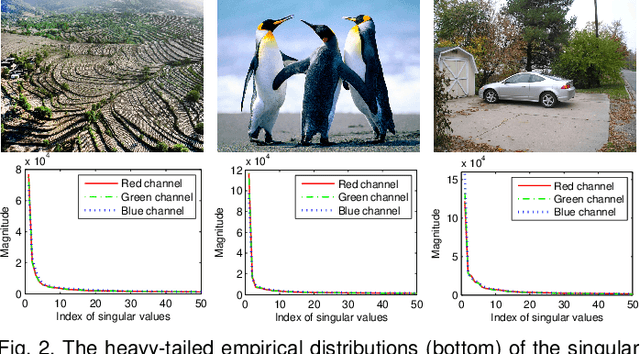
The heavy-tailed distributions of corrupted outliers and singular values of all channels in low-level vision have proven effective priors for many applications such as background modeling, photometric stereo and image alignment. And they can be well modeled by a hyper-Laplacian. However, the use of such distributions generally leads to challenging non-convex, non-smooth and non-Lipschitz problems, and makes existing algorithms very slow for large-scale applications. Together with the analytic solutions to lp-norm minimization with two specific values of p, i.e., p=1/2 and p=2/3, we propose two novel bilinear factor matrix norm minimization models for robust principal component analysis. We first define the double nuclear norm and Frobenius/nuclear hybrid norm penalties, and then prove that they are in essence the Schatten-1/2 and 2/3 quasi-norms, respectively, which lead to much more tractable and scalable Lipschitz optimization problems. Our experimental analysis shows that both our methods yield more accurate solutions than original Schatten quasi-norm minimization, even when the number of observations is very limited. Finally, we apply our penalties to various low-level vision problems, e.g., text removal, moving object detection, image alignment and inpainting, and show that our methods usually outperform the state-of-the-art methods.
* 29 pages, 19 figures
Optimization Algorithm Inspired Deep Neural Network Structure Design
Oct 03, 2018
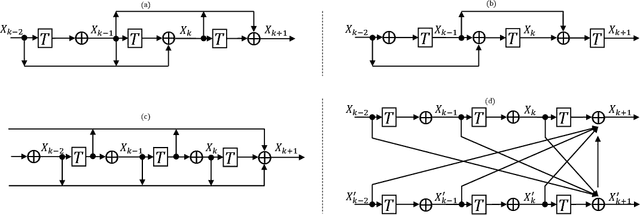
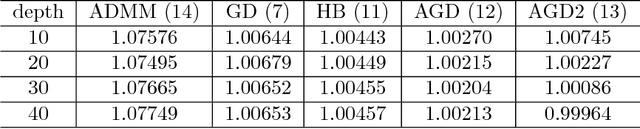
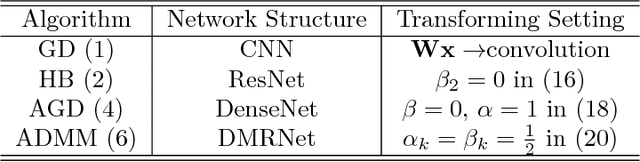
Deep neural networks have been one of the dominant machine learning approaches in recent years. Several new network structures are proposed and have better performance than the traditional feedforward neural network structure. Representative ones include the skip connection structure in ResNet and the dense connection structure in DenseNet. However, it still lacks a unified guidance for the neural network structure design. In this paper, we propose the hypothesis that the neural network structure design can be inspired by optimization algorithms and a faster optimization algorithm may lead to a better neural network structure. Specifically, we prove that the propagation in the feedforward neural network with the same linear transformation in different layers is equivalent to minimizing some function using the gradient descent algorithm. Based on this observation, we replace the gradient descent algorithm with the heavy ball algorithm and Nesterov's accelerated gradient descent algorithm, which are faster and inspire us to design new and better network structures. ResNet and DenseNet can be considered as two special cases of our framework. Numerical experiments on CIFAR-10, CIFAR-100 and ImageNet verify the advantage of our optimization algorithm inspired structures over ResNet and DenseNet.
On the Convergence of Learning-based Iterative Methods for Nonconvex Inverse Problems
Aug 16, 2018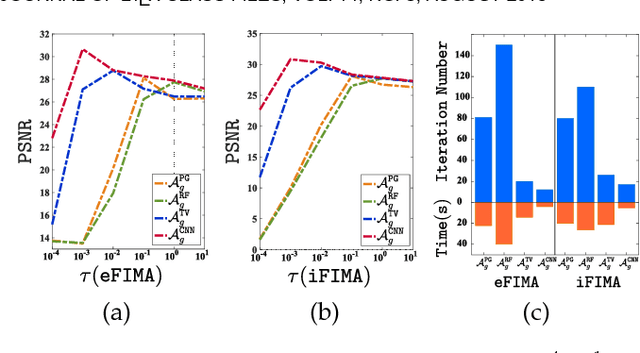
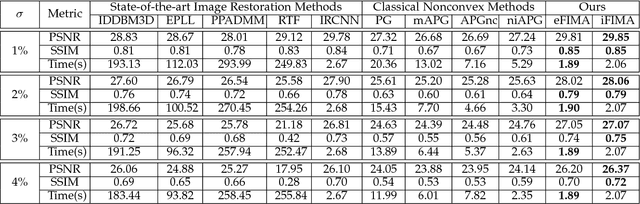
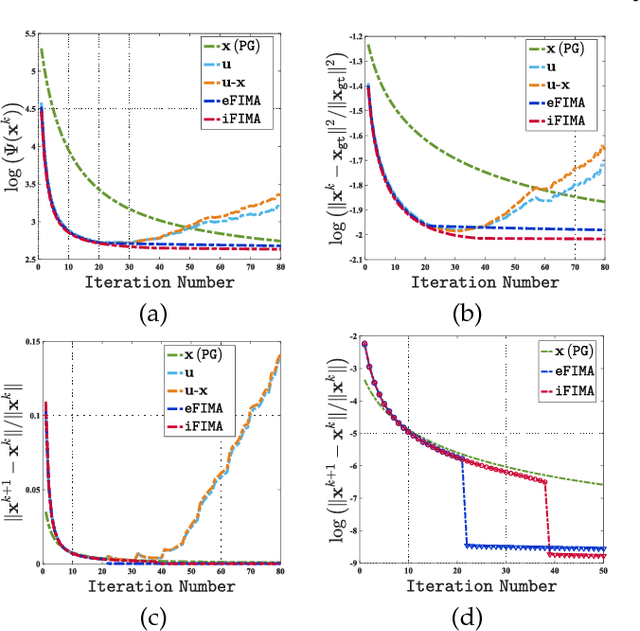
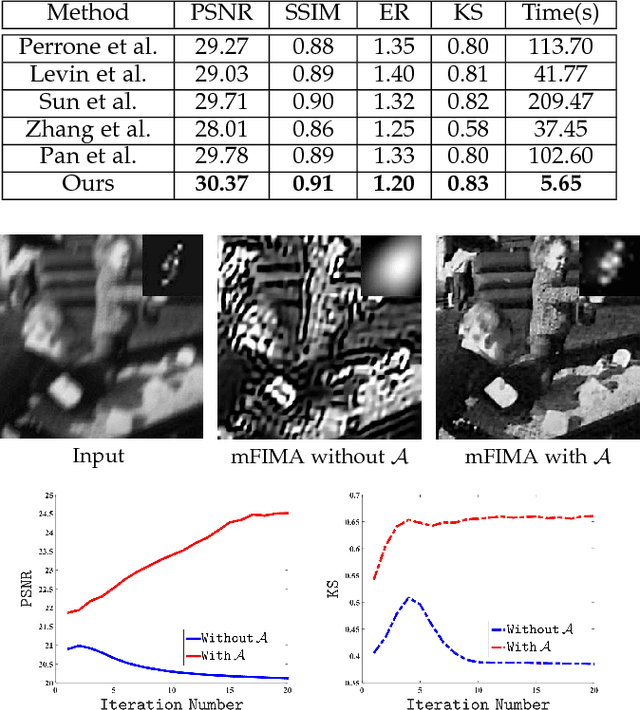
Numerous tasks at the core of statistics, learning and vision areas are specific cases of ill-posed inverse problems. Recently, learning-based (e.g., deep) iterative methods have been empirically shown to be useful for these problems. Nevertheless, integrating learnable structures into iterations is still a laborious process, which can only be guided by intuitions or empirical insights. Moreover, there is a lack of rigorous analysis about the convergence behaviors of these reimplemented iterations, and thus the significance of such methods is a little bit vague. This paper moves beyond these limits and proposes Flexible Iterative Modularization Algorithm (FIMA), a generic and provable paradigm for nonconvex inverse problems. Our theoretical analysis reveals that FIMA allows us to generate globally convergent trajectories for learning-based iterative methods. Meanwhile, the devised scheduling policies on flexible modules should also be beneficial for classical numerical methods in the nonconvex scenario. Extensive experiments on real applications verify the superiority of FIMA.
Recurrent Squeeze-and-Excitation Context Aggregation Net for Single Image Deraining
Jul 28, 2018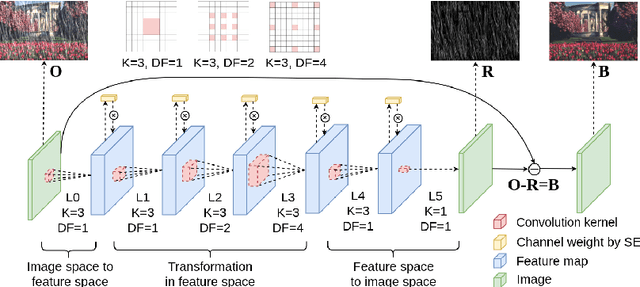
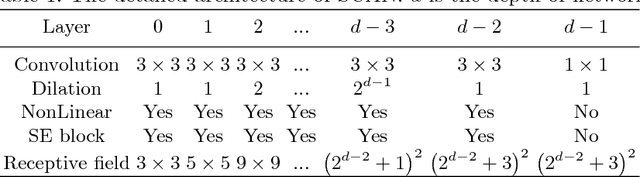
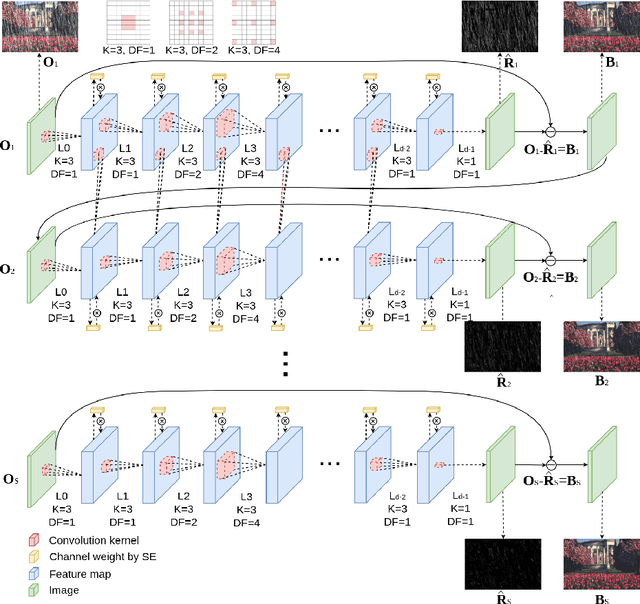
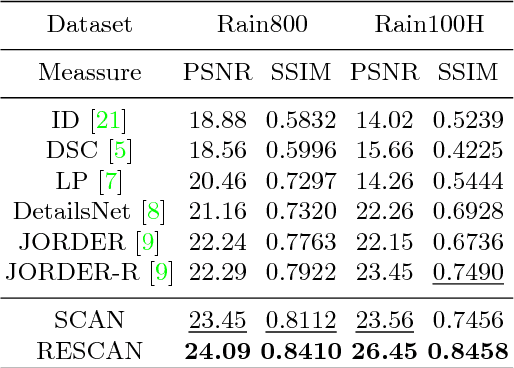
Rain streaks can severely degrade the visibility, which causes many current computer vision algorithms fail to work. So it is necessary to remove the rain from images. We propose a novel deep network architecture based on deep convolutional and recurrent neural networks for single image deraining. As contextual information is very important for rain removal, we first adopt the dilated convolutional neural network to acquire large receptive field. To better fit the rain removal task, we also modify the network. In heavy rain, rain streaks have various directions and shapes, which can be regarded as the accumulation of multiple rain streak layers. We assign different alpha-values to various rain streak layers according to the intensity and transparency by incorporating the squeeze-and-excitation block. Since rain streak layers overlap with each other, it is not easy to remove the rain in one stage. So we further decompose the rain removal into multiple stages. Recurrent neural network is incorporated to preserve the useful information in previous stages and benefit the rain removal in later stages. We conduct extensive experiments on both synthetic and real-world datasets. Our proposed method outperforms the state-of-the-art approaches under all evaluation metrics. Codes and supplementary material are available at our project webpage: https://xialipku.github.io/RESCAN .
Essential Tensor Learning for Multi-view Spectral Clustering
Jul 10, 2018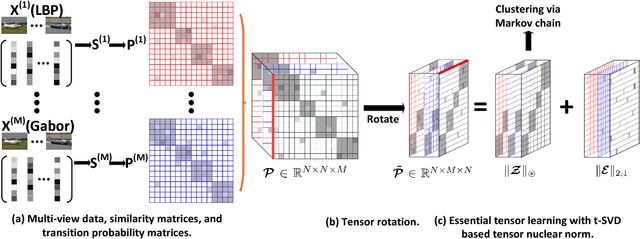
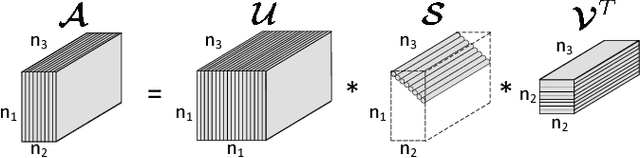

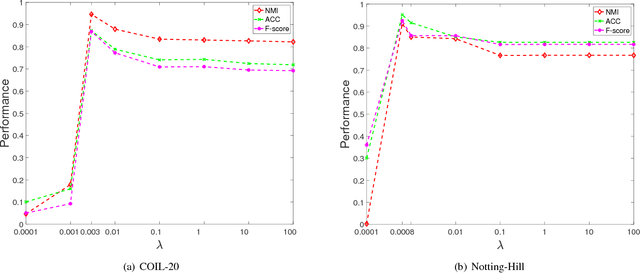
Multi-view clustering attracts much attention recently, which aims to take advantage of multi-view information to improve the performance of clustering. However, most recent work mainly focus on self-representation based subspace clustering, which is of high computation complexity. In this paper, we focus on the Markov chain based spectral clustering method and propose a novel essential tensor learning method to explore the high order correlations for multi-view representation. We first construct a tensor based on multi-view transition probability matrices of the Markov chain. By incorporating the idea from robust principle component analysis, tensor singular value decomposition (t-SVD) based tensor nuclear norm is imposed to preserve the low-rank property of the essential tensor, which can well capture the principle information from multiple views. We also employ the tensor rotation operator for this task to better investigate the relationship among views as well as reduce the computation complexity. The proposed method can be efficiently optimized by the alternating direction method of multipliers~(ADMM). Extensive experiments on six real world datasets corresponding to five different applications show that our method achieves superior performance over other state-of-the-art methods.
Exact Low Tubal Rank Tensor Recovery from Gaussian Measurements
Jun 07, 2018
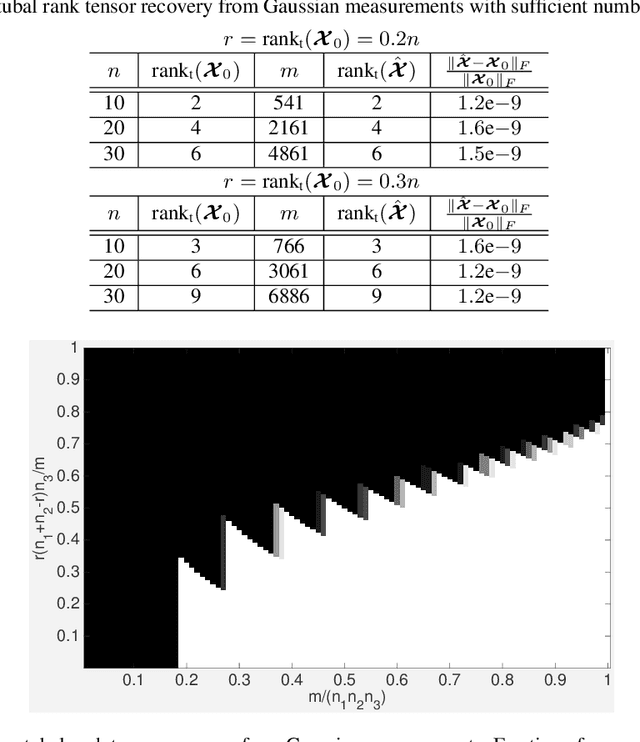
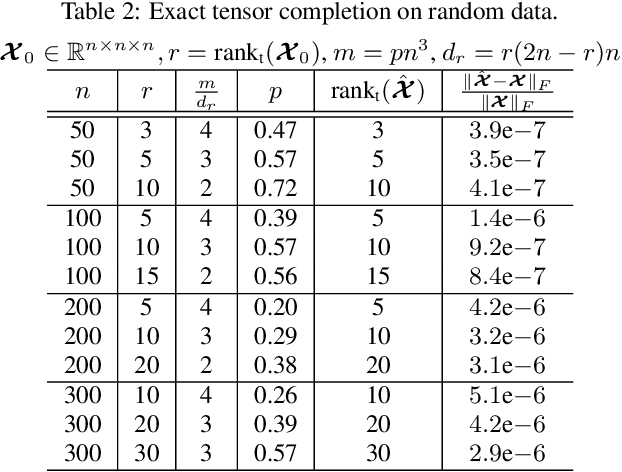
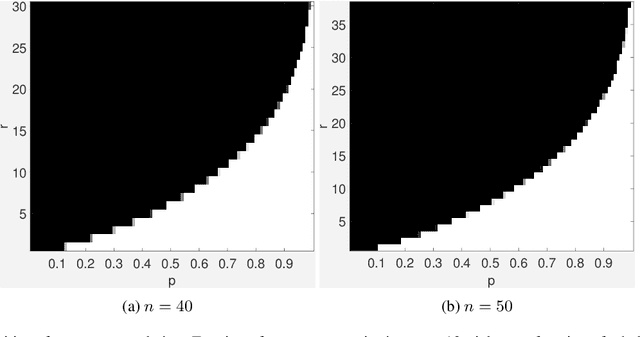
The recent proposed Tensor Nuclear Norm (TNN) [Lu et al., 2016; 2018a] is an interesting convex penalty induced by the tensor SVD [Kilmer and Martin, 2011]. It plays a similar role as the matrix nuclear norm which is the convex surrogate of the matrix rank. Considering that the TNN based Tensor Robust PCA [Lu et al., 2018a] is an elegant extension of Robust PCA with a similar tight recovery bound, it is natural to solve other low rank tensor recovery problems extended from the matrix cases. However, the extensions and proofs are generally tedious. The general atomic norm provides a unified view of low-complexity structures induced norms, e.g., the $\ell_1$-norm and nuclear norm. The sharp estimates of the required number of generic measurements for exact recovery based on the atomic norm are known in the literature. In this work, with a careful choice of the atomic set, we prove that TNN is a special atomic norm. Then by computing the Gaussian width of certain cone which is necessary for the sharp estimate, we achieve a simple bound for guaranteed low tubal rank tensor recovery from Gaussian measurements. Specifically, we show that by solving a TNN minimization problem, the underlying tensor of size $n_1\times n_2\times n_3$ with tubal rank $r$ can be exactly recovered when the given number of Gaussian measurements is $O(r(n_1+n_2-r)n_3)$. It is order optimal when comparing with the degrees of freedom $r(n_1+n_2-r)n_3$. Beyond the Gaussian mapping, we also give the recovery guarantee of tensor completion based on the uniform random mapping by TNN minimization. Numerical experiments verify our theoretical results.