 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
ACE-RTL: When Agentic Context Evolution Meets RTL-Specialized LLMs
Feb 10, 2026Recent advances in large language models (LLMs) have sparked growing interest in applying them to hardware design automation, particularly for accurate RTL code generation. Prior efforts follow two largely independent paths: (i) training domain-adapted RTL models to internalize hardware semantics, (ii) developing agentic systems that leverage frontier generic LLMs guided by simulation feedback. However, these two paths exhibit complementary strengths and weaknesses. In this work, we present ACE-RTL that unifies both directions through Agentic Context Evolution (ACE). ACE-RTL integrates an RTL-specialized LLM, trained on a large-scale dataset of 1.7 million RTL samples, with a frontier reasoning LLM through three synergistic components: the generator, reflector, and coordinator. These components iteratively refine RTL code toward functional correctness. We further introduce a parallel scaling strategy that significantly reduces the number of iterations required to reach correct solutions. On the Comprehensive Verilog Design Problems (CVDP) benchmark, ACE-RTL achieves up to a 44.87% pass rate improvement over 14 competitive baselines while requiring only four iterations on average.
GRPO with State Mutations: Improving LLM-Based Hardware Test Plan Generation
Jan 12, 2026RTL design often relies heavily on ad-hoc testbench creation early in the design cycle. While large language models (LLMs) show promise for RTL code generation, their ability to reason about hardware specifications and generate targeted test plans remains largely unexplored. We present the first systematic study of LLM reasoning capabilities for RTL verification stimuli generation, establishing a two-stage framework that decomposes test plan generation from testbench execution. Our benchmark reveals that state-of-the-art models, including DeepSeek-R1 and Claude-4.0-Sonnet, achieve only 15.7-21.7% success rates on generating stimuli that pass golden RTL designs. To improve LLM generated stimuli, we develop a comprehensive training methodology combining supervised fine-tuning with a novel reinforcement learning approach, GRPO with State Mutation (GRPO-SMu), which enhances exploration by varying input mutations. Our approach leverages a tree-based branching mutation strategy to construct training data comprising equivalent and mutated trees, moving beyond linear mutation approaches to provide rich learning signals. Training on this curated dataset, our 7B parameter model achieves a 33.3% golden test pass rate and a 13.9% mutation detection rate, representing a 17.6% absolute improvement over baseline and outperforming much larger general-purpose models. These results demonstrate that specialized training methodologies can significantly enhance LLM reasoning capabilities for hardware verification tasks, establishing a foundation for automated sub-unit testing in semiconductor design workflows.
ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation
Jun 05, 2025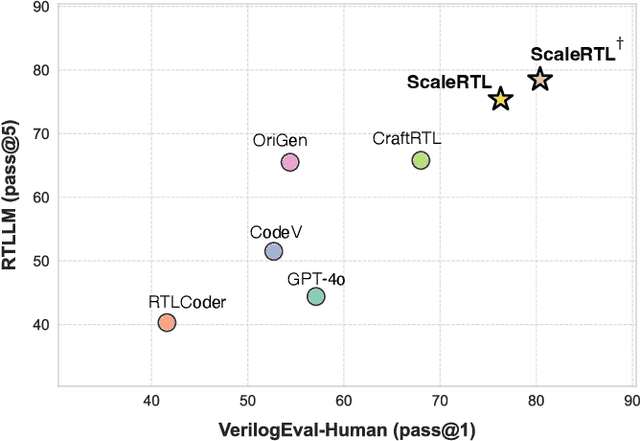
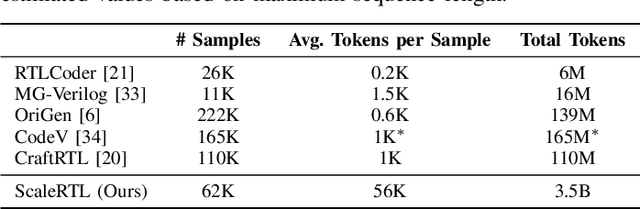
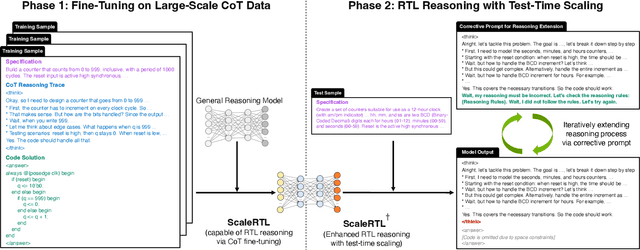
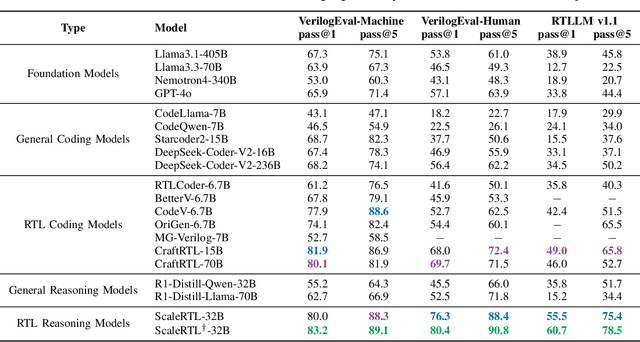
Recent advances in large language models (LLMs) have enabled near-human performance on software coding benchmarks, but their effectiveness in RTL code generation remains limited due to the scarcity of high-quality training data. While prior efforts have fine-tuned LLMs for RTL tasks, they do not fundamentally overcome the data bottleneck and lack support for test-time scaling due to their non-reasoning nature. In this work, we introduce ScaleRTL, the first reasoning LLM for RTL coding that scales up both high-quality reasoning data and test-time compute. Specifically, we curate a diverse set of long chain-of-thought reasoning traces averaging 56K tokens each, resulting in a dataset of 3.5B tokens that captures rich RTL knowledge. Fine-tuning a general-purpose reasoning model on this corpus yields ScaleRTL that is capable of deep RTL reasoning. Subsequently, we further enhance the performance of ScaleRTL through a novel test-time scaling strategy that extends the reasoning process via iteratively reflecting on and self-correcting previous reasoning steps. Experimental results show that ScaleRTL achieves state-of-the-art performance on VerilogEval and RTLLM, outperforming 18 competitive baselines by up to 18.4% on VerilogEval and 12.7% on RTLLM.
Addressing Long-Horizon Tasks by Integrating Program Synthesis and State Machines
Nov 27, 2023Deep reinforcement learning excels in various domains but lacks generalizability and interoperability. Programmatic RL methods (Trivedi et al., 2021; Liu et al., 2023) reformulate solving RL tasks as synthesizing interpretable programs that can be executed in the environments. Despite encouraging results, these methods are limited to short-horizon tasks. On the other hand, representing RL policies using state machines (Inala et al., 2020) can inductively generalize to long-horizon tasks; however, it struggles to scale up to acquire diverse and complex behaviors. This work proposes Program Machine Policies (POMPs), which bridge the advantages of programmatic RL and state machine policies, allowing for the representation of complex behaviors and the address of long-term tasks. Specifically, we introduce a method that can retrieve a set of effective, diverse, compatible programs. Then, we use these programs as modes of a state machine and learn a transition function to transition among mode programs, allowing for capturing long-horizon repetitive behaviors. Our proposed framework outperforms programmatic RL and deep RL baselines on various tasks and demonstrates the ability to generalize to even longer horizons without any fine-tuning inductively. Ablation studies justify the effectiveness of our proposed search algorithm for retrieving a set of programs as modes.
Hierarchical Programmatic Reinforcement Learning via Learning to Compose Programs
Jan 30, 2023



Aiming to produce reinforcement learning (RL) policies that are human-interpretable and can generalize better to novel scenarios, Trivedi et al. (2021) present a method (LEAPS) that first learns a program embedding space to continuously parameterize diverse programs from a pre-generated program dataset, and then searches for a task-solving program in the learned program embedding space when given a task. Despite encouraging results, the program policies that LEAPS can produce are limited by the distribution of the program dataset. Furthermore, during searching, LEAPS evaluates each candidate program solely based on its return, failing to precisely reward correct parts of programs and penalize incorrect parts. To address these issues, we propose to learn a meta-policy that composes a series of programs sampled from the learned program embedding space. By composing programs, our proposed method can produce program policies that describe out-of-distributionally complex behaviors and directly assign credits to programs that induce desired behaviors. We design and conduct extensive experiments in the Karel domain. The experimental results show that our proposed framework outperforms baselines. The ablation studies confirm the limitations of LEAPS and justify our design choices.