 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Learning for Neural Machine Translation
Sep 03, 2019
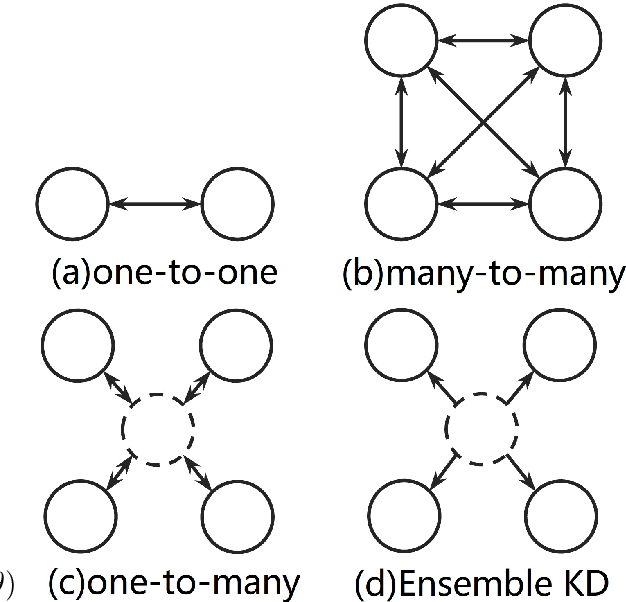
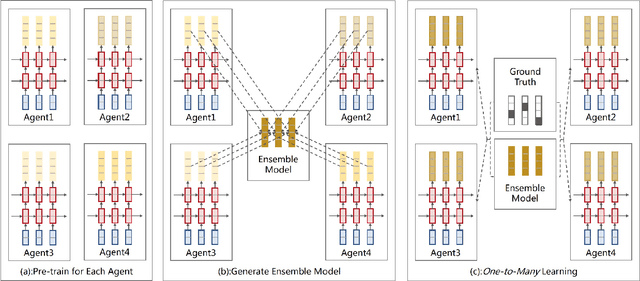
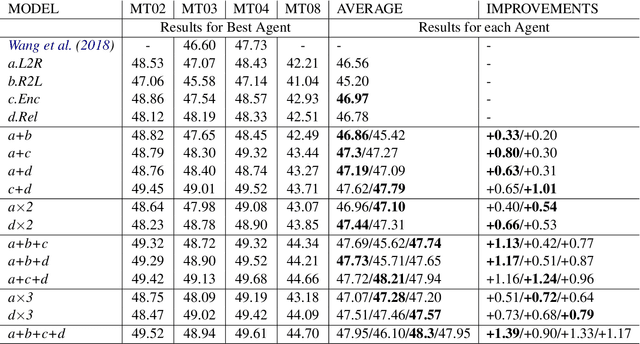
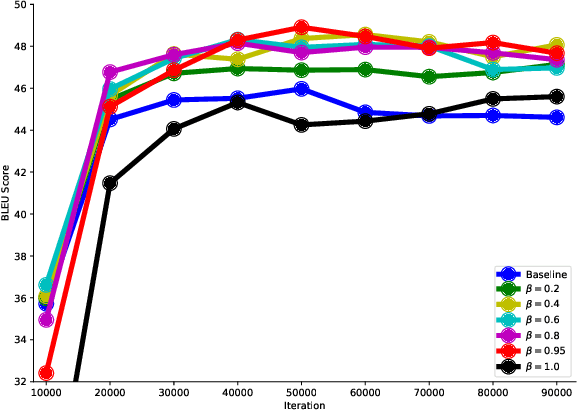
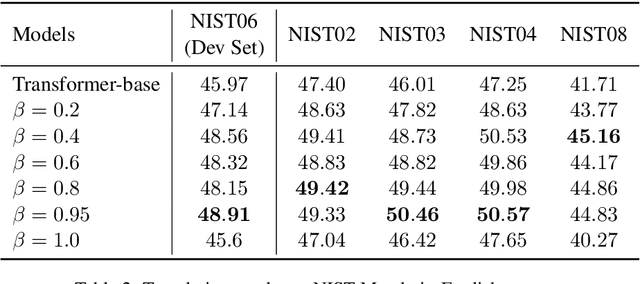
Conventional Neural Machine Translation (NMT) models benefit from the training with an additional agent, e.g., dual learning, and bidirectional decoding with one agent decoding from left to right and the other decoding in the opposite direction. In this paper, we extend the training framework to the multi-agent scenario by introducing diverse agents in an interactive updating process. At training time, each agent learns advanced knowledge from others, and they work together to improve translation quality. Experimental results on NIST Chinese-English, IWSLT 2014 German-English, WMT 2014 English-German and large-scale Chinese-English translation tasks indicate that our approach achieves absolute improvements over the strong baseline systems and shows competitive performance on all tasks.
DuTongChuan: Context-aware Translation Model for Simultaneous Interpreting
Aug 16, 2019


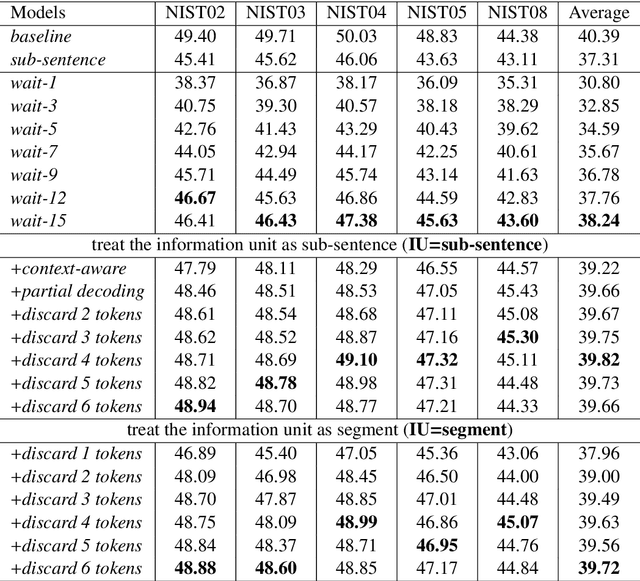
In this paper, we present DuTongChuan, a novel context-aware translation model for simultaneous interpreting. This model allows to constantly read streaming text from the Automatic Speech Recognition (ASR) model and simultaneously determine the boundaries of Information Units (IUs) one after another. The detected IU is then translated into a fluent translation with two simple yet effective decoding strategies: partial decoding and context-aware decoding. In practice, by controlling the granularity of IUs and the size of the context, we can get a good trade-off between latency and translation quality easily. Elaborate evaluation from human translators reveals that our system achieves promising translation quality (85.71% for Chinese-English, and 86.36% for English-Chinese), specially in the sense of surprisingly good discourse coherence. According to an End-to-End (speech-to-speech simultaneous interpreting) evaluation, this model presents impressive performance in reducing latency (to less than 3 seconds at most times). Furthermore, we successfully deploy this model in a variety of Baidu's products which have hundreds of millions of users, and we release it as a service in our AI platform.
End-to-End Speech Translation with Knowledge Distillation
Apr 17, 2019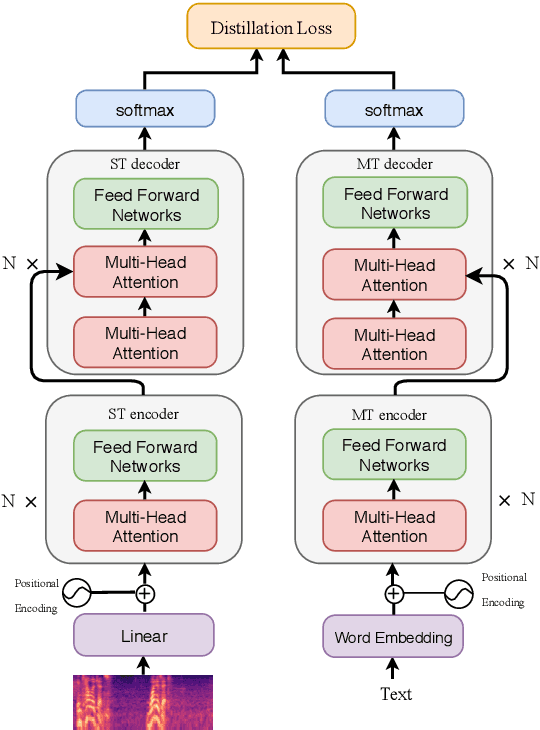
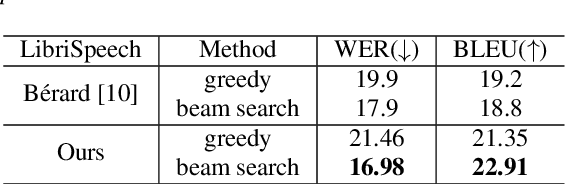
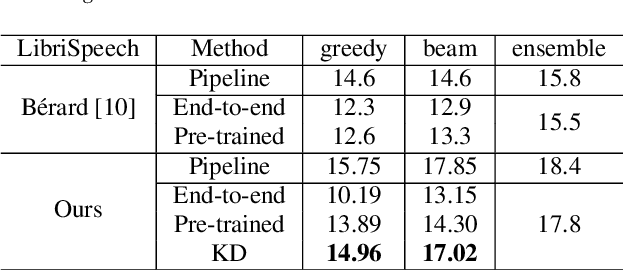
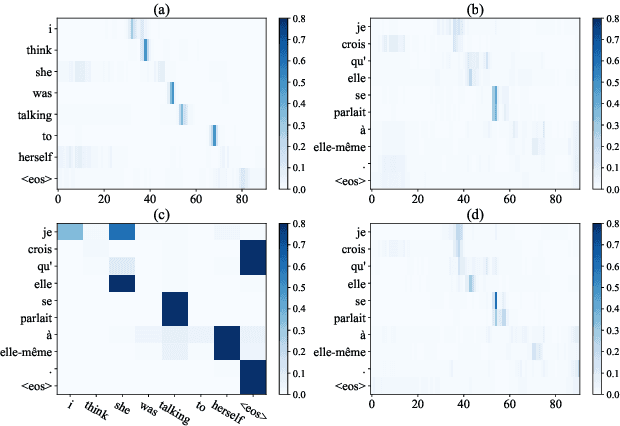
End-to-end speech translation (ST), which directly translates from source language speech into target language text, has attracted intensive attentions in recent years. Compared to conventional pipeline systems, end-to-end ST models have advantages of lower latency, smaller model size and less error propagation. However, the combination of speech recognition and text translation in one model is more difficult than each of these two tasks. In this paper, we propose a knowledge distillation approach to improve ST model by transferring the knowledge from text translation model. Specifically, we first train a text translation model, regarded as a teacher model, and then ST model is trained to learn output probabilities from teacher model through knowledge distillation. Experiments on English- French Augmented LibriSpeech and English-Chinese TED corpus show that end-to-end ST is possible to implement on both similar and dissimilar language pairs. In addition, with the instruction of teacher model, end-to-end ST model can gain significant improvements by over 3.5 BLEU points.
Modeling Coherence for Discourse Neural Machine Translation
Nov 14, 2018
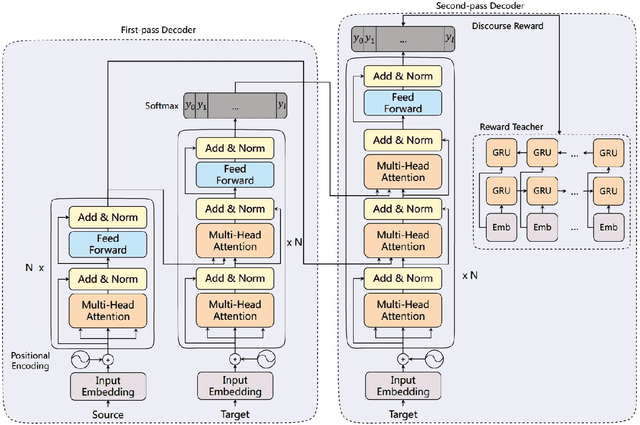
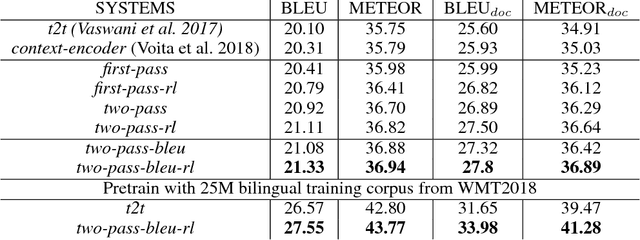
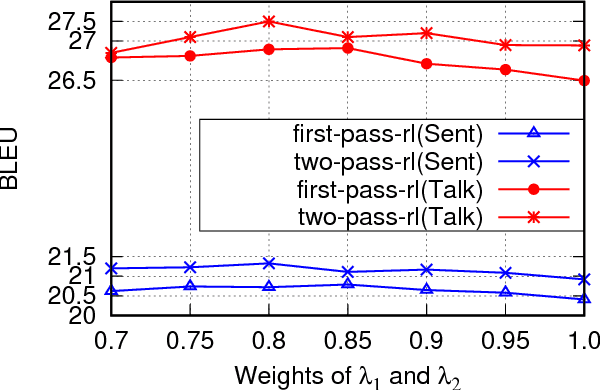
Discourse coherence plays an important role in the translation of one text. However, the previous reported models most focus on improving performance over individual sentence while ignoring cross-sentence links and dependencies, which affects the coherence of the text. In this paper, we propose to use discourse context and reward to refine the translation quality from the discourse perspective. In particular, we generate the translation of individual sentences at first. Next, we deliberate the preliminary produced translations, and train the model to learn the policy that produces discourse coherent text by a reward teacher. Practical results on multiple discourse test datasets indicate that our model significantly improves the translation quality over the state-of-the-art baseline system by +1.23 BLEU score. Moreover, our model generates more discourse coherent text and obtains +2.2 BLEU improvements when evaluated by discourse metrics.
* Accepted by AAAI2019
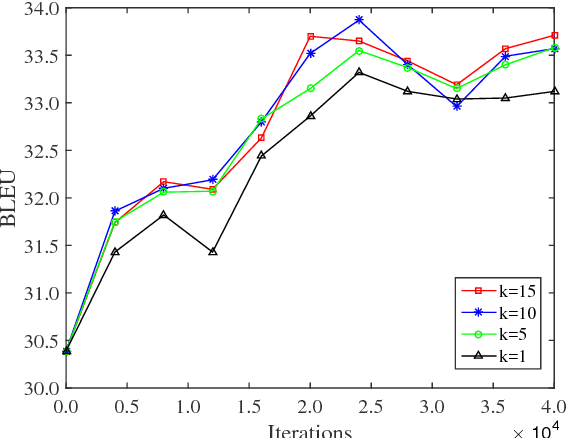
STACL: Simultaneous Translation with Integrated Anticipation and Controllable Latency
Nov 03, 2018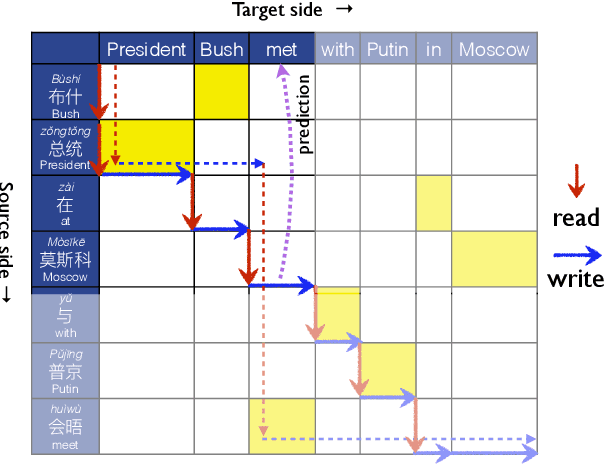
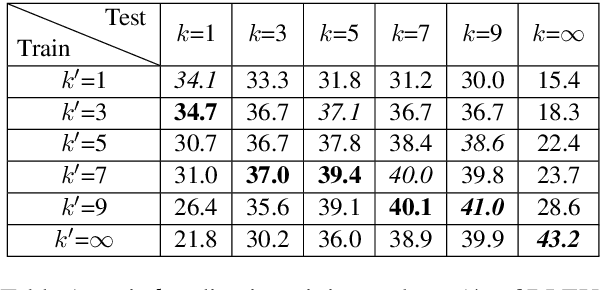

Simultaneous translation, which translates sentences before they are finished, is useful in many scenarios but is notoriously difficult due to word-order differences and simultaneity requirements. We introduce a very simple yet surprisingly effective `wait-k' model trained to generate the target sentence concurrently with the source sentence, but always k words behind, for any given k. This framework seamlessly integrates anticipation and translation in a single model that involves only minor changes to the existing neural translation framework. Experiments on Chinese-to-English simultaneous translation achieve a 5-word latency with 3.4 (single-ref) BLEU points degradation in quality compared to full-sentence non-simultaneous translation. We also formulate a new latency metric that addresses deficiencies in previous ones.
Robust Neural Machine Translation with Joint Textual and Phonetic Embedding
Oct 15, 2018
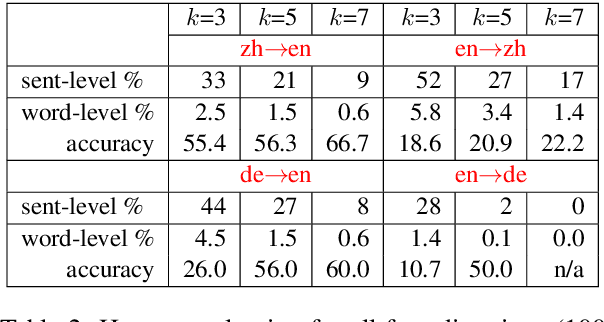
Neural machine translation (NMT) is notoriously sensitive to noises, but noises are almost inevitable in practice. One special kind of noise is the homophone noise, where words are replaced by other words with the same (or similar) pronunciations. Homophone noise arises frequently from many real-world scenarios upstream to translation, such as automatic speech recognition (ASR) or phonetic-based input systems. We propose to improve the robustness of NMT to homophone noise by 1) jointly embedding both textual and phonetic information of source sentences, and 2) augmenting the training dataset with homophone noise. Interestingly, we found that in order to achieve the best translation quality, most (though not all) weights should be put on the phonetic rather than textual information, where the latter is only used as auxiliary information. Experiments show that our method not only significantly improves the robustness of NMT to homophone noise, which is expected but also surprisingly improves the translation quality on clean test sets.
Multi-channel Encoder for Neural Machine Translation
Dec 06, 2017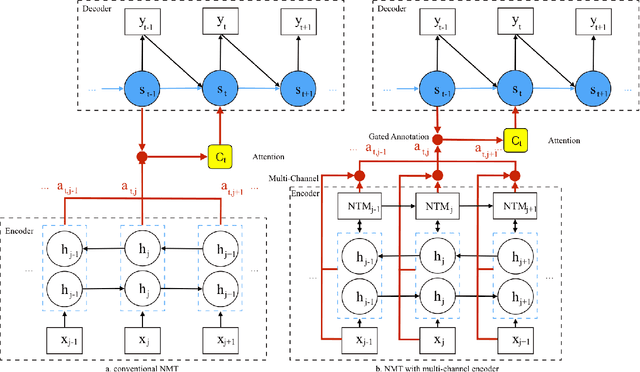
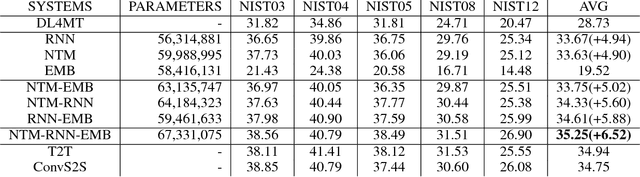
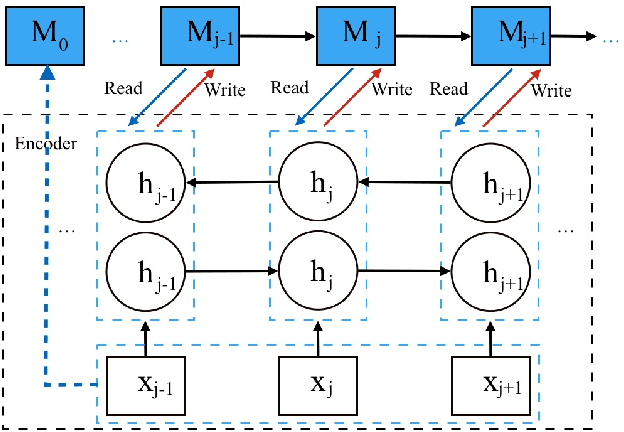
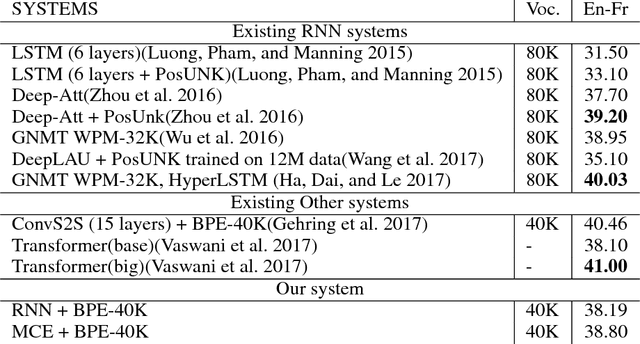
Attention-based Encoder-Decoder has the effective architecture for neural machine translation (NMT), which typically relies on recurrent neural networks (RNN) to build the blocks that will be lately called by attentive reader during the decoding process. This design of encoder yields relatively uniform composition on source sentence, despite the gating mechanism employed in encoding RNN. On the other hand, we often hope the decoder to take pieces of source sentence at varying levels suiting its own linguistic structure: for example, we may want to take the entity name in its raw form while taking an idiom as a perfectly composed unit. Motivated by this demand, we propose Multi-channel Encoder (MCE), which enhances encoding components with different levels of composition. More specifically, in addition to the hidden state of encoding RNN, MCE takes 1) the original word embedding for raw encoding with no composition, and 2) a particular design of external memory in Neural Turing Machine (NTM) for more complex composition, while all three encoding strategies are properly blended during decoding. Empirical study on Chinese-English translation shows that our model can improve by 6.52 BLEU points upon a strong open source NMT system: DL4MT1. On the WMT14 English- French task, our single shallow system achieves BLEU=38.8, comparable with the state-of-the-art deep models.
Semi-Supervised Learning for Neural Machine Translation
Dec 10, 2016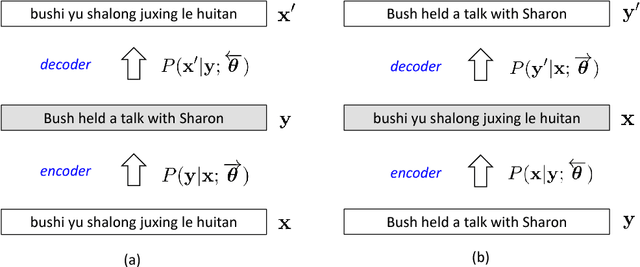
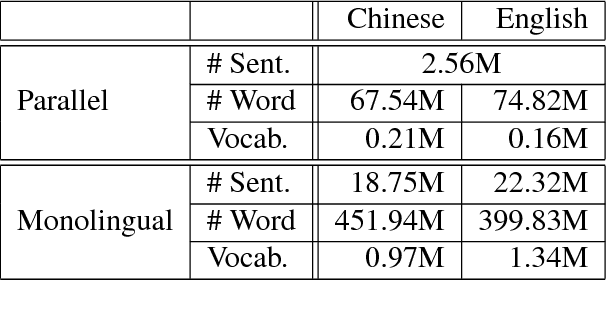
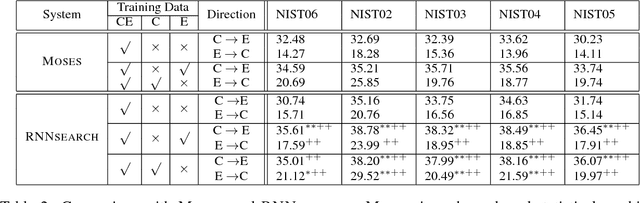
While end-to-end neural machine translation (NMT) has made remarkable progress recently, NMT systems only rely on parallel corpora for parameter estimation. Since parallel corpora are usually limited in quantity, quality, and coverage, especially for low-resource languages, it is appealing to exploit monolingual corpora to improve NMT. We propose a semi-supervised approach for training NMT models on the concatenation of labeled (parallel corpora) and unlabeled (monolingual corpora) data. The central idea is to reconstruct the monolingual corpora using an autoencoder, in which the source-to-target and target-to-source translation models serve as the encoder and decoder, respectively. Our approach can not only exploit the monolingual corpora of the target language, but also of the source language. Experiments on the Chinese-English dataset show that our approach achieves significant improvements over state-of-the-art SMT and NMT systems.
Minimum Risk Training for Neural Machine Translation
Jun 15, 2016
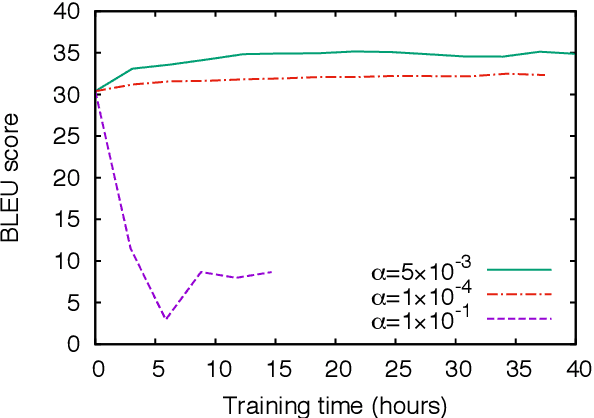
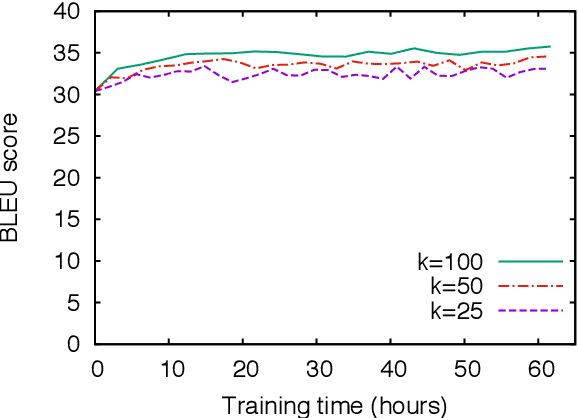
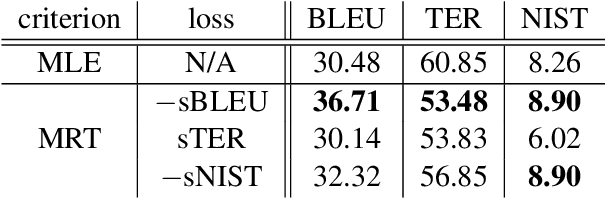
We propose minimum risk training for end-to-end neural machine translation. Unlike conventional maximum likelihood estimation, minimum risk training is capable of optimizing model parameters directly with respect to arbitrary evaluation metrics, which are not necessarily differentiable. Experiments show that our approach achieves significant improvements over maximum likelihood estimation on a state-of-the-art neural machine translation system across various languages pairs. Transparent to architectures, our approach can be applied to more neural networks and potentially benefit more NLP tasks.
Agreement-based Joint Training for Bidirectional Attention-based Neural Machine Translation
Apr 22, 2016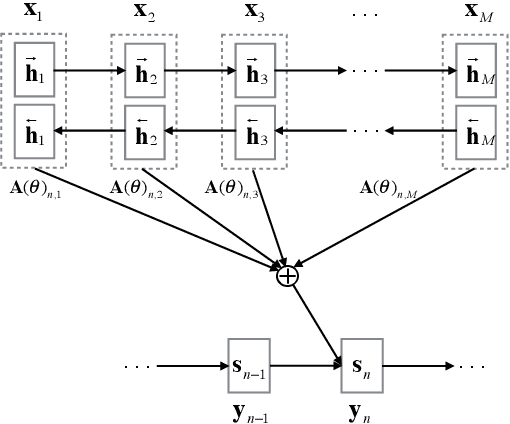

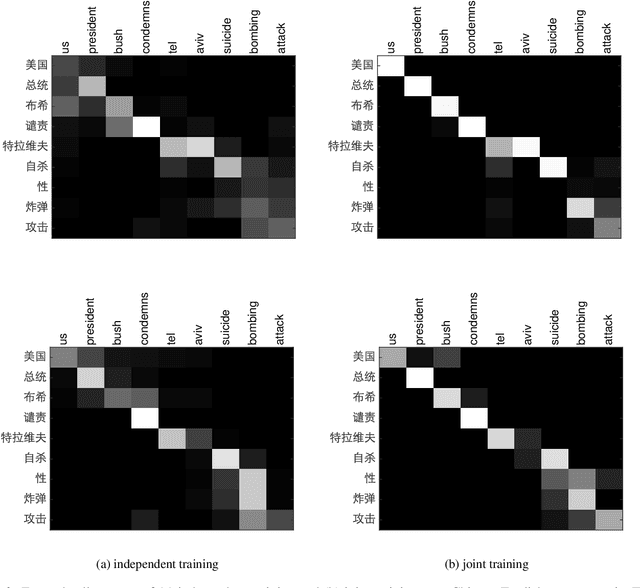

The attentional mechanism has proven to be effective in improving end-to-end neural machine translation. However, due to the intricate structural divergence between natural languages, unidirectional attention-based models might only capture partial aspects of attentional regularities. We propose agreement-based joint training for bidirectional attention-based end-to-end neural machine translation. Instead of training source-to-target and target-to-source translation models independently,our approach encourages the two complementary models to agree on word alignment matrices on the same training data. Experiments on Chinese-English and English-French translation tasks show that agreement-based joint training significantly improves both alignment and translation quality over independent training.