 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Stand-alone Neural Spelling Correction
Nov 12, 2020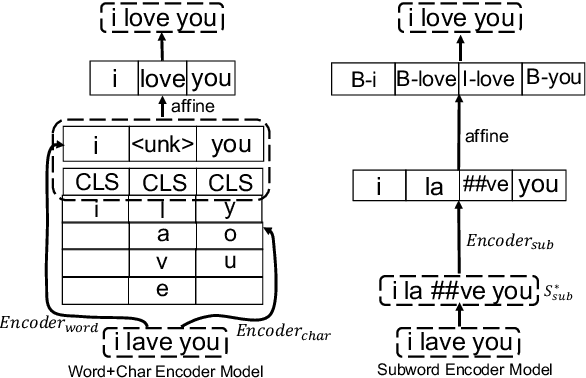
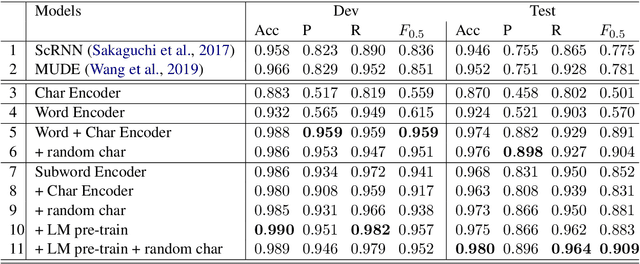
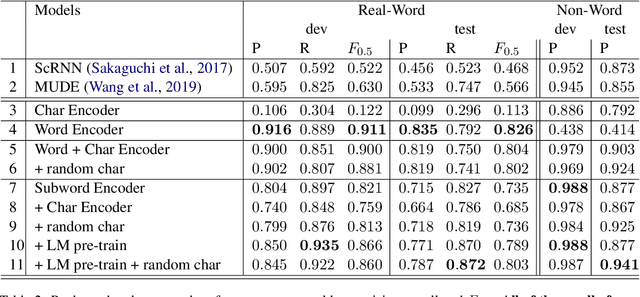

Existing natural language processing systems are vulnerable to noisy inputs resulting from misspellings. On the contrary, humans can easily infer the corresponding correct words from their misspellings and surrounding context. Inspired by this, we address the stand-alone spelling correction problem, which only corrects the spelling of each token without additional token insertion or deletion, by utilizing both spelling information and global context representations. We present a simple yet powerful solution that jointly detects and corrects misspellings as a sequence labeling task by fine-turning a pre-trained language model. Our solution outperforms the previous state-of-the-art result by 12.8% absolute F0.5 score.
Simultaneous Translation Policies: From Fixed to Adaptive
May 02, 2020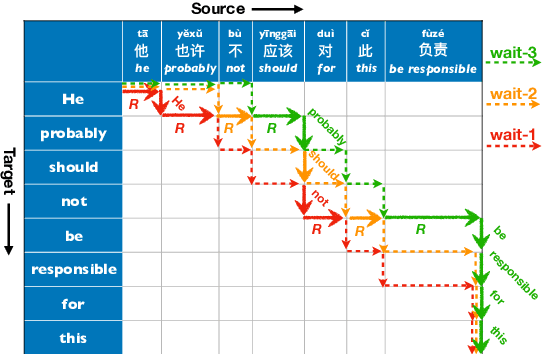

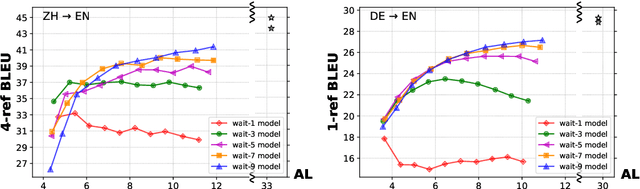

Adaptive policies are better than fixed policies for simultaneous translation, since they can flexibly balance the tradeoff between translation quality and latency based on the current context information. But previous methods on obtaining adaptive policies either rely on complicated training process, or underperform simple fixed policies. We design an algorithm to achieve adaptive policies via a simple heuristic composition of a set of fixed policies. Experiments on Chinese -> English and German -> English show that our adaptive policies can outperform fixed ones by up to 4 BLEU points for the same latency, and more surprisingly, it even surpasses the BLEU score of full-sentence translation in the greedy mode (and very close to beam mode), but with much lower latency.
Incremental Text-to-Speech Synthesis with Prefix-to-Prefix Framework
Nov 07, 2019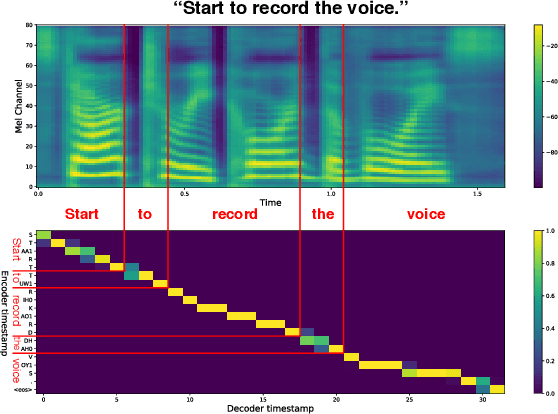
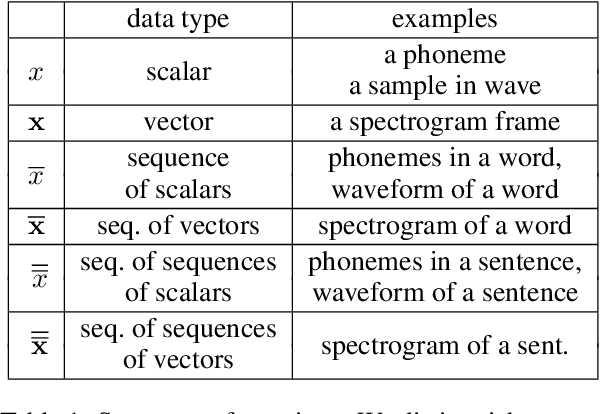
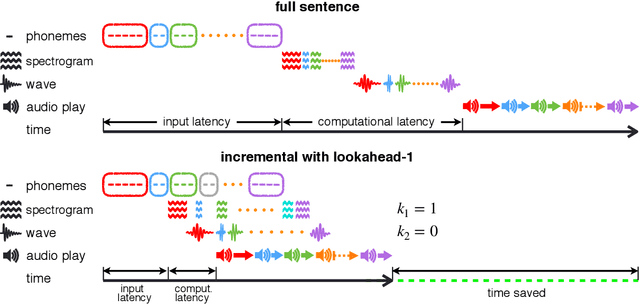
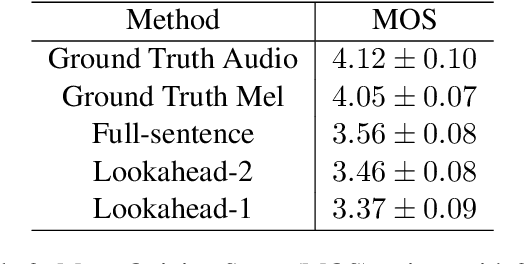
Text-to-speech synthesis (TTS) has witnessed rapid progress in recent years, where neural methods became capable of producing audio with near human-level naturalness. However, these efforts still suffer from two types of latencies: (a) the computational latency (synthesize time), which grows linearly with the sentence length even with parallel approaches, and (b) the input latency in scenarios where the input text is incrementally generated (such as in simultaneous translation, dialog generation, and assistive technologies). To reduce these latencies, we devise the first neural incremental TTS approach based on the recently proposed prefix-to-prefix framework. We synthesize speech in an online fashion, playing a segment of audio while generating the next, resulting in an O(1) rather than O(n) latency. Experiments on English TTS show that our approach achieves similar speech naturalness compared to full sentence methods, but only using a fraction of time and a constant (1 - 2 words) latency.
Machine Translation in Pronunciation Space
Nov 03, 2019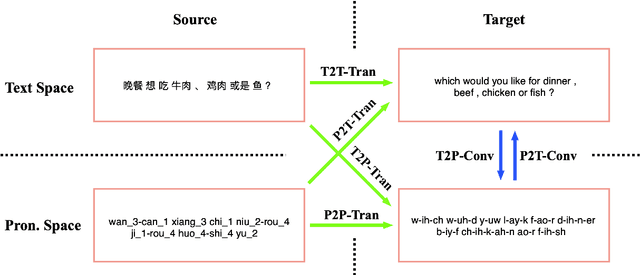



The research in machine translation community focus on translation in text space. However, humans are in fact also good at direct translation in pronunciation space. Some existing translation systems, such as simultaneous machine translation, are inherently more natural and thus potentially more robust by directly translating in pronunciation space. In this paper, we conduct large scale experiments on a self-built dataset with about $20$M En-Zh pairs of text sentences and corresponding pronunciation sentences. We proposed three new categories of translations: $1)$ translating a pronunciation sentence in source language into a pronunciation sentence in target language (P2P-Tran), $2)$ translating a text sentence in source language into a pronunciation sentence in target language (T2P-Tran), and $3)$ translating a pronunciation sentence in source language into a text sentence in target language (P2T-Tran), and compare them with traditional text translation (T2T-Tran). Our experiments clearly show that all $4$ categories of translations have comparable performances, with small and sometimes ignorable differences.
Robust Machine Translation with Domain Sensitive Pseudo-Sources: Baidu-OSU WMT19 MT Robustness Shared Task System Report
Jun 22, 2019
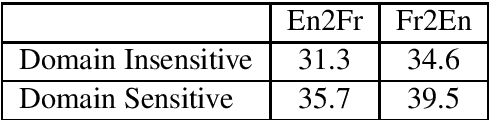
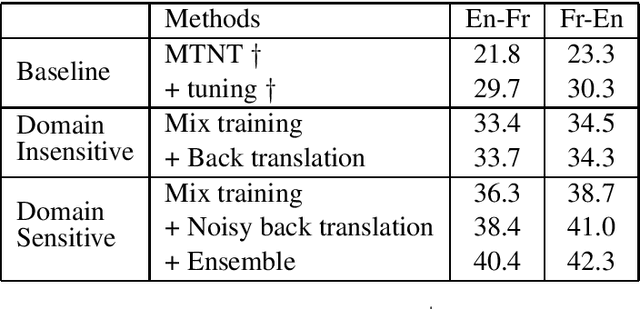
This paper describes the machine translation system developed jointly by Baidu Research and Oregon State University for WMT 2019 Machine Translation Robustness Shared Task. Translation of social media is a very challenging problem, since its style is very different from normal parallel corpora (e.g. News) and also include various types of noises. To make it worse, the amount of social media parallel corpora is extremely limited. In this paper, we use a domain sensitive training method which leverages a large amount of parallel data from popular domains together with a little amount of parallel data from social media. Furthermore, we generate a parallel dataset with pseudo noisy source sentences which are back-translated from monolingual data using a model trained by a similar domain sensitive way. We achieve more than 10 BLEU improvement in both En-Fr and Fr-En translation compared with the baseline methods.
STACL: Simultaneous Translation with Integrated Anticipation and Controllable Latency
Nov 03, 2018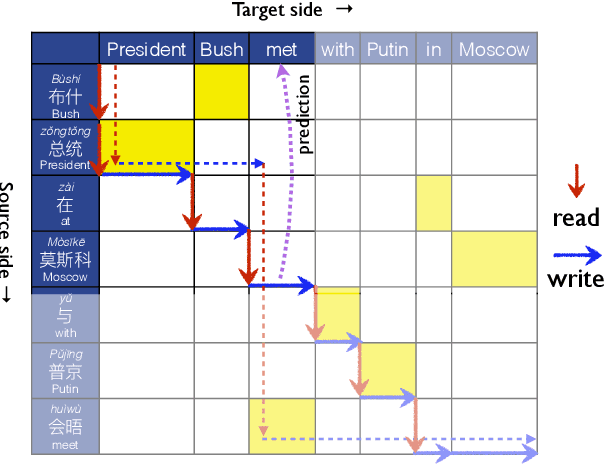
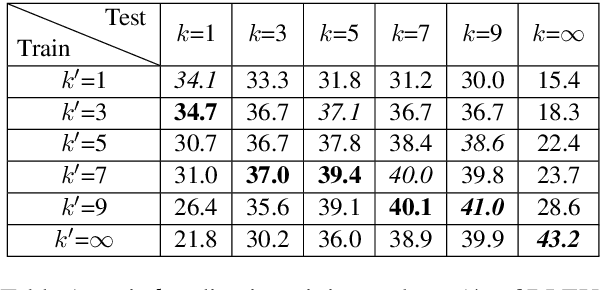

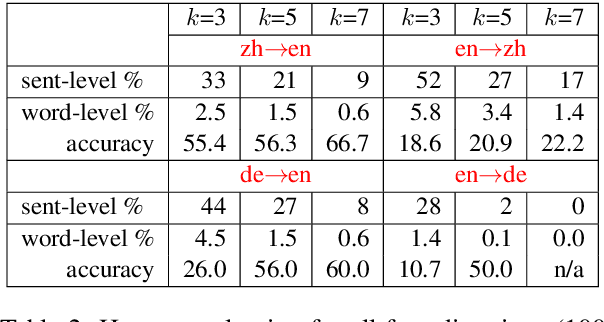
Simultaneous translation, which translates sentences before they are finished, is useful in many scenarios but is notoriously difficult due to word-order differences and simultaneity requirements. We introduce a very simple yet surprisingly effective `wait-k' model trained to generate the target sentence concurrently with the source sentence, but always k words behind, for any given k. This framework seamlessly integrates anticipation and translation in a single model that involves only minor changes to the existing neural translation framework. Experiments on Chinese-to-English simultaneous translation achieve a 5-word latency with 3.4 (single-ref) BLEU points degradation in quality compared to full-sentence non-simultaneous translation. We also formulate a new latency metric that addresses deficiencies in previous ones.
Robust Neural Machine Translation with Joint Textual and Phonetic Embedding
Oct 15, 2018
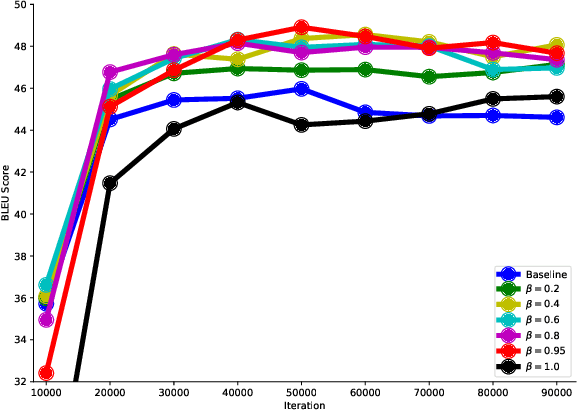
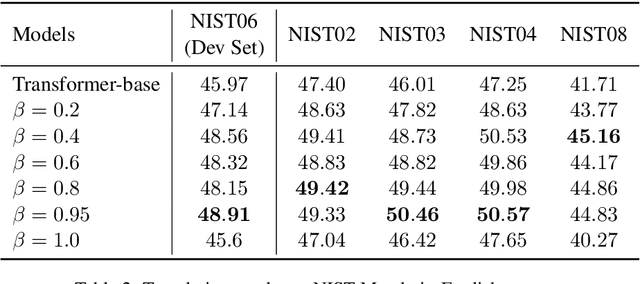
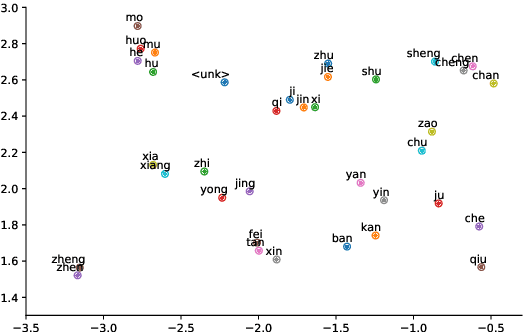
Neural machine translation (NMT) is notoriously sensitive to noises, but noises are almost inevitable in practice. One special kind of noise is the homophone noise, where words are replaced by other words with the same (or similar) pronunciations. Homophone noise arises frequently from many real-world scenarios upstream to translation, such as automatic speech recognition (ASR) or phonetic-based input systems. We propose to improve the robustness of NMT to homophone noise by 1) jointly embedding both textual and phonetic information of source sentences, and 2) augmenting the training dataset with homophone noise. Interestingly, we found that in order to achieve the best translation quality, most (though not all) weights should be put on the phonetic rather than textual information, where the latter is only used as auxiliary information. Experiments show that our method not only significantly improves the robustness of NMT to homophone noise, which is expected but also surprisingly improves the translation quality on clean test sets.
Resource-Efficient Neural Architect
Jun 12, 2018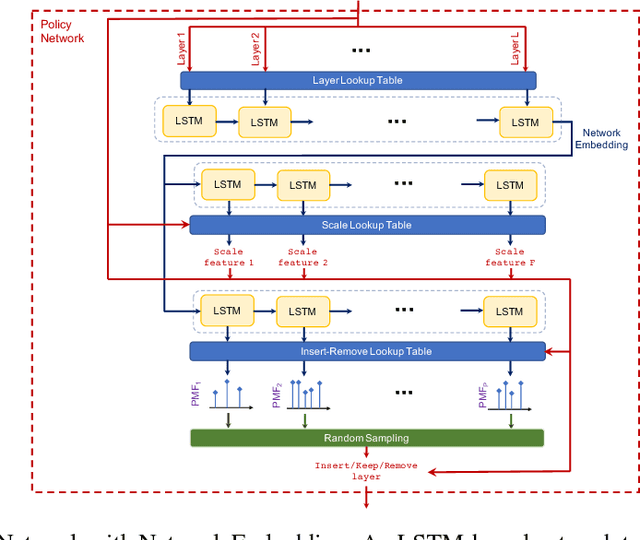
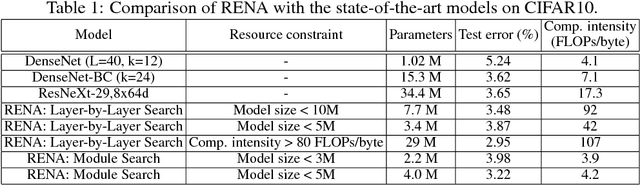
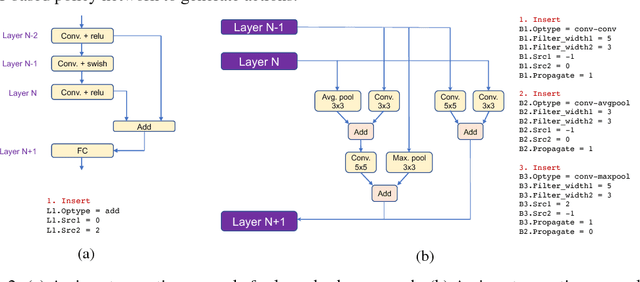
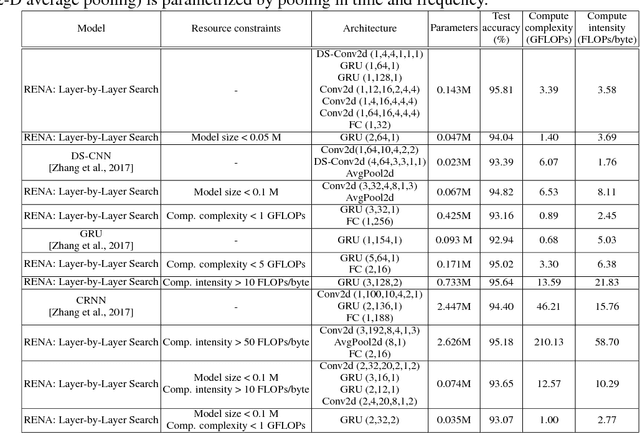
Neural Architecture Search (NAS) is a laborious process. Prior work on automated NAS targets mainly on improving accuracy, but lacks consideration of computational resource use. We propose the Resource-Efficient Neural Architect (RENA), an efficient resource-constrained NAS using reinforcement learning with network embedding. RENA uses a policy network to process the network embeddings to generate new configurations. We demonstrate RENA on image recognition and keyword spotting (KWS) problems. RENA can find novel architectures that achieve high performance even with tight resource constraints. For CIFAR10, it achieves 2.95% test error when compute intensity is greater than 100 FLOPs/byte, and 3.87% test error when model size is less than 3M parameters. For Google Speech Commands Dataset, RENA achieves the state-of-the-art accuracy without resource constraints, and it outperforms the optimized architectures with tight resource constraints.
Gram-CTC: Automatic Unit Selection and Target Decomposition for Sequence Labelling
Aug 12, 2017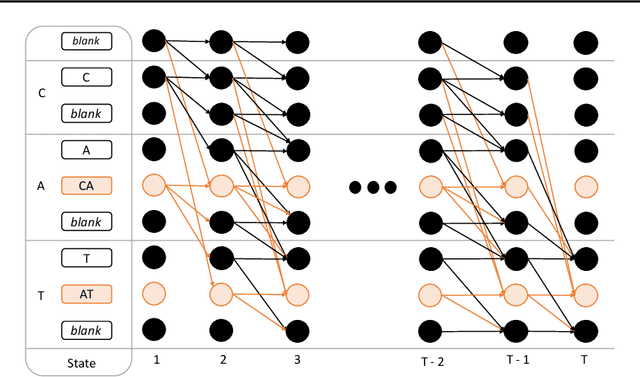
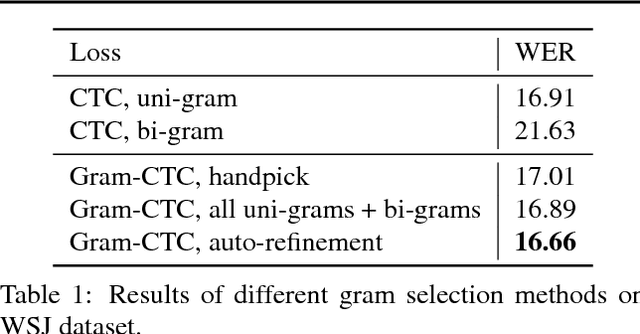
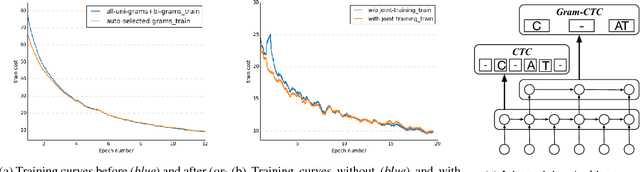
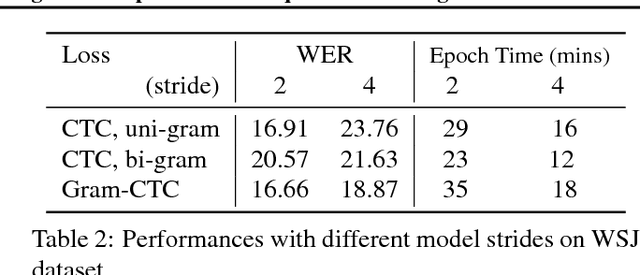
Most existing sequence labelling models rely on a fixed decomposition of a target sequence into a sequence of basic units. These methods suffer from two major drawbacks: 1) the set of basic units is fixed, such as the set of words, characters or phonemes in speech recognition, and 2) the decomposition of target sequences is fixed. These drawbacks usually result in sub-optimal performance of modeling sequences. In this pa- per, we extend the popular CTC loss criterion to alleviate these limitations, and propose a new loss function called Gram-CTC. While preserving the advantages of CTC, Gram-CTC automatically learns the best set of basic units (grams), as well as the most suitable decomposition of tar- get sequences. Unlike CTC, Gram-CTC allows the model to output variable number of characters at each time step, which enables the model to capture longer term dependency and improves the computational efficiency. We demonstrate that the proposed Gram-CTC improves CTC in terms of both performance and efficiency on the large vocabulary speech recognition task at multiple scales of data, and that with Gram-CTC we can outperform the state-of-the-art on a standard speech benchmark.
Exploring Neural Transducers for End-to-End Speech Recognition
Jul 24, 2017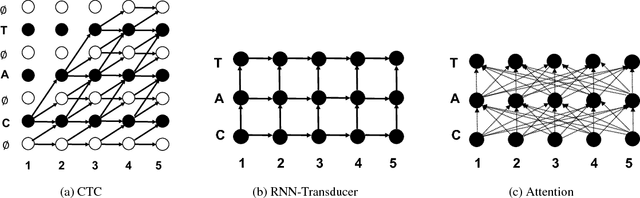
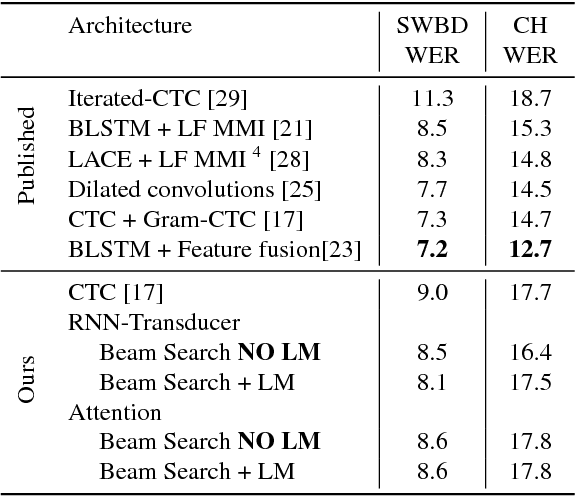
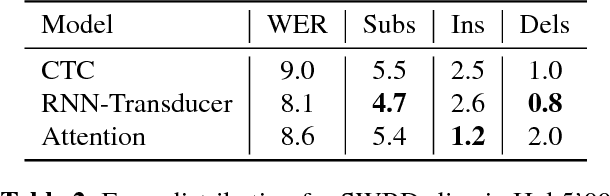
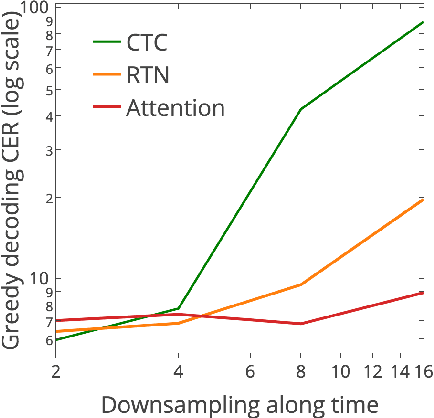
In this work, we perform an empirical comparison among the CTC, RNN-Transducer, and attention-based Seq2Seq models for end-to-end speech recognition. We show that, without any language model, Seq2Seq and RNN-Transducer models both outperform the best reported CTC models with a language model, on the popular Hub5'00 benchmark. On our internal diverse dataset, these trends continue - RNNTransducer models rescored with a language model after beam search outperform our best CTC models. These results simplify the speech recognition pipeline so that decoding can now be expressed purely as neural network operations. We also study how the choice of encoder architecture affects the performance of the three models - when all encoder layers are forward only, and when encoders downsample the input representation aggressively.