 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-Judge Framework for Evaluating Tone-Induced Hallucination in Vision-Language Models
Apr 22, 2026Vision-Language Models (VLMs) are increasingly deployed in settings where reliable visual grounding carries operational consequences, yet their behavior under progressively coercive prompt phrasing remains undercharacterized. Existing hallucination benchmarks predominantly rely on neutral prompts and binary detection, leaving open how both the incidence and the intensity of fabrication respond to graded linguistic pressure across structurally distinct task types. We present Ghost-100, a procedurally constructed benchmark of 800 synthetically generated images spanning eight categories across three task families: text-illegibility, time-reading, and object-absence, each designed under a negative-ground-truth principle that guarantees the queried target is absent, illegible, or indeterminate by construction. Every image is paired with five prompts drawn from a structured 5-Level Prompt Intensity Framework, holding the image and task identity fixed while varying only directive force, so that tone is isolated as the sole independent variable. We adopt a dual-track evaluation protocol: a rule-based H-Rate measuring the proportion of responses in which a model crosses from grounded refusal into unsupported positive commitment, and a GPT-4o-mini-judged H-Score on a 1-5 scale characterizing the confidence and specificity of fabrication once it occurs. We additionally release a three-stage automated validation workflow, which retrospectively confirms 717 of 800 images as strictly compliant. Evaluating nine open-weight VLMs, we find that H-Rate and H-Score dissociate substantially across model families, reading-style and presence-detection subsets respond to prompt pressure in qualitatively different ways, and several models exhibit non-monotonic sensitivity peaking at intermediate tone levels: patterns that aggregate metrics obscure.
Toward Accountable AI-Generated Content on Social Platforms: Steganographic Attribution and Multimodal Harm Detection
Apr 12, 2026The rapid growth of generative AI has introduced new challenges in content moderation and digital forensics. In particular, benign AI-generated images can be paired with harmful or misleading text, creating difficult-to-detect misuse. This contextual misuse undermines the traditional moderation framework and complicates attribution, as synthetic images typically lack persistent metadata or device signatures. We introduce a steganography enabled attribution framework that embeds cryptographically signed identifiers into images at creation time and uses multimodal harmful content detection as a trigger for attribution verification. Our system evaluates five watermarking methods across spatial, frequency, and wavelet domains. It also integrates a CLIP-based fusion model for multimodal harmful-content detection. Experiments demonstrate that spread-spectrum watermarking, especially in the wavelet domain, provides strong robustness under blur distortions, and our multimodal fusion detector achieves an AUC-ROC of 0.99, enabling reliable cross-modal attribution verification. These components form an end-to-end forensic pipeline that enables reliable tracing of harmful deployments of AI-generated imagery, supporting accountability in modern synthetic media environments. Our code is available at GitHub: https://github.com/bli1/steganography
Fuzzy Semantic Segmentation of Breast Ultrasound Image with Breast Anatomy Constraints
Oct 23, 2019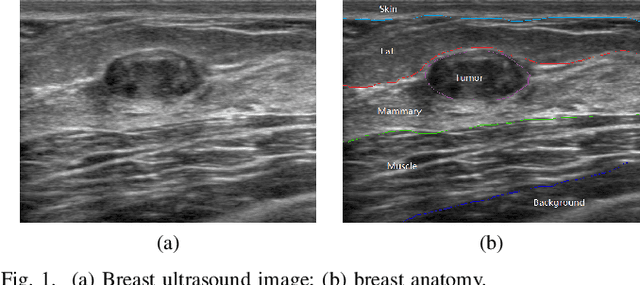


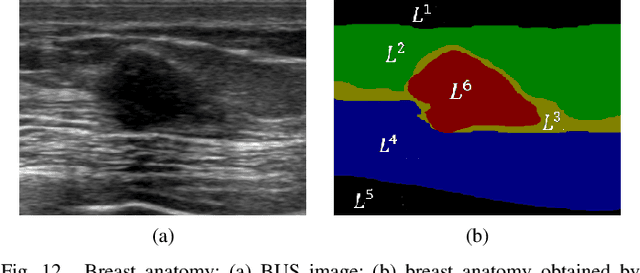
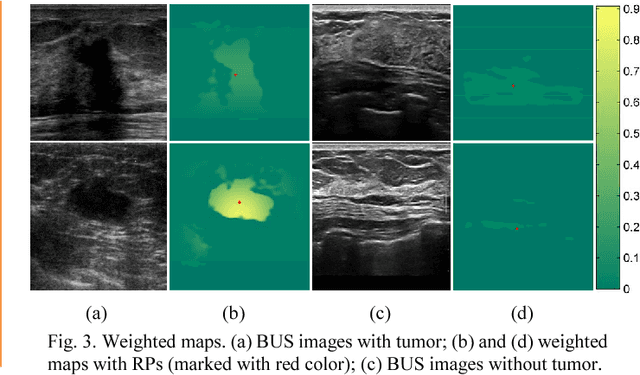
Breast cancer is one of the most serious disease affecting women's health. Due to low cost, portable, no radiation, and high efficiency, breast ultrasound (BUS) imaging is the most popular approach for diagnosing early breast cancer. However, ultrasound images are low resolution and poor quality. Thus, developing accurate detection system is a challenging task. In this paper, we propose a fully automatic segmentation algorithm consisting of two parts: fuzzy fully convolutional network and accurately fine-tuning post-processing based on breast anatomy constraints. In the first part, the image is preprocessed by contrast enhancement, and wavelet features are employed for image augmentation. A fuzzy membership function transforms the augmented BUS images into fuzzy domain. The features from convolutional layers are processed using fuzzy logic as well. The conditional random fields (CRFs) post-process the segmentation result. The location relation among the breast anatomy layers is utilized to improve the performance. The proposed method is applied to the dataset with 325 BUS images, and achieves state-of-art performance compared with that of existing methods with true positive rate 90.33%, false positive rate 9.00%, and intersection over union (IoU) 81.29% on tumor category, and overall intersection over union (mIoU) 80.47% over five categories: fat layer, mammary layer, muscle layer, background, and tumor.
A Hybrid Framework for Tumor Saliency Estimation
Jun 27, 2018
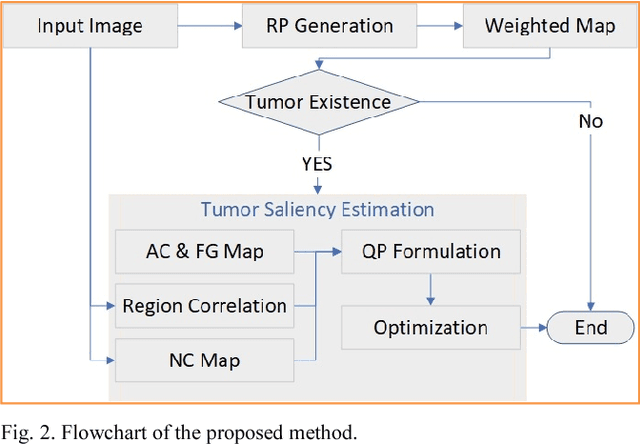
Automatic tumor segmentation of breast ultrasound (BUS) image is quite challenging due to the complicated anatomic structure of breast and poor image quality. Most tumor segmentation approaches achieve good performance on BUS images collected in controlled settings; however, the performance degrades greatly with BUS images from different sources. Tumor saliency estimation (TSE) has attracted increasing attention to solving the problem by modeling radiologists' attention mechanism. In this paper, we propose a novel hybrid framework for TSE, which integrates both high-level domain-knowledge and robust low-level saliency assumptions and can overcome drawbacks caused by direct mapping in traditional TSE approaches. The new framework integrated the Neutro-Connectedness (NC) map, the adaptive-center, the correlation and the layer structure-based weighted map. The experimental results demonstrate that the proposed approach outperforms state-of-the-art TSE methods.
Computer-Aided Knee Joint Magnetic Resonance Image Segmentation - A Survey
Feb 13, 2018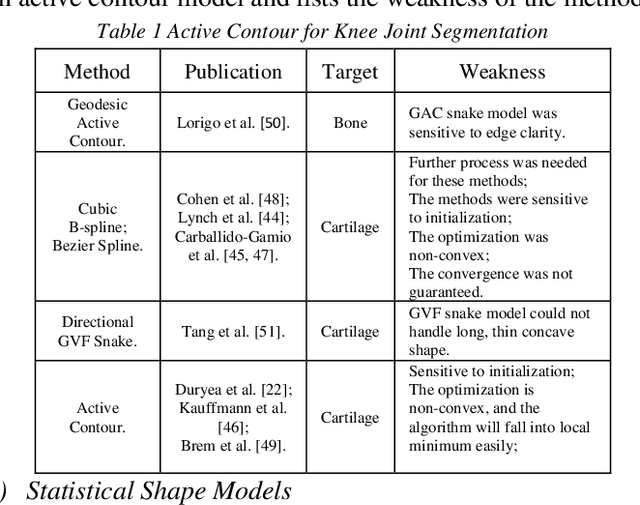

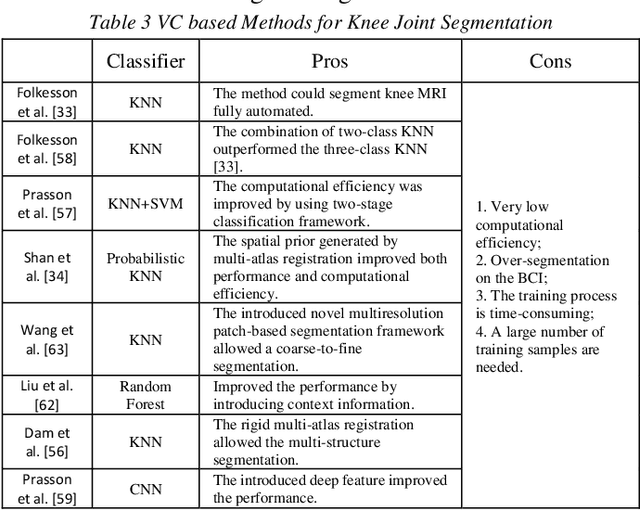
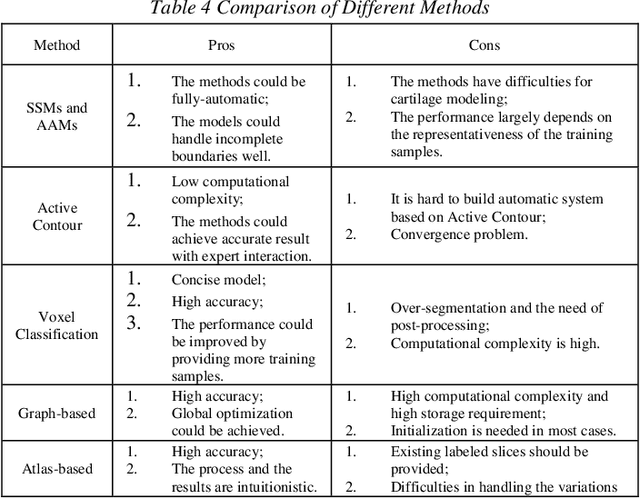
Osteoarthritis (OA) is one of the major health issues among the elderly population. MRI is the most popular technology to observe and evaluate the progress of OA course. However, the extreme labor cost of MRI analysis makes the process inefficient and expensive. Also, due to human error and subjective nature, the inter- and intra-observer variability is rather high. Computer-aided knee MRI segmentation is currently an active research field because it can alleviate doctors and radiologists from the time consuming and tedious job, and improve the diagnosis performance which has immense potential for both clinic and scientific research. In the past decades, researchers have investigated automatic/semi-automatic knee MRI segmentation methods extensively. However, to the best of our knowledge, there is no comprehensive survey paper in this field yet. In this survey paper, we classify the existing methods by their principles and discuss the current research status and point out the future research trend in-depth.
A Benchmark for Breast Ultrasound Image Segmentation (BUSIS)
Jan 09, 2018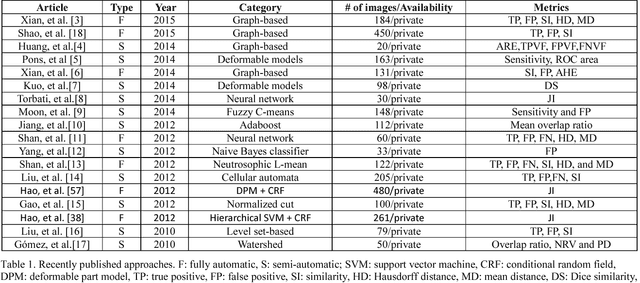


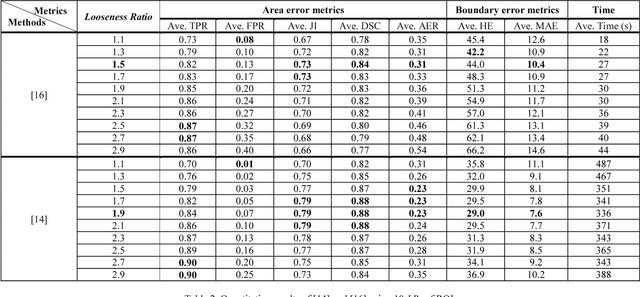
Breast ultrasound (BUS) image segmentation is challenging and critical for BUS Computer-Aided Diagnosis (CAD) systems. Many BUS segmentation approaches have been proposed in the last two decades, but the performances of most approaches have been assessed using relatively small private datasets with differ-ent quantitative metrics, which result in discrepancy in performance comparison. Therefore, there is a pressing need for building a benchmark to compare existing methods using a public dataset objectively, and to determine the performance of the best breast tumor segmentation algorithm available today and to investigate what segmentation strategies are valuable in clinical practice and theoretical study. In this work, we will publish a B-mode BUS image segmentation benchmark (BUSIS) with 562 images and compare the performance of five state-of-the-art BUS segmentation methods quantitatively.