 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Vectorized Lexical Constraints for Neural Machine Translation
Mar 23, 2022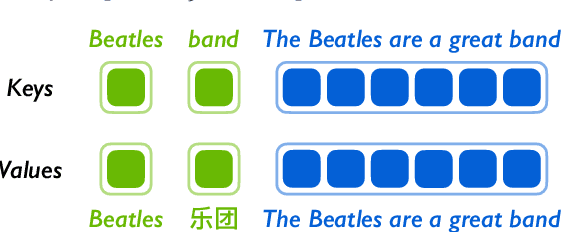
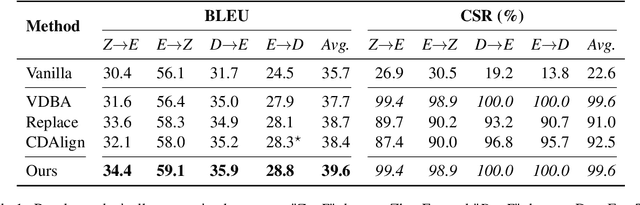
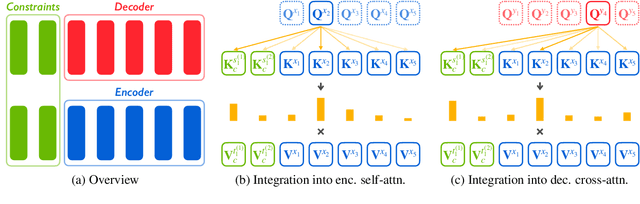

Lexically constrained neural machine translation (NMT), which controls the generation of NMT models with pre-specified constraints, is important in many practical scenarios. Due to the representation gap between discrete constraints and continuous vectors in NMT models, most existing works choose to construct synthetic data or modify the decoding algorithm to impose lexical constraints, treating the NMT model as a black box. In this work, we propose to open this black box by directly integrating the constraints into NMT models. Specifically, we vectorize source and target constraints into continuous keys and values, which can be utilized by the attention modules of NMT models. The proposed integration method is based on the assumption that the correspondence between keys and values in attention modules is naturally suitable for modeling constraint pairs. Experimental results show that our method consistently outperforms several representative baselines on four language pairs, demonstrating the superiority of integrating vectorized lexical constraints.
MSP: Multi-Stage Prompting for Making Pre-trained Language Models Better Translators
Oct 13, 2021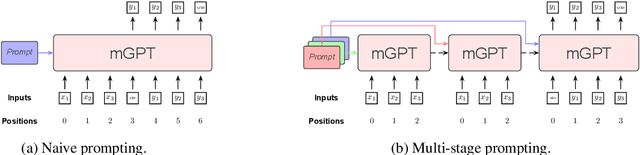
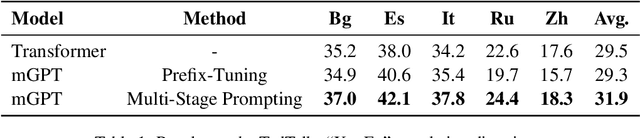
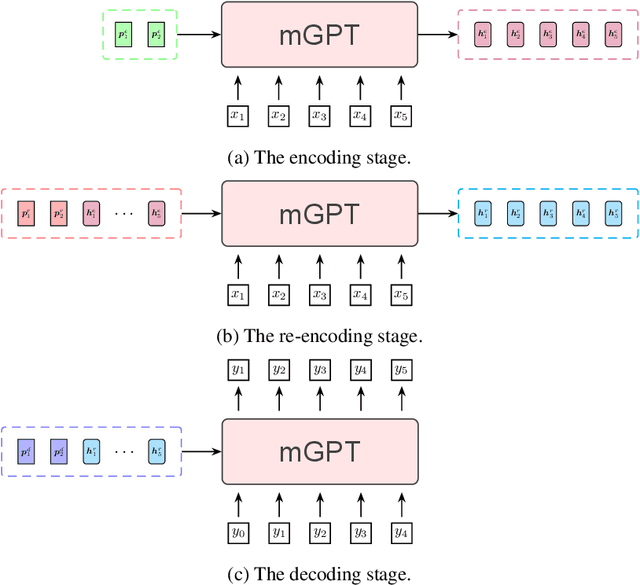

Pre-trained language models have recently been shown to be able to perform translation without finetuning via prompting. Inspired by these findings, we study improving the performance of pre-trained language models on translation tasks, where training neural machine translation models is the current de facto approach. We present Multi-Stage Prompting, a simple and lightweight approach for better adapting pre-trained language models to translation tasks. To make pre-trained language models better translators, we divide the translation process via pre-trained language models into three separate stages: the encoding stage, the re-encoding stage, and the decoding stage. During each stage, we independently apply different continuous prompts for allowing pre-trained language models better adapting to translation tasks. We conduct extensive experiments on low-, medium-, and high-resource translation tasks. Experiments show that our method can significantly improve the translation performance of pre-trained language models.
GraphPiece: Efficiently Generating High-Quality Molecular Graph with Substructures
Jun 29, 2021
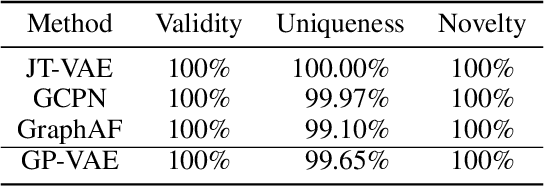

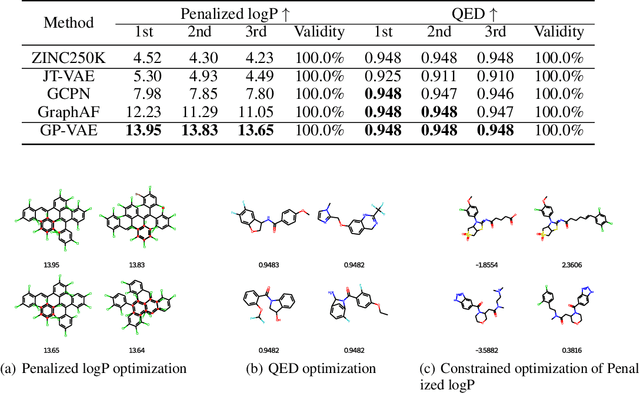
Molecular graph generation is a fundamental but challenging task in various applications such as drug discovery and material science, which requires generating valid molecules with desired properties. Auto-regressive models, which usually construct graphs following sequential actions of adding nodes and edges at the atom-level, have made rapid progress in recent years. However, these atom-level models ignore high-frequency subgraphs that not only capture the regularities of atomic combination in molecules but also are often related to desired chemical properties. In this paper, we propose a method to automatically discover such common substructures, which we call {\em graph pieces}, from given molecular graphs. Based on graph pieces, we leverage a variational autoencoder to generate molecules in two phases: piece-level graph generation followed by bond completion. Experiments show that our graph piece variational autoencoder achieves better performance over state-of-the-art baselines on property optimization and constrained property optimization tasks with higher computational efficiency.
Language Models are Good Translators
Jun 25, 2021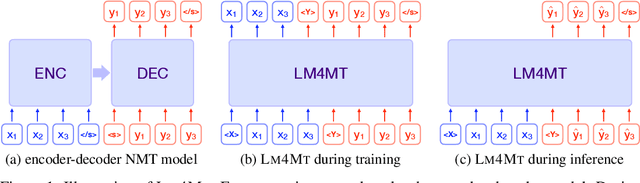
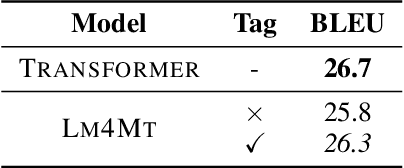
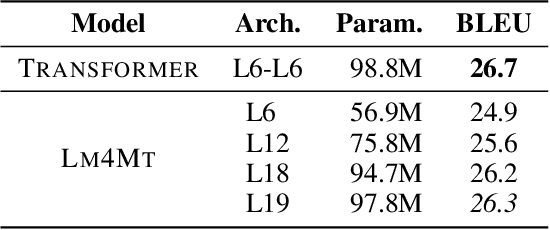
Recent years have witnessed the rapid advance in neural machine translation (NMT), the core of which lies in the encoder-decoder architecture. Inspired by the recent progress of large-scale pre-trained language models on machine translation in a limited scenario, we firstly demonstrate that a single language model (LM4MT) can achieve comparable performance with strong encoder-decoder NMT models on standard machine translation benchmarks, using the same training data and similar amount of model parameters. LM4MT can also easily utilize source-side texts as additional supervision. Though modeling the source- and target-language texts with the same mechanism, LM4MT can provide unified representations for both source and target sentences, which can better transfer knowledge across languages. Extensive experiments on pivot-based and zero-shot translation tasks show that LM4MT can outperform the encoder-decoder NMT model by a large margin.
CPM-2: Large-scale Cost-effective Pre-trained Language Models
Jun 24, 2021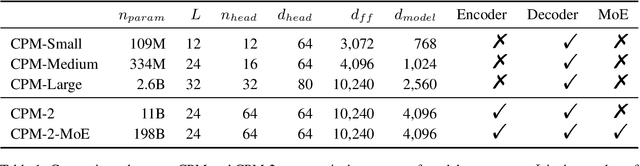

In recent years, the size of pre-trained language models (PLMs) has grown by leaps and bounds. However, efficiency issues of these large-scale PLMs limit their utilization in real-world scenarios. We present a suite of cost-effective techniques for the use of PLMs to deal with the efficiency issues of pre-training, fine-tuning, and inference. (1) We introduce knowledge inheritance to accelerate the pre-training process by exploiting existing PLMs instead of training models from scratch. (2) We explore the best practice of prompt tuning with large-scale PLMs. Compared with conventional fine-tuning, prompt tuning significantly reduces the number of task-specific parameters. (3) We implement a new inference toolkit, namely InfMoE, for using large-scale PLMs with limited computational resources. Based on our cost-effective pipeline, we pre-train two models: an encoder-decoder bilingual model with 11 billion parameters (CPM-2) and its corresponding MoE version with 198 billion parameters. In our experiments, we compare CPM-2 with mT5 on downstream tasks. Experimental results show that CPM-2 has excellent general language intelligence. Moreover, we validate the efficiency of InfMoE when conducting inference of large-scale models having tens of billions of parameters on a single GPU. All source code and model parameters are available at https://github.com/TsinghuaAI/CPM.
On the Language Coverage Bias for Neural Machine Translation
Jun 07, 2021
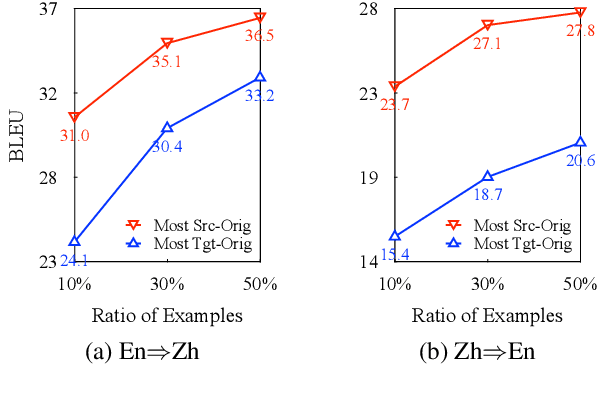

Language coverage bias, which indicates the content-dependent differences between sentence pairs originating from the source and target languages, is important for neural machine translation (NMT) because the target-original training data is not well exploited in current practice. By carefully designing experiments, we provide comprehensive analyses of the language coverage bias in the training data, and find that using only the source-original data achieves comparable performance with using full training data. Based on these observations, we further propose two simple and effective approaches to alleviate the language coverage bias problem through explicitly distinguishing between the source- and target-original training data, which consistently improve the performance over strong baselines on six WMT20 translation tasks. Complementary to the translationese effect, language coverage bias provides another explanation for the performance drop caused by back-translation. We also apply our approach to both back- and forward-translation and find that mitigating the language coverage bias can improve the performance of both the two representative data augmentation methods and their tagged variants.
Dynamic Multi-Branch Layers for On-Device Neural Machine Translation
May 14, 2021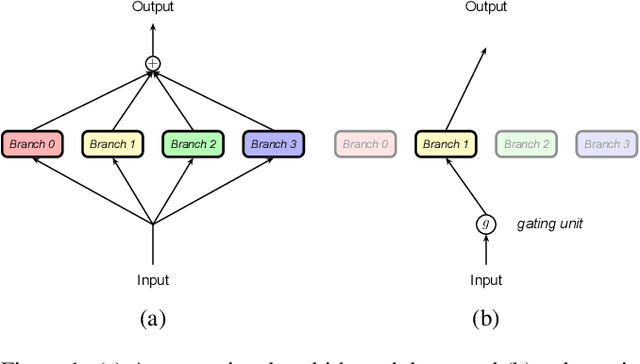
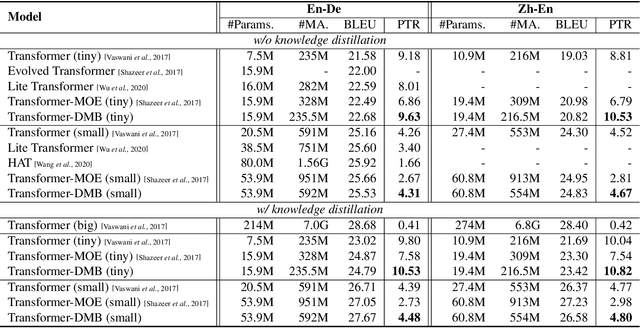
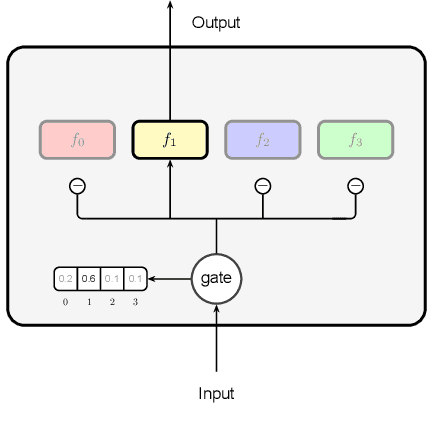
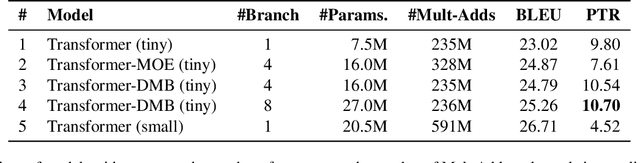
With the rapid development of artificial intelligence (AI), there is a trend in moving AI applications such as neural machine translation (NMT) from cloud to mobile devices such as smartphones. Constrained by limited hardware resources and battery, the performance of on-device NMT systems is far from satisfactory. Inspired by conditional computation, we propose to improve the performance of on-device NMT systems with dynamic multi-branch layers. Specifically, we design a layer-wise dynamic multi-branch network with only one branch activated during training and inference. As not all branches are activated during training, we propose shared-private reparameterization to ensure sufficient training for each branch. At almost the same computational cost, our method achieves improvements of up to 1.7 BLEU points on the WMT14 English-German translation task and 1.8 BLEU points on the WMT20 Chinese-English translation task over the Transformer model, respectively. Compared with a strong baseline that also uses multiple branches, the proposed method is up to 1.6 times faster with the same number of parameters.
Neural Machine Translation: A Review of Methods, Resources, and Tools
Dec 31, 2020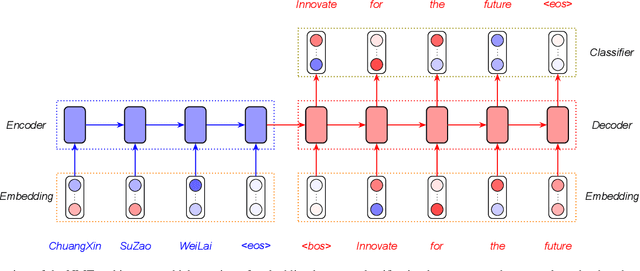

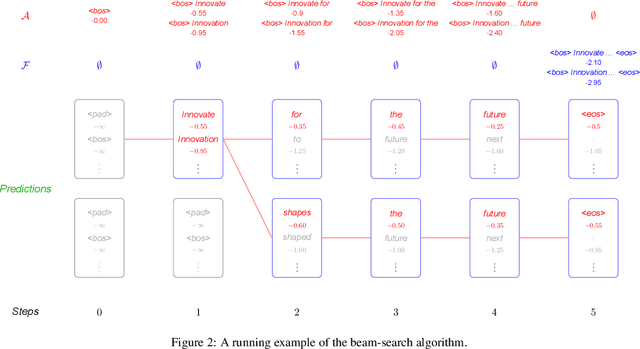
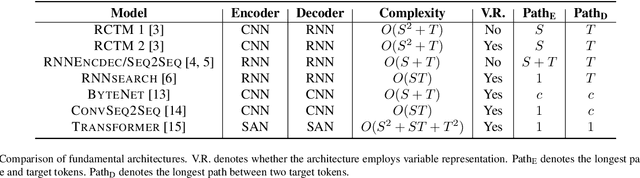
Machine translation (MT) is an important sub-field of natural language processing that aims to translate natural languages using computers. In recent years, end-to-end neural machine translation (NMT) has achieved great success and has become the new mainstream method in practical MT systems. In this article, we first provide a broad review of the methods for NMT and focus on methods relating to architectures, decoding, and data augmentation. Then we summarize the resources and tools that are useful for researchers. Finally, we conclude with a discussion of possible future research directions.
Modeling Voting for System Combination in Machine Translation
Jul 14, 2020
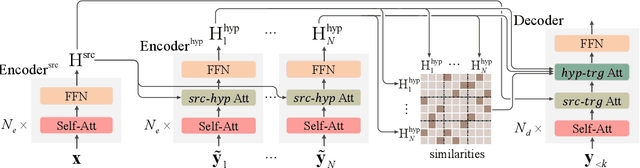
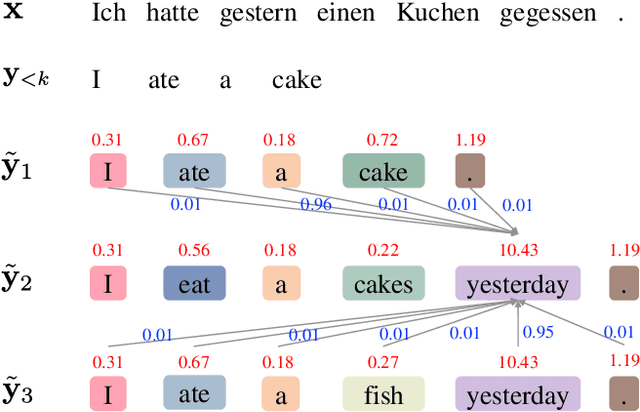
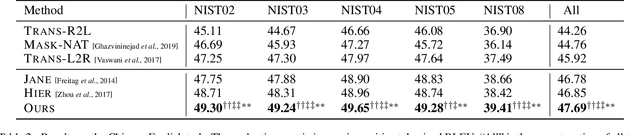
System combination is an important technique for combining the hypotheses of different machine translation systems to improve translation performance. Although early statistical approaches to system combination have been proven effective in analyzing the consensus between hypotheses, they suffer from the error propagation problem due to the use of pipelines. While this problem has been alleviated by end-to-end training of multi-source sequence-to-sequence models recently, these neural models do not explicitly analyze the relations between hypotheses and fail to capture their agreement because the attention to a word in a hypothesis is calculated independently, ignoring the fact that the word might occur in multiple hypotheses. In this work, we propose an approach to modeling voting for system combination in machine translation. The basic idea is to enable words in hypotheses from different systems to vote on words that are representative and should get involved in the generation process. This can be done by quantifying the influence of each voter and its preference for each candidate. Our approach combines the advantages of statistical and neural methods since it can not only analyze the relations between hypotheses but also allow for end-to-end training. Experiments show that our approach is capable of better taking advantage of the consensus between hypotheses and achieves significant improvements over state-of-the-art baselines on Chinese-English and English-German machine translation tasks.
Towards Linear Time Neural Machine Translation with Capsule Networks
Nov 01, 2018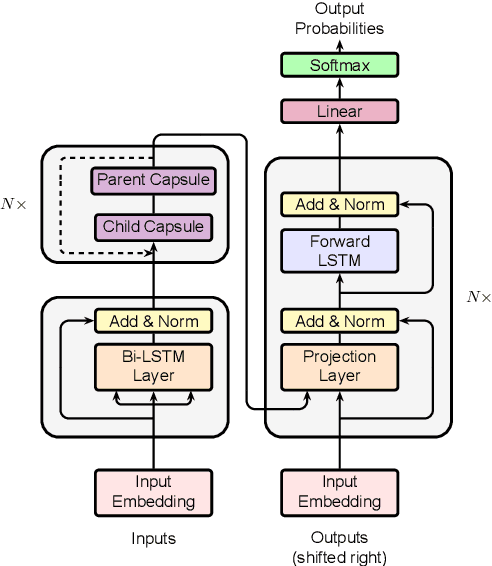
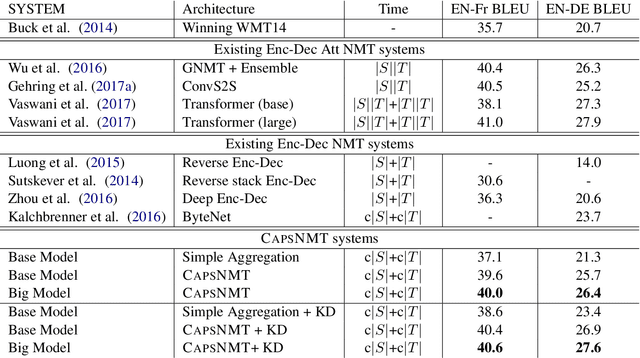
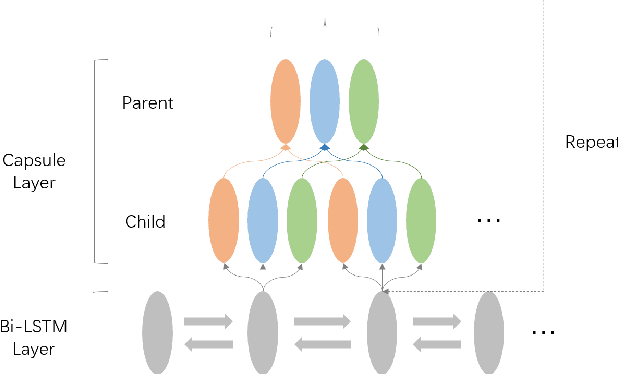

In this study, we first investigate a novel capsule network with dynamic routing for linear time Neural Machine Translation (NMT), referred as \textsc{CapsNMT}. \textsc{CapsNMT} uses an aggregation mechanism to map the source sentence into a matrix with pre-determined size, and then applys a deep LSTM network to decode the target sequence from the source representation. Unlike the previous work \cite{sutskever2014sequence} to store the source sentence with a passive and bottom-up way, the dynamic routing policy encodes the source sentence with an iterative process to decide the credit attribution between nodes from lower and higher layers. \textsc{CapsNMT} has two core properties: it runs in time that is linear in the length of the sequences and provides a more flexible way to select, represent and aggregates the part-whole information of the source sentence. On WMT14 English-German task and a larger WMT14 English-French task, \textsc{CapsNMT} achieves comparable results with the state-of-the-art NMT systems. To the best of our knowledge, this is the first work that capsule networks have been empirically investigated for sequence to sequence problems.