 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Spurious Subgraphs for Graph Out-of-Distribtuion Generalization
Jun 06, 2025Graph Neural Networks (GNNs) often encounter significant performance degradation under distribution shifts between training and test data, hindering their applicability in real-world scenarios. Recent studies have proposed various methods to address the out-of-distribution generalization challenge, with many methods in the graph domain focusing on directly identifying an invariant subgraph that is predictive of the target label. However, we argue that identifying the edges from the invariant subgraph directly is challenging and error-prone, especially when some spurious edges exhibit strong correlations with the targets. In this paper, we propose PrunE, the first pruning-based graph OOD method that eliminates spurious edges to improve OOD generalizability. By pruning spurious edges, \mine{} retains the invariant subgraph more comprehensively, which is critical for OOD generalization. Specifically, PrunE employs two regularization terms to prune spurious edges: 1) graph size constraint to exclude uninformative spurious edges, and 2) $\epsilon$-probability alignment to further suppress the occurrence of spurious edges. Through theoretical analysis and extensive experiments, we show that PrunE achieves superior OOD performance and outperforms previous state-of-the-art methods significantly. Codes are available at: \href{https://github.com/tianyao-aka/PrunE-GraphOOD}{https://github.com/tianyao-aka/PrunE-GraphOOD}.
VideoMolmo: Spatio-Temporal Grounding Meets Pointing
Jun 05, 2025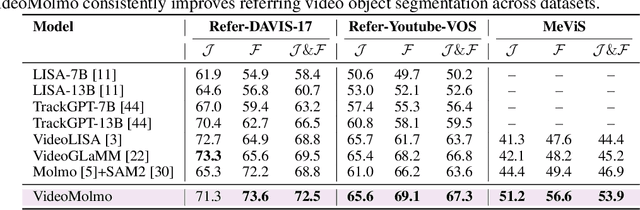



Spatio-temporal localization is vital for precise interactions across diverse domains, from biological research to autonomous navigation and interactive interfaces. Current video-based approaches, while proficient in tracking, lack the sophisticated reasoning capabilities of large language models, limiting their contextual understanding and generalization. We introduce VideoMolmo, a large multimodal model tailored for fine-grained spatio-temporal pointing conditioned on textual descriptions. Building upon the Molmo architecture, VideoMolmo incorporates a temporal module utilizing an attention mechanism to condition each frame on preceding frames, ensuring temporal consistency. Additionally, our novel temporal mask fusion pipeline employs SAM2 for bidirectional point propagation, significantly enhancing coherence across video sequences. This two-step decomposition, i.e., first using the LLM to generate precise pointing coordinates, then relying on a sequential mask-fusion module to produce coherent segmentation, not only simplifies the task for the language model but also enhances interpretability. Due to the lack of suitable datasets, we curate a comprehensive dataset comprising 72k video-caption pairs annotated with 100k object points. To evaluate the generalization of VideoMolmo, we introduce VPoS-Bench, a challenging out-of-distribution benchmark spanning five real-world scenarios: Cell Tracking, Egocentric Vision, Autonomous Driving, Video-GUI Interaction, and Robotics. We also evaluate our model on Referring Video Object Segmentation (Refer-VOS) and Reasoning VOS tasks. In comparison to existing models, VideoMolmo substantially improves spatio-temporal pointing accuracy and reasoning capability. Our code and models are publicly available at https://github.com/mbzuai-oryx/VideoMolmo.
Time Blindness: Why Video-Language Models Can't See What Humans Can?
May 30, 2025Recent advances in vision-language models (VLMs) have made impressive strides in understanding spatio-temporal relationships in videos. However, when spatial information is obscured, these models struggle to capture purely temporal patterns. We introduce $\textbf{SpookyBench}$, a benchmark where information is encoded solely in temporal sequences of noise-like frames, mirroring natural phenomena from biological signaling to covert communication. Interestingly, while humans can recognize shapes, text, and patterns in these sequences with over 98% accuracy, state-of-the-art VLMs achieve 0% accuracy. This performance gap highlights a critical limitation: an over-reliance on frame-level spatial features and an inability to extract meaning from temporal cues. Furthermore, when trained in data sets with low spatial signal-to-noise ratios (SNR), temporal understanding of models degrades more rapidly than human perception, especially in tasks requiring fine-grained temporal reasoning. Overcoming this limitation will require novel architectures or training paradigms that decouple spatial dependencies from temporal processing. Our systematic analysis shows that this issue persists across model scales and architectures. We release SpookyBench to catalyze research in temporal pattern recognition and bridge the gap between human and machine video understanding. Dataset and code has been made available on our project website: https://timeblindness.github.io/.
Open CaptchaWorld: A Comprehensive Web-based Platform for Testing and Benchmarking Multimodal LLM Agents
May 30, 2025



CAPTCHAs have been a critical bottleneck for deploying web agents in real-world applications, often blocking them from completing end-to-end automation tasks. While modern multimodal LLM agents have demonstrated impressive performance in static perception tasks, their ability to handle interactive, multi-step reasoning challenges like CAPTCHAs is largely untested. To address this gap, we introduce Open CaptchaWorld, the first web-based benchmark and platform specifically designed to evaluate the visual reasoning and interaction capabilities of MLLM-powered agents through diverse and dynamic CAPTCHA puzzles. Our benchmark spans 20 modern CAPTCHA types, totaling 225 CAPTCHAs, annotated with a new metric we propose: CAPTCHA Reasoning Depth, which quantifies the number of cognitive and motor steps required to solve each puzzle. Experimental results show that humans consistently achieve near-perfect scores, state-of-the-art MLLM agents struggle significantly, with success rates at most 40.0% by Browser-Use Openai-o3, far below human-level performance, 93.3%. This highlights Open CaptchaWorld as a vital benchmark for diagnosing the limits of current multimodal agents and guiding the development of more robust multimodal reasoning systems. Code and Data are available at this https URL.
Uni4D: A Unified Self-Supervised Learning Framework for Point Cloud Videos
Apr 07, 2025



Point cloud video representation learning is primarily built upon the masking strategy in a self-supervised manner. However, the progress is slow due to several significant challenges: (1) existing methods learn the motion particularly with hand-crafted designs, leading to unsatisfactory motion patterns during pre-training which are non-transferable on fine-tuning scenarios. (2) previous Masked AutoEncoder (MAE) frameworks are limited in resolving the huge representation gap inherent in 4D data. In this study, we introduce the first self-disentangled MAE for learning discriminative 4D representations in the pre-training stage. To address the first challenge, we propose to model the motion representation in a latent space. The second issue is resolved by introducing the latent tokens along with the typical geometry tokens to disentangle high-level and low-level features during decoding. Extensive experiments on MSR-Action3D, NTU-RGBD, HOI4D, NvGesture, and SHREC'17 verify this self-disentangled learning framework. We demonstrate that it can boost the fine-tuning performance on all 4D tasks, which we term Uni4D. Our pre-trained model presents discriminative and meaningful 4D representations, particularly benefits processing long videos, as Uni4D gets $+3.8\%$ segmentation accuracy on HOI4D, significantly outperforming either self-supervised or fully-supervised methods after end-to-end fine-tuning.
Mobile-MMLU: A Mobile Intelligence Language Understanding Benchmark
Mar 26, 2025



Rapid advancements in large language models (LLMs) have increased interest in deploying them on mobile devices for on-device AI applications. Mobile users interact differently with LLMs compared to desktop users, creating unique expectations and data biases. Current benchmark datasets primarily target at server and desktop environments, and there is a notable lack of extensive datasets specifically designed for mobile contexts. Additionally, mobile devices face strict limitations in storage and computing resources, constraining model size and capabilities, thus requiring optimized efficiency and prioritized knowledge. To address these challenges, we introduce Mobile-MMLU, a large-scale benchmark dataset tailored for mobile intelligence. It consists of 16,186 questions across 80 mobile-related fields, designed to evaluate LLM performance in realistic mobile scenarios. A challenging subset, Mobile-MMLU-Pro, provides advanced evaluation similar in size to MMLU-Pro but significantly more difficult than our standard full set. Both benchmarks use multiple-choice, order-invariant questions focused on practical mobile interactions, such as recipe suggestions, travel planning, and essential daily tasks. The dataset emphasizes critical mobile-specific metrics like inference latency, energy consumption, memory usage, and response quality, offering comprehensive insights into model performance under mobile constraints. Moreover, it prioritizes privacy and adaptability, assessing models' ability to perform on-device processing, maintain user privacy, and adapt to personalized usage patterns. Mobile-MMLU family offers a standardized framework for developing and comparing mobile-optimized LLMs, enabling advancements in productivity and decision-making within mobile computing environments. Our code and data are available at: https://github.com/VILA-Lab/Mobile-MMLU.
A Frustratingly Simple Yet Highly Effective Attack Baseline: Over 90% Success Rate Against the Strong Black-box Models of GPT-4.5/4o/o1
Mar 13, 2025Despite promising performance on open-source large vision-language models (LVLMs), transfer-based targeted attacks often fail against black-box commercial LVLMs. Analyzing failed adversarial perturbations reveals that the learned perturbations typically originate from a uniform distribution and lack clear semantic details, resulting in unintended responses. This critical absence of semantic information leads commercial LVLMs to either ignore the perturbation entirely or misinterpret its embedded semantics, thereby causing the attack to fail. To overcome these issues, we notice that identifying core semantic objects is a key objective for models trained with various datasets and methodologies. This insight motivates our approach that refines semantic clarity by encoding explicit semantic details within local regions, thus ensuring interoperability and capturing finer-grained features, and by concentrating modifications on semantically rich areas rather than applying them uniformly. To achieve this, we propose a simple yet highly effective solution: at each optimization step, the adversarial image is cropped randomly by a controlled aspect ratio and scale, resized, and then aligned with the target image in the embedding space. Experimental results confirm our hypothesis. Our adversarial examples crafted with local-aggregated perturbations focused on crucial regions exhibit surprisingly good transferability to commercial LVLMs, including GPT-4.5, GPT-4o, Gemini-2.0-flash, Claude-3.5-sonnet, Claude-3.7-sonnet, and even reasoning models like o1, Claude-3.7-thinking and Gemini-2.0-flash-thinking. Our approach achieves success rates exceeding 90% on GPT-4.5, 4o, and o1, significantly outperforming all prior state-of-the-art attack methods. Our optimized adversarial examples under different configurations and training code are available at https://github.com/VILA-Lab/M-Attack.
Style Content Decomposition-based Data Augmentation for Domain Generalizable Medical Image Segmentation
Feb 28, 2025Due to the domain shifts between training and testing medical images, learned segmentation models often experience significant performance degradation during deployment. In this paper, we first decompose an image into its style code and content map and reveal that domain shifts in medical images involve: \textbf{style shifts} (\emph{i.e.}, differences in image appearance) and \textbf{content shifts} (\emph{i.e.}, variations in anatomical structures), the latter of which has been largely overlooked. To this end, we propose \textbf{StyCona}, a \textbf{sty}le \textbf{con}tent decomposition-based data \textbf{a}ugmentation method that innovatively augments both image style and content within the rank-one space, for domain generalizable medical image segmentation. StyCona is a simple yet effective plug-and-play module that substantially improves model generalization without requiring additional training parameters or modifications to the segmentation model architecture. Experiments on cross-sequence, cross-center, and cross-modality medical image segmentation settings with increasingly severe domain shifts, demonstrate the effectiveness of StyCona and its superiority over state-of-the-arts. The code is available at https://github.com/Senyh/StyCona.
KITAB-Bench: A Comprehensive Multi-Domain Benchmark for Arabic OCR and Document Understanding
Feb 20, 2025



With the growing adoption of Retrieval-Augmented Generation (RAG) in document processing, robust text recognition has become increasingly critical for knowledge extraction. While OCR (Optical Character Recognition) for English and other languages benefits from large datasets and well-established benchmarks, Arabic OCR faces unique challenges due to its cursive script, right-to-left text flow, and complex typographic and calligraphic features. We present KITAB-Bench, a comprehensive Arabic OCR benchmark that fills the gaps in current evaluation systems. Our benchmark comprises 8,809 samples across 9 major domains and 36 sub-domains, encompassing diverse document types including handwritten text, structured tables, and specialized coverage of 21 chart types for business intelligence. Our findings show that modern vision-language models (such as GPT-4, Gemini, and Qwen) outperform traditional OCR approaches (like EasyOCR, PaddleOCR, and Surya) by an average of 60% in Character Error Rate (CER). Furthermore, we highlight significant limitations of current Arabic OCR models, particularly in PDF-to-Markdown conversion, where the best model Gemini-2.0-Flash achieves only 65% accuracy. This underscores the challenges in accurately recognizing Arabic text, including issues with complex fonts, numeral recognition errors, word elongation, and table structure detection. This work establishes a rigorous evaluation framework that can drive improvements in Arabic document analysis methods and bridge the performance gap with English OCR technologies.
DarwinLM: Evolutionary Structured Pruning of Large Language Models
Feb 11, 2025



Large Language Models (LLMs) have achieved significant success across various NLP tasks. However, their massive computational costs limit their widespread use, particularly in real-time applications. Structured pruning offers an effective solution by compressing models and directly providing end-to-end speed improvements, regardless of the hardware environment. Meanwhile, different components of the model exhibit varying sensitivities towards pruning, calling for \emph{non-uniform} model compression. However, a pruning method should not only identify a capable substructure, but also account for post-compression training. To this end, we propose \sysname, a method for \emph{training-aware} structured pruning. \sysname builds upon an evolutionary search process, generating multiple offspring models in each generation through mutation, and selecting the fittest for survival. To assess the effect of post-training, we incorporate a lightweight, multistep training process within the offspring population, progressively increasing the number of tokens and eliminating poorly performing models in each selection stage. We validate our method through extensive experiments on Llama-2-7B, Llama-3.1-8B and Qwen-2.5-14B-Instruct, achieving state-of-the-art performance for structured pruning. For instance, \sysname surpasses ShearedLlama while requiring $5\times$ less training data during post-compression training.